
引入
Uber是一家科技公司,在2010年初推出了让司机与乘客便捷沟通的应用软件,从而改变了出租车市场。为了支持业务,Uber 积极利用数据分析和机器学习模型辅助运营。从Uber 乘车的动态定价到外卖软件 Uber Eats 的“餐厅经理(Restaurant Manager)”仪表板,都使用实时数据进行高效操作。在本文中,请跟随笔者一起了解 Uber 如何管理其支持实时应用程序的基础架构。
注:本文是笔者阅读论文 Real-time Data Infrastructure at Uber 后的笔记。
一、背景
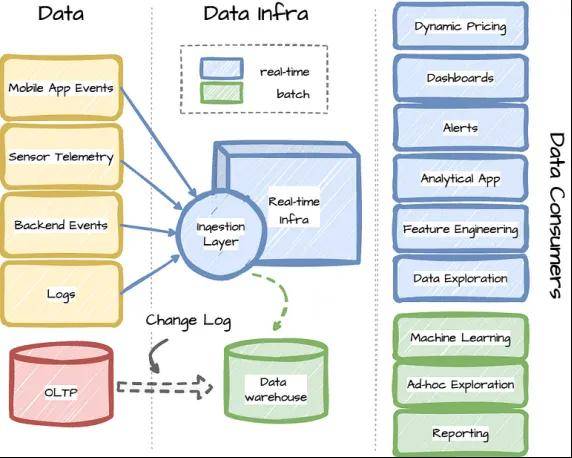
Uber的业务具有高度实时性。数据不断从多个来源收集:司机、乘客、餐馆、食客或后端服务。Uber处理这些数据以提取有价值的信息,以便为许多用例做出实时决策,如客户激励、欺诈检测和机器学习模型预测。实时数据处理在Uber的业务中扮演着至关重要的角色。该公司使用开源解决方案和内部改进来构建实时基础架构。
宏观来看,Uber的实时数据处理包括三个广泛领域:
1. 消息平台:允许生产者和订阅者之间的通信。
2. 流处理:允许将处理逻辑应用于消息流。
3. 在线分析处理(OLAP):能够在近乎实时的情况下对所有数据进行分析查询。
每个领域都面临着三个基本的扩展挑战:
数据扩展:实时数据输入总量呈指数级增长。此外,为了实现高可用性,Uber的基础架构位于多个地理区域,这意味着系统在处理数据量增加的同时,还保持数据新鲜度、端到端延迟和可用性服务水平协议(SLA)。
用例扩展:随着Uber业务的增长,新的用例出现,不同组织部分之间的需求各不相同。
用户扩展:与实时数据系统交互的不同用户具有不同的技术技能水平,包括没有工程背景的业务用户、需要开发复杂实时数据管道的高级用户。
二、对基础架构的要求
Uber的实时基础架构需要以下要点:
1. 一致性:关键应用程序需要在所有区域中的数据具备一致性。
2. 可用性:基础架构必须具有高度可用性,保证99.99%的服务水平。
3. 新鲜度:大多数用例要求数据具有秒级新鲜度。这确保了对特定事件(如安全事件)做出响应的能力。
4. 延迟:一些用例需要在原始数据上执行查询,并要求查询的p99延迟低于 1秒。
5. 可扩展性:系统能够随着不断增长的数据量进行扩展。
6. 成本:Uber需要低成本的数据处理和服务,用以确保高运营效率。
7. 灵活性:Uber必须提供程序化和声明式接口,以表达计算逻辑,服务于不同类别的用户。
三、构建模块
在这一部分,我们来审视一下Uber基础架构的主要逻辑构建模块:
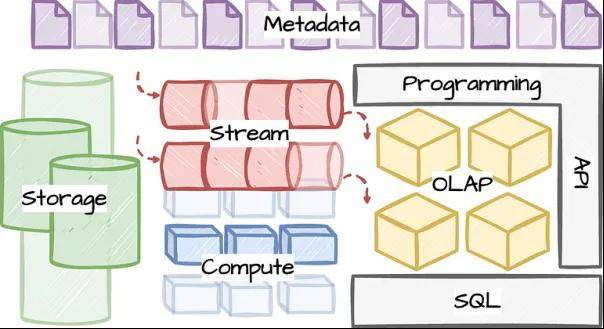
存储:该层为其他层提供对象或bolb存储,并保证写后读的一致性。它用于长期存储,应该针对高写入率进行优化。Uber还使用这一层,进行数据回填或引导到流或OLAP表。
流:它充当发布-订阅接口,应该针对低延迟的读写进行优化。它需要对数据进行分区,并保证至少一次的语义(译者注:at least once,系统保证消息被接收,但不能保证只接收一次)。
计算:该层在流和存储层上提供计算。该层还要求在源和接收器之间保证至少一次的语义。
OLAP:这一层针对来自流或存储的数据,提供有限的SQL能力;针对服务分析查询进行优化。从不同来源获取数据时,需要保证至少一次语义。某些用例需要基于主键精确地一次获取数据(exactly once)。
SQL:是计算和OLAP层之上的查询层。它将SQL语句编译成可以应用于流或存储的计算函数。当与OLAP层配合使用,将增强OLAP层的SQL限制能力。
API:高层的应用程序访问流或计算函数的编程方式。
元数据:管理所有层的所有元数据的简单接口。这一层需要元数据版本控制和跨版本的向后兼容性。
四、开源解决方案
接下来的部分将介绍Uber采用的开源系统,对应于相应的构建模块。
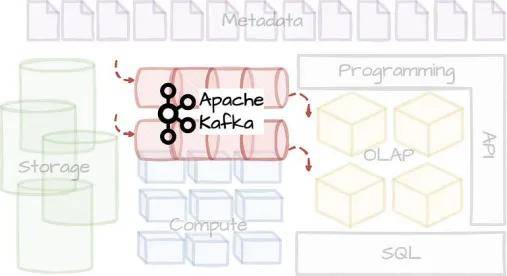
Apache Kafka是业界广泛采用的流行开源事件流系统,最初由LinkedIn开发,随后在2011年初开源。除性能外,Kafka被采用的其他因素还包括简单性、生态系统成熟度和开源社区。
Uber拥有最大的Apache Kafka部署之一:每天数万亿条消息和PB级的数据。
Kafka在Uber支持许多工作流程:传播来自乘客和司机应用的事件数据,支持流分析平台,或者将数据库变更日志传递给下游订阅者。
由于Uber独特的规模特性,他们对Kafka进行了以下增强:
1)集群联邦:逻辑集群
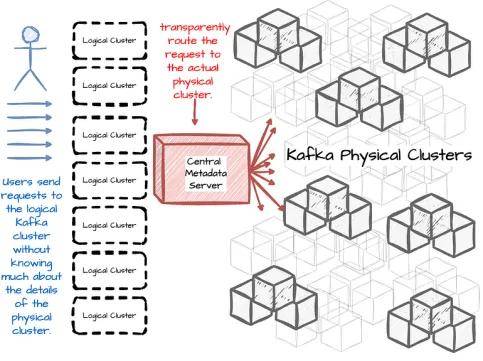
Uber开发了一个联邦化的Kafka集群设置,对生产者和消费者隐藏了集群细节:
他们向用户展示了“逻辑Kafka集群”。用户不需要知道主题位于哪个集群中。
专用服务器会集中管理所有集群和主题的元数据,并将客户端的请求路由到物理集群。
此外,集群联邦有助于提高可扩展性。当一个集群被充分利用时,Kafka服务可以通过添加更多的集群进行水平扩展。新的主题可以在新集群中无缝创建。
集群联邦还简化了主题管理。由于应用程序和客户端众多,将一个活动主题迁移到Kafka集群之间需要大量工作。在大多数情况下,这个过程需要手动配置,将流量路由到新集群,从而导致消费者重新启动。集群联邦有助于在不重启应用程序的情况下,将流量重定向到另一个物理集群。
2)死信队列:失败消息的队列
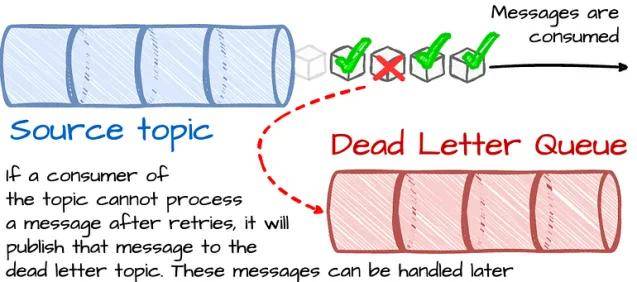
在某些情况下,下游系统无法处理消息(如消息损坏)。最初,有两种方法可以处理这种情况:
Kafka丢弃这些消息。
系统无限期地重试,这会阻塞后续消息的处理。
然而,Uber有许多场景,既不要求数据丢失,也不要求阻塞处理。为了解决这类用例,Uber在Kafka的基础上构建了死信队列(DLQ)策略:如果消费者在重试后无法处理消息,它将把该消息发布到DLQ。这样,未处理的消息将被单独处理,不会影响到其他消息。
3)消费者代理:中间层
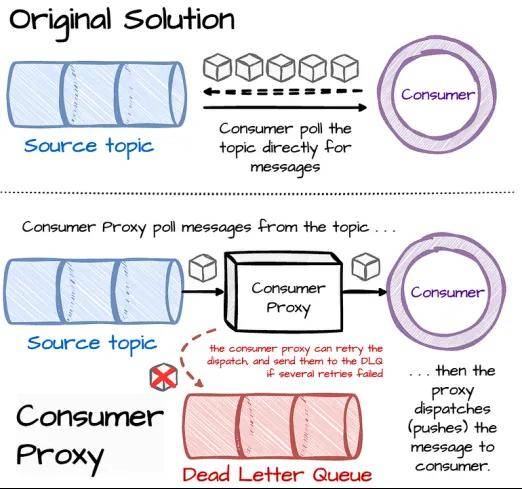
随着数以万计的运行Kafka的应用程序,Uber在调试它们和升级客户端库方面都面临挑战。用户还在企业内部,使用多种编程语言与Kafka交互,这使得提供多语言支持变得十分吃力。
Uber构建了一个消费者代理层来应对这些挑战;代理从Kafka读取消息,并将其路由到gRPC服务端点。它处理消费者库的复杂性,应用程序只需采用一个薄型的gRPC客户端。当下游服务无法接收或处理某些消息时,代理可以重试路由,并在多次重试失败后将消息发送到DLQ。代理还能将Kafka中的发送机制,从消息轮询改为基于推送的消息分派。这提高了消费吞吐量,并允许更多的并发应用程序处理机会。
4)跨集群复制:集群间高效复制主题
由于业务规模庞大,Uber在不同的数据中心使用多个Kafka集群。在这种部署中,Uber需要Kafka的跨集群数据复制,原因有二:
用户需要一个全局数据视图来处理各种用例。例如,为了计算行程指标,他们必须整合和分析所有数据中心的数据。
Uber复制Kafka部署以实现故障情况下的冗余。
Uber构建并开源了一个名为uReplicator的可靠解决方案,用于Kafka复制。复制器采用重新平衡算法,在重新平衡的过程中尽可能减少受影响主题分区的数量。此外,它还可以在流量突发时将负载重新分配给备用工作器。
笔者稍微研究了以下 uReplicator 的高层架构,发现了以下内容:
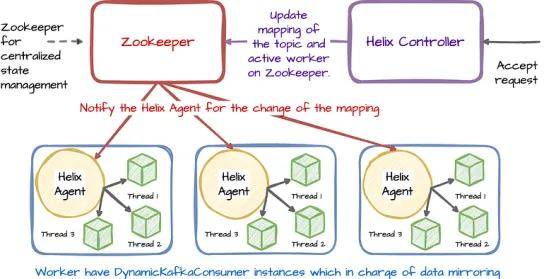
Uber 使用 Apache Helix 进行 uReplicator 集群管理。
Helix 控制器负责向工作器分配主题分区,处理主题/分区的添加/删除,检测节点故障,以及重新分配这些特定的主题分区。
收到主题/分区复制的请求后,Helix 控制器会向 Zookeeper 服务更新主题/分区与当映射发生变化时,工作者中的 Helix 代理会收到通知。
工作器中的 DynamicKafkaConsumer 实例将执行复制任务。
Uber 还开发并开源了另一个名为 Chaperone 的服务,以跨集群复制不会造成数据丢失。它收集关键统计数据,如每个复制阶段的唯一消息数量。然后,Chaperone 比较统计数据,并出现不匹配时生成警报。
Uber 使用 Apache Flink 构建了流处理平台,处理来自 Kafka 的所有实时数据。Flink 提供了一个具有高吞吐量和低延迟的分布式流处理框架。Uber 采用 Apache Flink 有以下原因:
其鲁棒性支持大量工作负载,具有原生状态管理和故障恢复的检查点功能。
易于扩展,并且可以有效处理反压。
拥有一个庞大且活跃的开源社区。
Uber 对 Apache Flink 做出了以下贡献和改进:
1)Flink SQL:使用SQL构建流式分析应用程序
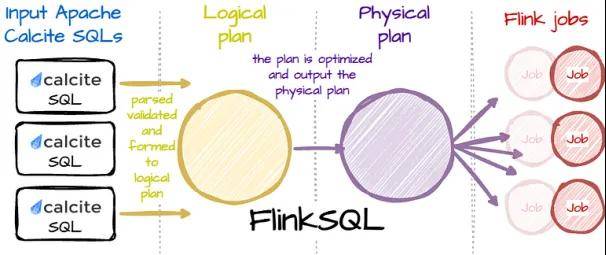
Uber 在 Flink 的顶层设计了一个名为 Flink SQL 的层,它可以将 Apache Calcite SQL 输入转换为 Flink 作业。处理器将查询编译为分布式 Flink 应用程序,并管理其整个生命周期,让用户专注于处理逻辑。在幕后,系统将 SQL 输入转换为逻辑计划,然后通过优化器形成物理计划。最后,该计划使用 Flink API 将计划转换为 Flink 作业。
然而,向用户隐藏复杂性,会增加基础架构团队管理生产作业的运营开销。Uber不得不应对这些挑战:
资源估算和自动缩放:Uber 使用分析找到常见作业类型与资源需求之间的关联,同时持续监控工作负载,以实现更好的集群利用率,并按需执行自动缩放。
作业监控和自动故障恢复:由于用户不知道幕后的运作规则,平台必须自动处理Flink作业故障。为此,Uber 构建了一个基于规则的引擎。该组件比较作业的指标,然后采取相应的行动,例如重新启动作业。
注:Flink SQL 是一个具有无限制输入和输出的流处理引擎,它的语义不同于批处理 SQL 系统,如 Presto(稍后将讨论)。
2)用于部署、管理和运行的统一架构

Uber的Flink统一平台实现了分层架构,以提高可扩展性和可扩展性。
平台层组织业务逻辑并与其他平台集成,如机器学习或工作流管理。该层将业务逻辑转换为标准的 Flink 作业定义,并将其传递给下一层。
作业管理层处理 Flink 作业的生命周期:验证、部署、监控和故障恢复。它存储作业信息:状态检查点和元数据。该层还充当代理,根据作业信息将作业路由到物理集群。该层还有一个共享组件,可持续监控作业的健康状况,并自动恢复失败的作业。它为平台层提供了一套API抽象。
底层由计算集群和存储后端组成。它提供了物理资源的抽象,无论它们是在本地还是云基础架构中。例如,存储后端可以使用HDFS、Amazon S3或Google Cloud Storage (GCS)作为Flink作业的检查点。
得益于这些改进,Flink 已成为 Uber 的中央处理平台,负责处理成千上万的作业。现在,让我们继续讨论OLAP构建模块的下一个开源系统:Apache Pinot。
Apache Pinot 是一个开源的分布式 OLAP 系统,用于执行低延迟的分析查询。它在LinkedIn 创建,“因为工程人员认为没有现成的解决方案满足该社交网站的要求”之后。Pinot 具有 lambda 架构,可呈现在线(实时)和离线(历史)数据之间的统一视图。
自从 Uber 引入 Pinot 以来的两年时间里,其数据足迹从几GB增长到数百TB。随着时间推移,查询工作负载从每秒几百个QPS(Queries-per-second,每秒查询数)增加到数万个QPS。
Pinot 支持多种索引技术来回答低延迟的 OLAP 查询,例如倒排索引、范围索引或星树索引。Pinot 采用分散-收集-合并方法,以分布式方式查询大型表。它按时间边界划分数据,并将数据分组,同时并行执行查询计划。以下是 Uber 决定使用Pinot 作为其 OLAP 解决方案的原因:
在2018年,可供选择的方案有 Elasticsearch 和 Apache Druid,但他们在接下来的评估中发现,Pinot 的内存和磁盘占用更小,而且支持明显更低的查询延迟 SLA。
对于ElasticSearch:在向 Elasticsearch 和 Pinot 输入相同数量数据的情况下,Elasticsearch的内存使用量是Pinot的4倍,磁盘使用量是Pinot的8倍。此外,Elasticsearch的查询延迟比Pinot高2到4倍,使用组合过滤器、聚合和分组/排序查询进行基准测试。
对于Apache Druid:Pinot在架构上与Apache Druid类似,但采用了优化的数据结构,例如位压缩前向索引,以降低数据占用。它还使用专门的索引以加快查询执行速度,例如星树索引、排序和范围索引,这可能导致查询延迟的差异达到一个数量级。
五、用例
在Uber,用户利用Pinot处理许多实时分析用例。这些用例的主要要求是数据新鲜度和查询延迟。为满足Uber的独特要求,工程师们为Apache Pinot提供了以下功能:
Upsert(更新插入)
Upsert操作结合了插入和更新操作。它允许用户更新现有记录,并在数据库中不存在记录的情况下插入新记录。Upsert是许多用例的常见需求,例如更正车费或更新交付状态。

Upsert操作的主要挑战是找到所需记录的位置。为了克服这一点,Uber使用主键将输入流分成多个分区,并将每个分区分发给节点进行处理。这意味着同一个节点将处理具有相同主键的所有记录。Uber还开发了一种路由策略,将同一分区段上的子查询路由到同一节点。
全面的 SQL 支持
Pinot最初缺乏重要的SQL特性,如子查询和连接。Uber已将Pinot与Presto集成,以便在Pinot之上启用标准的PrestoSQL查询。
Uber投入了大量精力将Pinot与数据生态系统的其余部分集成,以确保良好的用户体验。
例如,Pinot与Uber的模式服务集成,可从输入Kafka主题推断模式并估计数据的基数。Pinot 还集成了 Flink SQL 作为数据汇,这样客户就可以建立 SQL 转换查询,并将输出信息推送到 Pinot。
1)HDFS:档案存储

Uber使用HDFS存储长期数据,来自 Kafka 的 Avro 格式数据大多以原始日志的形式存储在 HDFS 中。压缩过程将日志合并成Parquet格式,然后可通过 Hive、Presto 或 Spark 等处理引擎使用。该数据集是所有分析目的的真实来源。Uber 还将此存储用于 Kafka 和 Pinot 中的数据回填。此外,其他平台也将 HDFS 用于其特定用途。例如:
Apache Flink 使用 HDFS 进行作业检查点。
Apache Pinot 使用 HDFS 进行长期段存档。
2)Presto:交互式查询层

Uber 采用 Presto 作为其交互式查询引擎解决方案。Presto 是 Facebook 开发的开源分布式查询引擎。它采用大规模并行处理(MPP)引擎,在内存中执行所有计算,避免将中间结果写入磁盘,从而实现对大规模数据集的快速分析查询。
Presto 提供了一个带有高性能 I/O 接口的 Connector API,允许连接到多个数据源:Hadoop数据仓库、关系数据库管理系统(RDBMS)或 NoSQL 系统。Uber为Presto构建了一个 Pinot 连接器,以满足实时探索需求。这样,用户就可以在Apache Pinot 上执行标准的 PrestoSQL。
Pinot 连接器需要决定哪些物理计划的部分可以下推到 Pinot 层。由于 API 的限制,该连接器的第一个版本只包括谓词下推。Uber 改进了 Presto 的查询计划器,并扩展了连接器 API,尽可能多地将运算符下推到 Pinot 层。这有助于降低查询延迟,充分利用 Pinot 的索引功能。
在了解 Uber 如何使用开源系统构建实时基础架构后,我们将讨论 Uber 生产中的一些用例,以及他们如何使用这些系统来实现他们的目标。
3)分析应用:激增定价(Surge Pricing)
激增定价用例是 Uber 中的一种动态定价机制,用于平衡可用司机的供应与乘车需求。用例的总体设计:
从 Kafka 获取流数据。
管道在 Flink 中运行基于机器学习的复杂算法,并将结果存储在键值存储中,以便快速查询。
激增定价应用优先考虑数据的新鲜度和可用性,而不是数据的一致性,以满足延迟 SLA 要求,因为延迟到达的消息无助于计算。
这种权衡的结果是,Kafka 集群的配置可以提高吞吐量,但不能保证无损。
4)仪表板:Uber Eats 餐厅经理
Uber Eats 餐厅经理仪表板允许餐厅所有者运行切片查询,以查看 Uber Eats 订单的深入分析,如客户满意度、热门菜单项目和服务质量分析。用例的整体设计:
该用例需要新鲜数据和低查询延迟,但它不需要太多灵活性,因为查询的模式是固定的。
Uber 使用带有 start-tree 索引的 Pinot 来缩短服务时间。
他们利用Flink执行过滤、聚合和滚动等任务,帮助Pinot减少处理时间。
Uber还观察了转换时间(Flink)和查询时间(Pinot)之间的权衡。转换过程会产生优化的索引(在 Pinot 中),并减少需要服务的数据。反过来,这也降低了服务层的查询灵活性,因为系统已经将数据变成了“固定形状”。
5)机器学习:实时预测监控
机器学习在 Uber 中扮演着至关重要的角色,为确保模式的质量,监控模型预测输出的准确性至关重要。用例的总体设计:
由于数据量大、卡数高,该解决方案需要具备可扩展性:数千个已部署的模型,每个模型都有数百个特征。
它利用了 Flink 的水平可扩展性。Uber 部署了一个大型流作业来聚合指标并检测预测异常。
Flink 作业将预聚合创建为 Pinot 表,以提高查询性能。
6)个例探索:Uber Eats 运营自动化
Uber Eats 团队需要在来自快递员、餐厅和食客的实时数据上执行临时分析查询。这些洞察将用于基于规则的自动化框架。该框架特别在 COVID-19 期间帮助运营团队在遵守法规和安全规则的情况下运营业务。用例的总体设计:
底层系统必须具有高可靠性和可扩展性,因为这一决策过程对业务至关重要。
用户在 Pinot 管理的实时数据上使用 Presto 来检索相关指标,然后将其输入自动化框架。
该框架使用 Pinot 聚合过去几分钟内给定地点所需的统计数据,然后相应地为快递员和餐厅生成警报和通知。
Pinot、Presto 和 Flink 随着数据的增长而快速扩展,并在高峰时段稳定运行。
在结束文章之前,我将在以下部分提供Uber的全面活跃策略,它如何管理数据回填,以及从Uber学到的经验教训。
Uber 依靠多地区战略,确保在地理分布广泛的数据中心上运行服务并提供备份。由此,如果一个地区的服务不可用,其他地区的服务仍可正常运行。这种方法的基础是多地区 Kafka 设置,它提供了数据冗余和流量延续。
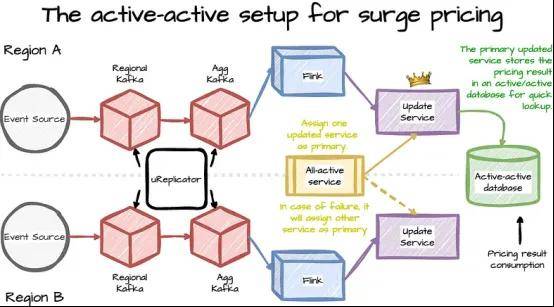
以下是动态定价应用的active-active设置示例:
所有行程事件都发送到Kafka区域集群,然后路由到聚合集群,获得全局视图。
Flink任务将计算每个区域(region)中不同领域(area)的定价。
每个区域都有一个更新服务实例,全活协调服务将其中一个标记为主实例(primary)。
为方便快速查询,主区域的更新服务将定价结果存储在全活数据库中。
当主区域发生故障时,全活服务将另一个区域分配为主区域,计算将转移到另一个区域。
Flink作业的计算状态太大,无法在区域之间同步复制,因此必须独立计算。
→ 由于 Uber 需要管理每个区域的冗余管道,因此这种方法需要大量计算。
出于多种原因,Uber 需要重新处理旧的数据流:
新数据管道通常需要针对现有数据进行测试。
机器学习模型必须用几个月的数据进行训练。
流处理管道中的变更或错误需要重新处理旧数据。
Uber 使用 Flink 构建了流处理回填解决方案,它有两种运行模式:
基于 SQL: 这种模式允许用户在实时数据集(Kafka)和离线数据集(Hive)上执行相同的 SQL 查询。
基于 API: Kappa+ 架构允许在批量数据上直接重用流处理逻辑。
Uber的经验教训
Uber 在开源组件上构建了大部分实时分析堆栈,这些开源组件为 Uber 奠定了坚实的基础。不过,也遇到了一些挑战:
根据实践经验,大多数开源技术都是为特定目的而构建的。
Uber必须做大量工作,调整开源解决方案以适用于广泛的用例和编程语言。
对于 Uber 这样的大公司来说,在架构演变过程中通常会遇到多种驱动因素,例如新的业务需求或行业趋势。因此,Uber 认识到了实现快速软件开发的重要性,以便每个系统都能快速发展:
接口标准化对于清晰的服务边界至关重要。Uber利用Monorepo在单个代码库中管理所有项目。
Uber始终倾向于使用瘦客户机(thin clients),以减少客户端升级的频率。在引入瘦Kafka客户端之前,升级Kafka客户端需要几个月的时间。
采用语言整合策略,减少与系统通信的方式数量。Uber只支持Java和Golang编程语言,使用PrestoSQL作为声明性SQL语言。
平台团队将所有基础架构组件与Uber专有的CI/CD框架集成,以在临时环境中持续测试和部署开源软件更新或功能开发,这也最大限度减少了生产环境中的问题和错误。
操作:Uber投资了声明式框架来管理系统部署。用户定义了诸如集群启动/关闭、资源重新分配或流量重新平衡等操作的高级意图后,框架将自动处理这些指令,无需工程师干预。
监控:Uber使用Kafka、Flink或Pinot为每个特定用例构建了实时自动化仪表板和警报。
Uber努力解决用户规模扩展带来的挑战,主要改进了以下几个方面:
数据发现:Uber的集中式元数据存储库充当Kafka、Pinot和Hive等跨系统模式的真实来源,使用户能够方便地搜索所需的数据集。该系统还记录了这些组件中数据流的数据沿袭。
数据审计:应用程序的事件从端到端进行审计。Kafka客户端为个别事件附加额外的元数据,例如唯一标识符、应用程序时间戳、服务名称和层级。系统使用这些元数据跟踪数据生态系统每个阶段的数据丢失和重复,帮助用户有效检测数据问题。
无缝上线:系统为生产环境中部署的相应服务自动提供应用程序日志的Kafka主题。用户还可以使用拖放式UI创建Flink和Pinot管道,由此减少了基础架构配置的复杂性。
结语
Uber的论文包含了有关实时基础架构、系统设计以及公司如何改进和调整开源解决方案(如Kafka、Pinot或Presto)以满足其独特扩展要求的宝贵经验。
参考资料
[1] Yupeng Fu and Chinmay Soman, Real-time Data Infrastructure at Uber (2021).
[2] Mansoor Iqbal, Uber Revenue and Usage Statistics (2024).
[3] Arpit Bhayani, Understanding the read-your-write consistency and why it is important.
[4] Alex Xu, At most once, at least once, exactly once (2022).
[5] Hongliang Xu, uReplicator: Uber Engineering’s Scalable Robust Kafka Replicator (2018).
[6] CelerData, Compute Architecture Pros & Cons — Scatter/Gather, MapReduce and MPP (Massively Parallel Processing) (2023)
[7] Aditi Prakash, Demystifying Predicate Pushdown: A Guide to Optimized Database Queries (2023).
[8] Dremio, Slice and Dice Analysis.








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721