
背景
Twitter的旧架构基于lambda架构,包括批处理层、速度层和服务层。批处理层主要处理
Twitter每日需实时处理高达4000亿的事件,并生成PB级的数据。这些数据主要来源于分布式数据库、Kafka以及Twitter事件总线等多种事件源。
接下来,我们将深入探讨Twitter在事件处理方面的演变,具体包括以下方面:
回顾Twitter过去的事件处理方式及其存在的问题
分析促使Twitter进行架构迁移的业务需求和客户影响
详细介绍新架构的设计与实施
对比新旧架构的性能差异
在处理事件方面,Twitter依赖一系列内部工具,例如:
Scalding用于批量处理
Heron是流媒体引擎
TimeSeriesAggregator(TSAR)用于批处理和实时处理
为了更好地理解这些工具的作用,我们先简要介绍它们:
Scalding是一个Scala库,能够轻松定义Hadoop MapReduce作业。Scalding通过Cascading(一个Java库),抽象出对底层Hadoop细节的处理,并提供了与Scala的紧密集成,使得MapReduce作业的开发更为高效。
Apache Heron是Twitter开发的流处理引擎,旨在处理大规模数据(PB级)、提升开发效率并简化调试过程。
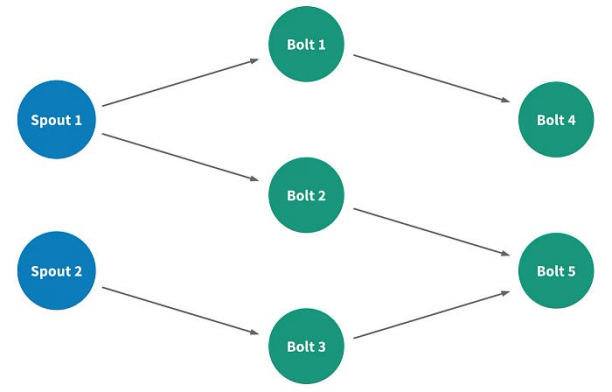
在Heron中,流处理应用被称为拓扑,它是由表示数据计算元素的节点、表示元素之间流动数据流的边为基础构建的有向无环图。
有两种类型的节点:
Spouts:它们连接到数据源并将数据注入流中
Bolts:它们处理传入的数据并发出数据
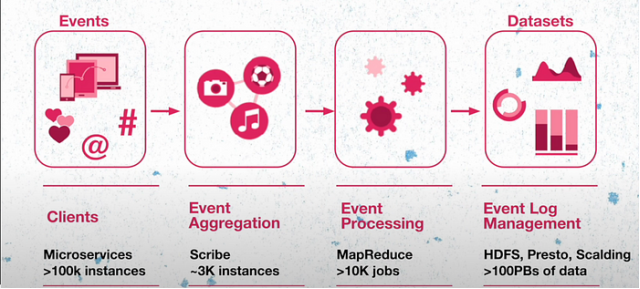
Twitter 的数据工程团队面临着每天批量实时处理数十亿个事件的挑战。TSAR是一个强大的、可扩展的实时事件时间序列聚合框架,主要负责监控参与度,如聚合推文的互动数据,并按多种维度(如设备、参与类型等)进行细分。
让我们从宏观角度来认识Twitter的运作方式。Twitter的所有功能均由微服务(其中包括遍布全球的10万多个实例)支持。微服务负责生成事件,这些事件会被发送到Meta基于开源项目构建的事件聚合层,经过事件聚合层的处理,被分组、聚合,并存储在HDFS中。随后,这些事件数据经过进一步处理、格式转换和重新压缩,形成良好的数据集。
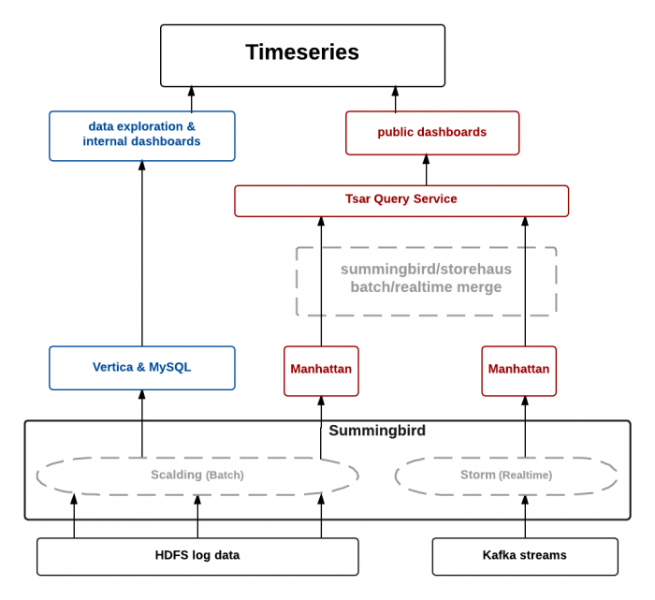
旧架构
Twitter的旧架构基于lambda架构,包括批处理层、速度层和服务层。批处理层主要处理客户端生成的日志,经过事件处理后存储在Hadoop分布式文件系统(HDFS)上。Twitter还构建了一系列扩展管道,用于预处理原始日志,并将其导入Summingbird平台作为离线数据源。速度层则负责处理Kafka主题(topic)中的实时组件源。
数据处理完毕后,批处理数据存储在Manhattan分布式系统中,而实时数据则被缓存于Twitter自有的分布式缓存Nighthawk中。TSAR系统(例如查询缓存和数据库的TSAR查询服务)是服务层的构成部分之一。
Twitter在三个不同的数据中心部署了实时管道和查询服务。为了降低批处理计算成本,Twitter选择在一个数据中心运行批处理管道,并将数据复制到其他两个数据中心。
那么,为何实时数据会选择存储在缓存中而非数据库中呢?
旧架构的挑战
旧架构面临的挑战不容忽视。让我们通过一个具体案例来理解:
设想FIFA世界杯这样的大型赛事期间,推文源开始向推文拓扑发送大量事件。若解析推文的Bolts无法及时处理这些事件,拓扑内部将出现背压。系统长时间处于背压情况时,Heron Bolts会积累Spout lag,此系统延迟较高。Twitter观察到,当这种情况发生时,拓扑滞后往往需要很长时间才能下降。
过去,团队通过重启Heron容器以恢复流处理来解决这一问题。但这种做法可能导致事件丢失,进而导致缓存中聚合计数不准确。
Twitter有多个繁重的计算管道,以处理PB级的数据。管道每小时运行一次,将数据同步至Manhattan数据库。若同步作业超时而下一个作业已开始,可能导致系统背压增加,甚至数据丢失。
TSAR查询服务整合了Manhattan数据库与缓存服务,向客户端提供数据支持。由于实时数据可能会丢失,TSAR查询服务提供给客户的指标也可能失真。
是什么促使Twitter解决这些问题呢?以下是可能的因素:
Twitter的广告服务是其主要的收入模式之一,性能下降将直接影响其商业模式。
Twitter提供各种数据产品服务来检索有关印象和参与度指标的信息,数据不准确将影响这些服务。
另外,批处理作业导致从事件创建到可用存在数小时的时延,这意味着客户执行的数据分析或其他操作将不会拥有最新数据,可能会滞后几个小时。
所以,如果想要根据用户生成的事件更新用户的时间线,或者根据用户与Twitter系统的交互方式对用户行为进行分析,客户都需要等待批处理完成。
新架构
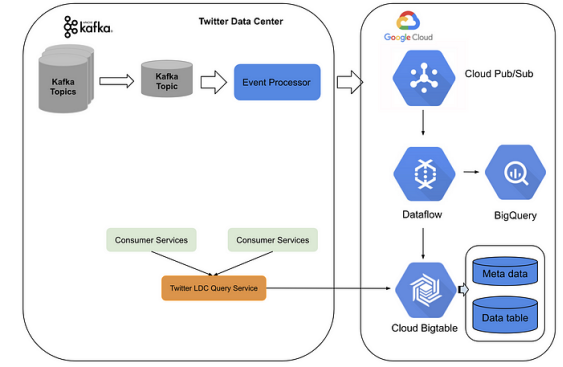
新架构建立于Twitter数据中心服务和Google Cloud平台之上。Twitter创建了一个事件处理管道,将Kafka主题转换为pub子主题,并将其发送至Google Cloud。在Google Cloud上,流数据流作业执行实时聚合,并将数据存入BigTable。
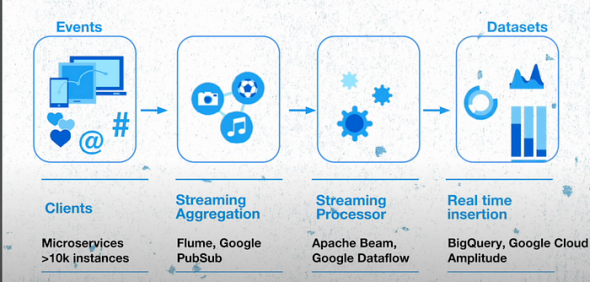
服务层方面,Twitter采用了一个LDC查询服务(前端位于Twitter数据中心,后端位于BigTable及Bigquery)。整个系统能够以低延迟(约10毫秒)的状态流式处理每秒数百万事件,并在高流量期间轻松扩展。
新架构不仅降低了批处理管道的建设成本,还实现了实时聚合的高精度和稳定的低延迟。此外,Twitter无需在多个数据中心维护不同的实时事件聚合。
性能比较
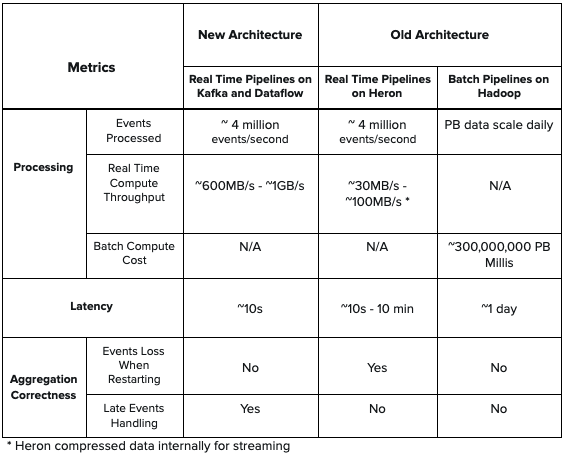
与旧架构中的Heron拓扑相比,新架构提供了更低的延迟和更高的吞吐量,同时还能处理后期事件计数,以保证在实时聚合时不再丢失事件。此外,相较旧架构,新架构中没有批处理组件,简化了设计并降低了计算成本。
总结
通过将基于 TSAR 构建的旧架构迁移到 Twitter 数据中心和谷歌云平台上的混合架构,Twitter能够实时处理数十亿个事件,并实现低延迟、高准确性、高稳定性、架构简单化,同时降低工程师的运营成本。
参考资料
Log Events @ Twitter: Challenges of Handling Billions of Events per Minute | Lohit Vijayarenu
https://youtu.be/EXMt_t_uWGE
Processing billions of events in real time at Twitter
https://blog.x.com/engineering/en_us/topics/infrastructure/2021/processing-billions-of-events-in-real-time-at-twitter-#below








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721