

作者介绍
李庆丰,新浪微博研发中心高级总监。负责微博基础架构和流媒体等研发方向,在高可用架构、视频、直播等技术方向有丰富的研发实战及管理经验,同时作为微博技术新兵训练营负责人,主导技术新人技术融入提升培训体系。技术社区的拥护者,多次担任业界前沿技术大会的讲师及出品人。
分享概要
一、微博的业务场景和挑战
二、如何构建高可用架构体系
容量问题
性能问题
依赖问题
容灾问题
三、新的探索与展望
一、微博的业务场景和挑战
微博是2009年上线的一款社交媒体平台。刚开始微博的功能比较简单,就是用户关注了一些其他微博账号,就可以在自己的信息流里看到相关用户的动态微博。

为了满足不同用户的实际需求,微博的功能也变得越来越丰富,出现了多种信息流机制,比如基于关注关系进行信息分发的关注流、基于用户兴趣进行信息分发的推荐流,还有发现页中大家都很关注的热搜板块等。
有人把微博比喻为一个大广场,每当有社会热点事件出现,首先都会在微博上发酵,然后用户都集中来微博上关注事情进展,进行相关的热议,因此也给技术架构带来巨大的挑战。

2023年第一季度财报显示:微博活跃用户MAU5.93亿,DAU2.55亿。如此大的用户量,对技术架构就是一个不小的挑战,微博用户每天发布微博、评论、点赞等可以达到亿级规模,每天新增的订阅关注也在千万级规模。
用户规模大,首先要具备海量数据存储能力,同时作为用户日常的高频应用,也要求具备一定的容灾能力。所以在谈到微博的高可用挑战的时候,首先要关注的就是微博在什么情况下流量高、挑战大。总结下来,微博有4个典型的流量场景:
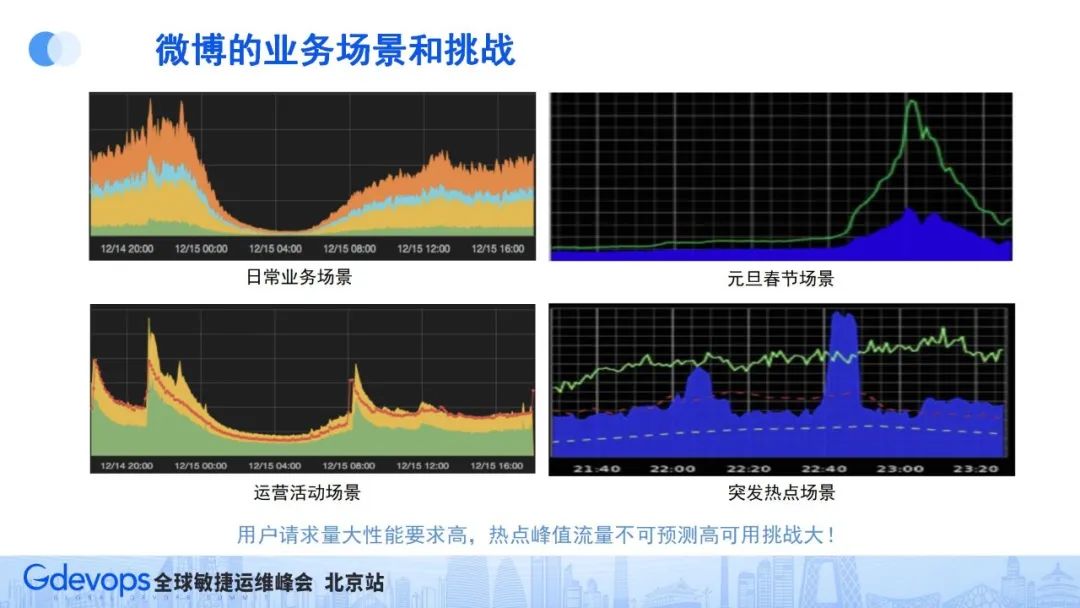
日常业务场景:微博用户一般在中午和晚上比较活跃,所以从流量上看微博会有午高峰和晚高峰;
重大节假日场景:比如元旦、春节时期,微博也会有一个非常大的流量高峰;
运营活动场景:特别的一些运营活动,流量也会比较高;
突发热点场景:这是对微博技术架构最大的挑战。
前三个场景是可以预期的,可以提前准备,而突发热点场景是不可预知的,且往往流量峰值非常高。
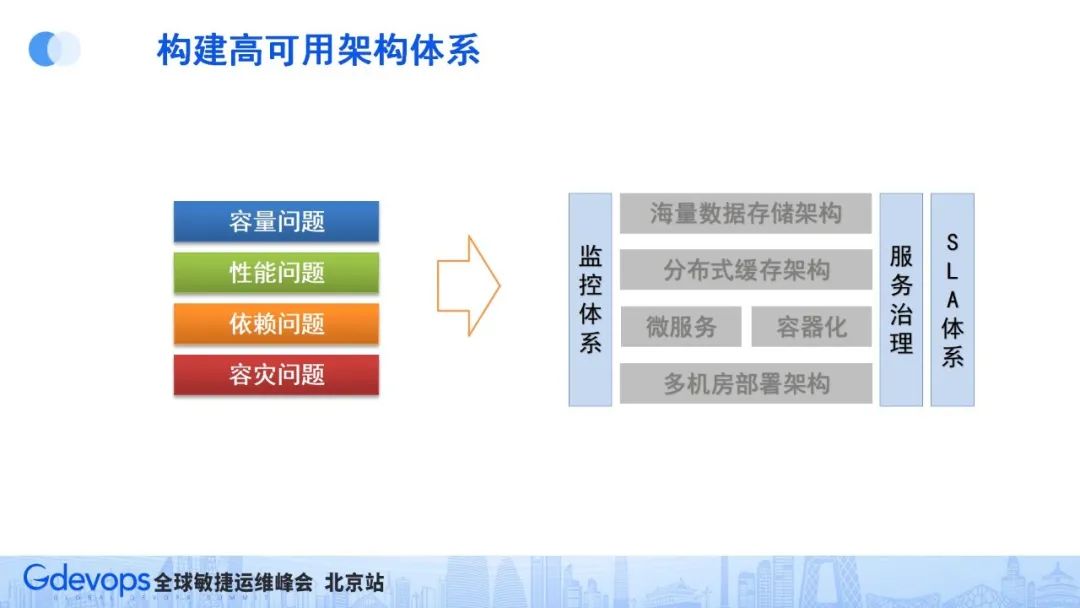
因此,从微博的业务情况和场景上看,高可用架构的挑战可以归纳出四个主要问题:

容量问题:数据存储不下,请求量扛不住
微博从刚上线时的几百万用户到现在几亿用户量,博文内容数据也在不断累积,数据量和存储压力越来越大;同时,随着用户规模增大,并发用户请求量也会增大。
性能问题:服务响应太慢,资源成本太高
接口性能问题,不仅会影响用户消费微博信息流的体验,还会增加资源成本。
依赖问题:个别非核心资源拖死整个服务
就是边缘业务功能有问题,影响了核心功能,这是不能接受的。
容灾问题:机房、专线故障导致服务不可用
近几年也经常听说机房或专线故障导致某些服务不可用情况,作为用户高频使用的APP,需要有一定的容灾能力。
二、构建高可用架构体系
针对上面提到的问题和挑战,对应的解决方案如下:

当然,解决问题最重要的一步是能够提前感知和发现问题,因此需要有比较完备的监控体系,这就组成了我们的高可用架构体系(如下图所示)。
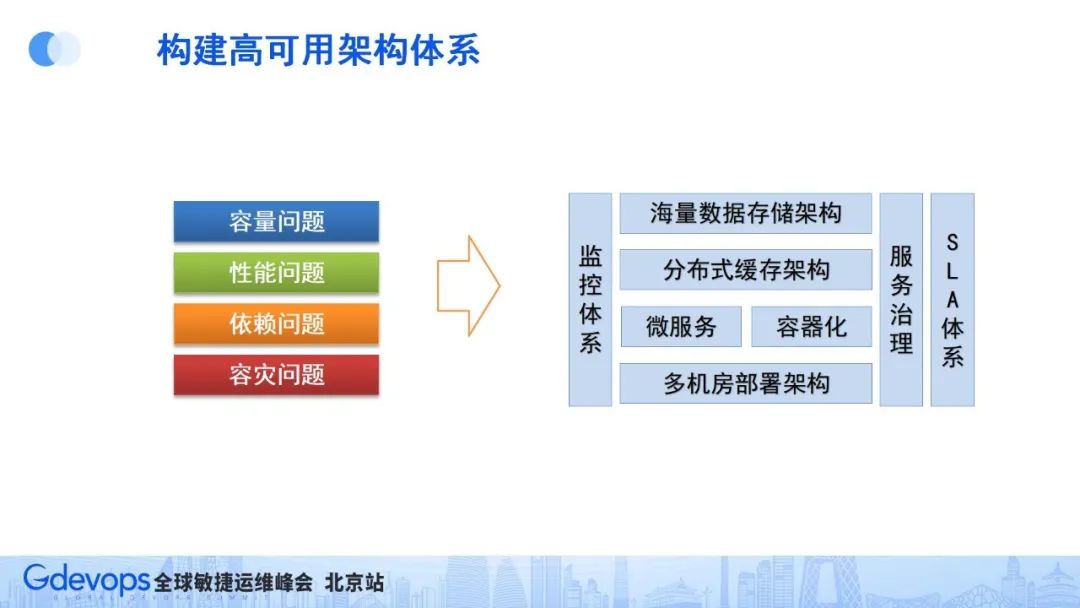
下面我们谈谈各个模块的具体技术架构方案:
建设海量数据存储架构要关注四个方面:首先是容量评估,根据业务规模和场景确定存储容量和请求的读写比例和规模,接着就可以进行存储组件选型(MySQL、Redis等),然后就需要根据实际压测数据,确定相关的容量安全阈值和请求量安全阈值,同时增加相关监控和报警,最后还要做好容量的可扩展预案,一旦存储容量或请求容量达到安全阈值,能从容按照预案应对。

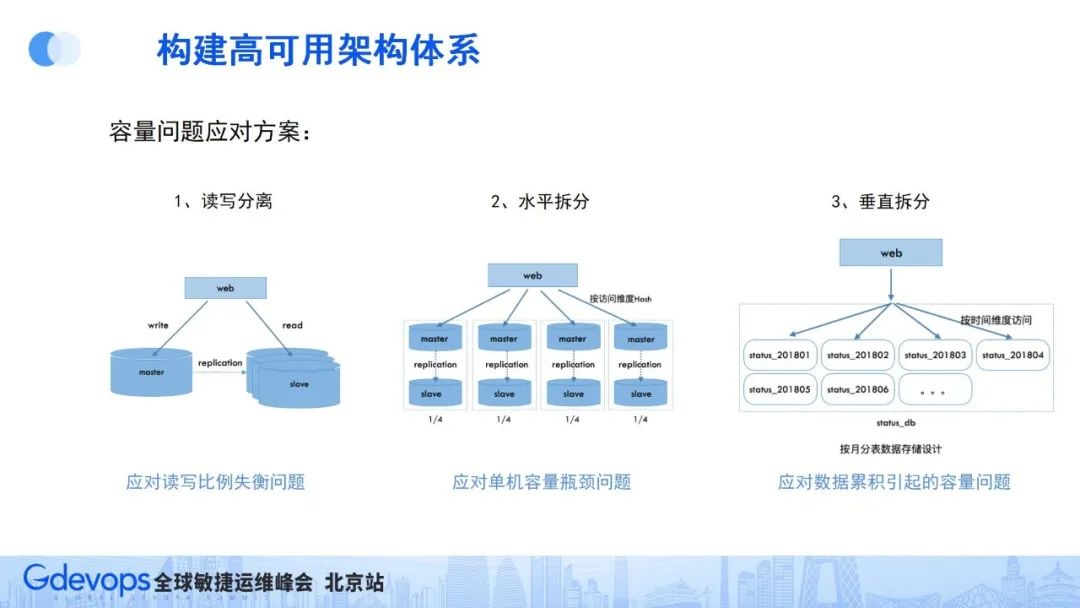
存储容量的可扩展预案,需要提前做好三方面的准备:
读写分离:特别适合读写比例失衡的业务场景,方便将来针对性地进行容量扩展;
水平拆分:能够把数据按hash存储到多个存储实例中,解决单机存储容量的瓶颈问题;
垂直拆分:针对随着时间会累积增加的内容存储场景,提前按时间维度做好分库或分表,应对随着时间累积引起的存储容量问题。
微博场景已经有十几年的历程,博文内容存储量会随着时间不断增多,因为内容存储按时间维度进行垂直拆分,每隔一段时间,就可以自然地增加新的数据库实例,不断扩展整体存储容量。
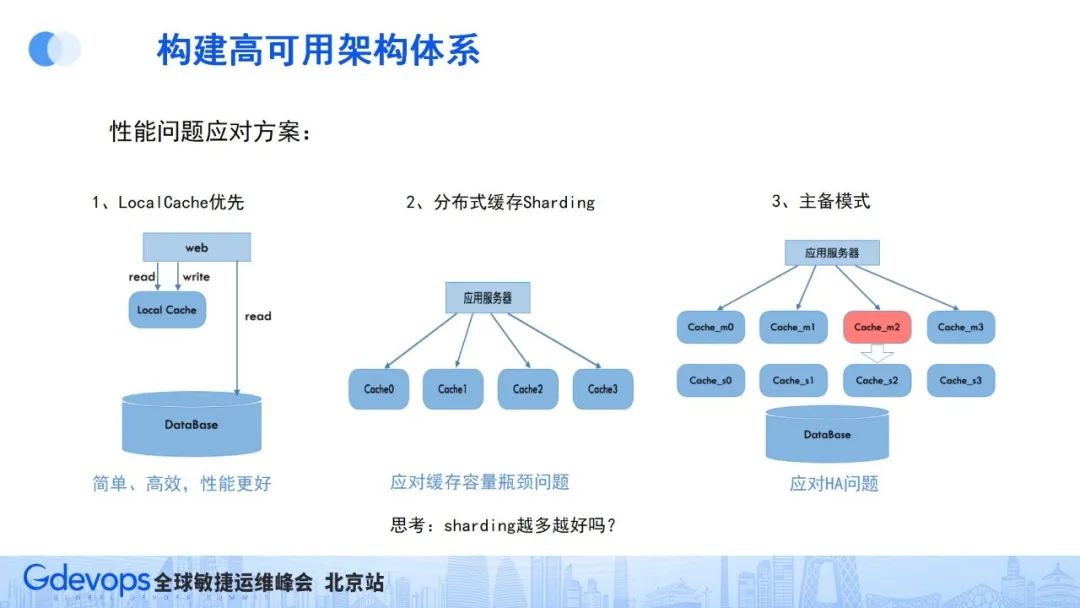
性能问题的主要应对方式是建设分布式缓存架构,也包含四个方面的建设。首先是容量评估(对应缓存要缓存什么数据,缓存数据有多大规模,增长趋势如何等),有了这些评估情况,就可以进行缓存组件选型(本地缓存LocalCache还是分布式缓存,分布式缓存常见的还有memcached或redis等),原则上,如果缓存数据不多,能使用LocalCache搞定的就尽量用LocalCache,会相对简单。
与此同时,因为互联网产品用户规模大,需要缓存的数据多,大部分情况都要用分布式缓存就来解决,所以缓存组件也需要建立性能基准,确定请求安全阈值,建立监控和报警机制,最后也要提前做好缓存容量可扩展预案。

缓存容量的可扩展和保障预案主要从下面三个方面准备:
因本地缓存机制简单高效、性能好,所以要优先使用本地缓存LocalCache;如果本地缓存放不下,就要使用分布式缓存,使用sharding分片把数据按指定hash规则放到对应缓存实例中;同时还需要考虑缓存高可用的问题,因为一旦缓存出了故障,就会有大量请求直接穿透数据库,可能会直接把对应数据库实例打挂,造成服务雪崩,一般预防措施是采用Master/Slave的主从模式。
系统一般都会有核心和非核心功能,它们之间会有调用关系,也就是有依赖关系。通常情况下,这种调用依赖会加上超时控制和重试机制,尽量降低依赖的影响。
同时,在核心功能内部,也会有核心服务模块和非核心服务模块、核心资源和非核心资源;因为这些服务模块在一个JVM(以java环境为例)或容器里,在运行环境中共享cpu、内存、磁盘,所以它们之间的很难避免互相影响。
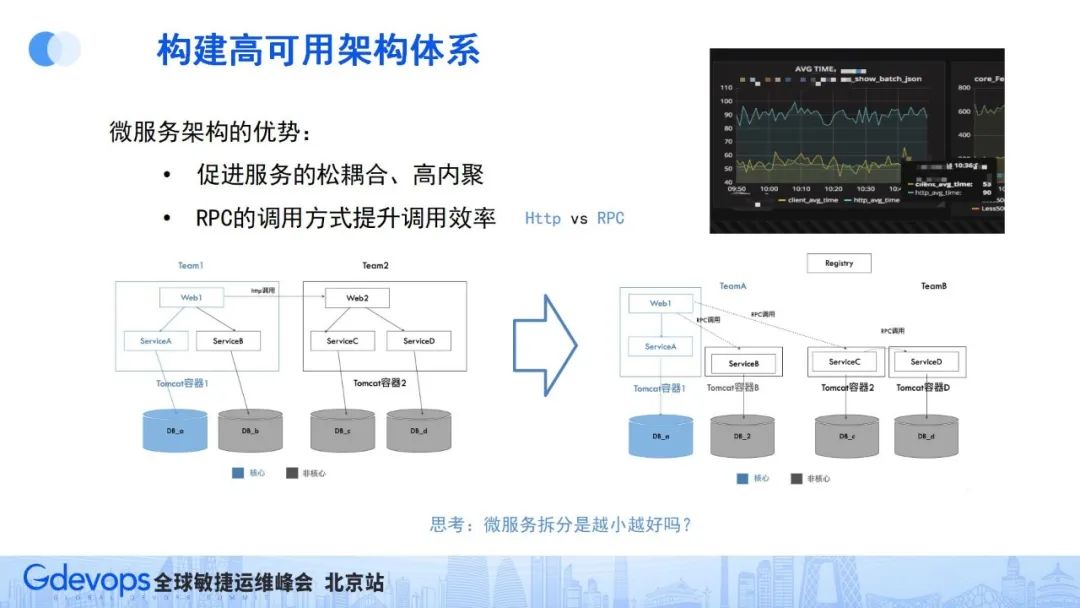
基于这种情况,我们通常会想到微服务架构。微服务架构在2012、2013年的时候就非常火,好的微服务架构要求实现松耦合、高内聚。
通过微服务的理念,把服务模块拆得足够细,再加上超时控制和容错机制,相互之间的依赖会变轻量,但同时会带来另一个问题——服务性能会变差。
通常HTTP调用相比JVM内部的进程调用耗时会慢很多,所以我们又引入了RPC调用方式来解决服务性能的问题。RPC的调用方式是在调用方和被调用方之间建立长连接通道,相比HTTP调用,省去了域名解析、握手建连流程,调用效率会高很多。
微博内部服务使用了PHP、GO、Java等不同的开发语言,为了能让这些服务间实现高效的RPC调用,我们在2014年自研了跨语言RPC服务Motan,并于内部广泛使用。目前这个RPC框架是已开源,已有5000+ star,感兴趣的同学可以去了解和共同建设。Github地址:https://github.com/weibocom/motan
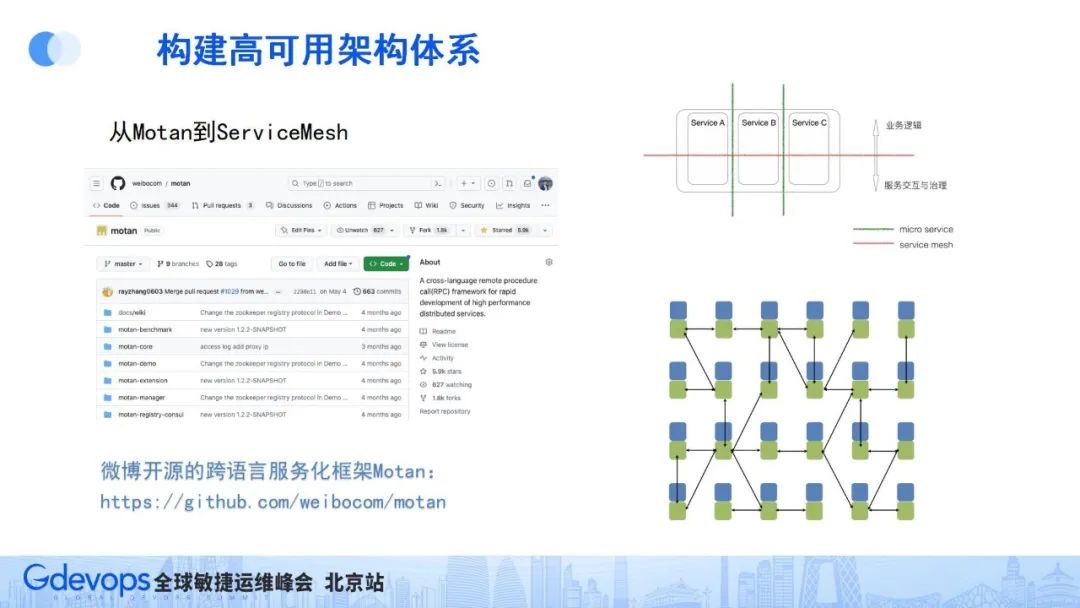
2017年左右出现了ServiceMesh技术,这是对微服务和RPC技术的一次理念升级。
因微博场景需要解决跨语言的问题,所以很早就在motan RPC框架基础上,把服务治理能力抽象到一个Agent中,然后部署上下层成为基础设施组件的一部分,这和业界ServiceMesh的部分理念不谋而合。
紧接着,我们在Motan框架基础上建设了WeiboMesh服务组件。区别于原来的微服务,我们无需业务关心通用服务治理能力下层的基础设施层,只要用了WeiboMesh,自然就具备了相关的通用服务治理能力,业务在调用接口的时候,就感觉在调用本地服务接口一样方便。
下图所示为WeiboMesh架构。我们把WeiboMesh服务直接打到基础镜像里,这样在业务部署服务时,自然就有了服务网格的基础通信能力、服务治理能力,业务间通过服务网格的通信基础走长连接通道,更加方便高效。
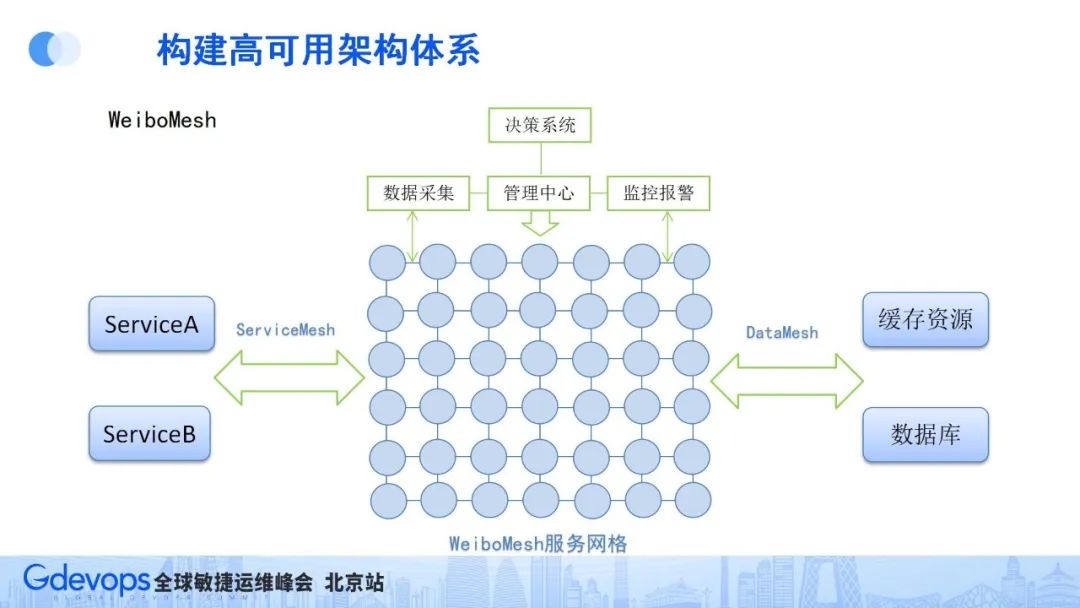
WeiboMesh的使用主要分成两方面:一方面是服务间的调用(ServiceMesh);另一方面是资源调用(DataMesh)。
资源调用DataMesh对性能要求会更高一些,有了服务网格模式后,我们就能更好地监控到所有业务的资源调用情况,方便进行相关调用管理,比如资源流量调用等。有了这些监控数据和调度手段,就能够在全站建立联动策略和故障容灾体系。
目前为止,我们通过微服务架构解决了服务依赖问题、通过Motan RPC调用解决了调用性能问题、通过ServiceMesh解决了服务治理通用化问题。但微服务还带来了一个问题——运维复杂度问题。
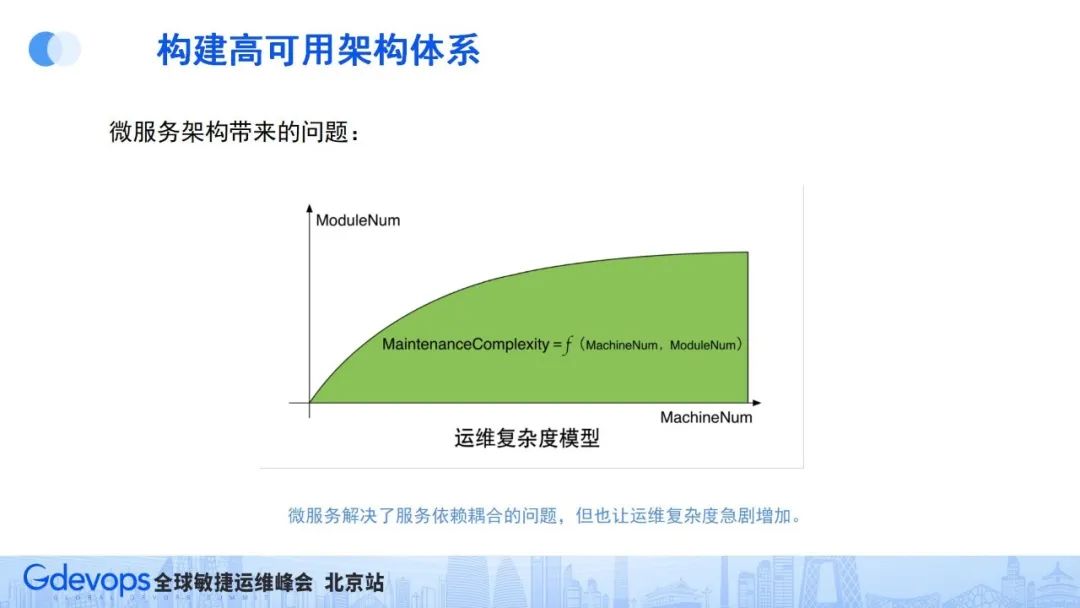
如上图所示,运维复杂度取决于两个因素:
服务规模:整个集群部署的服务器越多,运维复杂度就会越大;
服务种类:集群中的服务类型越多,运维复杂度也会随之提升。
所以,微服务拆分之后,即使集群还是同样的服务器规模,但是服务种类大幅增加了,运维复杂度也大幅增加了。
在2014年左右,Docker容器化技术正好出现了,其可以实现用非常小的成本解决运维复杂度的问题,微博作为国内最早一批大规模应用容器化技术的团队,也享受着这一新技术的红利。
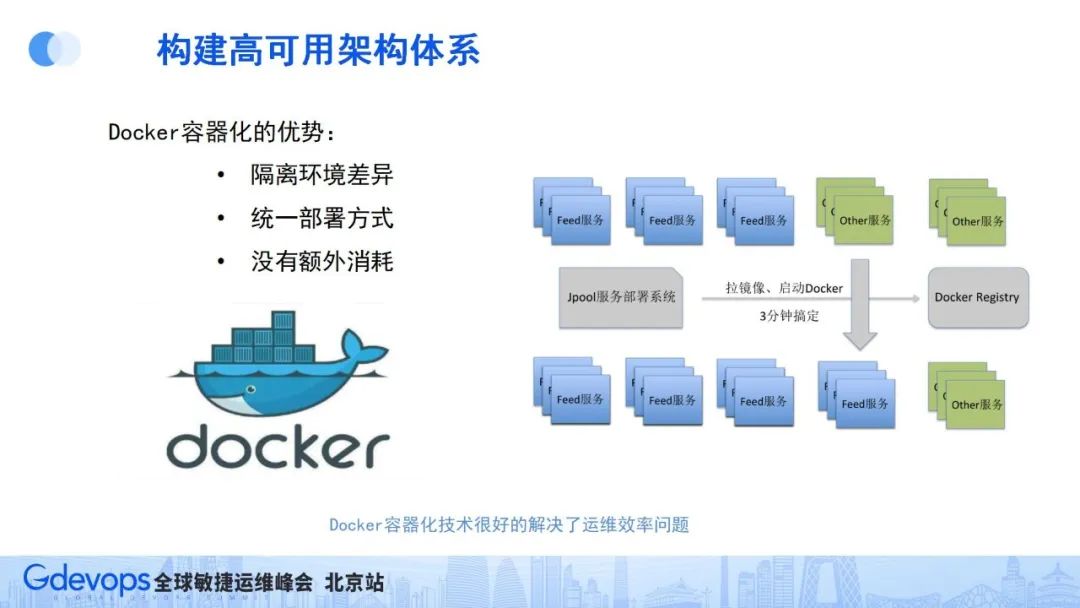
Docker容器化技术的优势是可以隔离环境差异、实现统一的部署方式,同时还没有太多额外消耗。统一部署方面,我们通过统一基础镜像的方式,解决组件和版本依赖问题。
如微博春晚扩容场景。因之前运维复杂度高,春节需要提前一个月准备采购机器和版本环境,不同服务还要检查相关差异,而在2014年春节的时候,我们首次大规模应用容器化技术进行春晚抗峰扩容,利用容器化技术屏蔽系统环境和版本差异,扩容准备时间大幅缩短,很好地解决了微服务带来的运维复杂度问题。
同时,伴随着现在公有云厂商的出现,我们又有了新的想法。回顾微博4种典型流量场景,微博的流量高峰和低谷都非常明显,如果按照高峰来部署服务器,资源成本会非常高,因此在运维效率得到一定的提升之后,我们只需部署基础流量的服务器资源,出现流量高峰的时候再从公有云临时借用一部分服务器,流量高峰过去后再归还,这样的策略大幅降低服务器成本。
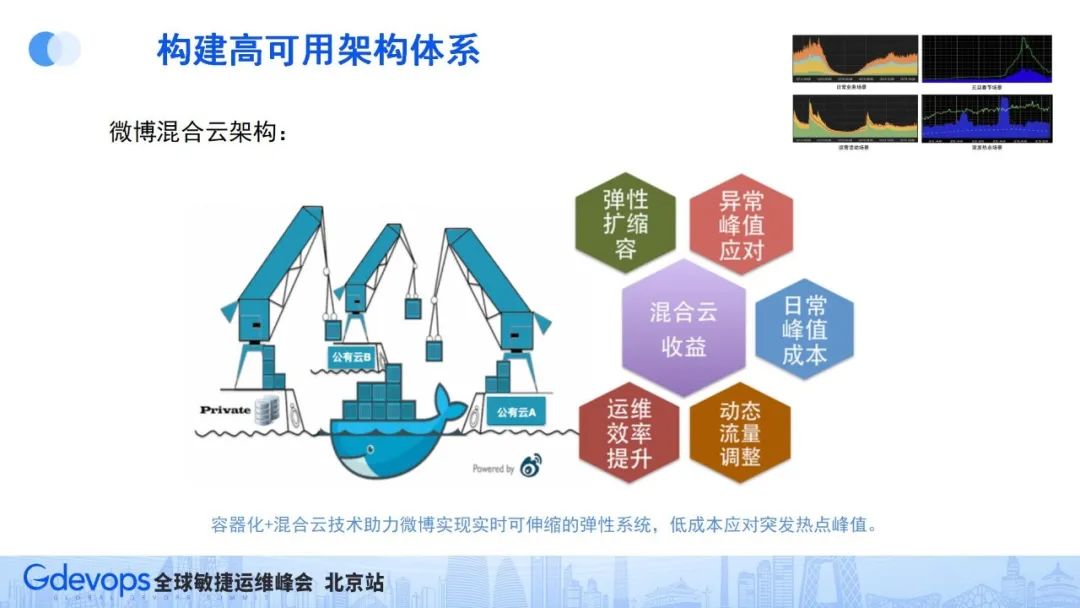
基于以上思路,我们通过容器化技术+公有云技术,并通过容器化技术屏蔽我们本地服务器和公有云服务器的环境差异,建设了微博的混合云架构。
混合云架构让微博可以日常部署基础的服务器资源,在各种流量高峰场景,还可以快速从公有云临时借服务器部署,极大地降低服务运维资源成本。特别是在微博的突发热点场景下,依托混合云技术的动态扩缩容能力,让我们可以用相对较小的成本,很好地应对微博突发热点流量。
多机房部署是大型服务必须考虑的事情,因此机房容灾的重要性在这几年特别突出。有些公司因机房问题导致的故障甚至还上了热搜,还因此受到了处罚,所以基础运维负责人要尤为重视容灾问题。

说到多机房容灾架构,我们一定首先要了解一个古老而重要的理论——CAP理论(就是一致性、可用性、分区容忍性,同一时间场景只能满足其二),对于社交场景一般是舍弃一致性,把一致性从强一致性降为最终一致性。
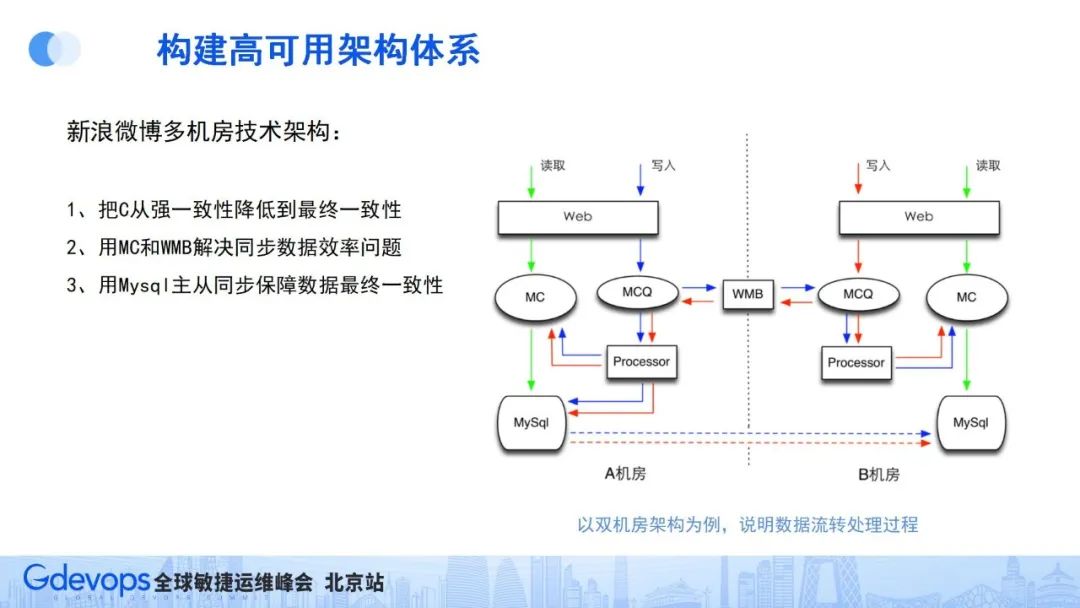
上图是微博的简化版多机房架构,这个架构主要解决三个问题:
一是把数据的强一致性降为最终一致性,多个机房之间的最终数据是通过数据主从同步的方式实现的,以此来保障机房数据的最终一致性;
二是通过自研的WMB消息总线服务,快速把消息进行机房间同步,保障机房间消息同步的高效、稳定、完整;
三是通过缓存机制,保障用户实施看到不同机房间的消息内容,不过度依赖数据库同步。
在这样的架构下 ,即使某一机房出现问题,机房内部还能形成自运行生态,从而保障服务可用。
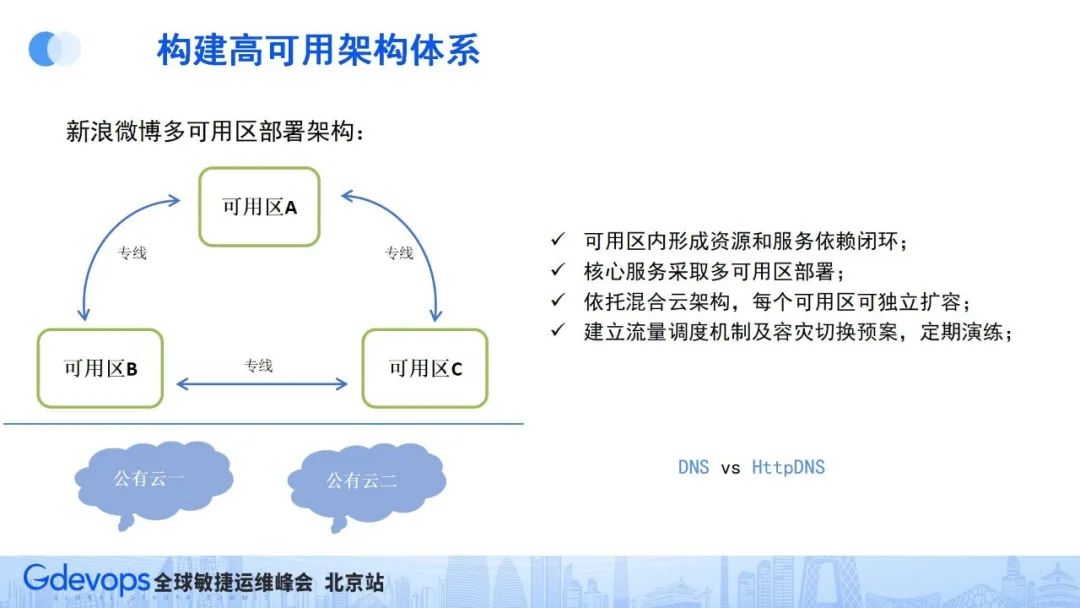
微博的机房较为分散,把几个相近的机房称为一个可用区,最终微博形成的是:三可用区+公有云架构。在可用区内部,服务和资源依赖形成闭环,同时不能强依赖可用区外的服务和资源,核心服务采用多可用区部署;同时依托混合云架构,让每个可用区可独立通过公有云随时进行快速扩容;最终还要建立流量调用机制,并定期进行相关场景的容灾演练。
探讨四大问题后,还需要探讨监控体系、服务治理SLA体系问题。服务监控是整个高可用体系的眼睛,能够及时发现问题并制定预案,服务治理也已完全融入ServiceMesh中,SLA体系作为重要的量化指标,对确保上下游建立良好默契、提高解决问题的效率有着重要作用。

高可用架构体系易于搭建,难在维护。随着日常需求的不断上线变更,系统架构也在不断变化,原来的容灾预案也可能会受影响而失效。因此,多机房架构需要持续地积累和传承,最终把这个技术经验转化为基础组件,形成平台的技术体系。
有了平台的技术体系,系统的可用性就无需过度依赖人的因素,只需服务部署在这个技术体系上,海量数据存储、分布式缓存架构、混合云体系能力都可以浑然天成。
三、新的探索与展望
微博一直在建设PAAS平台,未来,我们希望把平台积累的技术经验、技术组件集成到这个PAAS平台上,业务开发同学把功能开发完成后,只要在git提交,就能自动进行CI/CD流程、进行服务部署。

微博PAAS还以混合云技术为基础,实现服务资源的动态扩缩容能力,通过容器化技术和K8s技术,管理并标准化服务Node节点,通过ServiceMesh和DataMesh组件,管理服务间调用和资源调用,包括继承服务治理能力。通过Paaslet来进行资源的隔离和优先级调度,实现多类型服务混合部署,提升资源利用率。所有部署在PAAS平台上的服务,都可以得到runtime的实时监测,可以及时发现服务运行时异常、保障服务稳定。
随着AIGC的兴起,我们也在积极探索AIGC代码生成和异常监测方案,目前我们开发了WeCode组件,从代码开发层面提升代码质量保障服务稳定。
微博PAAS平台建设方面已初具规模,也还在不断完善,后续有机会再和大家分享。
点击此处获取本期PPT(提取码:0728)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721