
作者介绍
侯容,知乎-平台团队-用户理解&数据赋能研发 Leader。18 年入职知乎,曾担任社区、社交等业务高级研发和业务架构师,21 年加入平台团队担任用户理解&数据赋能组研发 Leader。带领团队从 0 到 1 从底层到业务层搭建实时数据基建和业务,同时整合资源完成用户理解工程及 DMP 的建设。当前负责业务包括用户理解工程、DMP、实时数据基建以及基于用户内容理解和数据的运营平台等。
一、背景
知乎业务中存在哪些问题需要解决?
为什么要建立 DMP 平台来解决这些问题?
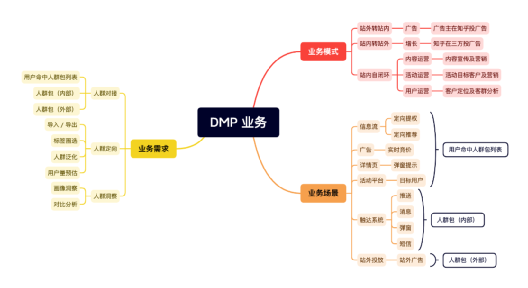
2、DMP 业务流程
当前这些业务的运营流程是怎样的?
DMP 如何与业务结合并赋能?
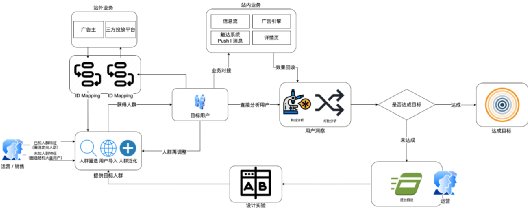
其中运营模式包含如下 3 类:
1)站内运营自闭环
内容运营。拿内容找用户,定向消费用户,站内投放,分析效果和人群成分等。
活动运营。拿活动找用户,定向消费用户,站内投放,分析效果和人群成分等。
用户运营。洞察用户,分析。
2)站内向站外投放闭环
增长投放。定向合适的人群,并在站外投放广告,数据回收,效果分析。
3)站外向站内广告闭环
广告投放。站外用户导入,定向投放。或基于对目标群体的理解圈选定向投放。
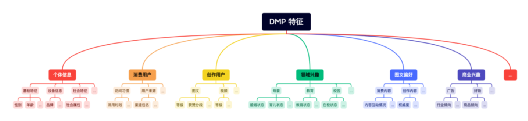
3、DMP 画像特征
当前有哪些画像特征?
这些特征是如何分层分类的?
量级如何?
3 层级特征分类:
一级分类 (8 组)
二级分类 (40 组)
标签组(120 个)
性别、手机品牌、话题兴趣…
标签(250 万)
男|女、 HUAWEI|Apple、对影视内容感兴趣程度高…
二、架构与实现
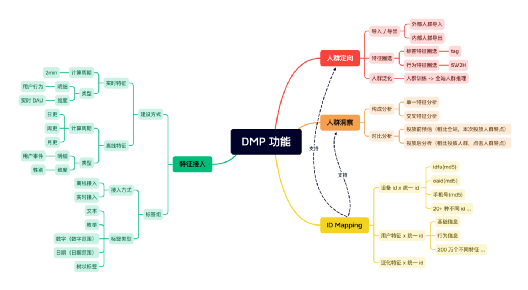
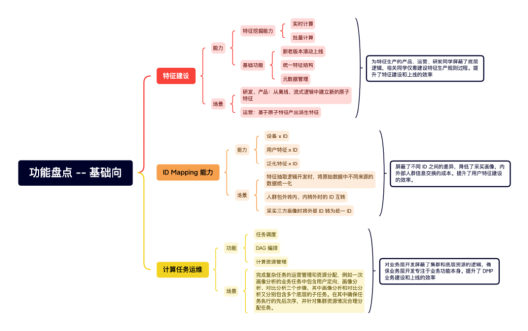
1、DMP 功能梳理
DMP 通过设计哪些功能模块,支持相应的业务流程?
2、DMP 架构
DMP 通过设计哪些功能模块,支持相应的业务流程?

架构设计重点是解决业务功能的实现复杂度,同时架构设计也是明确模块重心和设计目标的一种重要手段。拆分后,不同模块都有不同的设计重心:
1)对外模块。针对使用方定制设计。
DMP 接口:高稳定性、高并发高吞吐
DMP 前台:操作简单,低运营使用成本
DMP 后台:日常开发工作配置化,降低开发成本
2)业务模块。以可扩展为第一要务。
人群圈选:可扩展。新增特征 0 成本,新增规则低成本。
人群洞察:可扩展。新增特征 0 成本,新增洞察方式低成本。
人群泛化:可扩展。新增泛化方式低成本。
3)业务支持模块。线性水平扩展及屏蔽内部逻辑。
特征生产:扩展成本低。原子特征低成本生产,派生特征通过后台可配置
ID Mapping:屏蔽 ID 打通逻辑
计算任务运维:屏蔽机器资源和任务依赖的逻辑
存储:可扩展可持续,不因业务成长而导致成本大幅增加
3、DMP 平台功能盘点

DMP 上线至今支持了:
5+ 万人群定向
400+ 次人群洞察
60+ 次人群泛化
数据量级:
120 个标签组
250 万个标签
1100 亿条用户 x 标签的数据
数据量级:
每日 2.x TB 共 5 日 11 TB(离线、实时)特征(Doris)
120 个离线生产任务和 5 个实时生产任务
每日 6100 次人群预估,300 个人群圈选,1-2 个人群洞察,1 个人群泛化任务
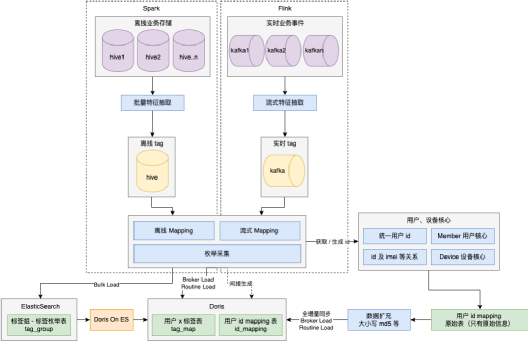
4、特征数据链路及存储
DMP 的批量、流式特征如何建设并落地到相应的存储?
数据量级:
1)特征链路
离线 Spark:Hive -> 特征抽取 -> 离线标签 -> mapping -> Doris / ES / HDFS
实时 Flink:Kafka -> 特征抽取 -> 实时标签 -> mapping -> Doris / ES / HDFS
2)存储
① Doris
用户 x 标签:用户有哪些标签(1100 亿)
id mapping:id 转化宽表(8.5 亿)
② ElasticSearch
标签枚举表:标签中文信息及搜索(250 万)
5、人群定向流程
人群定向分哪几个过程?怎么做的?
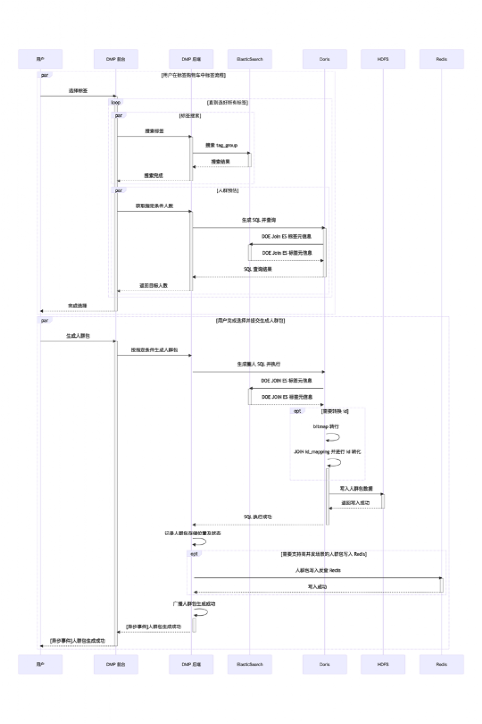
子流程:标签搜索、标签选择、人群预估、人群圈选
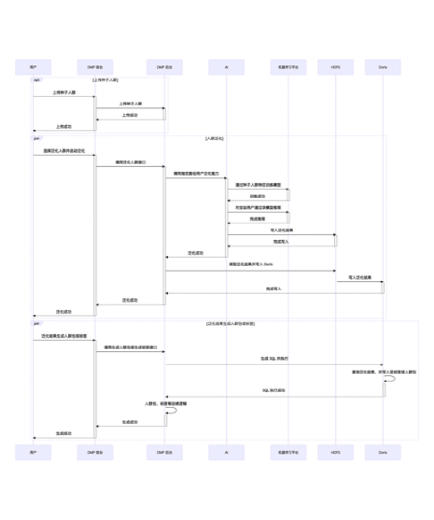
子流程:种子人群上传、人群泛化
流程图中主要介绍了:标签搜索、标签选择、人群预估、人群圈选、种子人群上传、人群泛化几个子流程的执行过程。具体在业务上执行的人群定向流程很多,以下说几种典型的:
标签加购物车 -> 圈选。
传种子人群 -> 泛化。
历史效果人群 -> 泛化 -> 叠加本次运营特点 -> 圈选。
历史效果人群 -> 洞察 -> 重新生成标签关系 -> 圈选 -> 叠加历史正向人群 -> 泛化 -> 限制分发条件 -> 圈选。
对标签、历史人群进行组合、泛化、再限制条件再圈选、洞察,最后再调整等等。
三、难题及解决方案
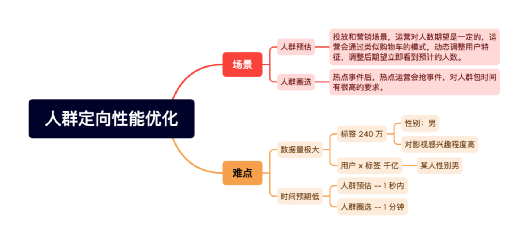
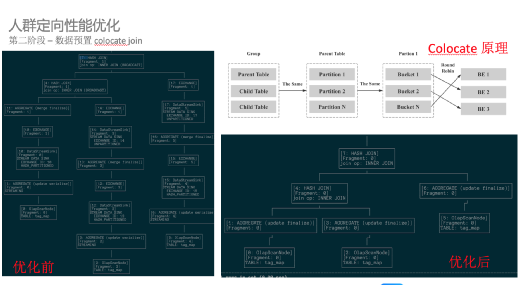
在 DMP 业务中,我们主要遇到了人群定向方面的难题,难题的原因主要有:1、人群特征数量大(1200 亿);2、时间要求低(人群预估 1 秒,圈选 1 分钟)。
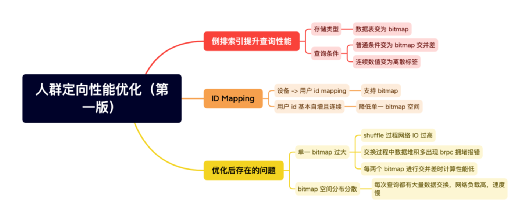
1、优化第一版
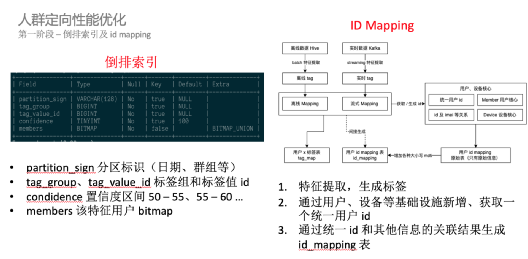
倒排、id mapping 以及查询逻辑优化

2、优化第二版
分而治之
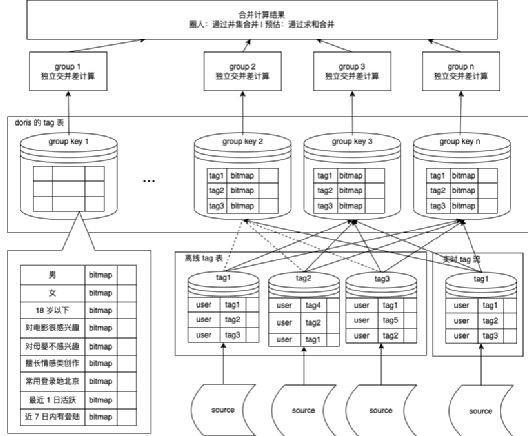
将连续一块的用户 id 的不同 tag 的数据,都增加统一的 group 字段进行分组。
在 group 内完成交并差后,最后进行数据汇总。
同时开启多线程模式,提升每组的计算效率。
四、未来及展望
1、业务向

2、技术向
1)提升查询效率
自动探测 SQL 复杂查询条件预先合并成一个派生特征的 bitmap,预测和圈人时对复杂条件 SQL 重写为派生特征。
2)提升导入速度
Spark 直接写 Doris Tablet 文件,并挂载到 FE。
针对大导入场景与 Doris 团队共建,提升写入效率。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721