
导读:
我们做软件开发时,或多或少的会记录日志。由于日志不是系统的核心功能,常常被忽视,定位问题的时候才想起它。本文由浅入深的探讨不起眼的日志是否重要,以及分布式架构下的日志运维工具应该具备哪些能力,希望感兴趣的读者能从本文获得一些启发,有所帮助。
一、什么是日志
日志是一种按照时间顺序存储记录的数据,它记录了什么时间发生了什么事情,提供精确的系统记录,根据日志信息可以定位到错误详情和根源。按照APM概念的定义,日志的特点是描述一些离散的(不连续的)事件。
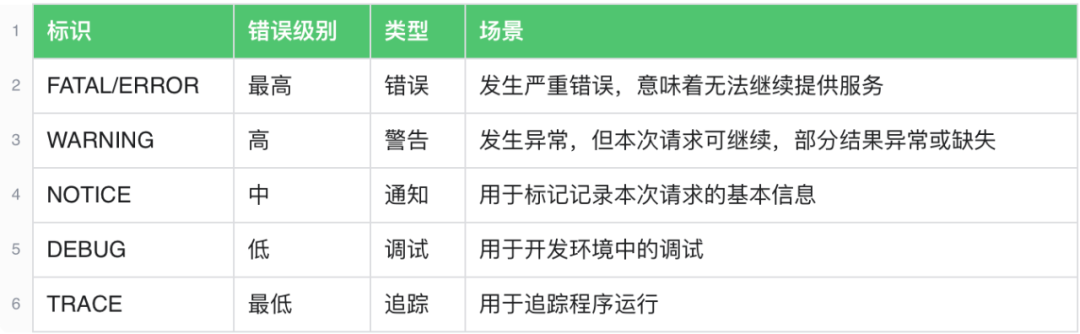
日志是按照错误级别分级的,常见的错误级别有 FATAL / WARNING / NOTICE / DEBUG / TRACE 5种类型。通常我们会在项目里面定义一个日志打印级别,高于这个级别的错误日志会数据落盘。
二、什么时候记录日志
在大型网站系统架构里面,日志是其中的重要功能组成部分。它可以记录下系统所产生的所有行为,并按照某种规范表达出来。我们可以使用日志系统所记录的信息为系统进行排错,优化性能。通过统计用户行为日志,帮助产品运营同学做业务决策。在安全领域,日志可以反应出很多的安全攻击行为,比如登录错误,异常访问等。日志能告诉你很多关于网络中所发生事件的信息,包括性能信息、故障检测和入侵检测。还可以为审计进行审计跟踪,日志的价值是显而易见的。
三、日志的价值
在大型网站系统架构里面,日志是其中的重要功能组成部分。它可以记录下系统所产生的所有行为,并按照某种规范表达出来。我们可以使用日志系统所记录的信息为系统进行排错,优化性能。通过统计用户行为日志,帮助产品运营同学做业务决策。在安全领域,日志可以反应出很多的安全攻击行为,比如登录错误,异常访问等。日志能告诉你很多关于网络中所发生事件的信息,包括性能信息、故障检测和入侵检测。还可以为审计进行审计跟踪,日志的价值是显而易见的。
四、分布式架构的日志运维
微服务发展迅猛的今天,松耦合的设计层出不穷,为简化服务服务带来了极大的便利。业务方向分工明确,研发同学只需要关心自己模块的版本迭代上线就好。随着整个业务架构的扩大,服务实例的数量迎来了爆炸性的增长,往往带来以下问题:
由不同团队开发,使用不同的编程语言,日志格式不规范统一;
微服务迭代速度快,日志漏记、级别使用错误、难以提取有效信息;
容器实例分布在成千上万台服务器上,横跨多个数据中心,异构部署,难以串联请求链路。
没有工具的情况下,需要登录服务实例,查看原始日志,在日志文件中通过grep、awk方式获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大不易归档、文本搜索太慢、不方便多维度查询。这时候需要更加高效的运维工具来代替人工访问日志。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
我们希望通过原始日志可以理解系统行为,这需要建设具备性能分析,问题定位的能力的工具平台。它能够支持:
在故障发生前,分析风险和系统瓶颈;
在故障发生时,及时通知,快速定位解决问题;
在故障发生后,有历史数据迅速复盘。
通过建设具备日志即时收集、分析、存储等能力的工具平台。用户可以快速高效地进行问题诊断、系统运维、流量稳定性监控、业务数据分析等操作。比如搭建链路追踪系统,能追踪并记录请求在系统中的调用顺序,调用时间等一系列关键信息,从而帮助我们定位异常服务和发现性能瓶颈,提升了系统的『可观测性』。前面提到日志在APM标准的定义下日志的特点是描述一些离散的(不连续的)事件。这里说下APM是什么,方便更好的构建监控方面的知识体系。
五、APM和可观测性
APM 是Application Performance Managment的缩写,即:“应用性能管理”。可以把它理解成一种对分布式架构进行观测分析优化的理念和方法论。监控系统(包括告警)作为SLA体系的一个重要组成部分,不仅在业务和系统中充当保镖发现问题、排查问题的作用。
随着系统不断演进完善,我们可以获得越多帮助于了解业务和系统的数据和信息,这些信息可以更进一步的帮助我们进行系统上的优化,由于可以梳理请求链路得出用户的浏览偏好,甚至可以影响业务上的关键决策。
整体来说,整个APM体系就是将大三类数据(logs、metrics、trace)应用到四大模块中(收集、加工、存储、展示),并在四个难点(程序异构,组件多样,链路完整,时效采样)上不断优化。
可观测性是APM的一大特征,主要由以下三大支柱构成,分别是Logging(日志),Metrics(指标),以及Tracing(应用跟踪)。
Logging:自动埋点/手动埋点,展现的是应用运行而产生的事件或者程序在执行的过程中间产生的一些日志,可以详细解释系统的运行状态,但是存储和查询需要消耗大量的资源。
Metrics:服务、端点、实例的各项指标,是一种聚合数值,存储空间很小,可以观察系统的状态和趋势,对于问题定位缺乏细节展示,最节省存储资源。
Tracing:同一TraceId的调用序列,面向的是请求,可以轻松分析出请求中异常点,资源可能消耗较大,不过依据具体功能实现相对可控。

Metrics:指标。
I think that the defining characteristic of metrics is that they are aggregatable: they are the atoms that compose into a single logical gauge, counter, or histogram over a span of time.
大致上可理解为一些可进行聚合计算的原子型数据。举些例子:cpu占用情况、系统内存占用、接口响应时间、接口响应QPS、服务gc次数、订单量等。这些都是根据时间序列存储的数据值,可以在一段时间内进行一些求和、求平均、百分位等聚合计算。指标在监控系统中不可或缺,我们都需要收集每种指标在时间线上的变化,并作同比、环比上的分析。metrics的存储形式为有时间戳标记的数据流,通常存储在TSDB(时间序列数据库)中。
Metrics侧重于各种报表数据的收集和展示,常用在大规模业务的可用性建设、性能优化、容量管理等场景,通过可视化仪表盘可高效地进行日常系统巡检、快速查看应用健康状况,可以精准感知可用性和性能问题,为产品的稳定运行保驾护航。
Prometheus 是一个开源的监控解决方案,它能够提供监控指标数据的采集、存储、查询以及监控告警等功能。作为云原生基金会(CNCF)的毕业项目,Prometheus 已经在云原生领域得到了大范围的应用,并逐渐成为了业界最流行的监控解决方案之一。
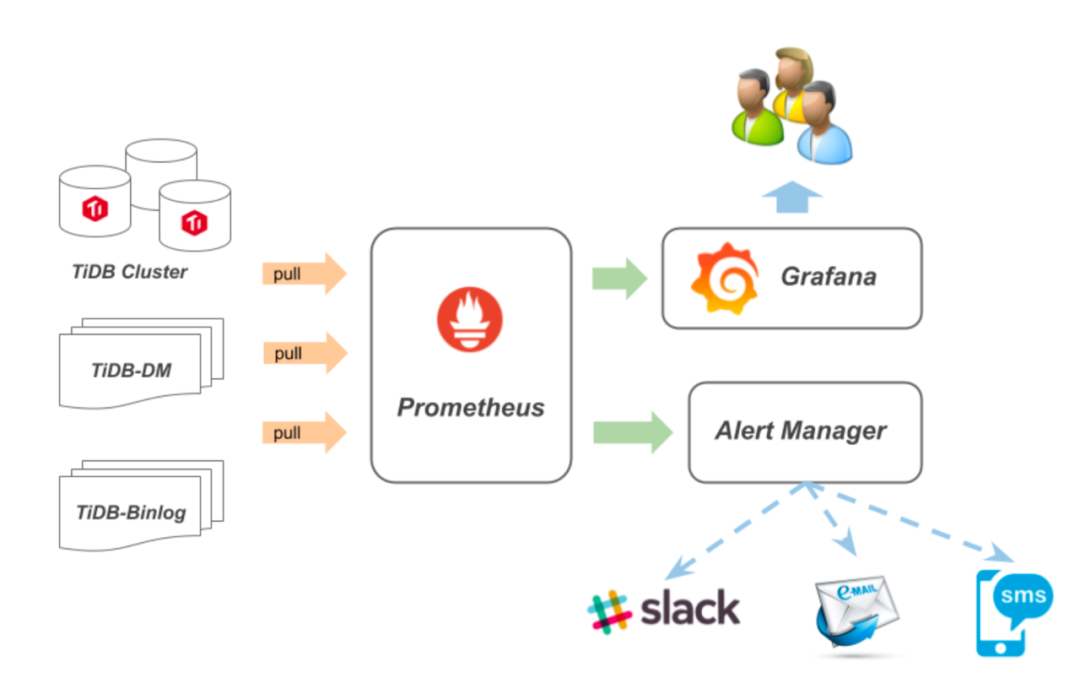
下图为Prometheus的工作流程,可以简单理解为:Prometheus server定期拉取目标实例的采集数据,时间序列存储,一方面通过配置报警规则,把触发的报警发送给接收方,一方面通过组件Grafana把数据以图形化形式展示给用户。
Logging:日志。
I think that the defining characteristic of logging is that it deals with discrete events.
日志是系统运行时发生的一个个事件的记录。Logging的典型特征就是它和孤立的事件(Event)强关联,一个事件的产生所以导致了一条日志的产生。举个例子就是一个网络请求是一个事件,它被云端接到后Nginx产生了一个访问log。大量的不同外部事件间基本是离散的,比如多个用户访问云端业务时产生的5个事件间没有必然的关系,所以在一个服务节点的角度上看这些事件产生的日志间也是离散的。
关于日志管理平台,相信很多同学听说过最多的就是ELK(elastic stack),ELK是三款软件的简称,分别是Elasticsearch、 Logstash、Kibana组成。在APM体系中,它可以实现关键字的分布式搜索和日志分析,能够快速定位到我们想要的日志,通过可视化平台的展示,能够从多个维度来对日志进行细化跟踪。
Elasticsearch基于java,是个开源分布式搜索引擎,它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
Kibana基于nodejs,是一款开源的数据分析和可视化平台,它是Elastic Stack成员之一,设计用于和Elasticsearch协作。您可以使用Kibana对Elasticsearch索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
Logstash基于java,是一个开源的用于收集,分析和存储日志的工具,能够同时从多个来源采集数据,转换数据,然后将数据发送到最喜欢的存储库中(我们的存储库当然是ElasticSearch)。
下面是ELK的工作原理:
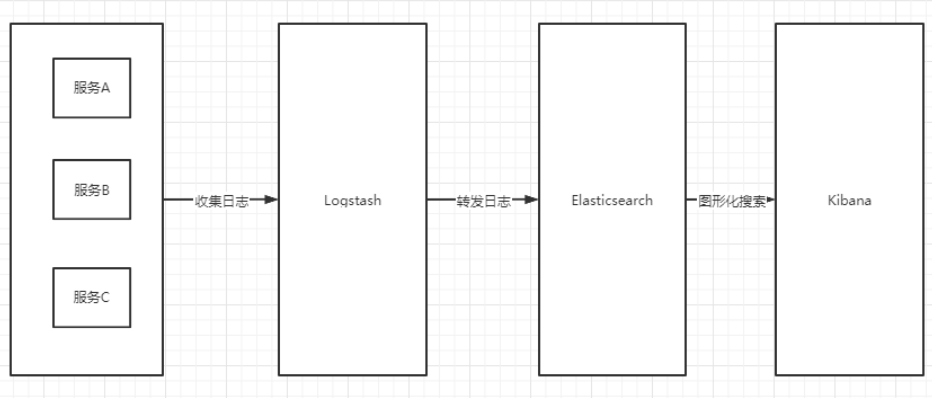
ELK中的L理解成Logging Agent比较合适。Elasticsearch和Kibana是存储、检索和分析log的标准方案。在高负载的ELK平台迭代实践中,常常采用一些优化策略。比如:ElasticSearch 做冷热数据分离,历史索引数据关闭;Filebeat更加轻量,对资源消耗更少,替代Logstash作为数据收集引擎;增加消息队列做数据缓冲,通过解耦处理过程实现削峰平谷,帮助平台顶住突发的访问压力。
ELK的缺点也是明显的,部署这样一套日志分析系统,不论是存储还是分析所需要占用的机器成本是挺大的。业务日志是时时打印的,大规模的在线服务一天日志量可能达到TB级别,如果采用ELK平台,在保证关键日志信息入库的同时,有针对性的对所需日志文件进行采集和过滤是必不可少的。
Tracing:链路。
I think that the single defining characteristic of tracing , then, is that it deals with information that is request-scoped.
链路可理解为某个最外层请求下的所有调用信息。在微服务中一般有多个调用信息,如从最外层的网关开始,A服务调用B服务,调用数据库、缓存等。在链路系统中,需要清楚展现某条调用链中从主调方到被调方内部所有的调用信息。这不仅有利于梳理接口及服务间调用的关系,还有助于排查慢请求产生的原因或异常发生的原因。
Tracing最早提出是来自Google的论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,它让Tracing流行起来。而Twitter基于这篇论文开发了Zipkin并开源了这个项目。再之后业界百花齐放,诞生了一大批开源和商业Tracing系统。
Tracing 以请求的维度,串联服务间的调用关系并记录调用耗时,即保留了必要的信息,又将分散的日志事件通过Span层串联, 帮助我们更好的理解系统的行为、辅助调试和排查性能问题。它的基本概念如下两点:
Trace(调用链):OpenTracing中的Trace(调用链)通过归属于此调用链的Span来隐性的定义。一条Trace(调用链)可以被认为是一个由多个Span组成的有向无环图(DAG图),可以简单理解成一次事务;
Span(跨度):可以被翻译为跨度,可以被理解为一次方法调用,一个程序块的调用,或者一次RPC/数据库访问,只要是一个具有完整时间周期的程序访问,都可以被认为是一个Span。
对于一个组件来说,一次处理过程产生一个 Span,这个 Span 的生命周期是从接收到请求到返回响应这段过程,在单个Trace中,存在多个Span。
举个例子,比如一个请求用户订单信息的接口,流量分发到了应用层实例(Span A)来处理请求,应用层实例(Span A)需要请求订单中心服务实例(Span B)来获取订单数据,同时请求用户中心服务实例(Span C)来获取用户数据。基础服务B、C可能还有其他依赖服务链路,则如下图所示结构,Span间的因果关系如下:
[] ←←←(the root span)|+------+------+| |[] [Span C] ←←←(Span C 是 Span A 的孩子节点, ChildOf)| |[] +---+-------+| |[] [Span F] >>> [Span G] >>> [Span H]↑↑↑(Span G 在 Span F 后被调用, FollowsFrom)
OpenTracing是一个中立的(厂商无关、平台无关)分布式追踪的API 规范,提供统一接口,可方便开发者在自己的服务中集成一种或多种分布式追踪的实现。由于近年来各种链路监控产品层出不穷,当前市面上主流的工具既有像Datadog这样的一揽子商业监控方案,也有AWS X-Ray和Google Stackdriver Trace这样的云厂商产品,还有像Zipkin、Jaeger这样的开源产品。
云原生基金会(CNCF) 推出了OpenTracing标准,推进Tracing协议和工具的标准化,统一Trace数据结构和格式。OpenTracing通过提供平台无关、厂商无关的API,使得开发人员能够方便添加(或更换)追踪系统的实现。比如从Zipkin替换成Jaeger/Skywalking等后端。

在众多Tracing产品中,值得一提的是国人自研开源的产品Skywalking。它是一款优秀的APM工具,专为微服务、云原生架构和基于容器架构而设计,支持Java、.Net、NodeJs等探针方式接入项目,数据存储支持Mysql、Elasticsearch等。功能包括了分布式链路追踪,性能指标分析和服务依赖分析等。2017年加入Apache孵化器,2019年4月17日Apache董事会批准SkyWalking成为顶级项目,目前百度厂内有一些业务线采用skywalking作为主要的日志运维平台。
指标、日志、链路在监控中是相辅相成的。现在再来看上图中,两两相交的部分:
通过指标和日志维度,我们可以做一些事件的聚合统计,例如,绘制流量趋势图,某应用每分钟的错误日志数
通过链路和日志系统,我们可以得到某个请求详细的请求信息,例如请求的入参、出参、链路中途方法打印出的日志信息;
通过指标和链路系统,我们可以查到请求调用信息,例如 SQL执行总时长、各依赖服务调用总次数;
可见,通过这三种类型数据相互作用,可以得到很多在某种类型数据中无法呈现的信息。例如下图是一个故障排查的示例,首先,我们从消息通知中发现告警,进入metrics指标面板,定位到有问题的数据图表,再通过指标系统查询到详细的数据,在logging日志系统查询到对应的错误,通过tracing链路追踪系统查看链路中的位置和问题(当然也可以先用链路追踪系统进行故障的定位,再查询详细日志),最后修复故障。这是一个典型的将三个系统串联起来应用的示例。

六、文库在日志运维上的实践
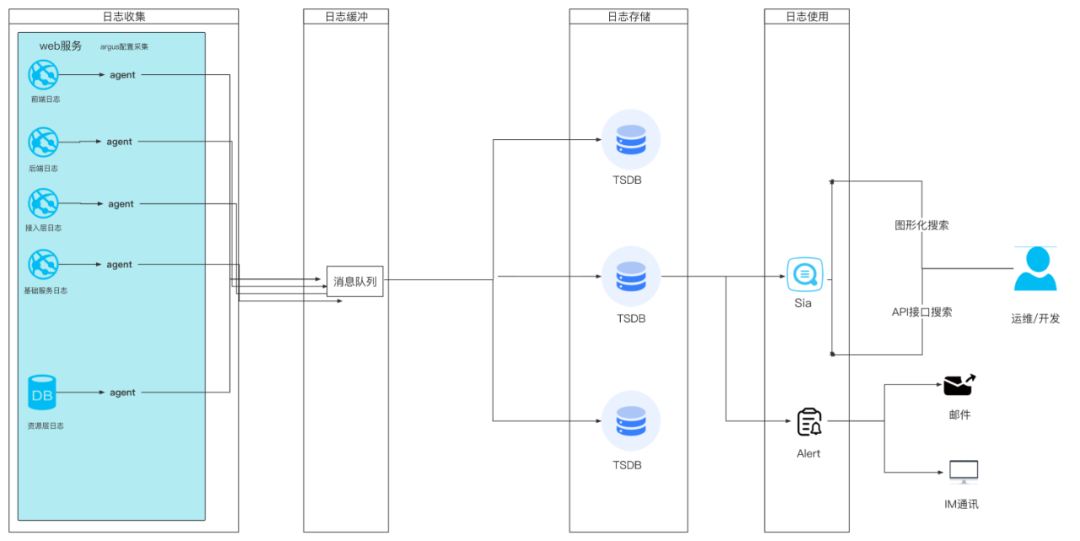
文库App对于域名、中间件、依赖服务等流量稳定性,机器资源的监控,基于厂内现有的解决方案(Bns+Argus监控系统+Sia可视化平台)实现。工作流程可以理解为:
在日志采集平台(Argus)配置数据采集规则,异常判断规则和报警配置规则;
通过服务实例映射配置(Bns)获取到要采集日志的实例列表,实例服务的log format要符合采集规则的正则表达式;
Agent上报日志分析数据给MQ消化,MQ存入TSDB;
日志汇聚后的分析计算结果符合异常判断规则,则触发对应配置的报警规则;
报警规则可以配置多维度分级分时间和不同方式提醒到接收人。同时,通过配置群聊机器人对包括资源,接入层,运行层,服务及底层依赖的等服务,依据阀值进行基本实时的监控报警;
可视化平台(Sia)通过 metric 配置从 TSDB 中读出相应数据,进行图形化展示。
即时日志捞取工具在我们业务开发中也是比较常见的,通常通过批量并发执行远程服务器指令来实现,解决依次执行的繁锁,让运维操作更安全便捷。
这种工具不依赖agent,只通过ssh就可以工作,一般通过中控机或者账户密码等方式做ssh访问控制,执行grep,tail等命令获取日志,然后对logs进行分析,可以解决日常中很多的需求。简化代码如下。
package mainimport ("fmt""log""os/exec""runtime""sync")// 并发环境var wg sync.WaitGroupfunc main() {runtime.GOMAXPROCS(runtime.NumCPU())instancesHost := getInstances()wg.Add(len(instancesHost))for _, host := range instancesHost {go sshCmd(host)}wg.Wait()fmt.Println("over!")}// 执行查询命令func sshCmd(host string) {defer wg.Done()logPath := "/xx/xx/xx/"logShell := "grep 'FATAL' xx.log.20230207"cmd := exec.Command("ssh", "PasswordAuthentication=no", "ConnectTimeout=1", host, "-l", "root", "cd", logPath, "&&", logShell)out, err := cmd.CombinedOutput()fmt.Printf("exec: %s\n", cmd)if err != nil {fmt.Printf("combined out:\n%s\n", string(out))log.Fatalf("cmd.Run() failed with %s\n", err)}fmt.Printf("combined out:\n%s\n", string(out))}// 获取要查询的实例ip地址库func getInstances() []string {return []string{"x.x.x.x","x.x.x.x","x.x.x.x",}}
把如上代码部署在中控机上ssh免密登录,通过go run batch.go或执行go build后的二进制文件,可以实现批量查询日志的基础能力。在此基础上增加传参,可以实现指定集群实例,指定exec命令,并发度控制,优化输出等功能。
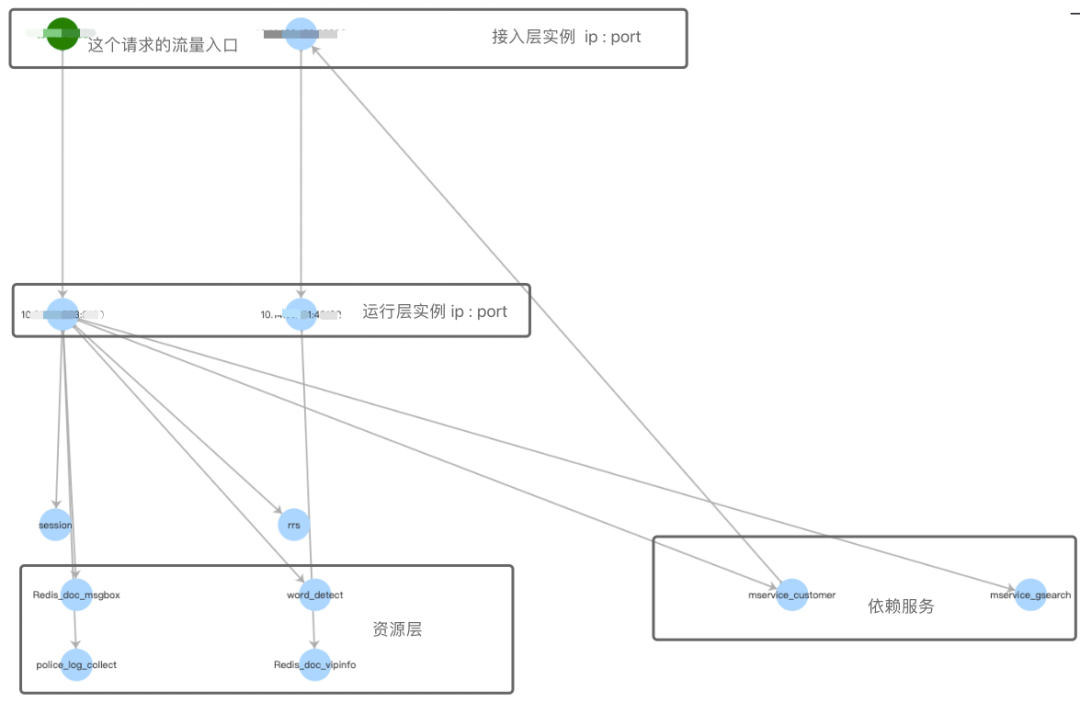
文库自研的全链路日志跟踪平台,支持trace全链路日志跟踪,指标汇聚,关键信息高亮,搜索范围覆盖nginx,nodejs,php,go等异构微服务,还支持动态绘制调用链路图。用户可以通过查询tracid的方式获得一个请求链路的http分析,调用服务的次数汇聚,日志list和拓扑链路图。
透传trace的底层流程是在接入层nginx扩展生成的一个20 -26位长、编码了nginx所在机器ip和请求时间的纯数字字符串。这个字符串在请求日志、服务运行日志、rpc日志中记录,通过Http Header向下透传,在服务间调用过程中,在当前层记录调用的下一层实例ip:port信息,保证trace参数维持。
绿色的节点为链路调用的起始节点,一般是文库接入层。鼠标hover到哪个节点会title展示详情,并在整个链路中隐去与之不相关的节点链路。如果节点有fatal,warning的日志,节点背景色会以红色,黄色展示。
七、日志的坏味道
信息不明确。后果:执行效率降低;
格式不规范。后果:不可读,无法采集;
日志过少,缺乏关键信息。后果:降低定位问题效率;
参杂了临时、冗余、无意义的日志。后果:生产打印大量日志消耗性能;
日志错误级别使用混乱。后果:导致监控误报;
使用字符串拼接方式,而非占位符。后果:可维护性较低;
代码循环体打非必要的日志。后果:有宕机风险;
敏感数据未脱敏。后果:有隐私信息泄露风险;
日志文件未按小时分割转储。后果:不易磁盘空间回收;
服务调用间没有全局透传trace信息。后果:不能构建全链路日志跟踪。
八、日志good case
能快速的定位问题;
能提取有效信息,了解原因;
了解线上系统的运行状态;
汇聚日志关键信息,可以发现系统的瓶颈;
日志随着项目迭代,同步迭代;
日志的打印和采集、上报服务,不能影响系统的正常运行。
九、结语
在万物上云的时代,通过搭建合适的日志运维平台来赋予数据搜索、分析和监控预警的能力,让沉寂在服务器的日志"动"起来,可以帮助我们在数据分析,问题诊断,系统改进的工作中更加顺利的进行,希望本文的内容对大家的实践有所帮助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721