
一、系统稳定性和高可用的辨析
系统稳定性,从字面上来看,就是让系统尽可能稳定,不要出问题。但业务是变化的,系统肯定也是一直变化的,有可能新加了个功能就把系统搞挂了,也有可能突然业务流量暴增把系统搞挂了。所以,要保障系统稳定性可谓非常之难。
稳定性、可用性是系统运行时的衡量指标。一般在稳定性治理活动中会经常提到。
稳定性治理、稳定性建设,具体都做什么,其主要内容有哪些?其实是一个很大的话题。并且这个领域,概念较多,但却很少有准确无歧义的术语。
可以先通过下面的问题略作体会。
二者有什么差异?有哪些相似之处?
他们应该在业务发展的什么时期建设?还是可以同时建设?
实际上,很多互联网大厂,也基本不明显区分二者。
稳定性建设、高可用建设落地时发现,二者之间的区别并不大,要落地的动作重合度很高。所以,到底如何界定二者呢?
之所以存在系统稳定性建设、系统高可用建设的叫法,是因为没从根本上区分这些概念。
A服务新功能上线后持续运行,接口成功率100%,无报错、无异常;运行很久后,发现逻辑缺陷或实现选型的差错,线上错了一大片数据。
问:A服务可用性指标如何?稳定性指标如何?
A系统每年因故障中断10次,每次恢复故障平均要20分钟;
B系统每年因故障中断2次,每次需300分钟恢复。
问:A系统与B系统相比,可用性和稳定性两个指标谁更高?
实际上,稳定性和高可用两个术语,都是模糊的概念,没有严格清晰的边界、没有准确统一的定义。
尤其是系统稳定性,这个词在行业上很少用在系统的量化上。(技术领域、技术团队所做的任何提升都可看作是稳定性保障工作)
国内的人或者国内大厂总是喜欢使用稳定性来描述/衡量系统。国际上更喜欢可用性和可靠性,出的书也都是高可用和高可靠,没有以稳定性来命名的。
其实国内讨论的系统稳定性,更多的是在表达可靠性与可用性。
二、可靠性、可用性与稳定性
思考:
A系统每年因故障中断10次,每次恢复故障平均要20分钟;
B系统每年因故障中断2次,每次需100分钟恢复。
问:A系统与B系统相比,可用性和可靠性谁更高?
延伸抛一个问题:可用性和可靠性之间有什么联系?
The probability that the system will meet certain performance standards and yield correct out put for a specific time.
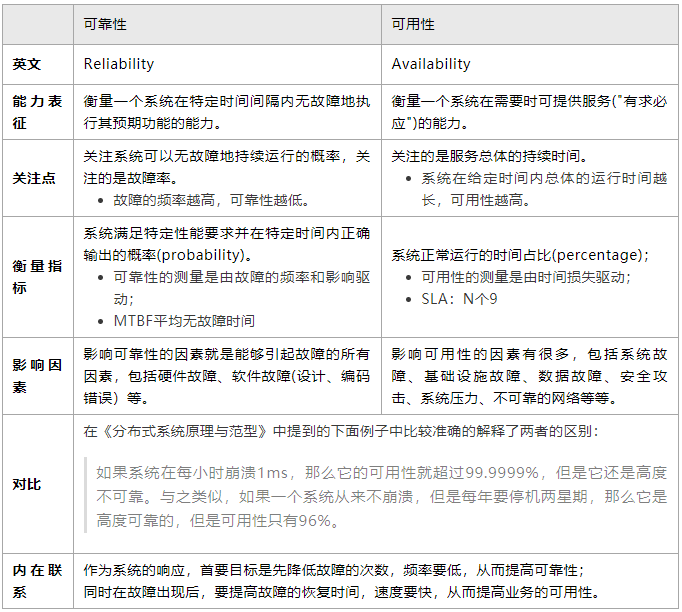
可靠性,即系统满足特定性能标准并在特定时间内产生正确输出的概率。
可靠性相关的几个指标如下:
1)MTBF(Mean Time Between Failure)
即平均无故障时间,是指从新的产品在规定的工作环境条件下开始工作到出现第一个故障的时间的平均值。
MTBF越长表示可靠性越高,正确工作能力越强 。
2)MTTR(Mean Time To Repair)
即平均修复时间,是指可修复产品的平均修复时间,就是从出现故障到修复中间的这段时间。
MTTR越短表示易恢复性越好。
3)MTTF(Mean Time To Failure)
即平均失效时间。系统平均能够正常运行多长时间,才发生一次故障。
系统的可靠性越高,平均无故障时间越长。
故障的频率越高,可靠性越低。可靠性差一定程度上是会拉低可用性,可靠性可以被认为是可用性的一个子集;但反过来不一定成立。
The percentage of time that the infrastructure, system, or solution is operational under normal circumstances.
可用性,即系统正常运行的时间占比。
可用性指系统在给定时间内可以正常工作的时间占比,通常用SLA(服务等级协议,service level agreement)指标来表示。
这是这段时间的总体的可用性指标。
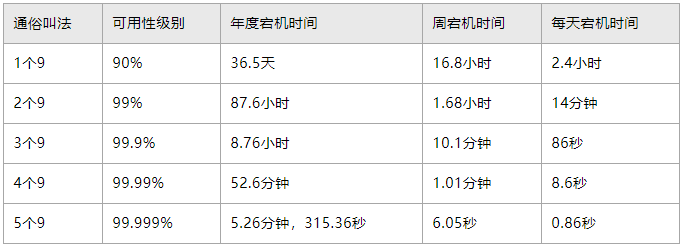
墨菲定律说“会出错的事总会出错”,可用性做到100%是可望而不可及的。对于SLA指标来说,9的数字越多可用性越高,宕机时间越少,系统就可以在给定的时刻内高比例地正常工作。然而对系统的挑战就越大,投入的成本也会越高。比如5个9要求系统每年只宕机5.26分钟,而4个9要求每年宕机时间不超过52.6分钟。这就使得系统需要在设计、基础设施、数据备份等不同层面采取多种方式,甚至增加基础设施投资来保证可用性。
不同系统的可用性要求也是不同的,比如:淘宝、京东等这些电商系统用户量很多,不同区不同时刻都有大量的用户在使用系统,这必然对系统的可用性要求很高。
影响可用性的因素有很多,包括系统故障、基础设施故障、数据故障、安全攻击、系统压力、不可靠的网络等等。
通常,可用性和可靠性是齐头并进的, 可靠性的提高通常会转化为可用性的提高。然而,这两个指标产生的结果、关注点不同。
可用性的测量是由时间损失驱动的,而可靠性的测量是由故障的频率和影响驱动的。
对于任一指标,组织都需要决定他们可以承受多少时间损失和故障频率,而不会破坏最终用户的整体系统性能。同样,他们需要决定在服务、基础设施和支持上花费多少,以满足系统可用性和可靠性的某些标准。
通常情况下,系统稳定性建设/高可用建设,首要目标是先降低故障的次数,频率要低,从而提高可靠性;同时在故障出现后,要提高故障的恢复时间,速度要快,从而提高业务的可用性。
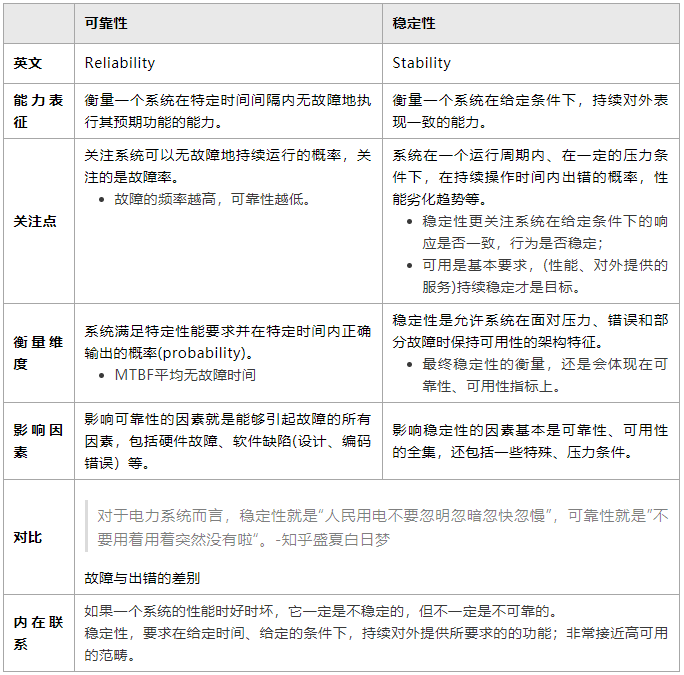
如果一个系统的性能时好时坏,它一定是不稳定的,而不一定是不可靠的。
稳定性就是“人民用电不要忽明忽暗忽快忽慢”;潜在的用电高峰也要稳定提供服务,说明稳定性还是会要求系统具备一定的自适应能力。
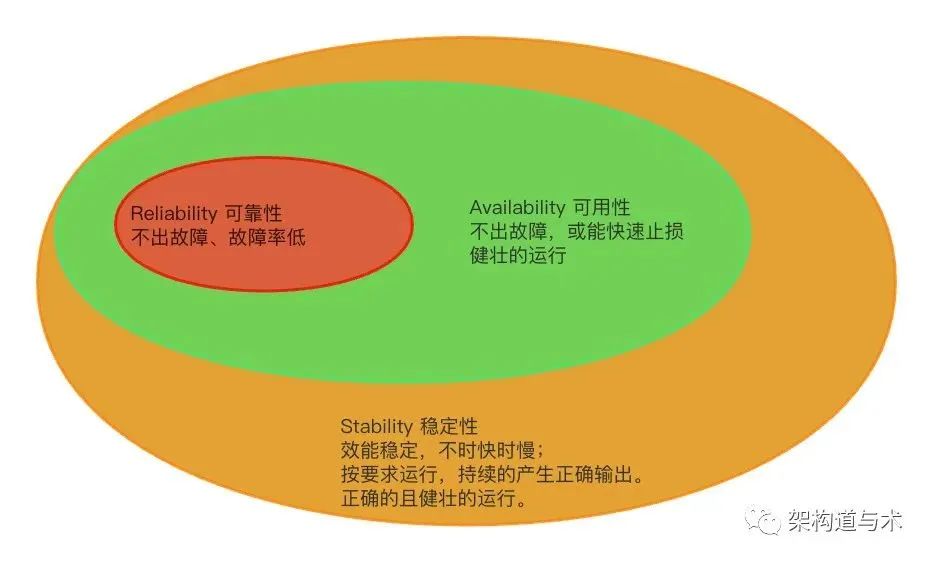
可靠是可用的前提,持续稳定是可靠的进一步提升。
到这里,你是否对可用性、可靠性和稳定性有了更清晰的了解了呢?有了这些指标可以帮助我们去分析系统存在的问题,比如说故障频率较高,故障恢复时间较长,那么系统的可靠性可用性一定很低,对用户的影响一定很高,就可以促使我们去从各个角度去改进和提高,去找架构设计的问题,去找系统实现的缺陷,去找依赖的基础设施问题等等,从而改善我们的系统。尤其是在当下复杂的分布式系统下,这些显得尤为重要。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721