
开发一个不崩溃的核酸系统到底难不难?

这篇文章,勇哥想象自己是核酸系统架构师,谈谈自己对核酸系统的理解。
一、明确系统边界
作为架构师,首先需要明确系统边界。
核酸检测核心流程:
医护人员打开核酸系统的手机端应用,录入试管编码 ;
医护人员扫描居民的健康码;
医护人员采集咽拭子标本;
检测结束之后,医护人员将检测标本送至检测中心;
检测中心将检测结果提交到核酸系统,然后核酸系统会将核酸结果同步到健康码系统。
成都核酸系统崩溃时,流程阻塞在步骤一和二。
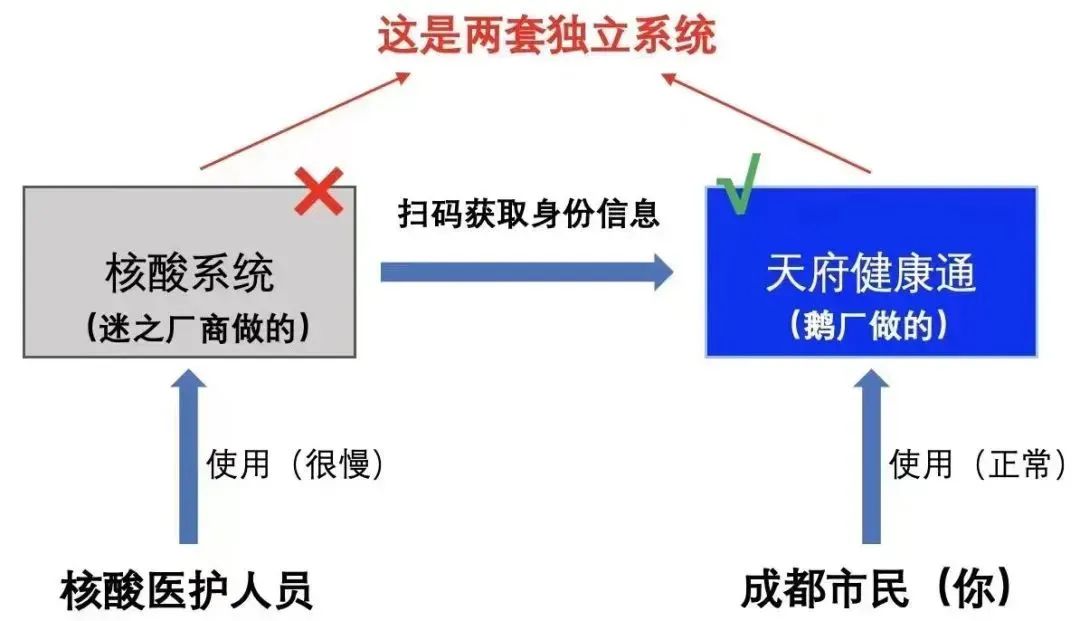
对于成都市居民来讲,与他们关系最为密切的就是两套系统。
核酸系统:核酸医护人员使用 , 东软负责开发和维护;
天府健康通:广大市民使用,腾讯研发和维护。
二、崩溃疑云
核酸系统软件是属于政府购买 (TO G),市民使用 (TO C) 。
核酸系统是一个多方协作的系统,它不仅直接和政府有关系,还涉及到多个厂商,一个系统工程背后,除了系统集成商之外,包括多个分包商。比如西安的一码通,曾集结了电信、东软、美林和安恒等公司。
正因为这套系统涉及面之广,当成都核酸系统崩溃时,我们需要冷静下来,缕清条理。
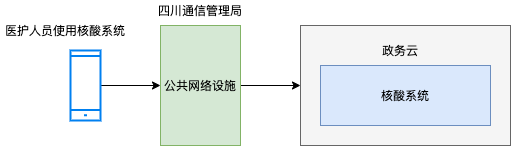
我们先从基础设施层的维度来分析,很多互联网公司会将自己的服务部署在阿里云或者腾讯云,部署方便,也可以动态扩容。
那么核酸系统部署在哪里呢?假如核酸系统是以 SAAS 形态部署(东软自建机房,或者东软采用阿里云/腾讯云服务),那么成都核酸崩溃事件,东软必然脱不了干系 。但东软随后硬气的发了公告:
系统上线后,发现有响应延迟、卡顿等现象,东软集团第一时间组织专家组和坚守现场的公司技术人员,与成都市相关部门一起,排查事故原因,强化安全防护,保证系统运行。据技术专家研判,目前出现的系统响应延迟、卡顿等现象与核酸检测系统软件无关。9月3日零点左右,在进行网络调整之后,系统运行平稳顺畅,效率得到极大提升,当日共完成1200万样本采集量。
假如核酸系统没有问题,会不会是网络问题呢?

成都核酸系统奔溃时,医护人员以为是信号问题,纷纷举起手中的手机,捕捉信号,而排队的市民却可以刷抖音,头条。
9月3日下午4点32分,四川省通信管理局发文称,“全市通信网络运行平稳,各核酸检测点移动网络覆盖良好,没有出现网络拥塞和故障。”
我们基本可以做出判断:成都核酸系统部署在政务云,也就是政府部门提供基础设施 ,应用开发商将软件部署在政务云机房里 。
核算系统崩溃的可能原因:
政务云机房问题
网络问题(负载均衡,带宽,防火墙), 或者机房服务器出现故障。
核酸系统软件问题
核酸检测软件确实承载能力有限,软件崩溃了。
三、应用层设计
核酸系统是属于高并发应用吗?这里我们做个估算:
人口估算法
据统计成都市人口2千万多人,假设集中在6小时内做核酸,平均每小时支持的并发人数是3531666。每秒支持的并发约为1000。基于检测人员的集中度不均衡的因素,假设高峰期是平均并发的2-3倍。则每秒并发“核酸登记”2000-3000左右。
检测点估算法
今年5月份,上海抗疫期间一共有 15000 + 核酸检测点 ,我们假设成都有和上海一样多的核酸检测点。市民在排队核酸检测时,核酸医护人员扫居民健康码的时间间隔在10秒到15秒之间,每个核酸检测点并行两排检测通道,那么每秒并发“核酸登记”也是在 2000-3000 左右。
通过两种估算方法,我们发现:核酸系统的请求并发度并不高。
虽然并发度不高,但每天的业务数据条数量级较高 ,按照东软的公告,每天可以完成1200万核酸样本采集。
假设核酸检测记录一天1000万条数据,一周就有7000万条,1个月就能达到3亿条数据。那么势必要使用分库分表。
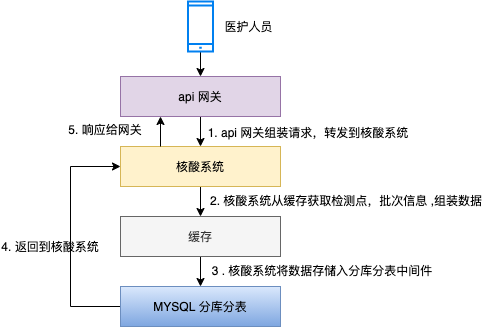
医护人员扫市民的健康码 ,核酸登记的请求发送到 api 网关 , api 网关将请求转发到核酸系统;
缓存存储检测点,检测批次等基础信息,核酸系统通过缓存判断业务请求是否合法,若合法,则组装真正的入库的数据;
核酸系统调用分库分表中间件将数据插入到数据库。
看起来,核酸系统的架构设计还是比较简单清晰的,核心点在于用分库分表硬挡高流量访问。
但现在这种模式就完美了吗 ?
我们举湖北鄂通码举例,核酸登记后,健康码在 10~20 分钟状态会修改成绿色并标识成:核酸已检测,也就是核酸已检测的状态会异步同步到健康码服务。
我们不由得想到了消息队列 MQ ,MQ 最大的优势在于:异步和解耦,MQ 模式还有一个优点:当流量激增时,消息队列还可以起到消峰的作用。
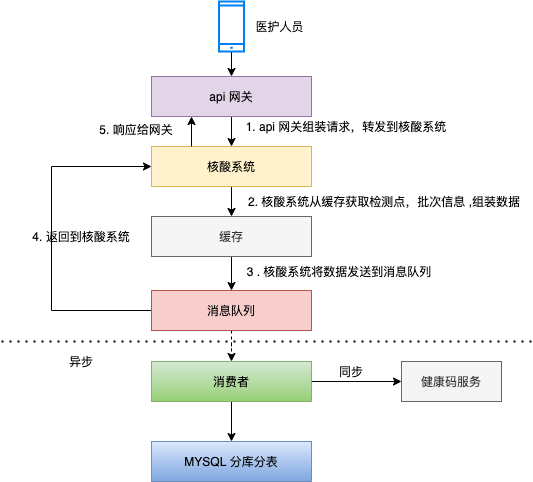
MQ 方案里,核心流程如下:
医护人员扫市民的健康码 ,核酸登记的请求发送到 api 网关 ,api 网关将请求转发到核酸系统;
缓存存储检测点,检测批次等基础信息,核酸系统通过缓存判断业务请求是否合法,若合法,则组装真正的入库的数据;
核酸系统将检测记录发送到消息队列,返回给前端响应成功;
消费者接收消息后调用分库分表中间件将数据插入到数据库 ;
消费者接收消息后同步状态到健康码服务。
在架构设计中,并不是引入了组件就完事了,更需要考虑如何精准的使用组件。
比如,使用消息队列 kafka ,如何保证不丢消息,如何保证高可用。使用了分库分表中间件,是不是需要考虑数据异构,以及冷热分离等。
四、监控平台
我们经常讲:研发人员有两只眼睛,一只是监控平台,另一只是日志平台。
在对性能和高可用讲究的场景里,监控平台的重要性再怎么强调也不过分。
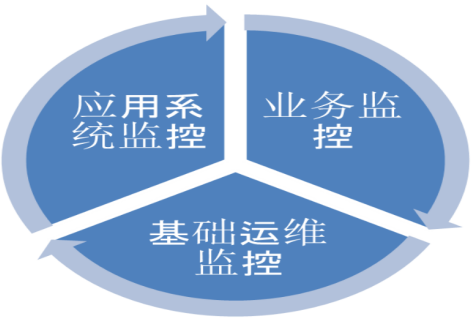
1、基础运维监控
基础运维监控负责监控服务器的 CPU、网络、磁盘、负载、网络流量、TCP 连接等指标,并且通过设定报警阈值实时通知指定负责人。
基础运维监控
我们在基础设施层这一节里提到:
核酸系统崩溃时,成都政务云不能提供畅通的核酸检测服务 , 可能原因之一是政务云机房问题。
当政务云机房出现问题时,基础运维监控可以帮助运维人员更快的发现问题,并制定解决策略。
2、应用系统监控
应用系统监控是研发人员接触最多的一种监控类型,系统出现瓶颈的时候,应用系统监控会有最直观的体现。
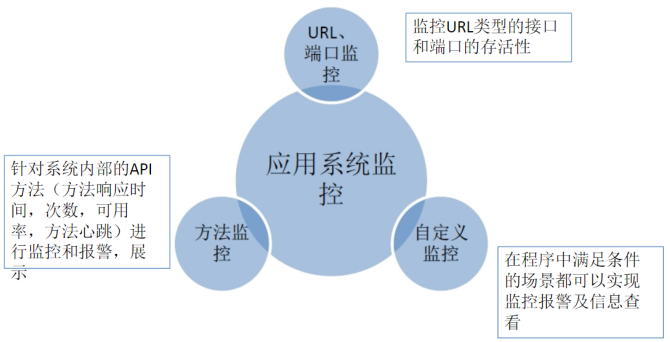
笔者一般会关注性能监控,方法可用性监控,方法调用次数监控,JVM 监控这四大类。
性能监控
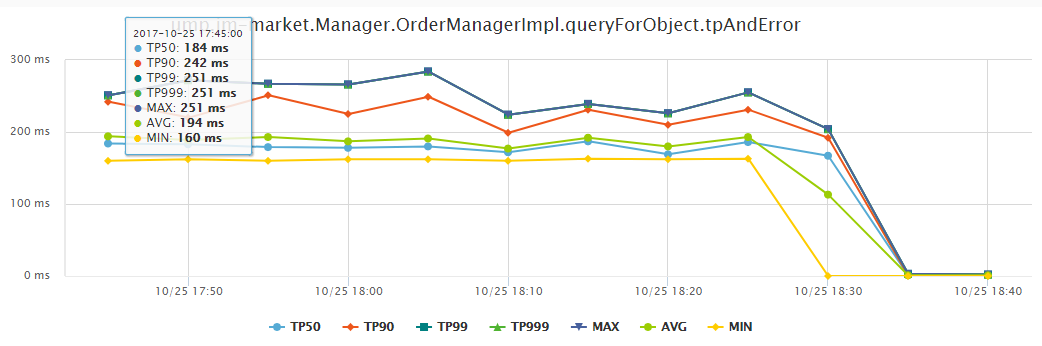
性能监控
性能监控不同时间段性能分布,实时统计 TP99、TP999 、AVG 、MAX 等维度指标,这也是性能调优的重点关注对象。
方法调用次数监控
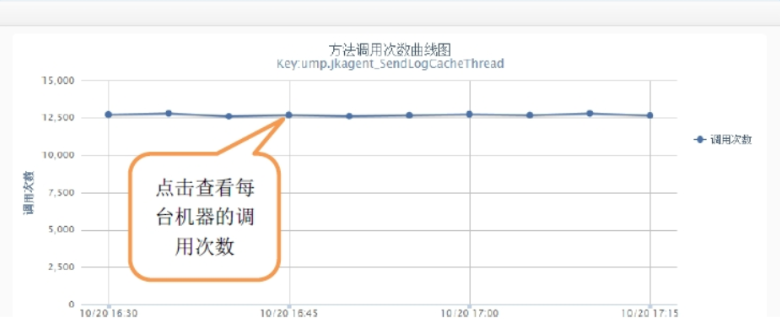
方法调用次数监控可以按照机器,时间段分析接口或者方法的调用次数,当大流量来袭时,可以清晰的看到请求的波动。
方法可用性监控
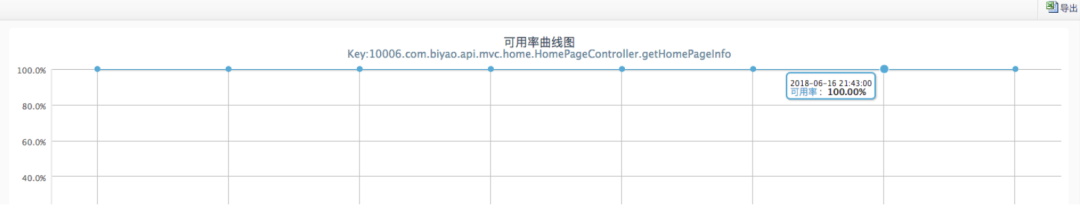
方法可用率监控
方法可用性监控是指:当接口被调用或者方法被执行,可能返回异常或者方法执行抛异常,分析该方法是否调用正常,当系统出现严重问题时,方法可用率是一个重要的参考指标。
JVM 监控
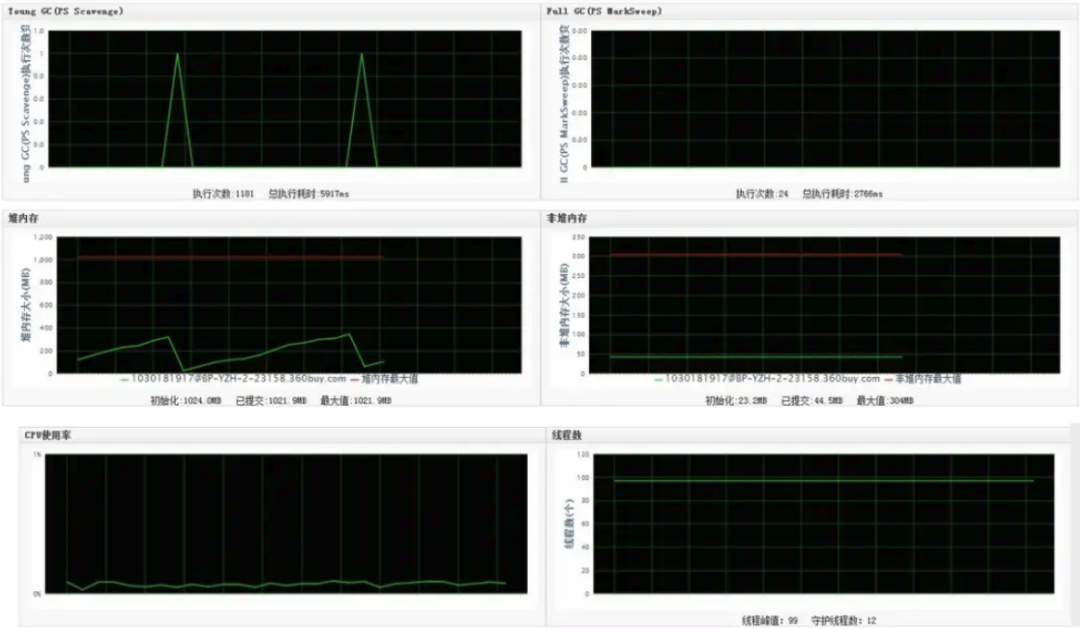
JVM 监控
JVM 监控是 JAVA 工程师特别关注的监控类型,我们会重点关注:堆内存,GC 频率 ,线程数等等。
3、业务监控
业务监控功能是从业务角度出发,各个应用系统需要从业务层面进行哪些监控,以及提供怎样的业务层面的监控功能支持业务相关的应用系统。
具体就是对业务数据,业务功能进行监控,实时收集业务流程的数据,并根据设置的策略对业务流程中不符合预期的部分进行预警和报警,并对收集到业务监控数据进行集中统一的存储和各种方式进行展示。
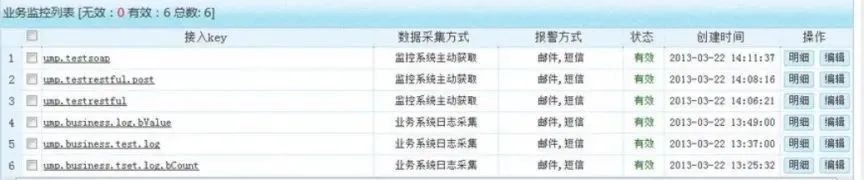
比如订单系统中有一个定时结算的服务,每两分钟执行一次。我们可以在定时任务 JOB 中添加埋点,并配置业务监控,假如十分钟该定时任务没有执行,则发送邮件,短信给相关负责人。
五、多方协作
很多同学都指责东软失职:“核酸系统在仓促上线之后,到底有没有进行完备的性能测试 ”。
确实,性能测试非常重要,通过压测可以知道系统的极限值是多大,当系统承受不住访问时,就会暴露出瓶颈,如服务器 CPU、数据库、内存、响应速度等,从而促使研发团队进行再优化。
这里我们先按捺指责的冲动,核酸系统是一个多方协作的系统,它不仅直接和政府有关系,还涉及到多个厂商,一个系统工程背后,除了系统集成商之外,包括多个分包商。
《核酸检测系统崩溃,东软该不该背锅?》这篇文章提到:
原则上,监督管理部门要把所有厂商叫在一块协同作战。但没有顶层统筹的强压之下,厂商之间的沟通和协调很难达成。大多数情况之下的压测,各个厂商有点“各自为政”的意思。一般,软件厂商会自己测试自己,鲜少几家联合起来测验。“不同厂商坐在一起的时候,大家都觉得自己没有问题,都会觉得是别人的问题。理由也会一致,我们的系统在别的地方跑过,没出岔子"。甚至应对这一局面,各家的心思都极为微妙。“每个厂家在系统上的投入都是一笔不菲的开支,在应急状态之下,如果上面领导没表态,也没明确是公益性质还是有偿的付出,厂家相应选择也是谨慎的。” 因此大多数情况之下的压测,各个厂商有点“各自为政”的意思。一般,软件厂商会自己测试自己,鲜少几家联合起来压测。
这篇文章的一个观点,“这是技术层面之外,一个城市应急预案的管理能力问题。” 我深以为然。
六、总结
假如我是核酸系统的架构师。。。。
我会使用消息队列 + 分库分表来最大程度提升系统的吞吐量。
我会在使用消息队列中间件的时候,重点关注如何不丢失消息,消息系统如何做到高可用。
我会使用分库分表中间件时,重点关注冷热分离,如何将数据异构到数据仓库。
我会在政务云部署监控系统,提供基础运维监控,应用系统监控,业务监控的能力,当系统出现问题时,团队可以以最快的速度发现问题,并解决问题。
可是,核酸系统是一个多方协作的系统,我们不仅需要和政府沟通,也需要和众多三方厂商协作。
也许,当我提出需要更多服务器预算时,政府部门的预算并不充足,或者就算充足了,走流程也要一个月的时间;
也许,当我提出需要部署监控系统,公司会以人力不足为由或者政务云硬件资源不足,否定我的方案;
也许,当我联调时发现一个三方接口速度慢,排查起来(沟通成本)需要 4-7 天时,我也不得不沉浸在琐事中;
直到最后,当系统崩溃时,我也只能叹息到:“尊重技术,尊重专业”。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721