

分享概要
一、数据一致性核对的背景与困局
1、背景
缺少高效易用的工具/平台能在第一时间发现业务与数据问题、能实现快速接入业务实时校验。
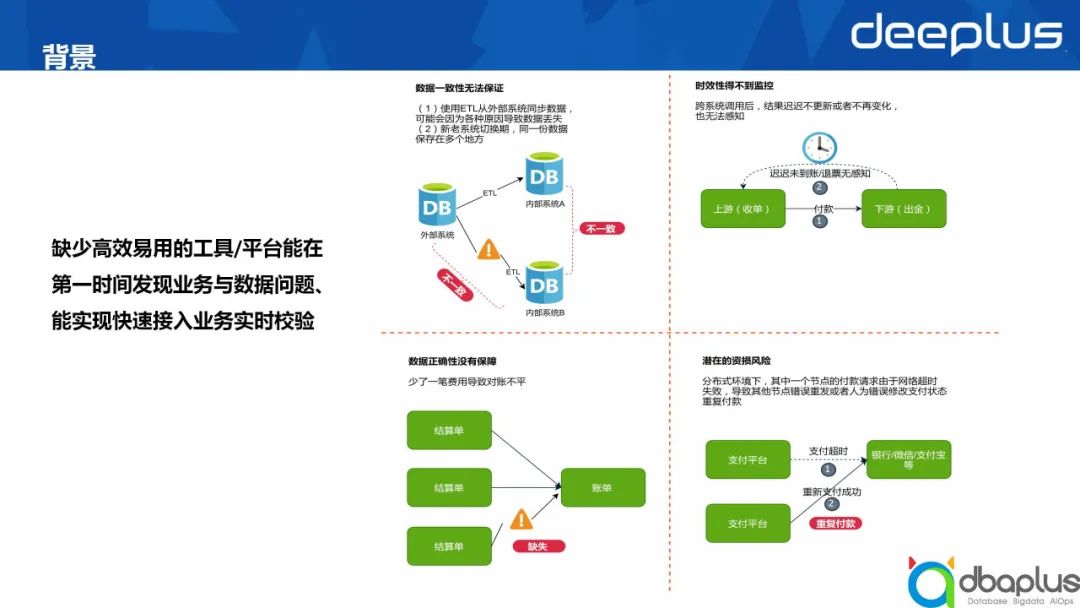
2、困局
1)关注不到位
影响数据一致性、正确性和时效性的因素非常多,再严谨的设计都无法避免人/物的出错。
严重依赖内部流程自检和业务反馈,不主动做跨系统明细级别的检查。
2)解决难度大
大多出现数据问题的场景隐秘,没有一定经验的专业人员不易发现和解决。
传统大数据量下的核对思路是使用大数据组件来解决,比如:使用hive的表join、flink的流join等。执行复杂、时效性低、成本相对高。
二、业务一致性核对平台概述

图 1-业务一致性核心平台功能架构
业务一致性核对平台针对离线和实时数据,提供不同的核对方式。“使用简单”是平台建设目标之一,下图描述接入步骤:
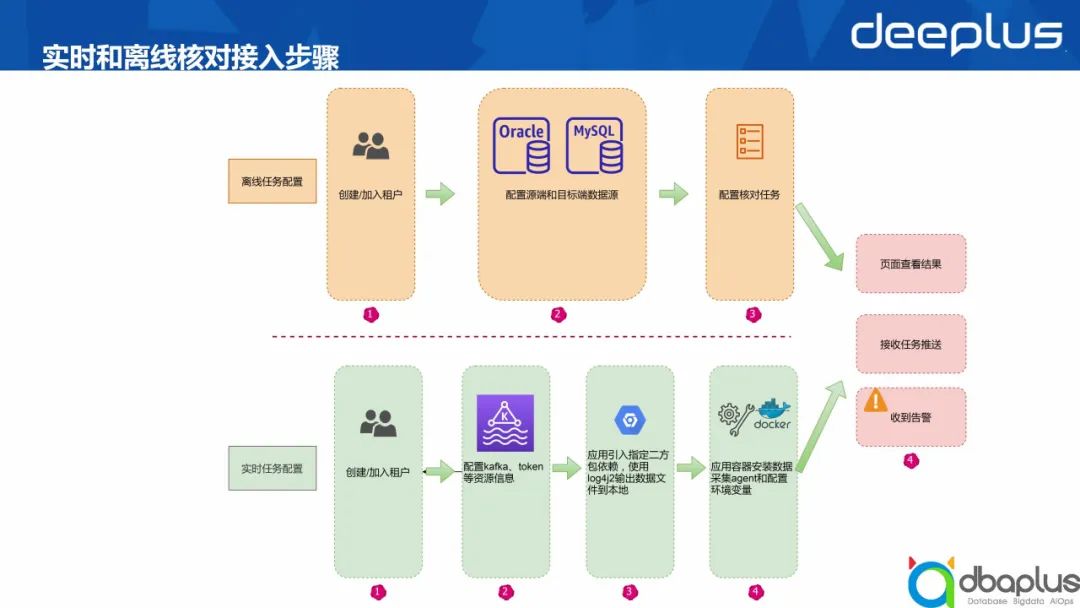
图2-业务一致性核对平台接入步骤
三、实时数据核对系统设计
1、设计目标
低侵入:业务接入方便、改动小、无异常影响、极低性能影响。
低延时:数据上报延迟控制在秒级。
高吞吐:满足业务高峰期间核对需求。
实时告警:告警检测高度灵敏。
主动熔断:实时向业务平台发送熔断信号。
租户隔离:避免不同流量下的租户数据相互影响。

图 3-实时核对架构
1)第一阶段
数据先从上游使用flume-agent采集后,通过mq上传到实时核对接收模块并放入redis缓存中。缓存数据结构采用zset,报文作为元素(member),时间作为分数(score)写入zset中保存。
2)第二阶段
下游数据产生并按照同样的方式上传到核对模块内部。先使用完整报文去上游缓存中匹配,如果找不到在根据业务指定唯一键检索缓存队列(zscan模式迭代寻找)。
3)第三阶段
根据下游匹配结果,产生“核对通过”、“疑似差错”、“确定差错”三种结果。
4)第四阶段
根据差错告警规则,决定是否通知用户。
2、实时核对异常应对
1)case1:下游先于上游到达
如果下游数据中的事件时间和当前时间差值很小,使用同步锁的方式迭代zset,避免大量zscan操作导致redis cpu飙高。
下游写入暂存队列时上游刚好到达。
当下游数据在“上游暂存”队列中找不到id相同的记录时,会写入“下游暂存”队列。这个“get then set”的操作会和上游数据到达时先查询“下游暂存”队列,不存在则写入“上游暂存”队列的“get then set”操作可能同时发生。可以使用同步锁来解决。
2)case2:上游数据消费速度远远快于下游
导致上游redis缓存队列积压“溢出”,此时需要降低上游flume agent发送频率或者停止消费上游kafka队列消息。
3)case3:过期移出
上下游暂存队列可能出现一直未被匹配移出的情况,这时候需要定时移出写入时间最早的N个记录,并持久化到差错记录表中。同时定时执行差错重对。
3、实时核对性能
1)吞吐量高
采集端通过采集本地磁盘文件数据后批量上送到kafka,中间基本不涉及数据转换(转换流程在业务应用中)。
2)核对速度快
在上游暂存队列积压100w数据量下,下游核对耗时:
完全通过2s
差错4s
四、10min千万级离线数据核对系统设计
1、大数据量核对思路
分块checksum
归并比较
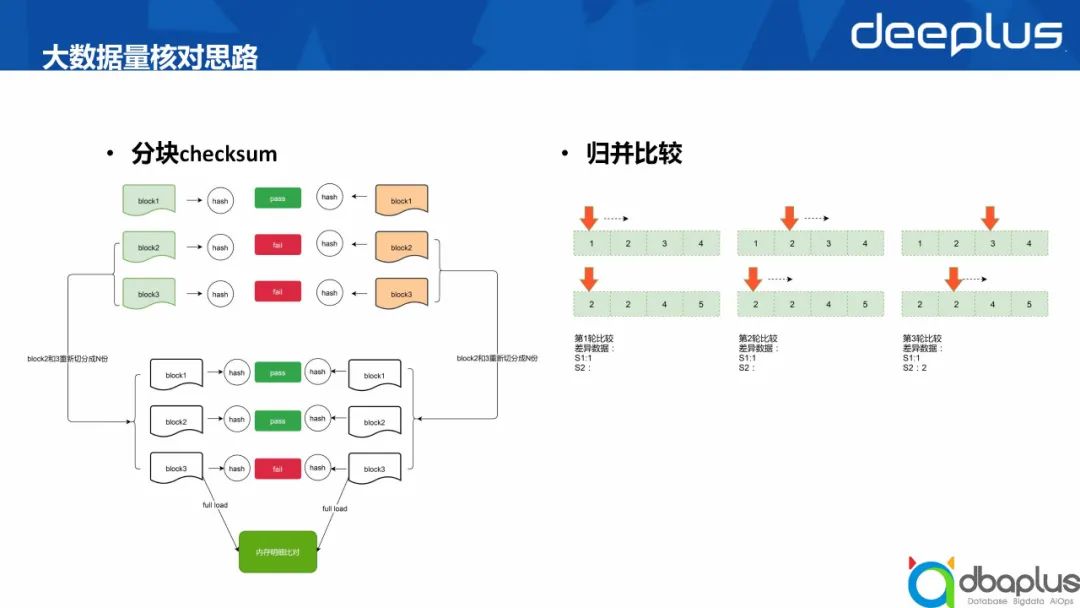
2、方案对比
1)分块checksum
优势:完全一致时checksum的速度最快。
不足:a.性能不够稳定 b.需要设计可靠的顺序无关的checksum算法。
2)归并比较
优势:性能相对稳定,实现上也相对简单很多。
不足:
a.需要先排序
b.排序耗时最短可以是O(NlgN)
c.比较耗时是O(N)
结论:从实现难易程度和时间稳定性方面考虑,最终采用基于归并比较的方式实现。
3、离线核对1.0

图 4-离线核对1.0架构
使用流读的方式,从数据库中快速查询返回经过排序后的数据,在内存逐行比较。
注意:只需要两边数据源各读一行记录即可比较,无需所有记录在内存中再核对(回看归并比较图解)
核对结果中,只对存在差异的记录进行落地保存。
1)离线核对1.0特点
① 核对速度快
针对mysql driver使用stream result set方式读取;oracle等支持游标通过设置一定大小的fetch size,能保证在10min内完成千万级的数据核对及差异落地。
② 告警实时性高
kafka 0.10.x之后支持流计算,基于其中滑动时间窗口DSL实现的实时告警,能保证触发时延小于1s。
③ 支持自动拆分任务
通过解析一端的核对sql,找到第一个唯一键的数据分布,拆分成多个查询sql,对应改写另一端的sql,进而拆分成多个核对子任务,实现更大量的数据核对。
2)离线核对1.0存在的问题
只支持mysql协议和oracle协议的数据库,适用性过于狭窄。
需要在业务库中排序,排序键过多且数据过大时会导致业务库内存消耗过大且导致二级索引失效。
字段映射只能通过sql函数实现,增加db压力且专业性过高(希望懂一点点sql的产品也能使用)。
4、离线核对2.0
1)目标
突破数据源类型限制
源端性能影响降到最小
2)大体思路
数据先查询回应用本地后,然后在本地排序,再基于本地有序数据做归并比较。
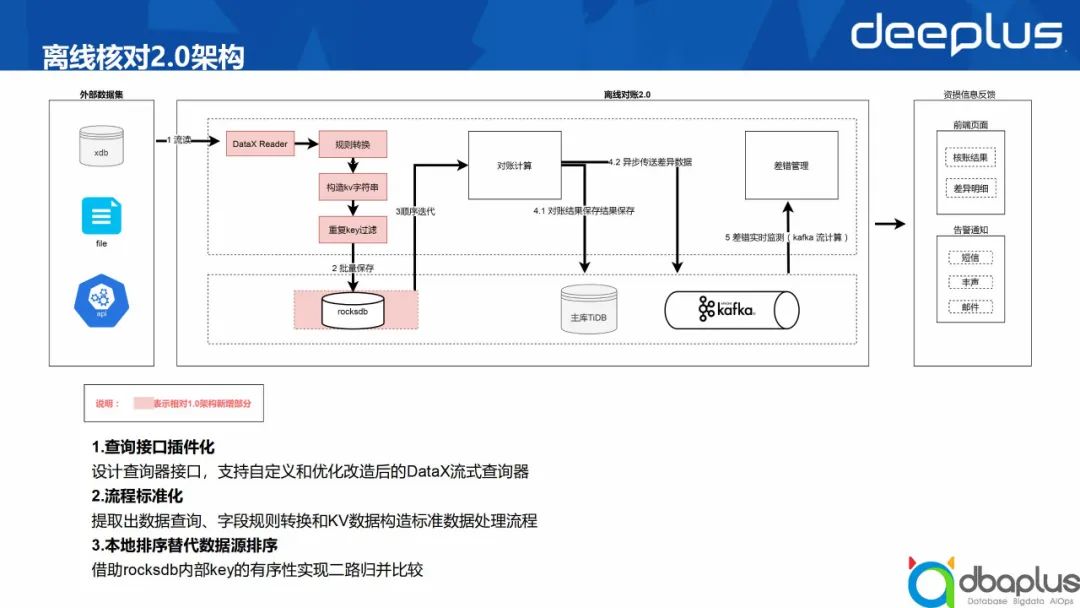
图 5-离线核对2.0架构
3)优化点
查询接口插件化
设计查询器接口,支持自定义和优化改造后的DataX流式查询器。
流程标准化
提取出数据查询、字段规则转换和KV数据构造标准数据处理流程。
本地排序替代数据源排序
借助rocksdb内部key的有序性实现二路归并比较。
5、RocksDB是什么
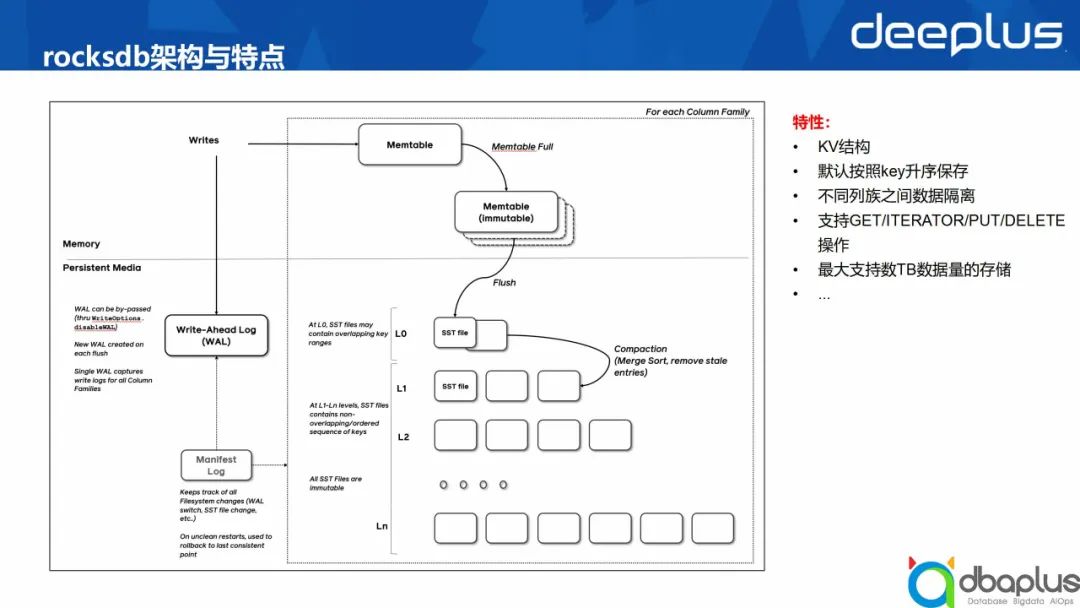
图 6-rocksdb架构
1)特点
KV结构
默认按照key升序保存
不同列族之间数据隔离
支持GET/ITERATOR/PUT/DELETE操作
最大支持数TB数据量的存储
......
6、RocksDB在2.0中的应用

图 7-数据在rocksdb中的结构
1)具体设计方案
每个应用节点上的任务共享一个RocksDB实例(一个目录),不同任务数据使用列族隔离。
源端和目标端的数据各用一个列族(column family)存储,命名:{taskId}_{0/1}。
行转kv:key=k1,k2.... ; value=o1,o2,o3....
单独一个列族存储唯一键重复的记录,并且在每个key后边添加自增id避免再次冲突。
通过在内存上加一层布隆过滤器,提前过滤肯定不重复的“key”(绝大部分),疑似重复的再查询一次RocksDB确认,提升重复键检测性能。
2)对RocksDB的优化调整
取消WAL日志,降低磁盘消耗和压缩日志带来的CPU消耗,宕机任务自动失败。
取消内置布隆过滤器,使用自定义的(应用层基于历史任务预估写入数据量创建的布隆过滤器更加准确和高效)。
限制整个RocksDB最大写入缓存使用,降低堆外内存溢出风险(部分版本rocksdbjni有缺陷)。
7、离线核对2.0带来的突破
1)更容易支持多样数据源
通过拆解Datax Reader,兼容数据核对流程,利用开源的力量支持更多样的异(同)构数据源间两两核对。
2)降低对业务库的影响和要求
1.0让数据在用户的业务库中排序后,再在平台中“归并”比较。2.0引入RocksDB,让数据在平台内(LSM的SST有序性)排序后再通过迭代“归并”比较,极大降低业务库内存消耗(内存排序)和解除对特定数据源的限制(之前要求必须支持order by asc)
3)支持任意形式的数据API
由于不需要数据源支持order by,所以核对数据源不再局限于数据库,而是任意可以获取数据的API(数据库、接口、文件、mq等) 。
双边各1000W数据核对依旧能保持在7分钟内。
五、50亿数据同步经验分享
1、背景
业务平台A需要在支付时,查询财务凭证数据,而这些凭证数据保存在系统B中。凭证数据情况如下:
存量超过50亿(两表关联后),需要拉取字段约70个;
日增(新增/更新)量500w-1500w;
使用oracle存储。
2、同步方案
1)整体步骤
先做全量迁移,记录起始时间T1和结束时间T2。
等全量迁移完成后,再做增量迁移,增量时间起点是T1。
进行数据核对。
2)全量同步任务切分
以业务日期(yyyyMMdd)字段budat作为切分条件,先以年为界限分成2005-2021共计7个任务{job1,job2,job3,job4,job5,job6,job7},不同job并发执行。
每个job再以“天”为切分条件,分成356个实例task{task1,task2,...,task365},task串行执行。
3)增量同步任务
使用更新时间update_time作为查询条件,配置定时10分钟调度任务,每次同步范围是update_time between t-15 and t-5,t的初始值是T1。
当一个调度时间nextScheduleTime > now()的时间,[T1,now()]内的增量数据已经全部同步完毕!
4)数据一致性检查任务
和全量任务相似,用budat作为条件每次核对1天数据,直到下一个调度时间大于当前时间则停止。
增量核对任务改成每天核对T-1的增量数据。
3、经验总结
分治
找到能使数据拆分(相对)均衡的字段,以该字段为核心继续细分数据直到单次任务的耗时可接受。
如果倾斜严重,可以多选择几个字段或者改成where k=xx and hash(k)%N = n
顺序
先全量,再增量。因为历史数据是可能被修改的,如果刚好全量同步任务和增量任务对查询到同一条记录的不同版本,可能会出现写入冲突或者旧版本数据覆盖性版本数据等情况
增量范围
增量任务的起始时间一般要比全量任务早几分钟
增量任务的截止时间小于当前时间,避免由于上游(一般拉从库)主从延迟过高导致数据丢失
数据核对是必要的
Q&A
Q1:多租户下集群资源怎么隔离及分配,怎么保证任务高峰时间任务的稳定运行?后续会考虑支持Yarn调度吗?
A1:保证任务高峰时间任务的稳定运行有几种方式:实时核对mq每个租户独立主题,缓存空间也独立;离线核对是共享,因为cpu承担主要压力;离线核对的任务会依赖自行实现的均衡调度算法,让每个节点的资源消耗相对均衡。后续是否使用Yarn还在评估。
Q2:数据实时同步场景下怎么核对明细数据一致性?比如MySQL实时同步进MongoDB。
A2:首先,不建议在实时同步的情况下核对最近的热点数据,但是可以过滤相对稳定的状态数据,比如:“成功”、“失败”、“完成”等;其次,离线核对可以支持异构数据源之间的核对。
Q3:这么多校验任务是否会将线上库查挂?
A3:每次核对只会创建一个核对任务,是否定时核对取决于用户,所以多校验任务不会将线上库查挂。
Q4:数据实时同步,上游数据可能随时发生变化,有没有办法找到一致性时间点,然后做数据核对?
A4:不建议在实时同步的情况下核对最近的热点数据,但是可以过滤相对稳定的状态数据,比如:“成功”、“失败”、“完成”等。
Q5:数据同步如果是带时间字段,发现现有数据时间大于同步过来的时间,就直接丢弃同步过来的数据,可行吗?
A5:这一做法有风险,可能会导致核对漏数的情况。
Q6:数据在本地排序,再进行归并比较,是否会大幅占用本地内存?
A6:不会大幅占用本地内存,数据在本地排序并进行归并比较具体依赖的是RocksDB的实现性能。
Q7:使用stream resultset数据库长连接着有没有影响?
A7:目前尚未发现对源系统有较大影响,具体情况可以关注一下DataX的使用问题。
Q8:实时核对中一侧数据长时间未到达,这种情况该怎么处理?
A8:如果一侧数据长时间未到达会触发过期淘汰策略,记为”疑似差错”并落库,后续定时进行差错重对。
Q9:大数据场景下支持先group后sum、count之类的聚合函数吗?
A9:是否支持此类聚合函数与数据源有关,与数据核对无关。
Q10:用了DataX就能保证数据一致性?
A10:DataX只是ETL工具,并不是数据一致性校验工具,但是DataX会记录同步出错数据。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721