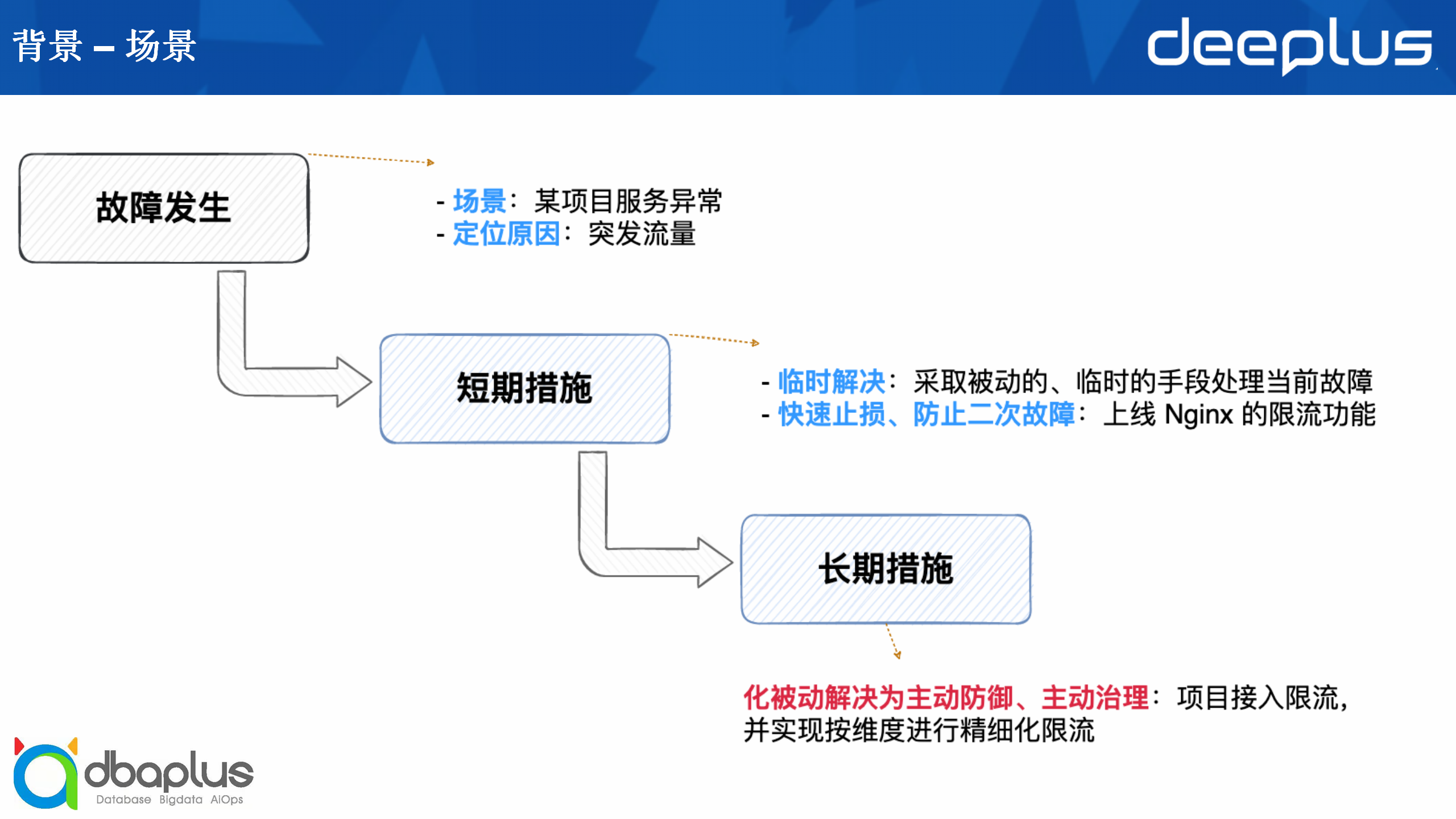
某一天有一个项目服务突然出现异常,我们定位到的原因是有大量的突发流量进来,那么我们会先采取被动的临时手段去处理当前故障,接着上线Nginx的限流功能进行快速止损,防止二次故障。但是Nginx的限流功能是比较粗糙的,所以我们有一个更好的长期措施,即项目接入限流功能,并实现按维度进行精细化的限流,化被动解决为主动防御、主动治理。对于这一个项目来说,做到这一步应该是比较好的效果。
那么我们能否更进一步?更进一步我们需要考虑经验积累、通用性、整体效益这三个方面。
-
经验积累:有什么经验总结可以被其他项目借鉴?
-
通用性:解决方案其他项目可以直接使用吗?
-
整体效益:可以降低团队的整体成本吗?
我们的方案设计需要考虑不同项目之间的差异性,因为我们需要接入的项目可能有十几个甚至更多,不同项目的差异性会体现在开发语言、请求类型、生命周期、部署环境、链路节点等方面。
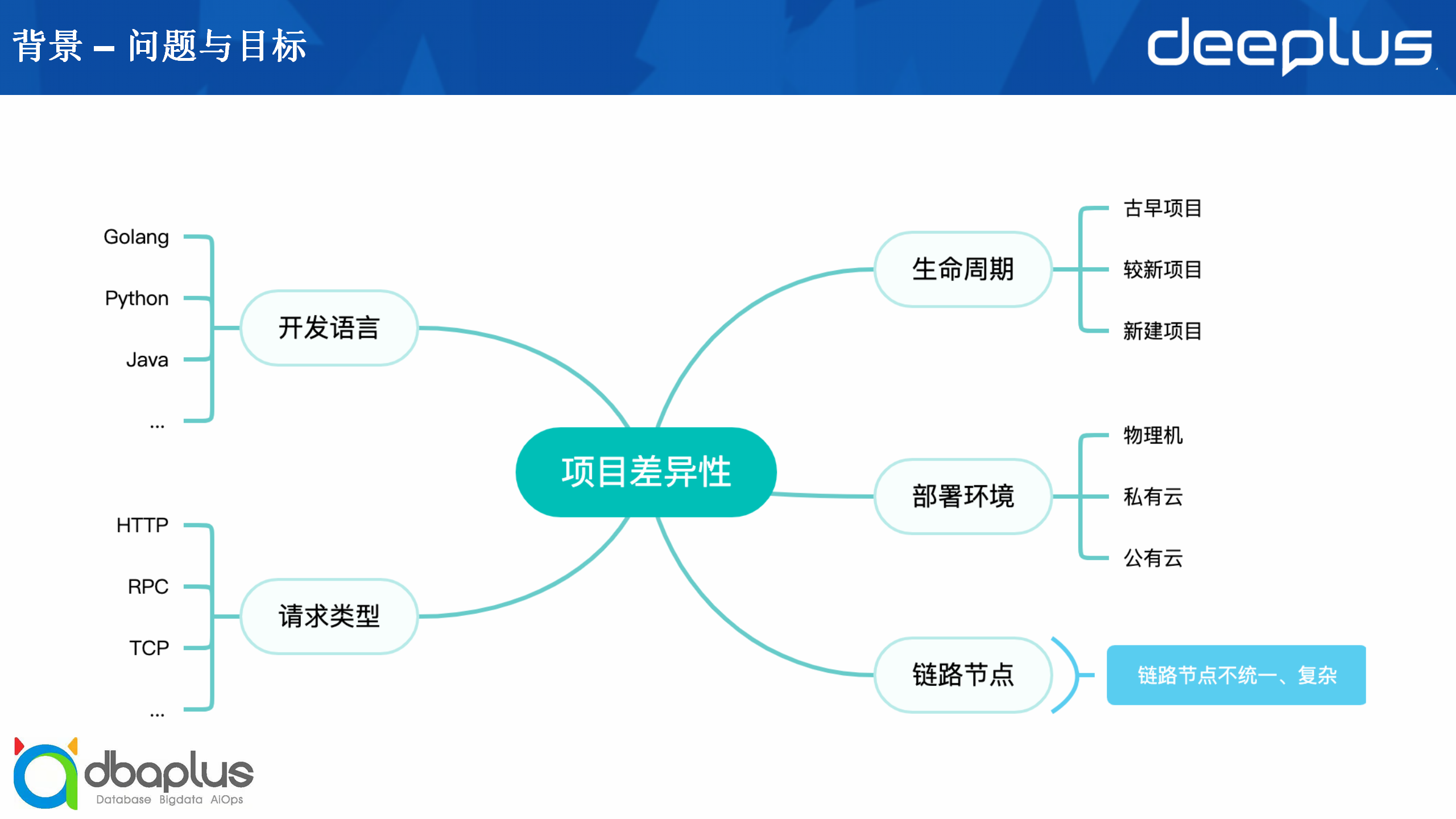
其中我们特别需要注意的是生命周期,有的项目可能是十几年前就存在的老项目,有的可能是最近两三年的较新的项目,还有的可能是以后会建立的全新项目,我们的方案需要能够同时匹配这三种项目,以及需要抹平其他的几种差异。
此外,我们的方案也有一些其他的期望目标,比如低成本、高效率、高质量,以及专业性、稳定性、可扩展性、高性能。
其他几点则比较好理解,那么摆在我们眼前的问题就是项目的数量多,差异性大,期望目标和要求也多,那么我们应该如何设计这个方案?
在介绍具体的技术方案之前,我简单讲述一下我们的协作方式。
在公司内部推广一个技术落地,我们通常会采用单项目的方式进行,即单独某个项目了解需求、设计、开发,在本项目落地之后再逐步推广到其他项目,这种方式虽然没有问题,但是存在几个缺点:
基于以上情况,我们设计了一个专业组机制,希望能够让专业的人做专业的事,工作流程如下:
首先从多个有需求的项目组里招募感兴趣或者有经验的成员加入专业组,比如图示里从项目组1、项目组2和项目组3里各抽出一个人成立专业组,然后针对这几个项目设计总体方案,以满足他们的需求,在项目落地之后,再逐步推广到其他项目。
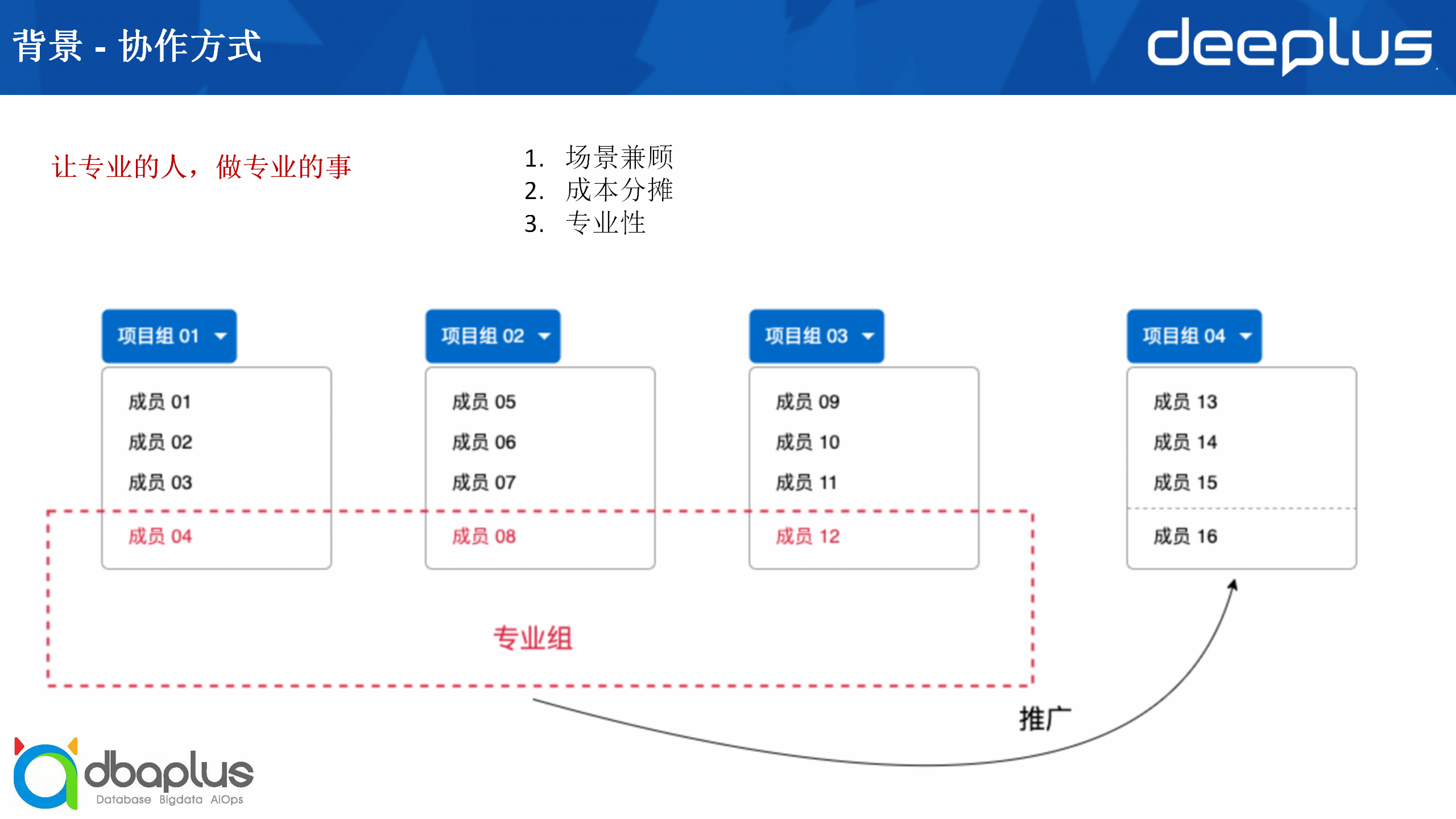
与单项目推进相比,专业组机制的优点如下:
在解决现有功能上,专业组在整个过程中发挥了很大的作用。
下面我们介绍具体的技术方案。
首先的问题是我们的限流应该做在哪一层?一般来说我们可以在应用层限流,也就是在API服务节点再增加一个web中间件,在请求进入API服务时判断请求是否被限流,这是比较常见的方式,对于单个项目而言成本也是最低的。
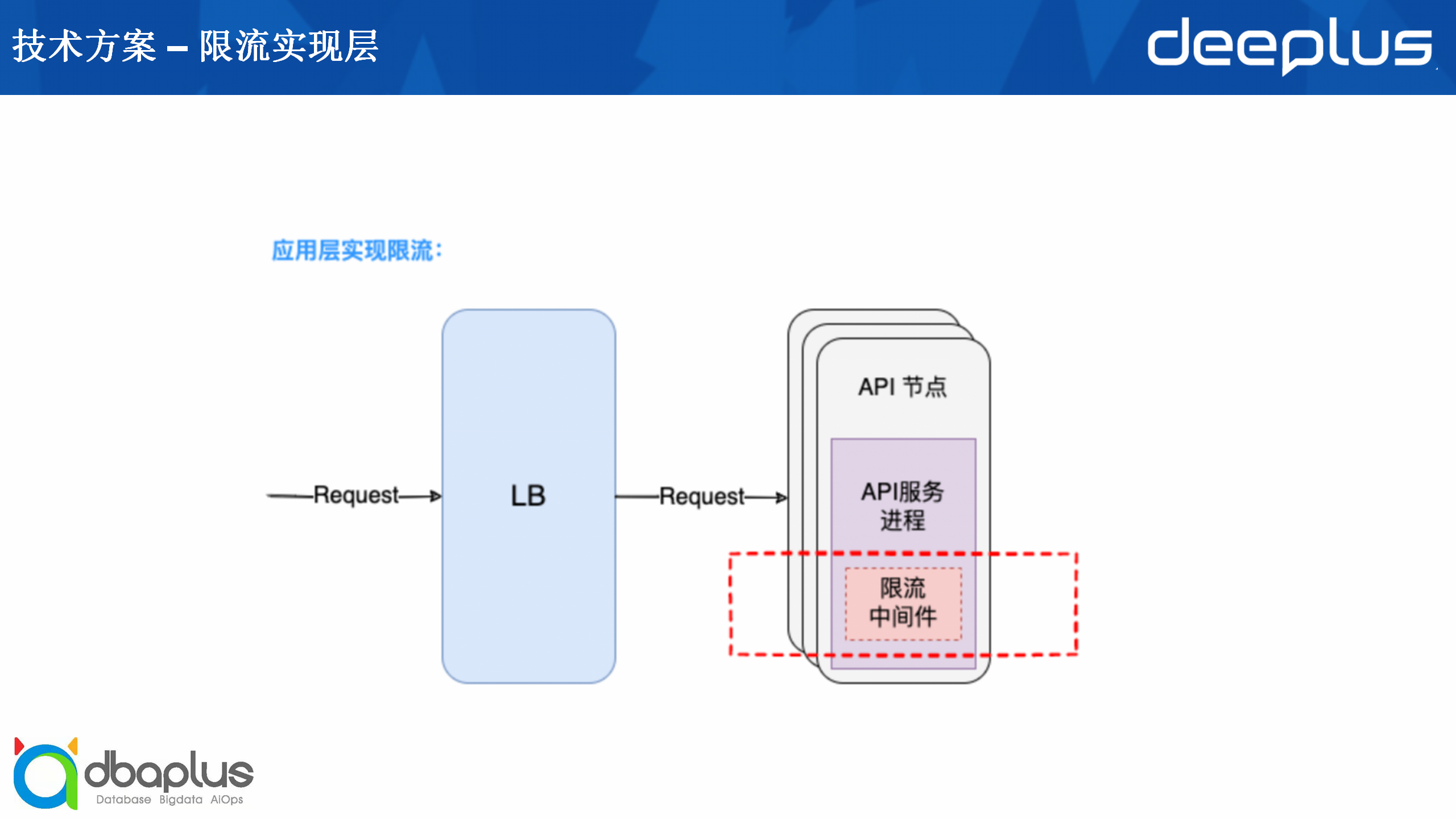
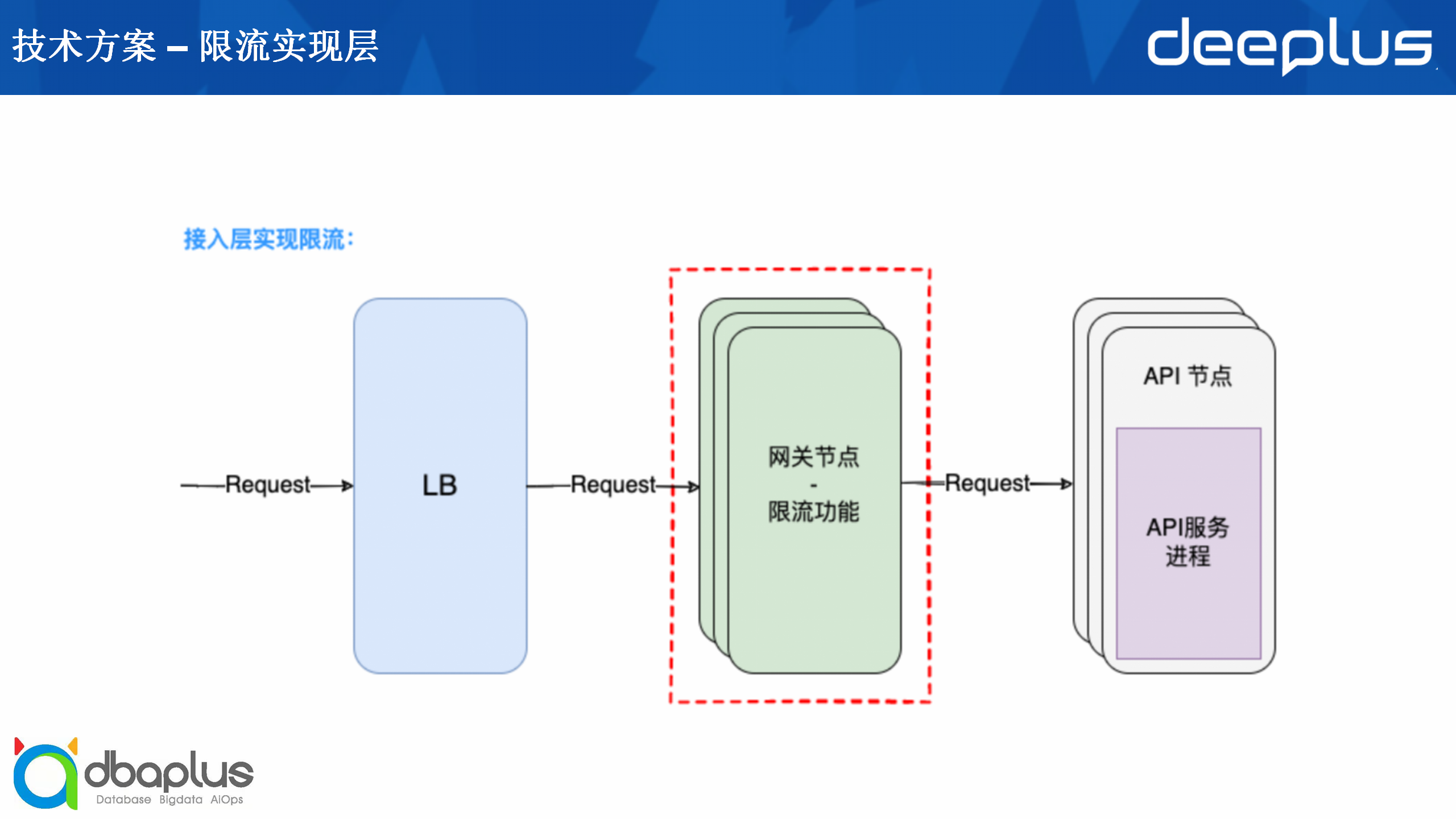
除了应用层实现限流之外,还有接入层实现限流的做法。在原先的LB到API节点之间,我们可以增加一个网关层,将限流功能做在网关层。
两种方法相比较,应用层限流有以下缺陷:
基于以上情况我们选择了接入层实现限流。在接入层实现,我们就需要一个网关作为统一的记录层。
按照官方的说法,Kong网关是一个轻量、快速、灵活的云原生API网关,Kong是基于OpenResty和Nginx实现的。我们在解决这一个问题的情况下,为什么要选择Kong?也是基于我们常见的高性能、高可用、灵活、易扩展等方面。其中我们特别在意以下两点:
Kong的插件机制可以支持多种语言,如Golang、Lua、Python、JS。我们选择了Lua和Golang作为我们的开发插件。两种之间的区别是Lua插件在Kong进程中是直接执行的,也就是它和Kong是同一个进程,而每一个Go插件是一个单独的插件,和Kong主进程之间的通信需要通过IPC进行。
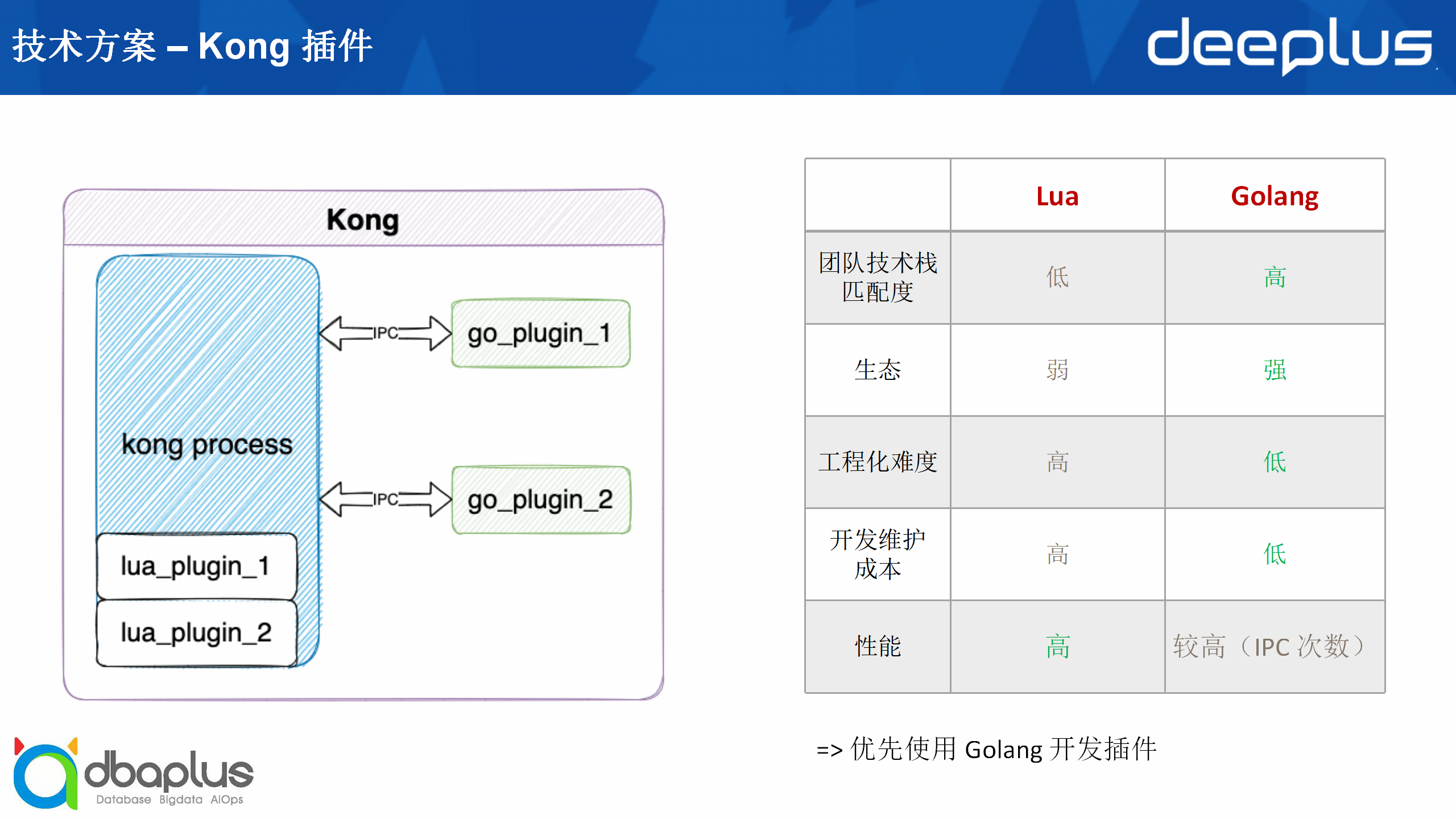
Lua和Golang相比较,在团队技术栈匹配度、生态、工程化难度、开发维护成本上,Golang都占有比较明显的优势,而在性能方面Lua会更高。因为Golang在插件每次执行的时候都需要进行IPC通信,在IPC通信次数较高的情况下,性能会受到较大影响。但是我们在实践过程中发现,在现有场景下,我们的IPC通信次数相对较少,对性能的影响也比较低。所以总体上我们是优先使用Golang开发插件,如果Golang实现不了再退而求其次用Lua进行开发。
前面我们通过把Kong作为接入层解决了不同项目在环境上的差异性,接着我们可以使用插件机制解决不同项目在需求上的差异性。
我们可以将一个项目的限流需求分为业务需求模块和限流功能模块两个部分。
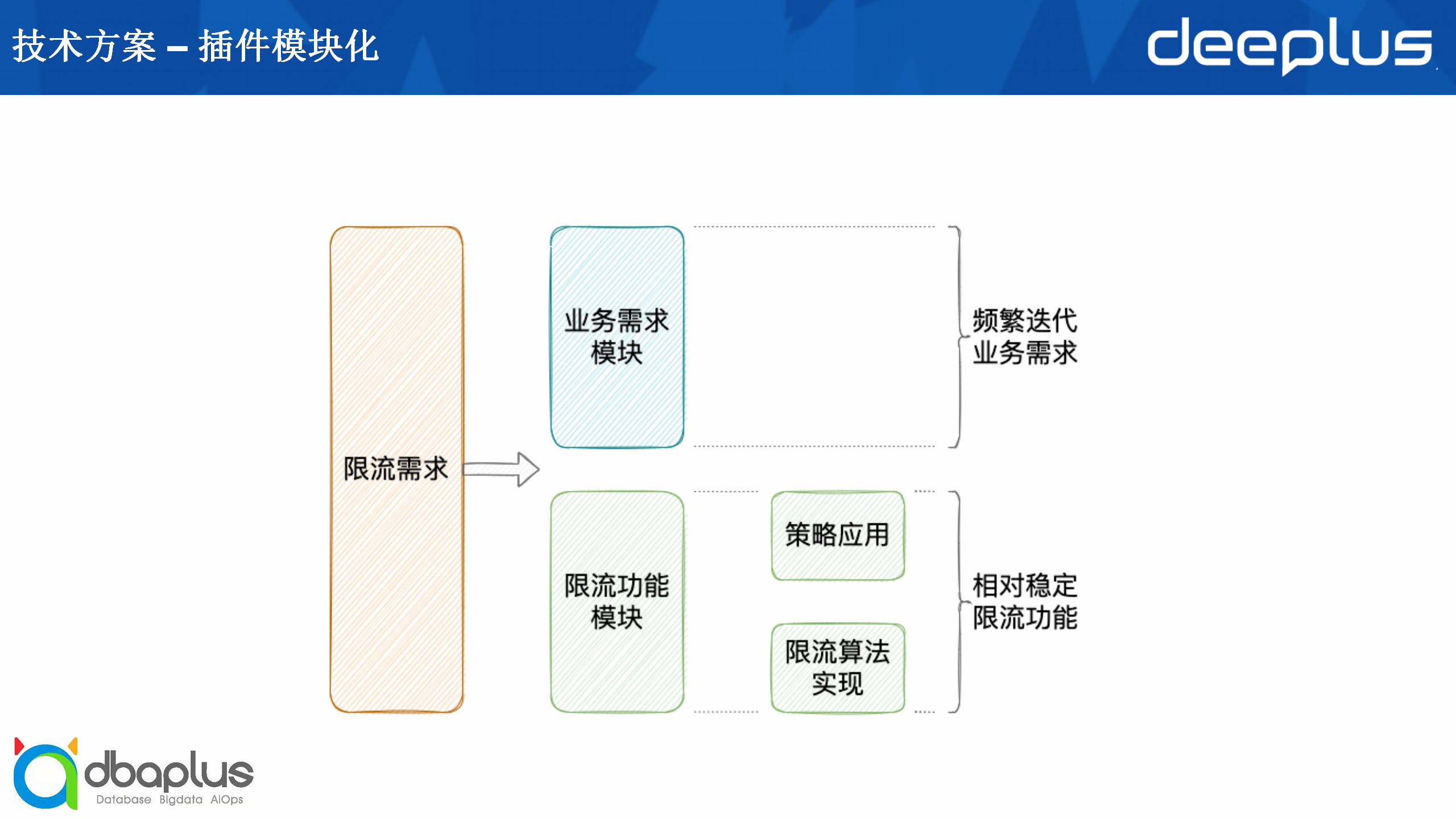
在具体的限流算法的实现之上,还有一个策略的应用,即对于同一个限流方法,比如令牌桶,我们可能会设计不同的策略进行应用。
基于以上模块划分,我们在实际开发时分了三层,从下到上依次是限流算法层、限流插件层、业务插件层。
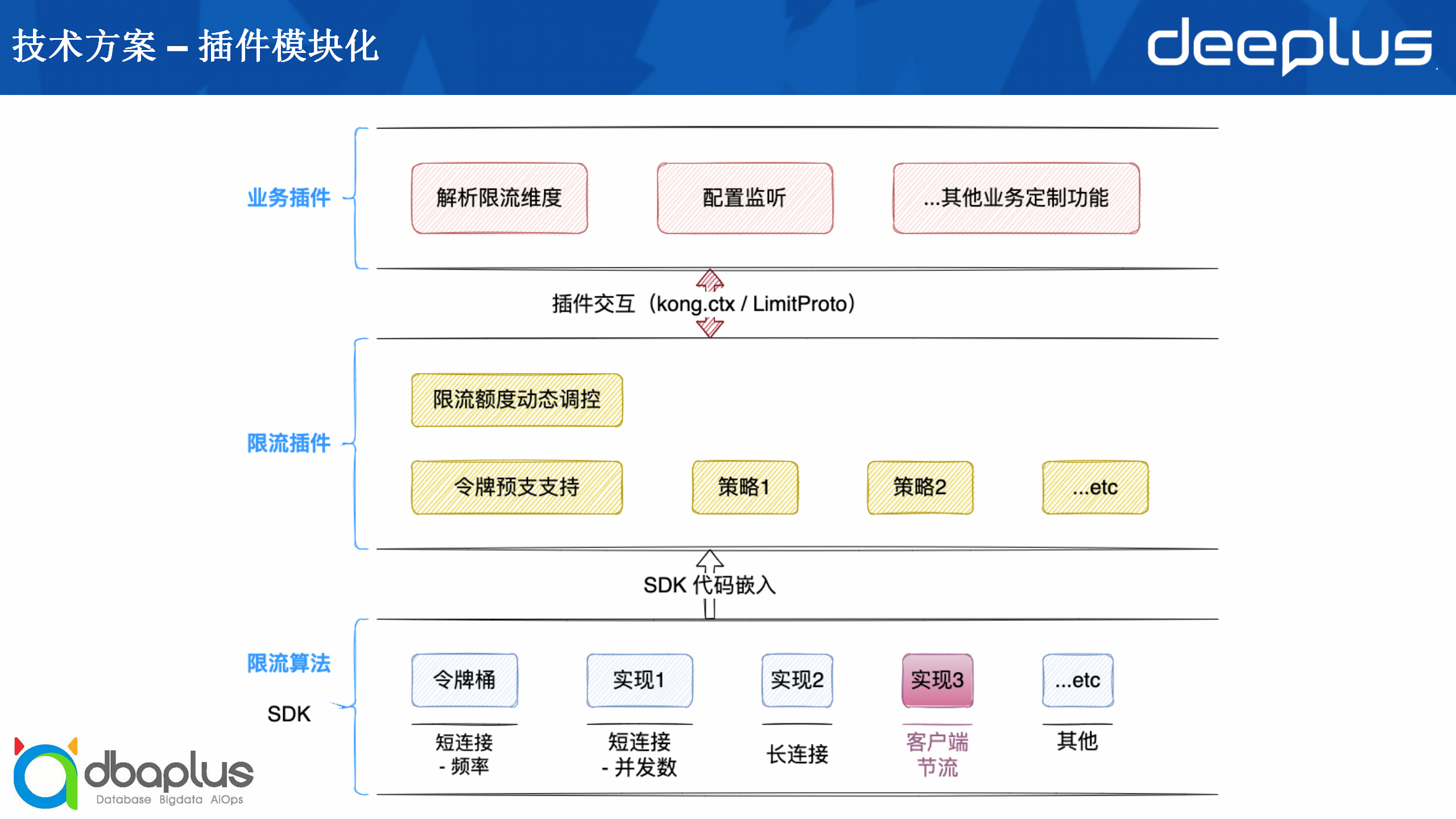
1)限流算法层
限流算法层主要是SDK的形式,因为我们的限流场景比较多,算法也不同,所以我们对于每一个不同的场景都会单独开发SDK,比如短连接限制频率的场景可能会有令牌桶或时间窗口等,短连接并发数、长连接也有具体的实现。
需要特别注意的是客户端节流的场景,我们在实际应用时发现,该场景除了接入Kong服务端性能之外,客户端请求时也需要进行限流。客户端限流指的是客户端主动发起请求调用第三方频率时,我们也希望能够控制频率,保护第三方服务。
限流算法的SDK是以代码嵌入的形式嵌入到限流插件层。
2)限流插件层
限流插件层会调用SDK,针对不同的场景需要设置不同的策略,比如我们的令牌桶限制短连接频率,一个插件可能会实现令牌预知功能,而另一个插件可能会做限流额度、动态调控等,也就是已经往业务层走了一步。
3)业务插件层
业务插件层会根据项目组不同的需求制定单独的业务场景,比如不同的项目组可能会有不同的限流维度进行解析,需要项目组自己适配等。
如配置监听,以及业务组的其他业务定制功能,也可以做在这一层。
我们的分层主要分为三层,实际Kong执行会有两个插件,分别是业务插件和限流插件,这里的插件指的是Kong本身自带的执行插件。

接下来以长轮询场景为例,讲述需要限制接入的客户端连接数场景。
首先请求进入Kong网关时,在业务插件我们会解析它的限流维度,比如user、path、method、ip,然后把这些维度生成一个字符串限流KEY,它可能是一个比较长的字符串。
接着它会匹配特定的限流策略,如果匹配不到则会进入兜底策略,把这些信息生成限流的协议数据。业务插件的配置会记录请求的维度,比如path、method等,匹配到了限流策略之后,就会去生成它的限流协议,限流协议里会设置请求最大并发数、请求超时时间等。接着业务插件会把这些信息组装成一个协议,协议的格式如图右下角。
然后把这些数据通过Kong的Context机制传递到限流插件,限流插件则会解析该协议数据,然后执行限流逻辑判断,来判断这个请求应该被限流还是透传到上游服务。
项目组的需求,如果已有的插件可满足,则直接使用;如果不满足,可定制自己的业务插件。定制插件时项目组只需要关注项目需要的业务逻辑即可,相关的生态已由专业组提供,专业组负责所有限流插件、部分通用业务插件的开发,网关、插件公用功能开发,搭建安全性、稳定性保障,以及不同场景下的限流算法的设计实现等工作。插件开发完成后提交到插件库,后续其他项目组若有相同的项目,也可以直接使用。
接下来我们简单了解一下插件的分发与使用机制。
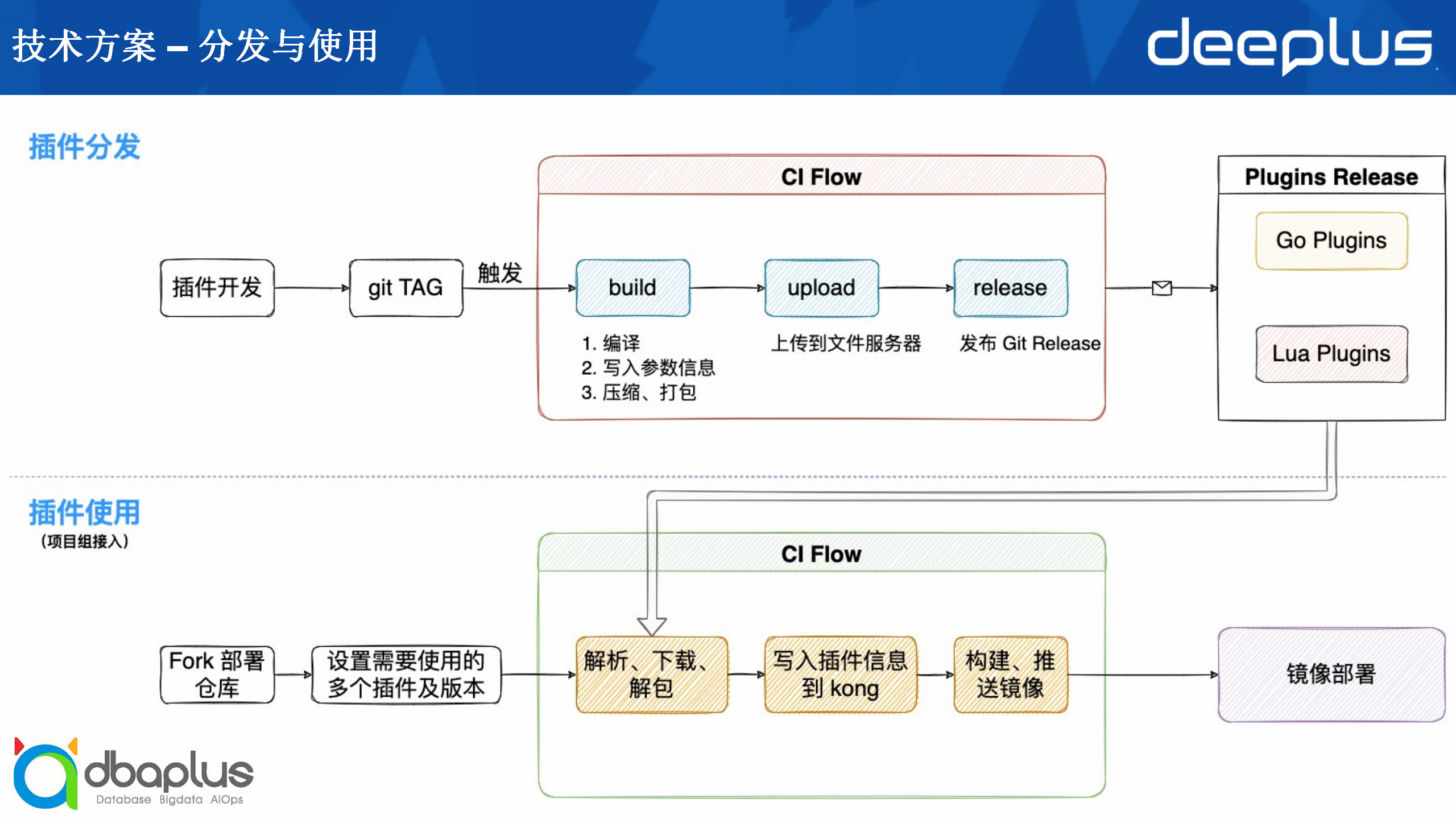
首先插件开发完成之后,我们会在GitLab上给它打一个tag,然后触发一个CI流程。CI流程做的工作主要是编译、写入参数信息、压缩打包,把插件打包成一个tag压缩文件,将其上传到文件服务,再发布到git release界面,那么项目组使用时就可以在release界面看到我们可以使用的插件及其功能。
而项目组在具体使用的时候,需要Fork部署仓库,然后设置需要使用的多个插件及版本。接着再去触发CI流程,我们会把插件重新下载回来,并且进行解析、解包等工作,然后把这些插件和它们的信息写入到Kong里,将其构建、推送成为一个完整的镜像,有了镜像之后,我们就可以在部署平台上进行部署,那么项目组就完成了Kong和插件的使用。
接下来简单介绍项目组实际的接入方式。前面我们提到项目组的差异比较多,因此我们分了5种情况:
1)如果是一个全新的项目,则直接接入。
2)现存项目,但是没有网关,那么主要考虑业务场景,整体评估之后再进行接入。
3)现存项目,且已有Kong网关,这种情况下直接安装和使用我们的限流插件即可。因为我们开发的插件也是Kong的标准插件,项目组使用限流插件时只需要对接其限流协议。
4)现存项目,且已有其他网关,那么就不能使用Kong网关了,直接对接限流算法的SDK即可。
5)客户端限流的情况下不需要Kong网关,也是直接对接客户端限流的SDK即可。
该方案的整体结构是比较简单的,便于适配不同的项目。
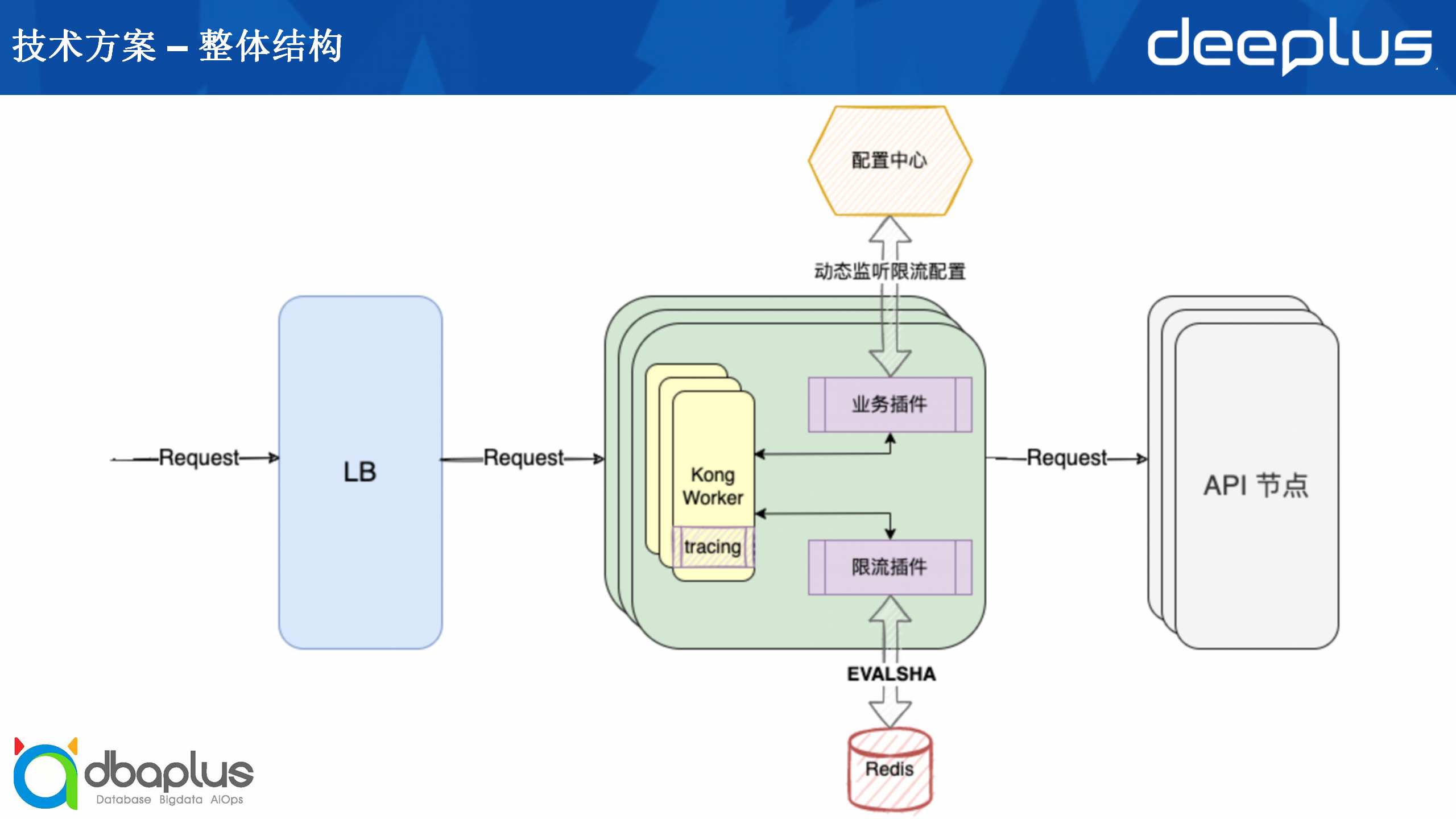
总体而言就是在LB和API节点之间加了一个Kong网关,网关方面首先我们会插入一个tracing插件,这个插件内嵌了Open-Tracing的实现,接着项目组根据自身需求选择业务插件和限流插件。
业务插件有一个功能是动态监听限流配置,需要外部的配置中心实现。动态监听主要是考虑到当有异常流量进来时,我们可能需要动态调整额度,比如场景可能是原先给该项目定的额度已经不能满足其需求了,该项目最近的用户量猛增,那么在这种情况下,我们不能限制它的流量,因此需要将额度调大,避免对业务造成不好的影响。
限流插件根据不同限流算法的实现,我们也有不同的依赖,比如我们在大部分情况下都会做分布式限流,我们选择通过Redis加一个Lua脚本实现分布式限流,那么这种情况下依赖还需要增加一个Redis。也有少部分情况下它可能是作为一个本地限流,需要根据项目组的具体实现。
实施方案指的是一个项目组从0接触到整个方案完成上线的过程,前期包括需求、评估和开发这几个步骤。
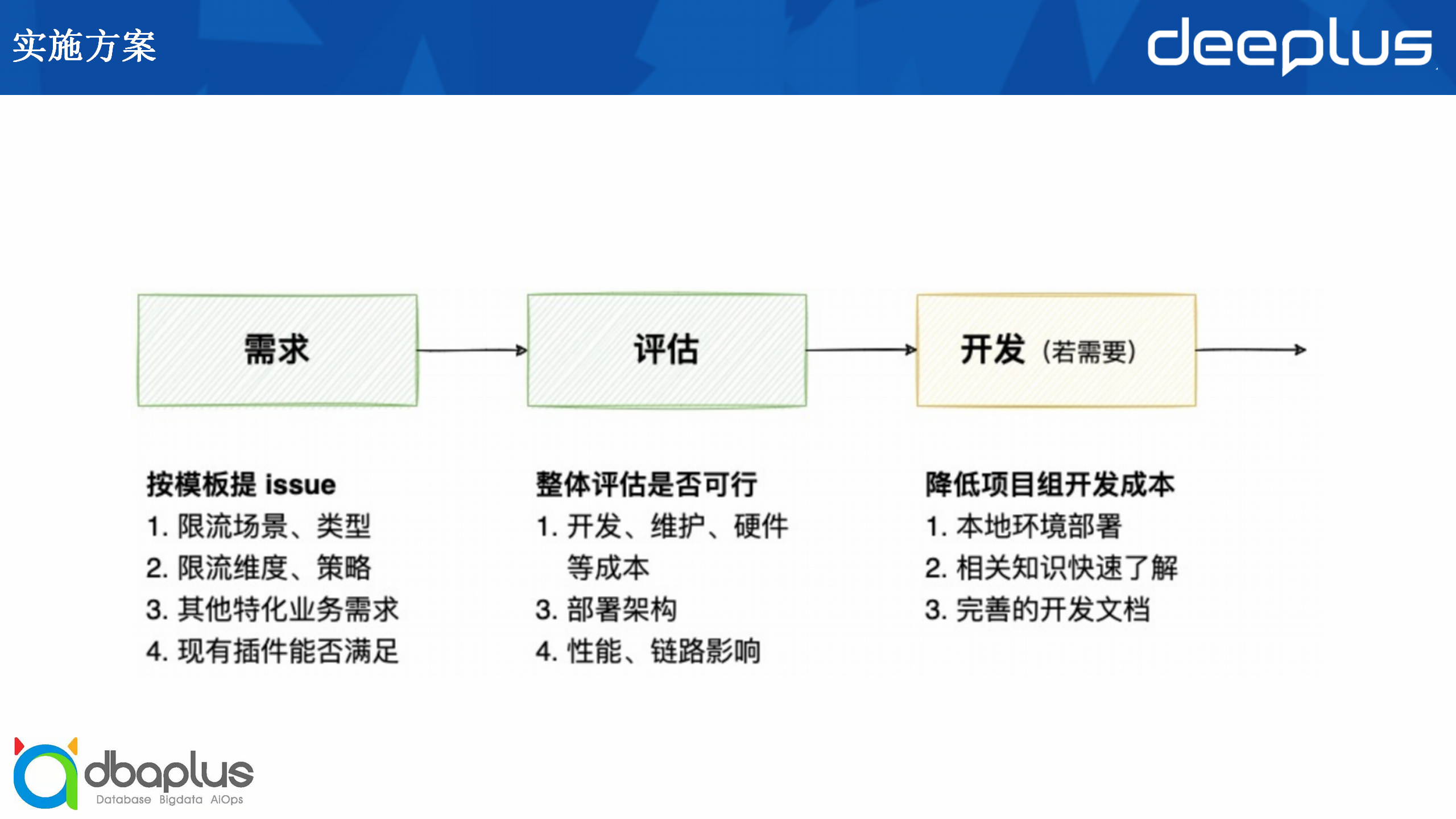
在需求阶段,项目组根据我们提供的模板提issue,里面会包含以下内容:
-
限流场景、类型
-
限流维度、策略
-
项目组需要特化的业务需求
-
现有插件能否满足项目组的需求
接着进行整体的评估工作,评估的方面包括:
-
开发、维护、硬件等成本
-
部署架构
-
性能、链路的影响
如果我们现有的插件无法满足项目组的需要,那么就需要进行开发工作。对于开发工作,我们有一个比较详细的指南,因此上手开发的成本比较低。项目组需要了解以下几个方面:
接下来是测试、部署与上线的环节。
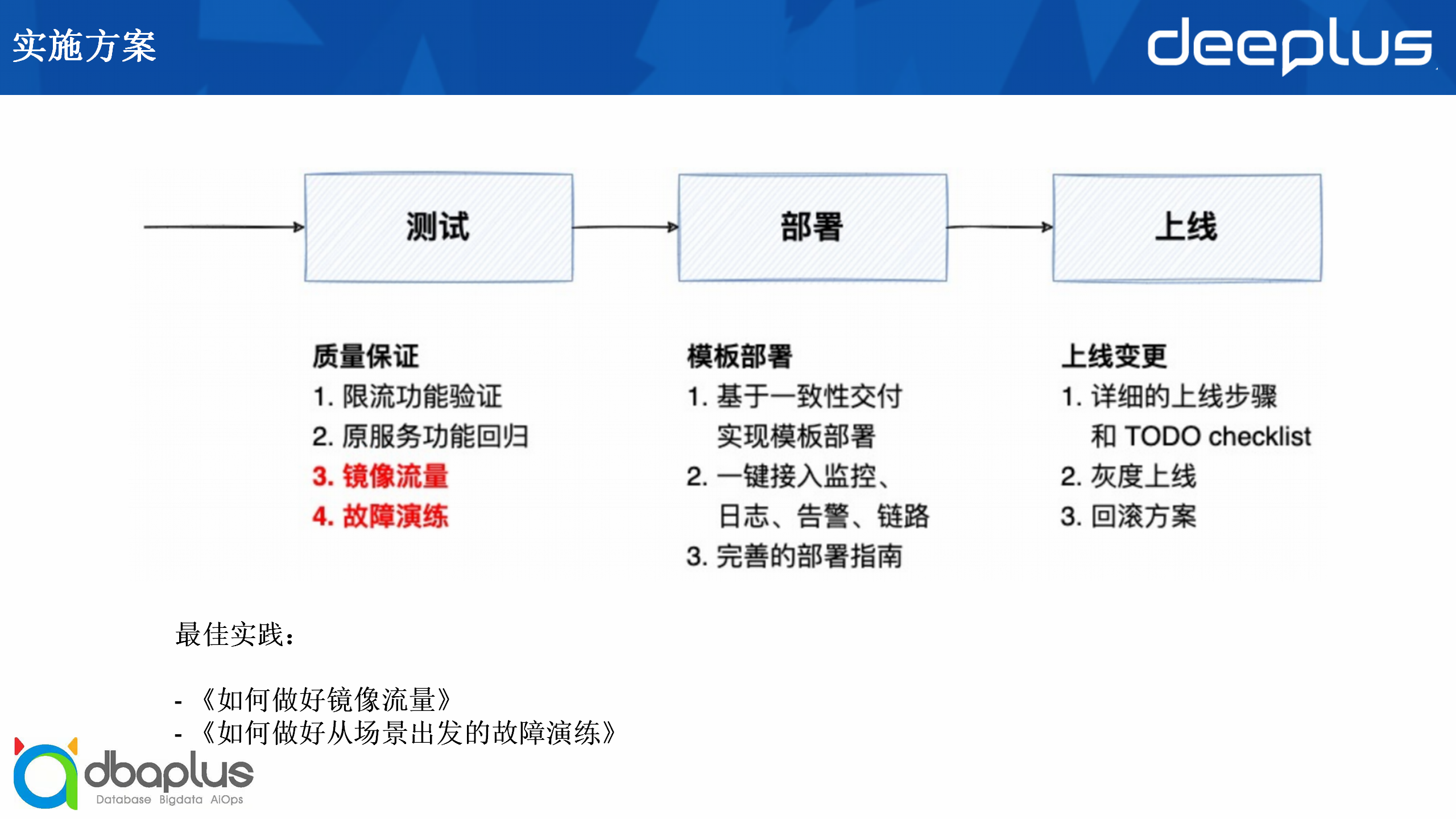
在测试环节我们的目的是需要保证接入Kong和插件之后的质量。
镜像流量和故障演练对于我们而言是比较重要的。
关于这两点,我们内部有两个最佳实践说明,分别是《如何做好镜像流量》和《如何做好从场景出发的故障演练》。
接下来是部署环节。
最后的步骤是上线,我们也提供了详细的上线步骤,以及checklist和最重要的灰度、回滚的技术方案。
总体而言我们这几个环节也达到了手把手指引、实现的整个过程。
前面我们提到的目标是低成本、高效率、高质量这几个方面。
1)开发成本:项目组对接时基本上是0成本,或者只有少量的开发工作。
2)维护成本:后续的维护、升级工作都是由专业组负责的。
3)硬件成本:主要的是Kong的集群部署,根据项目组本身的流量大小,可以部署不同的副本数。如果选择了分布式限流,那么还需要部署一个Redis,我们一般建议部署一个新的Redis,但是为了节约成本也可以和原先项目已有的Redis共用。
1)接入时间:我们在项目实践时,最快的接入时间是三天,三天是在项目组没有自己定制化的需求,不需要开发的情况下走完我们之前介绍的环节,即评估、测试、部署、上线。
2)硬件配置:我们有一个推荐配置,也就是根据我们不同的流量进行单独测试,以及我们提供了比较完整的性能测试数据作为参考。
3)高效部署:网易内部的平台相对完善,借助于我们的CI自动化、配置管理系统、容器云系统和一致性交付系统可以实现高效部署。
4)文档建设:文档建设我们是比较完善的,从刚开始接触限流这套方案到上线的整个过程中各个环节,我们都有很详细的文档指引,遇到问题可以从文档中寻找,也可以找专业组的同事了解。
1)技术支持:由专业组的同事提供技术支撑。
2)多样场景:我们的插件机制适配了多样化的限流场景和业务需求。
3)经验复用:在各个项目对接和使用过程中的经验或优化的问题,都可以总结复用,因为我们不同项目使用的是同一套技术体系,便于积累经验。
4)自定扩展:我们虽然定制化了一些插件,以及一些Kong的部署过程,但是在实际开发时也考虑到了Kong原生态的兼容性,也就是项目组依然可以使用Kong原生态提供的丰富功能。
5)运维体系:接入了整套运维设施相关的功能体系,也就是前面我们提到的监控、报警、日志等。
6)充分验证:我们的插件功能和性能得到了充分的测试,上线流程也比较完善,可以保证我们的可靠性。
通过以上环节可以保证服务限流方案的低成本、高效率和高质量。










如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721