
俗话说,能用钱解决的问题都不是问题。
一、从「AKF扩展立方」说起
在上一篇文章,我们从「服务维度」学习架构师的常用能力——微服务设计与治理。围绕着微服务生命周期的七个阶段,总结了常用的16条原则。其中原则15在微服务服务治理实践中非常重要,本文将重点进行拆解分析。
原则15:参考「AKF扩展立方」模型,服务除了「水平扩容」外,还可以考虑「功能拆分」或者 「数据分区」。
所谓AKF扩展立方体(AKF Scale Cube),是一个描述从单体应用到一个分布式可扩展架构的模型概念。
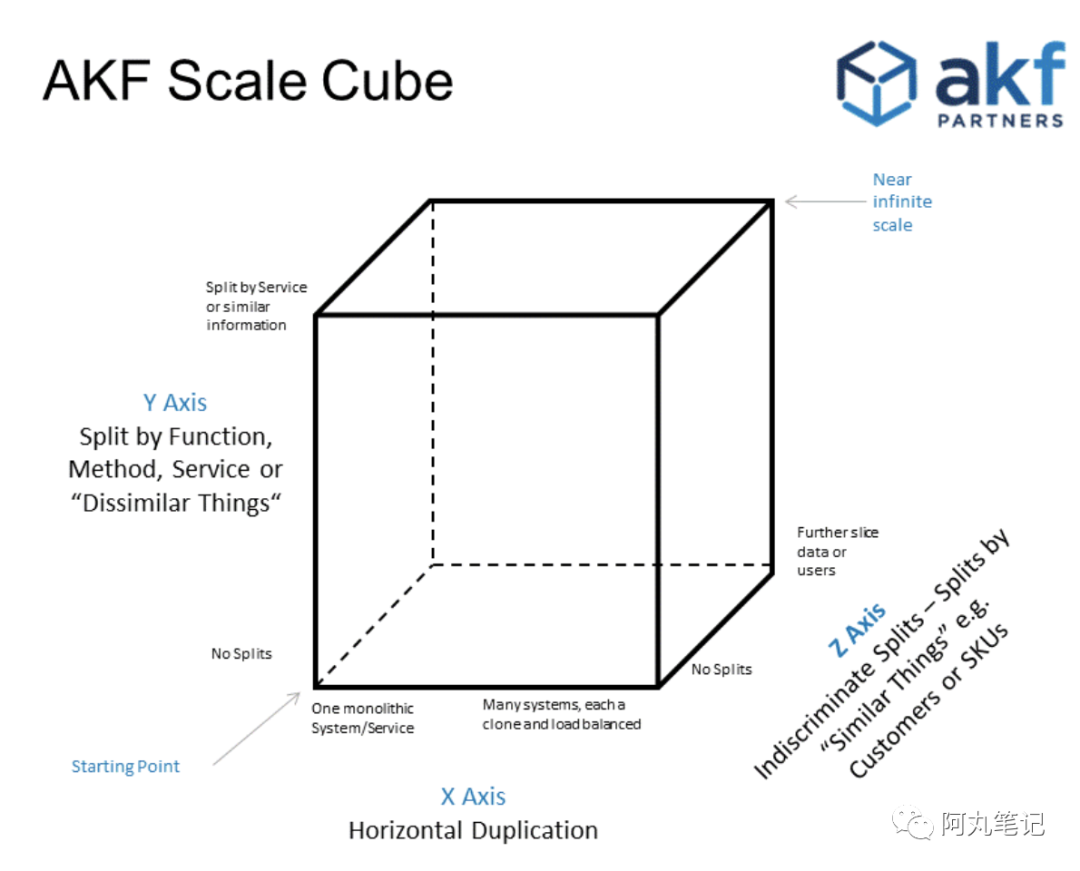
X轴:服务和数据的水平扩容
Y轴:功能/业务拆分
Z轴:沿客户边界的服务和数据分区
「水平扩容」比较容易理解,就是我们常见的操作——加机器。
根据AKF模型,面对服务负载升高的情况,其实除了加机器外,我们还可以考虑「功能拆分」或者 「数据分区」。
二、Y轴扩展的常用模式
「Y轴扩展」相对复杂,我总结了几种模式:
1)微服务拆分。根据具体业务模型、领域模型拆分更细粒度的微服务。
2)业务隔离拆分。利用消息队列,将在线业务(OLTP)和耗费大量资源的计算任务拆分隔离。
3)核心与非核心隔离。对于一个微服务,可以将SKA客户与普通客户进行隔离,SKA客户使用独立的集群资源,提高稳定性。
1、微服务拆分
某个微服务负载过高,一个非常常见的原因就是这个微服务承担了过多的职责。这个时候,我们需要根据具体业务模型、领域模型拆分更细粒度的微服务,也是我们常说的「垂直拆分」。
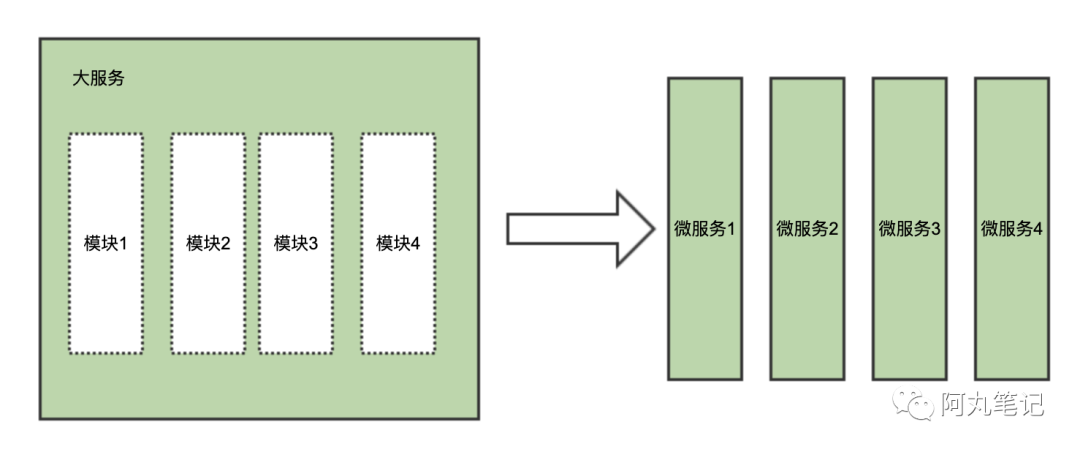
最典型的拆分方法论就是按照领域驱动设计(DDD)进行拆分。
以电商领域为例,按照领域可以拆分为:
用户服务
商品服务
订单服务
评价服务
其他

系统按照领域拆分为多个微服务后,各个微服务由单独的团队负责整个生命周期的维护,单独部署运行。
这种隔离拆分的方式,能带来以下优势:
提高整体系统的负载能力
各个微服务间具备独立扩缩容、故障隔离等能力
2、耗时任务隔离拆分
「Y轴扩展」除了按照领域进行服务拆分之外,另外一种非常重要的拆分方式,是将在线业务(OLTP)类型服务中「耗时任务」进行隔离拆分。
我们服务一般会采用Tomcat或者Jetty部署,同时采用同步调用的方式。以Jetty为例,默认线程池最大线程数为200。如果请求中有耗时任务,影响了同步请求的RT,那么线程池满后就会阻塞请求。
正如利特尔法则(Little's law)表述的:
在一个稳定的系统(L)中,长期的平均顾客人数,等于长期的有效抵达率(λ),乘以顾客在这个系统中平均的等待时间(W);或者,我们可以用一个代数式来表达。
因此,耗时任务会显著提高服务负载、降低在线业务服务的吞吐能力。
通过引入消息队列或者任务队列框架,我们可以将耗时任务从在线业务服务中进行隔离拆分。
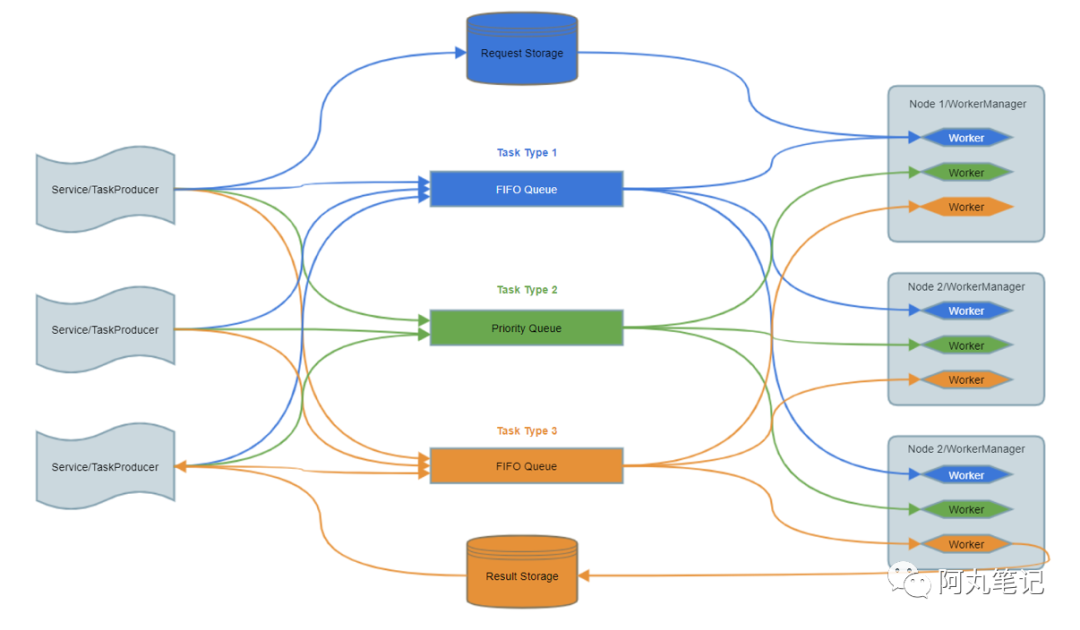
这种隔离拆分的方式,能带来以下优势:
提高在线服务的吞吐能力
避免耗时任务影响在线业务的稳定性
3、核心与非核心隔离拆分
「Y轴扩展」的第三种方式,是将核心与非核心进行拆分。
比如,我们通常可能会将「核心接口」与「非核心」接口通过一个服务内的不同线程池实现隔离。但是在节点资源(cpu/内存/带宽等)上并不能实现隔离。
因此,我们可以更进一步,通过集群拆分的形式进行隔离。
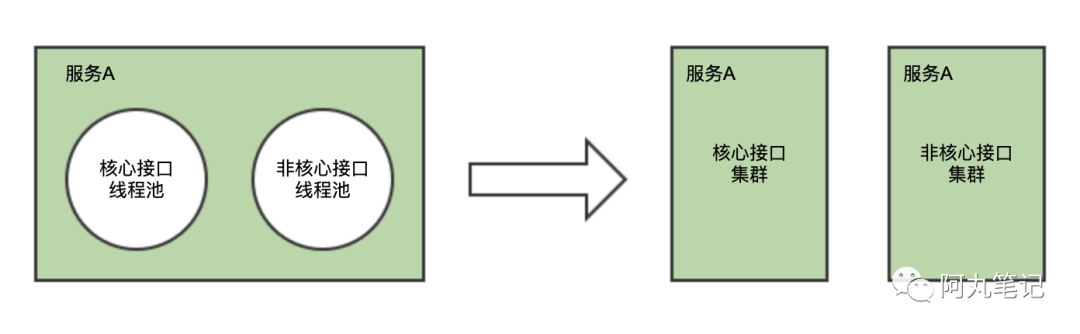
通过服务路由的配置,将核心接口路由到核心集群(一般节点配置更高),非核心接口路由到非核心集群。
另外,也有saas服务,通常会对SKA客户做独立集群,也是类似的逻辑。
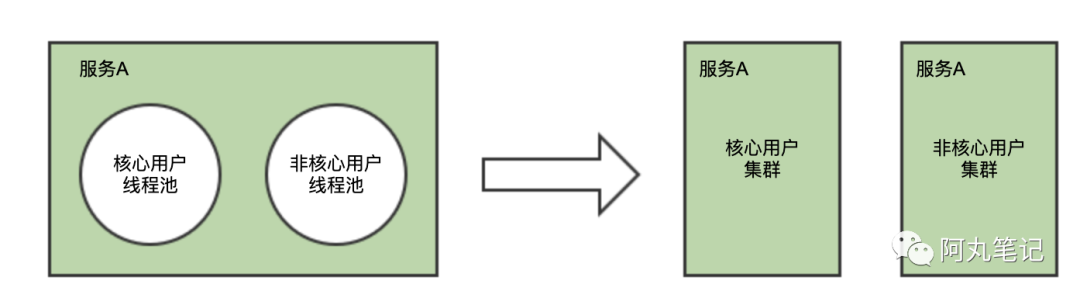
其实按用户拆分隔离跟「数据分区」有一点类似,也可以归类到「z轴扩展」
这种隔离拆分的方式,能带来以下优势:
精细化提高服务吞吐能力(针对核心接口、核心客户)
核心业务独享资源,提高核心业务稳定性
避免非核心接口/用户影响核心接口/用户的稳定性
三、Z轴扩展的思想与应用
Z轴扩展的核心思想,是基于请求者或用户独特的需求,进行系统划分,并使得划分出来的子系统是相互隔离但又是完整的。
生产实践中,常用的z轴扩展有两种应用:
单元化架构
数据分区
1、单元化架构
单元化架构主要关注的是应用部署、调用层面的问题。
一个单元,是一个五脏俱全的缩小版全站,它部署了所有微服务。
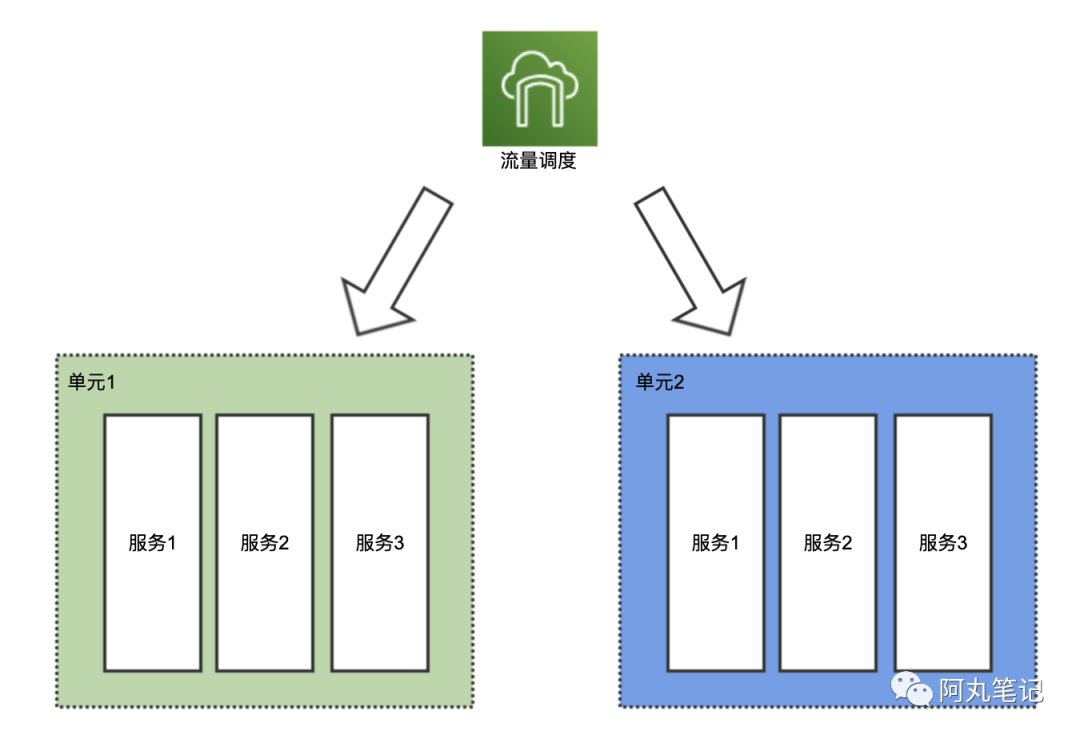
但它又不是真正的全站,因为每个单元只能操作一部分数据。
从这里我们也能看出,单元化架构要求系统必须具备的一项能力——数据分区。
当然,仅把数据分区了还不够,单元化的另外一个必要条件是,全站所有业务数据分区所用的拆分维度和拆分规则都必须一样。
一般来说,我们绝大多数系统都是面向用户的,按用户维度对数据分区,是一个最佳实践。
当然,如果是全球化部署的单元化架构,还需要考虑按照地域进行分区。
2、数据分区
数据分区(shard),即是将全局数据按照某一个维度水平划分开来,每个分区的数据内容互不重叠,这也就是数据库「水平拆分」所做的事情。
前面提到了「数据分区」是「单元化」的必要条件,但是「数据分区」还有其他很多场景应用。
最典型的,就是MySQL单机瓶颈后,需要进行「分库分表」。在服务中需要引入一些支持数据拆分和路由的中间件,如sharding-jdbc、mycat等,在数据层面需要配置相应的分片逻辑。
另外,其他数据库的分区扩展(如redis集群、mongo集群等),也是非常典型的应用场景。
一般包括以下几种数据划分的方式:
数据类型(如:业务类型)
数据范围(如:时间段,用户 ID)
数据热度(如:用户活跃度,商品热度)
按读写分(如:商品描述,商品库存)
四、小结
本文从「AKF扩展立方」说起,介绍了提高服务负载能力的几种服务治理方式。
除了X轴扩展(加机器)外,还可以通过Y轴扩展(功能/业务拆分)、Z轴扩展(数据分区)等方式,更优雅、更精细地进行优化。
希望能够抛砖引玉,提供一些启发和思考。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721