
本文根据王顺老师在〖deeplus直播:适配金融行业的数据库运维演进之路〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)

王顺
平安银行 数据库运维团队上海分组负责人
专注于数据库领域20+年的老兵,目前专注于数据库运维和数据库架构。
分享概要
一、数据库架构建设的基本方法和过程
二、某核心系统由大型机系统迁移到分布式架构
三、Redis异地容灾架构建设
一、数据库架构建设的基本方法和过程
1)数据库架构
在日常工作中,如果我们说到数据库架构,一般来说指的是网络、主机、存储及之上运行的数据库实例。数据库架构工作指的则是如何去评估和组合这些组件,从而为业务提供符合运营要求的数据库服务。
2)数据库访问组件
当数据库架构演进到分布式架构,如何让应用程序(服务)快速确认数据所在的位置,就成为了一个核心的问题,而这就是数据库访问组件的工作。
3)数据库运营平台
对于一个大型组织,运营几千套、几万套数据库实例是很平常的事情,而这也给运营团队的日常管理带来了一定难度的挑战。各个公司组织纷纷搭建运营平台,用于告警监控、故障处理、变更、版本发布等,在设计和构建数据库架构的同时建设数据库运营平台已经成为了一种标准操作。
1)业务需求
数据库架构首先要匹配组织的业务流程,满足组织的业务需求,是所有从业者的共识。
2)运营需求
设计和构建数据库架构的最终目标就是获得一个能够持续、稳定提供服务的数据库集群,从设计之初就充分了解和满足运营需求,是数据库架构设计成功的一个关键要素。
3)监管需求
对于强监管行业而言,不满足监管要求,项目就无法上线。因此,监管需求可以说事关监管行业的生死,必须在设计之初就充分考虑。
1)业界生态
“不要重复造轮子”,在数据库架构设计前,调研业界的技术生态非常重要。同时需要注意,我们所在组织的技术生态也是业界生态非常重要的一部分。
2)架构设计初稿
通过调研业界生态,我们能够获取数据库架构所需的模块,再结合项目的实际情况,对所需模块进行组合和完善,就能够获取数据库架构的初稿。
1)数据库选型和测试
数据库选型放在架构设计之后的一个重要考量是保证数据库架构设计的客观性。如果在数据库架构设计之前就选定了数据库,架构设计将不可避免地受到数据库功能特性的影响。
2)数据库架构原型
在拥有数据库架构设计和完成数据库选型的前提下,我们才能在测试或者开发环境构建数据库架构原型,这是我们下一步工作的基础。
1)在完成数据库原型建设之后,可以开始对数据库原型进行测试和验证,验证指标应回到最初的需求、业务目标、运营目标和监管目标。
2)每轮的测试和验证都会生成架构的优化项,结合项目的需求和目标,对数据库架构不断进行迭代,一般在3到5轮迭代之后就可以得到一个相对稳定可靠的数据库架构。
二、某核心系统由大型机系统迁移到分布式架构
迁移项目第一步是对当前系统的情况进行摸底调查。
1)容量和性能指标
系统指标分为很多方面,对于数据库架构而言,首先需要考虑的是性能和容量指标。
2)业务特性
该项目具有一个明显的特点——实时在线业务一次仅处理一个客户,账务结算和报表模块一次需要处理很多客户数据。
3)数据访问和处理
通常意义上所说的计算和存储分离指的是数据存储在大型机文件中,业务逻辑完全在应用层实现。
4)项目人员能力
项目人员的能力主要集中于JAVA的开发,对于Oracle和MySQL较为熟悉,其他关系型数据库的开发则相对陌生,项目人员的能力对于数据库选型有明显的影响。
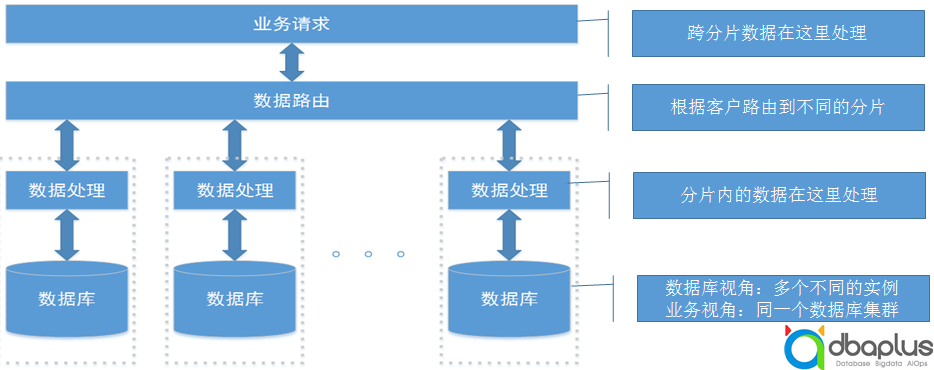
1)按照客户对数据进行分片,数据路由在应用层处理,每个分片都由一个数据处理模块和一组数据库实例组成,不同分片之间完全独立,跨分片的聚合计算在业务层处理。
2)站在数据库本身的视角,不同分片之间的数据库实例是完全独立的,不存在任何的数据交互。站在业务的角度,所有的数据库实例则组成了一个统一的数据库集群。
3)该架构的优点是单分片处理逻辑简单,对实时在线业务非常友好;缺点是跨分片处理逻辑复杂,报表和账务结算业务难度高。
1)Oracle和MySQL的对比测试
Oracle在性能和故障自动恢复上具有一定的优势,但分布式应用架构下数据库实例众多,Oracle的成本要远高于MySQL。
MySQL在技术生态上与应用分布式架构更匹配,但需要解决半同步不降级的问题。
2)经过架构师团队的讨论和权衡,最终决定使用MySQL衍生数据库,性能与原生MySQL接近,同时半同步不降级,满足RPO=0
1)配置管理:为每个数据库实例添加分片属性和业务属性。
2)端到端交付:为了满足数据库实例可以动态地横向扩容和缩容,增加了拉入节点、拉出节点和资源池的功能。
3)监控和故障处理:在原有的数据库监控平台的基础上,增加了业务视角和分片视角,当数据库实例故障时,能够更加精准定位到受影响的客户。
4)数据库变更:为满足24小时不停机的业务要求,增加了业务降级、流量管控、滚动处理和变更日历功能。
5)版本发布:在分布式架构下,为应对成倍上升的复杂度和风险,增加灰度发布、并行发布、分片自适应和版本编排功能。
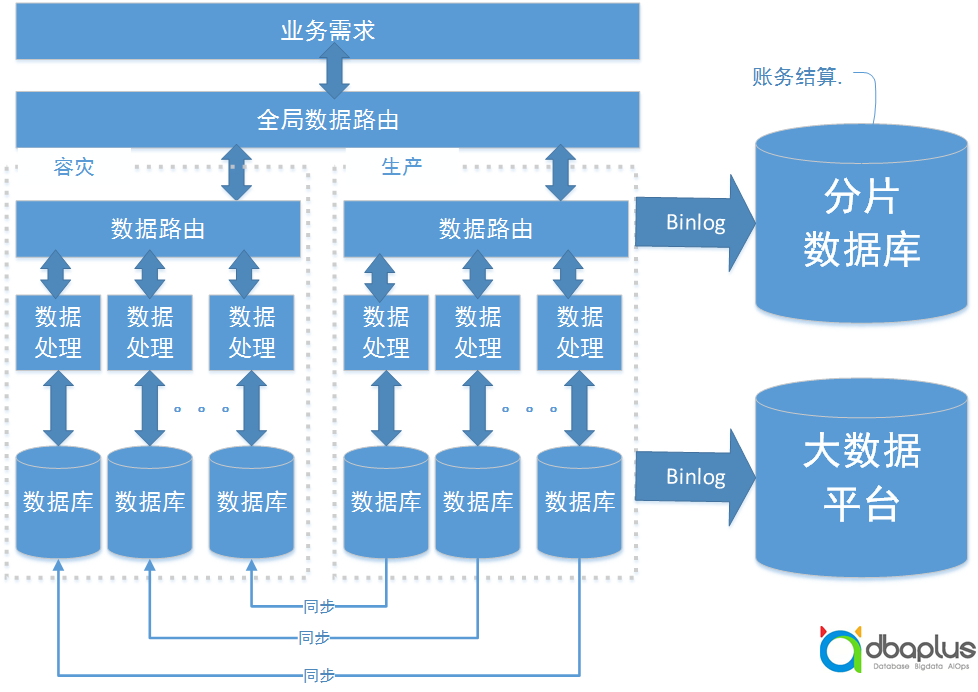
1)为满足监管要求,需要在已有架构上添加容灾架构。
在生产数据中心和容灾数据中心建设相同的数据路由、数据处理模块及对应的数据库实例,对应的数据库实例之间进行数据同步。
每个分片都可以独立在不同的数据中心之间自由切换。
添加全局数据路由,能够保证将事务处理路由到正确的数据中心处理。
2)使用业界已有的技术,通过binlog将数据实时同步到大数据平台,进行报表分析。
3)使用业界已有的技术,通过binlog将数据实时同步到分片数据库(整体引入),降低账务结算程序的复杂度。
三、Redis异地容灾架构建设
1)所有的Redis仅作为缓存使用,无数据同步需求。
2)95%以上的Redis为Cluster架构,5%以内的Redis为哨兵架构,本次设计的架构聚焦于Cluster架构。
3)95%以上的Redis Cluster无容量和性能要求,准确来说就是所有的Redis Cluster都可以标准化,只要后续提供扩容/缩容的功能即可。
4)生产Redis Cluster变化较大,异地容灾要求和生产同步上线和下线。
5)最小化DBA和应用开发团队的人力成本。
1)建设一个K8S集群,用来承载所有的Redis集群。
2)建设Redis集群同步平台,从已有的CMDB读取生产Redis集群的信息,并将创建的异地容灾Redis集群信息更新到CMDB。
3)同步进程根据CMDB生成生产Redis集群集合和异地容灾集合。生产集合减去异地容灾集合,即需要搭建的异地容灾集合,平台将自动创建异地容灾集群,并将信息更新到CMDB。异地容灾集合减去生产集合,即需要下线的异地容灾集合,平台将自动下线异地容灾集群,并将这些集群从CMDB中删除。
4)每天执行上述步骤,即可保证移动容灾集群和生产集群的同步。
5)K8S集群可以自动拉起宕掉的节点,结合Redis集群本身的高可用,即可保证异地容灾集群的高可用。
6)K8S集群本身的告警监控即可满足异地容灾的告警和故障处理需求。
7)设计自助平台,应用开发和运营团队可以进行自助查询、自助修改参数、自助扩容、自助申请域名等操作,最小化DBA和应用开发运营的人力成本。

Q&A
Q1:在架构设计层面,怎样避免数据迁移过程中的数据丢失问题呢?
A1:首先数据校验功能一定要与业务要求匹配,如果项目迁移是停机完成的,一次性数据校验程序就可以满足。如果项目迁移是在线完成的,就需要有实时数据校验功能。其次对于重要系统,最好有流控模块,比如先迁移5%的流量,在验证没有问题后再迁移其他的流量。
Q2:贵团队采用的数据分片方式是什么?有哪些需要注意的点?
A2:我们这个项目是在应用层面做分片,这种分片方式需要有一个强大的中间件来完成,否则的话业务开发就变得非常复杂。这种分片方式在设计分片键的时候需要充分考虑实时在线业务的情况,要保证一个事务在同一个分片内完成。
Q3:Redis集群容易节点宕机,有什么比较好的解决方案?
A3:首先,从我的运维实践来说Redis宕机频率在可接受的范围内。其次,Redis的Cluster架构,如果一个节点宕机后可以快速恢复的话,本身对业务的影响并不大。最后如果贵公司的Redis节点确实容易宕机的话,建议多建一个副本,这样即使宕机也不会影响线上业务。
Q4:Redis异地容灾,数据不做实时同步么?
A4:我们公司的系统,Redis只做缓存,所以没有任何同步的需求。如果贵公司的Redis承担缓存之外的功能,如需要记录业务状态,就需要做实时同步了,从实践上来看,这种用法效果不是很理想。
Q5:请问,Cluster一般是什么规模,即每个应用使用几主几从,每个节点maxmemory设置多大?
A5:Cluster一般是三主三从,maxmemory为2GB到8GB。一般单个实例的maxmemory超过8GB就不在扩容,而是采用增加节点的方式扩容。
Q6:数据库同城容灾,是一套数据物理放两边,还是两中心各自独立逻辑数据集群(逻辑复制)?
A6:同城数据中心一般保证足够的带库,所以绝大部分情况是使用数据库本身的同步功能。只有网络性能不满足,或者是有双写的要求,才考虑其他逻辑复制的方案。

获取本期PPT,请添加群秘微信号:dbachen








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721