
作者介绍

前言
我曾经面试安踏的技术岗,当时面试官问了我一个问题:如果你想使用某个新技术但是领导不愿意,你怎么办?
对于该问题我相信大家就算没有面试被问到过,现实工作中同事之间的合作也会遇到。
因此从我的角度重新去回答这个问题,有以下几点:
师出有名
在软件工程里是针对问题场景提供解决方案的,如果脱离的实际问题(需求)去做技术选型,无疑是耍流氓。大家可以回顾身边的“架构师”、“技术Leader”是不是拍拍脑袋做决定,问他们为什么这么做,可能连个冠冕堂皇的理由都给不出。
信任度
只有基于上面的条件,你才有理由建议引入新技术。领导愿不愿意引入新技术有很多原因:领导不了解这技术、领导偏保守、领导不是做技术的等。那么我认为这几种都是信任度,这种信任度分人和事,人就是引入技术的提出者,事就是提出引入的技术。
尽人事
任何问题只是单纯解决事都是简单的,以我以往的做法,把基本资料收集全并以通俗易懂的方式归纳与讲解,最好能提供一些能量化的数据,这样更加有说服力。知识普及OK后,就可以尝试写方案与做个Demo,方案最好可以提供多个,可以分短期收益与长期收益的。完成上面几点可以说已经尽人事了,如果领导还不答应那么的确有他的顾虑,就算无法落实,到目前为止的收获也不错。
复杂的是人
任何人都无法时刻站在理智与客观的角度去看待问题,事是由人去办的,所以同一件事由不同的人说出来的效果也不一样。因此得学会向上管理、保持与同事之间合作融洽度,尽早的建立合作信任。本篇文章更多叙述的事,因此人方面不过多深究,有兴趣的我可以介绍一本书《知行 技术人的管理之路》。
本篇我的实践做法与上述一样,除了4无法体现。那么下文我分了4大模块:业务背景介绍、基础概念讲解、方案的选用与技术细节。
部分源码,我放到了https://github.com/SkyChenSky/Sikiro 的Sikiro.ES.Api里。
一、背景
本公司多年以来用SQL Server作为主存储,随着多年的业务发展,已经到了数千万级的数据量。
而部分非核心业务原本应该超亿的量级了,但是因为从物理表的设计优化上进行了数据压缩,导致维持在一个比较稳定的数量。压缩数据虽然能减少存储量,优化提供一定的性能,但是同时带来的损失了业务可扩展性。举个例子:我们平台某个用户拥有最后访问作品记录和总的阅读时长,但是没有某个用户的阅读明细,那么这样的设计就会导致后续新增一个抽奖业务,需要在某个时间段内阅读了多长时间或者章节数量的作品,才能参加与抽奖;或者运营想通过阅读记录统计或者分析出,用户的爱好和受欢迎的作品。现有的设计对以上两种业务情况都是无法满足的。
此外我们平台还有作品搜索功能,like ‘%搜索%’查询是不走索引的而走全表扫描,一张表42W全表扫描,数据库服务器配置可以的情况下还是可以的,但是存在并发请求时候,资源消耗就特别厉害了,特别是在偶尔被爬虫爬取数据。(我们平台API的并发峰值能达到8w/s,每天的接口在淡季请求次数达到了1亿1千万)
关系型数据库拥有ACID特性,能通过金融级的事务达成数据的一致性,然而它却没有横向扩展性,只要在海量数据场景下,单实例,无论怎么在关系型数据库做优化,都是只是治标。而NoSQL的出现很好的弥补了关系型数据库的短板,在马丁福勒所著的《NoSQL精粹》对NoSQL进行了分类:文档型、图形、列式,键值,从我的角度其实可以把搜索引擎纳入NoSQL范畴,因为它的确满足的NoSQL的4大特性:易扩展、大数据量高性能、灵活的数据模型、高可用。我看过一些同行的见解,把Elasticsearch归为文档型NoSQL,我个人是没有给他下过于明确的定义,这个上面说法大家见仁见智。
MongoDB作为文档型数据库也属于我的技术选型范围,它的读写性能高且平衡、数据分片与横向扩展等都非常适合我们平台部分场景,最后我还是选择Elasticsearch。原因有三:
我们运维相比于MongoDB更熟悉Elasticsearch。
我们接下来有一些统计报表类的需求,Elastic Stack的各种工具能很好满足我们的需求。
我们目前着手处理的场景以非实时、纯读为主的业务,Elasticsearch近实时搜索已经能满足我们。
二、Elasticsearch优缺点
百度百科 :
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch由Java语言开发的,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。
对于满足当下的业务需求和未来支持海量数据的搜索,我选择了Elasticsearch,其实原因主要以下几点:

那么我个人认为Elasticsearch比较大的缺点只有吃内存,具体原因可以看下文内存读取部分。
三、Elasticsearch为什么快?
我个人对于Elasticsearch快的原因主要总结三点:
内存读取
多种索引:倒排索引和doc values。
集群分片
1、内存读取
Elasticsearch是基于Lucene, 而Lucene被设计为可以利用操作系统底层机制来缓存内存数据结构,换句话说Elasticsearch是依赖于操作系统底层的Filesystem Cache,查询时,操作系统会将磁盘文件里的数据自动缓存到 Filesystem Cache 里面去,因此要求Elasticsearch性能足够高,那么就需要服务器的提供的足够内存给Filesystem Cache 覆盖存储的数据。
上一段最后一句话什么意思呢?假如:Elasticsearch 节点有 3 台服务器各64G内存,3台总内存就是 64 * 3 = 192G。每台机器给 Elasticsearch jvm heap 是 32G,那么每服务器留给 Filesystem Cache 的就是 32G(50%),而集群里的 Filesystem Cache 的就是 32 * 3 = 96G 内存。此时,在 3 台Elasticsearch服务器共占用了 1T 的磁盘容量,那么每台机器的数据量约等于 341G,意味着每台服务器只有大概10分之1数据是缓存在内存的,其余都得走硬盘。
说到这里大家未必会有一个直观得认识,因此我从《大型网站技术架构:核心原理与案例分析》第36页抠了一张表格下来:

从上图加粗项看出,内存读取性能是机械磁盘的200倍,是SSD磁盘约等于30倍,假如读一次Elasticsearch走内存场景下耗时20毫秒,那么走机械硬盘就得4秒,走SSD磁盘可能约等于0.6秒。讲到这里我相信大家对是否走内存的性能差异有一个直观的认识。
对于Elasticsearch有很多种索引类型,但是我认为核心主要是倒排索引和doc values。
2、倒排索引
Lucene将写入索引的所有信息组织为倒排索引(inverted index)的结构形式。倒排索引是一种将分词映射到文档的数据结构,可以认为倒排索引是面向分词的而不是面向文档的。
假设在测试环境的Elasticsearch存放了有以下三个文档:
Elasticsearch Server(文档1)
Masterring Elasticsearch(文档2)
Apache Solr 4 Cookbook(文档3)
以上文档索引建好后,简略显示如下:

如上表格所示,每个词项指向该词项所出现过的文档位置,这种索引结构允许快速、有效的搜索出数据。
3、doc values
对于分组、聚合、排序等某些功能来说,倒排索引的方式并不是最佳选择,这类功能操作的是文档而不是词项,这个时候就得把倒排索引逆转过来成正排索引,这么做会有两个缺点:
构建时间长。
内存占用大,易OutOfMemory,且影响垃圾回收。
Lucene 4.0之后版本引入了doc values和额外的数据结构来解决上面得问题,目前有五种类型的doc values:NUMERIC、BINARY、SORTED、SORTED_SET、SORTED_NUMERIC,针对每种类型Lucene都有特定的压缩方法。
doc values是列式存储的正排索引,通过docID可以快速读取到该doc的特定字段的值,列式存储存储对于聚合计算有非常高的性能。
4、集群分片
Elasticsearch可以简单、快速利用多节点服务器形成集群,以此分摊服务器的执行压力。
此外数据可以进行分片存储,搜索时并发到不同服务器上的主分片进行搜索。
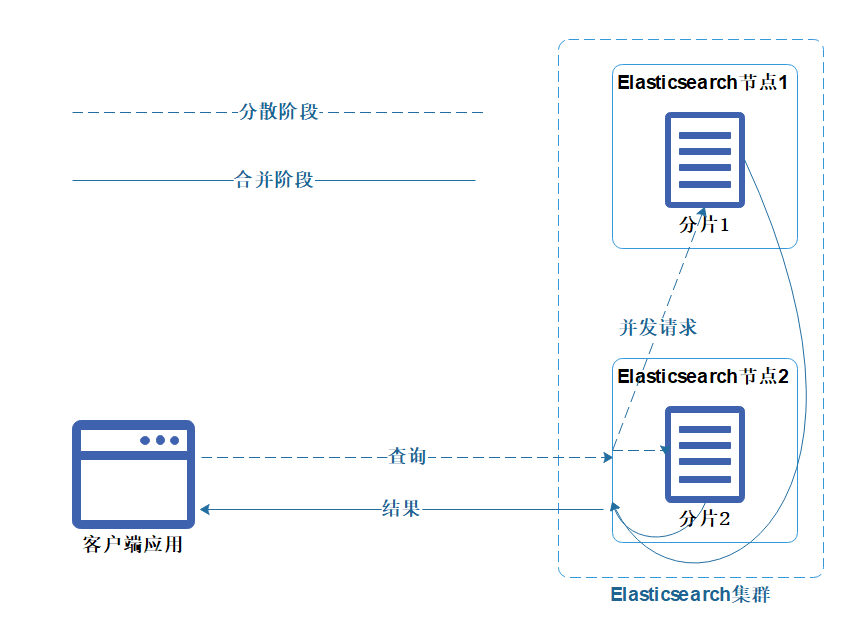
这里可以简单讲述下Elasticsearch查询原理,Elasticsearch的查询分两个阶段:分散阶段与合并阶段。
任意一个Elasticsearch节点都可以接受客户端的请求。接受到请求后,就是分散阶段,并行发送子查询给其他节点;
然后是合并阶段,则从众多分片中收集返回结果,然后对他们进行合并、排序、取长等后续操作。最终将结果返回给客户端。
机制如下图:
分页深度陷阱
基于以上查询的原理,扩展一个分页深度的问题。
现需要查页长为10、第100页的数据,实际上是会把每个 Shard 上存储的前 1000(10*100) 条数据都查到一个协调节点上。如果有 5 个 Shard,那么就有 5000 条数据,接着协调节点对这 5000 条数据进行一些合并、处理,再获取到最终第 100 页的 10 条数据。也就是实际上查的数据总量为pageSize*pageIndex*shard,页数越深则查询的越慢。因此ElasticSearch也会有要求,每次查询出来的数据总数不会返回超过10000条。
那么从业务上尽可能跟产品沟通避免分页跳转,使用滚动加载。而Elasticsearch使用的相关技术是search_after、scroll_id。
四、ElasticSearch与数据库基本概念对比
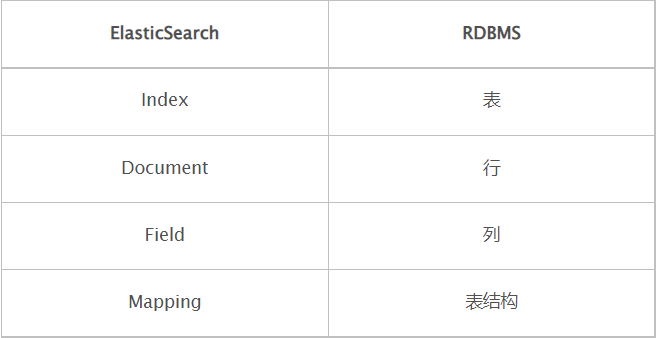
在Elasticsearch 7.0版本之前(<7.0),有type的概念,而Elasticsearch和关系型数据库的关系是,index = database、type = table,但是在Elasticsearch 7.0版本后(>=7.0)弱化了type默认为_doc,而官方会在8.0之后会彻底移除type。
五、服务器选型
在官方文档(https://www.elastic.co/guide/cn/elasticsearch/guide/current/heap-sizing.html)里建议Elasticsearch JVM Heap最大为32G,同时不超过服务器内存的一半,也就是说内存分别为128G和64G的服务器,JVM Heap最大只需要设置32G;而32G服务器,则建议JVM Heap最大16G,剩余的内存将会给到Filesystem Cache充分使用。如果不需要对分词字符串做聚合计算(例如,不需要 fielddata )可以考虑降低JVM Heap。JVM Heap越小,会导致Elasticsearch的GC频率更高,但Lucene就可以的使用更多的内存,这样性能就会更高。
对于我们公司的未来新增业务还会有收集用户的访问记录来统计PV(page view)、UV(user view),有一定的聚合计算,经过多方便的考虑与讨论,平衡成本与需求后选择了腾讯云的三台配置为CPU 16核、内存64G,SSD云硬盘的服务器,并给与Elasticsearch 配置JVM Heap = 32G。
六、需求场景选择
Elasticsearch在本公司系统的可使用场景非常多,但是作为第一次引入因慎重选择,给与开发与运维一定的时间熟悉与观察。
经过商讨,选择了两个业务场景,用户阅读作品的记录明细与作品搜索,选择这两个业务场景原因如下:
1、写场景
我们平台的用户黏度比较高,阅读作品是一个高频率的调用,因此用户阅读作品的记录明细可在短时间内造成海量数据的场景。(现一个月已达到了70G的数据量,共1亿1千万条)
2、读场景
阅读记录需提供给未来新增的抽奖业务使用,可从阅读章节数、阅读时长等进行搜索计算。
作品搜索原有实现是通过关系型数据库like查询,已是具有潜在的性能问题与资源消耗的业务场景。
对于上述两个业务,用户阅读作品的记录明细与抽奖业务属于新增业务,对于在投入成本相对较少,也无需过多的需要兼容旧业务的压力。
而作品搜索业务属于优化改造,得保证兼容原有的用户搜索习惯前提下,新增拼音搜索。同时最好以扩展的方式,尽可能的减少代码修改范围,如果使用效果不好,随时可以回滚到旧的实现方式。
七、设计方案
1、共性设计
我使用.Net 5 WebApi将Elasticsearch封装成ES业务服务API,这样的做法主要用来隐藏技术细节(时区、分词器、类型转换等),暴露粗粒度的读写接口。这种做法在马丁福勒所著的《NoSQL精粹》称把数据库视为“应用程序数据库”,简单来说就是只能通过应用间接的访问存储,对于这个应用由一个团队负责维护开发,也只有这个团队才知道存储的结构。这样通过封装的API服务解耦了外部API服务与存储,调用方就无需过多关注存储的特性,像Mongodb与Elasticsearch这种无模式的存储,无需优先定义结构,换而言之就是对于存储已有结构可随意修改扩展,那么“应用程序数据库”的做法也避免了其他团队无意侵入的修改。
考虑到现在业务需求复杂度相对简单,MQ消费端也一起集成到ES业务服务,若后续MQ消费业务持续增多,再考虑把MQ消费业务抽离到一个(或多个的)消费端进程。
目前以同步读、同步写、异步写的三种交互方式,进行与其他服务通信。
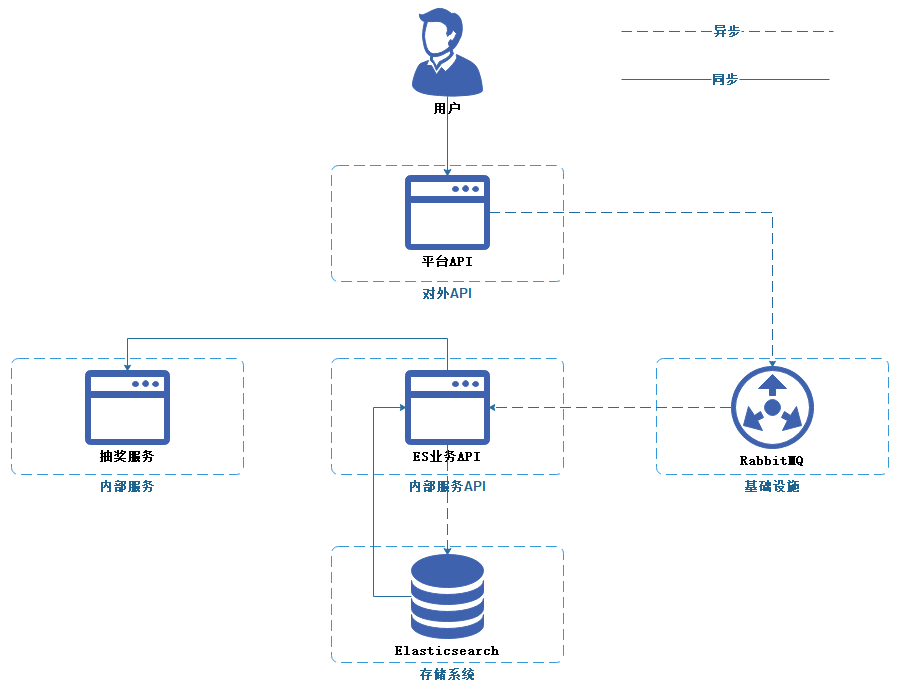
2、阅读记录明细
本需求是完全新增,因此引入相对简单,只需要在【平台API】使用【RabbitMQ】进行解耦,使用异步方式写入Elasticsearch,使用队列除了用来解耦,还对此用来缓冲高并发写压力的情况。
对于后续新增的业务例如抽奖服务,则只需要通过RPC框架对接ES业务API,以同步读取的方式查询数据。
3、作品搜索
对于该业务,我第一反应采用CQRS的思想,原有的写入逻辑我无需过多的关注与了解,因此我只需要想办法把关系型数据库的数据同步到Elasticsearch,然后提供业务查询API替换原有平台API的数据源即可。
那么数据同步则一般都是分推和拉两种方式。
4、推
推的实时性无疑是比拉要高,只需增量的推送做写入的数据(增、删、改)即可,无论是从性能、资源利用、时效各方面来看都比拉更有效。
实施该方案,可以选择Debezium和SQL Server开启CDC功能。
Debezium由RedHat开源的,同时需要依赖于kafka的,一个将多种数据源实时变更数据捕获,形成数据流输出的开源工具,同类产品有Canal, DataBus, Maxwell。
CDC全称Change Data Capture,直接翻译过来为变更数据捕获,核心为监测服务捕获数据库的写操作(插入,更新,删除),将这些变更按发生的顺序完整记录下来。
我个人在我博客文章多次强调架构设计的输入核心为两点:满足需求与组织架构,在满足需求的前提应优先选择简单、合适的方案。技术选型应需要考虑自己的团队是否可以支撑。在上述无论是额外加入Debezium和kafka,还是需要针对SQL Server开启CDC都超出了我们运维所能承受的极限,引入新的中间件和技术是需要试错的,而试错是需要额外高的成本,在未知的情况下引入更多的未知,只会造成更大的成本和不可控。
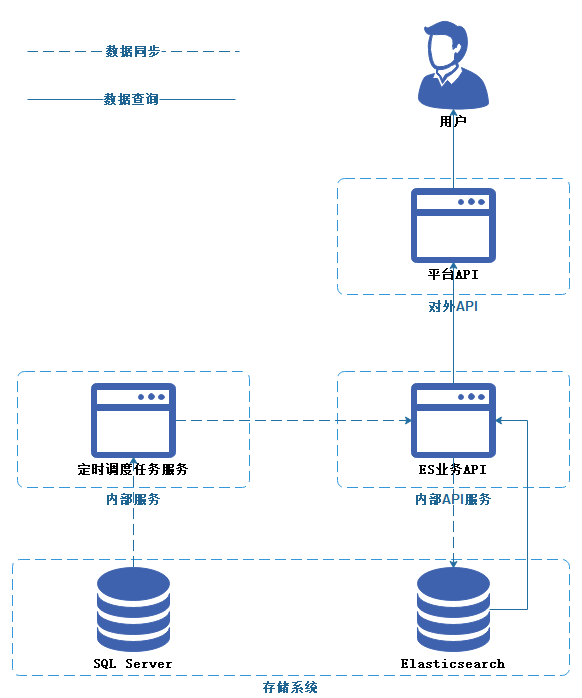
5、拉
拉无疑是最简单最合适的实现方式,只需要使用调度任务服务,每隔段时间定时去从数据库拉取数据写入到Elasticsearch就可。
然而拉取数据,分全量同步与增量同步:
对于增量同步,只需要每次查询数据源Select * From Table_A Where RowVersion > LastUpdateVersion,则可以过滤出需要同步的数据。但是这个方式有点致命的缺点,数据源已被删除的数据是无法查询出来的,如果把Elasticsearch反向去跟SQL Server数据做对比又是一件比较愚蠢的方式,因此只能放弃该方式。
而全量同步,只要每次从SQL Server数据源全量新增到Elasticsearch,并替换旧的Elasticsearch的Index,因此该方案得全删全增。但是这里又引申出新的问题,如果先删后增,那么在删除后再新增的这段真空期怎么办?假如有5分钟的真空期是没有数据,用户就无法使用搜索功能。那么只能先增后删,先新增到一个Index_Temp,全量新增完后,把原有Index改名成Index_Delete,然后再把Index_Temp改成Index,最后把Index_Delete删除。这么一套操作下来,有没有觉得很繁琐很费劲?Elasticsearch有一个叫别名(Aliases)的功能,别名可以一对多的指向多个Index,也可以以原子性的进行别名指向Index的切换,具体实现可以看下文。
八、阅读记录实现细节
1、实体定义
优先定义了个抽象类ElasticsearchEntity进行复用,对于实体定义有三个注意的细节点:
对于ElasticsearchEntity我定义两个属性_id与Timestamp,Elasticsearch是无模式的(无需预定义结构),如果实体本身没有_id,写入到Elasticsearch会自动生成一个_id,为了后续的使用便捷性,我仍然自主定义了一个。
基于上述的分页深度的问题,因此在后续涉及的业务尽可能会以search_after+滚动加载的方式落实到我们的业务。原本我们只需要使用DateTime类型的字段用DateTime.Now记录后,再使用search_after后会自动把DateTime类型字段转换成毫秒级的Timestamp,但是我在实现demo的时候,去制造数据,在程序里以for循环new数据的时候,发现生成的速度会在微秒级之间,那么假设用毫秒级的Timestamp进行search_after过滤,同一个毫秒有4、5条数据,那么容易在使用滚动加载时候少加载了几条数据,这样就到导致数据返回不准确了。因此我扩展了个[DateTime.Now.DateTimeToTimestampOfMicrosecond()]生成微秒级的Timestamp,以此尽可能减少出现漏加载数据的情况。
对于Elasticsearch的操作实体的日期时间类型均以DateTimeOffset类型声明,因为Elasticsearch存储的是UTC时间,而且会因为Http请求的日期格式不同导致存放的日期时间也会有所偏差,为了避免日期问题使用DateTimeOffset类型是一种保险的做法。而对于WebAPI 接口或者MQ的Message接受的时间类型可以使用DateTime类型,DTO(传输对象)与DO(持久化对象)使用Mapster或者AutoMapper类似的对象映射工具进行转换即可(注意DateTimeOffset转DateTime得定义转换规则 [TypeAdapterConfig<DateTimeOffset, DateTime>.NewConfig().MapWith(dateTimeOffset => dateTimeOffset.LocalDateTime)])。
如此一来,把Elasticsearch操作细节隐藏在WebAPI里,以友好、简单的接口暴露给开发者使用,降低了开发者对技术细节认知负担。
[]public class UserViewDuration : ElasticsearchEntity{/// <summary>/// 作品ID/// </summary>[]public long EntityId { get; set; }/// <summary>/// 作品类型/// </summary>[]public long EntityType { get; set; }/// <summary>/// 章节ID/// </summary>[]public long CharpterId { get; set; }/// <summary>/// 用户ID/// </summary>[]public long UserId { get; set; }/// <summary>/// 创建时间/// </summary>[]public DateTimeOffset CreateDateTime { get; set; }/// <summary>/// 时长/// </summary>[]public long Duration { get; set; }/// <summary>/// IP/// </summary>[]public string Ip { get; set; }}
public abstract class ElasticsearchEntity{private Guid? _id;public Guid Id{get{_id ??= Guid.NewGuid();return _id.Value;}set => _id = value;}private long? _timestamp;[]public long Timestamp{get{_timestamp ??= DateTime.Now.DateTimeToTimestampOfMicrosecond();return _timestamp.Value;}set => _timestamp = value;}}
2、异步写入
对于异步写入有两个细节点:
该数据从RabbtiMQ订阅消费写入到Elasticsearch,从下面代码可以看出,我刻意以月的维度建立Index,格式为 userviewrecord-2021-12,这么做的目的是为了方便管理Index和资源利用,有需要的情况下会删除旧的Index。
消息订阅与WebAPI暂时集成到同一个进程,这样做主要是开发、部署都方便,如果后续订阅多了,在把消息订阅相关的业务抽离到独立的进程。
1)按需演变,避免过度设计
① 订阅消费逻辑
public class UserViewDurationConsumer : BaseConsumer<UserViewDurationMessage>{private readonly ElasticClient _elasticClient;public UserViewDurationConsumer(ElasticClient elasticClient){_elasticClient = elasticClient;}public override void Excute(UserViewDurationMessage msg){var document = msg.MapTo<Entity.UserViewDuration>();var result = _elasticClient.Create(document, a => a.Index(typeof(Entity.UserViewDuration).GetRelationName() + "-" + msg.CreateDateTime.ToString("yyyy-MM"))).GetApiResult();if (result.Failed)LoggerHelper.WriteToFile(result.Message);}}
/// <summary>/// 订阅消费/// </summary>public static class ConsumerExtension{public static IApplicationBuilder UseSubscribe<T, TConsumer>(this IApplicationBuilder appBuilder, IHostApplicationLifetime lifetime) where T : EasyNetQEntity, new() where TConsumer : BaseConsumer<T>{var bus = appBuilder.ApplicationServices.GetRequiredService<IBus>();var consumer = appBuilder.ApplicationServices.GetRequiredService<TConsumer>();lifetime.ApplicationStarted.Register(() =>{bus.Subscribe<T>(msg => consumer.Excute(msg));});lifetime.ApplicationStopped.Register(() => bus?.Dispose());return appBuilder;}}
② 订阅与注入
public class Startup{public Startup(IConfiguration configuration){Configuration = configuration;}public IConfiguration Configuration { get; }public void ConfigureServices(IServiceCollection services){......}public void Configure(IApplicationBuilder app, IWebHostEnvironment env, IHostApplicationLifetime lifetime){app.UseAllElasticApm(Configuration);app.UseHealthChecks("/health");app.UseDeveloperExceptionPage();app.UseSwagger();app.UseSwaggerUI(c =>{c.SwaggerEndpoint("/swagger/v1/swagger.json", "SF.ES.Api v1");c.RoutePrefix = "";});app.UseRouting();app.UseEndpoints(endpoints =>{endpoints.MapControllers();});app.UseSubscribe<UserViewDurationMessage, UserViewDurationConsumer>(lifetime);}}
3、查询接口
查询接口此处有两个细节点:
如果不确定月份,则使用通配符查询userviewrecord-*,当然有需要的也可以使用别名处理。
因为Elasticsearch是记录UTC时间,因此时间查询得指定TimeZone。
[HttpGet][Route("record")]public ApiResult<List<UserMarkRecordGetRecordResponse>> GetRecord([FromQuery] UserViewDurationRecordGetRequest request){var dataList = new List<UserMarkRecordGetRecordResponse>();string dateTime;if (request.BeginDateTime.HasValue && request.EndDateTime.HasValue){var month = request.EndDateTime.Value.DifferMonth(request.BeginDateTime.Value);if(month <= 0 )dateTime = request.BeginDateTime.Value.ToString("yyyy-MM");elsedateTime = "*";}elsedateTime = "*";var mustQuerys = new List<Func<QueryContainerDescriptor<UserViewDuration>, QueryContainer>>();if (request.UserId.HasValue)mustQuerys.Add(a => a.Term(t => t.Field(f => f.UserId).Value(request.UserId.Value)));if (request.EntityType.HasValue)mustQuerys.Add(a => a.Term(t => t.Field(f => f.EntityType).Value(request.EntityType)));if (request.EntityId.HasValue)mustQuerys.Add(a => a.Term(t => t.Field(f => f.EntityId).Value(request.EntityId.Value)));if (request.CharpterId.HasValue)mustQuerys.Add(a => a.Term(t => t.Field(f => f.CharpterId).Value(request.CharpterId.Value)));if (request.BeginDateTime.HasValue)mustQuerys.Add(a => a.DateRange(dr =>dr.Field(f => f.CreateDateTime).GreaterThanOrEquals(request.BeginDateTime.Value).TimeZone(EsConst.TimeZone)));if (request.EndDateTime.HasValue)mustQuerys.Add(a =>a.DateRange(dr => dr.Field(f => f.CreateDateTime).LessThanOrEquals(request.EndDateTime.Value).TimeZone(EsConst.TimeZone)));var searchResult = _elasticClient.Search<UserViewDuration>(a =>a.Index(typeof(UserViewDuration).GetRelationName() + "-" + dateTime).Size(request.Size).Query(q => q.Bool(b => b.Must(mustQuerys))).SearchAfterTimestamp(request.Timestamp).Sort(s => s.Field(f => f.Timestamp, SortOrder.Descending)));var apiResult = searchResult.GetApiResult<UserViewDuration, List<UserMarkRecordGetRecordResponse>>();if (apiResult.Success)dataList.AddRange(apiResult.Data);return ApiResult<List<UserMarkRecordGetRecordResponse>>.IsSuccess(dataList);}
九、作品搜索实现细节
1、实体定义
SearchKey是原有SQL Server的数据,现需要同步到Elasticsearch,仍是继承抽象类。ElasticsearchEntity实体定义,同时这里有三个细节点:
public string KeyName,我定义的是Text类型,在Elasticsearch使用Text类型才会分词。
在实体定义我没有给KeyName指定分词器,因为我会使用两个分词器:拼音和默认分词,而我会在批量写入数据创建Mapping时定义。
实体里的 public List<int> SysTagId 与SearchKey在SQL Server是两张不同的物理表,是一对多的关系,在代码表示如下,但是在关系型数据库是无法与之对应和体现的,这就是咱们所说的“阻抗失配”,但是能在以文档型存储系统(MongoDB、Elasticsearch)里很好的解决这个问题,可以以一个聚合的方式写入,避免多次查询关联。
[]public class SearchKey : ElasticsearchEntity{[]public int KeyId { get; set; }[]public int EntityId { get; set; }[]public int EntityType { get; set; }[]public string KeyName { get; set; }[]public int Weight { get; set; }[]public bool IsSubsidiary { get; set; }[]public DateTimeOffset? ActiveDate { get; set; }[]public List<int> SysTagId { get; set; }}
2、数据同步
数据同步我采用了Quartz.Net定时调度任务框架,因此时效不高,所以每4小时同步一次即可,有42W多的数据,分批进行同步,每次查询1000条数据同时进行一次批量写入。全量同步一次的时间大概2分钟。因此使用RPC调用[ES业务API服务]。
因为具体业务逻辑已经封装在[ES业务API服务],因此同步逻辑也相对简单,查询出SQL Server数据源、聚合整理、调用[ES业务API服务]的批量写入接口、重新绑定别名到新的Index。
[DisallowConcurrentExecution]public class SearchKeySynchronousJob : BaseJob{public override void Execute(){var rm = SFNovelReadManager.Instance();var maxId = 0;var size = 1000;string indexName = "";while (true){//避免一次性全部查询出来,每1000条一次写入。var searchKey = sm.searchKey.GetList(size, maxId);if (!searchKey.Any())break;var entityIds = searchKey.Select(a => a.EntityID).Distinct().ToList();var sysTagRecord = rm.Novel.GetSysTagRecord(entityIds);var items = searchKey.Select(a => new SearchKeyPostItem{Weight = a.Weight,EntityType = a.EntityType,EntityId = a.EntityID,IsSubsidiary = a.IsSubsidiary ?? false,KeyName = a.KeyName,ActiveDate = a.ActiveDate,SysTagId = sysTagRecord.Where(c => c.EntityID == a.EntityID).Select(c => c.SysTagID).ToList(),KeyID = a.KeyID}).ToList();//以一个聚合写入到ESvar postResult = new SearchKeyPostRequest{IndexName = indexName,Items = items}.Excute();if (postResult.Success){indexName = (string)postResult.Data;maxId = searchKey.Max(a => a.KeyID);}}//别名从旧Index指向新的Index,最后删除旧Indexvar renameResult = new SearchKeyRenameRequest{IndexName = indexName}.Excute();}}}
3、业务API接口
批量新增接口这里有2个细节点:
在第一次有数据进来的时候需要创建Mapping,因为得对KeyName字段定义分词器,其余字段都可以使用AutoMap即可。
新创建的Index名称是精确到秒的 SearchKey-202112261121
/// <summary>/// 批量新增作品搜索列表(返回创建的indexName)/// </summary>/// <param name="request"></param>/// <returns></returns>[]public ApiResult Post(SearchKeyPostRequest request){if (!request.Items.Any())return ApiResult.IsFailed("无传入数据");var date = DateTime.Now;var relationName = typeof(SearchKey).GetRelationName();var indexName = request.IndexName.IsNullOrWhiteSpace() ? (relationName + "-" + date.ToString("yyyyMMddHHmmss")) : request.IndexName;if (request.IndexName.IsNullOrWhiteSpace()){var createResult = _elasticClient.Indices.Create(indexName,a =>a.Map<SearchKey>(m => m.AutoMap().Properties(p =>p.Custom(new TextProperty{Name = "key_name",Analyzer = "standard",Fields = new Properties(new Dictionary<PropertyName, IProperty>{{ new PropertyName("pinyin"),new TextProperty{ Analyzer = "pinyin"} },{ new PropertyName("standard"),new TextProperty{ Analyzer = "standard"} }})}))));if (!createResult.IsValid && request.IndexName.IsNullOrWhiteSpace())return ApiResult.IsFailed("创建索引失败");}var document = request.Items.MapTo<List<SearchKey>>();var result = _elasticClient.BulkAll(indexName, document);return result ? ApiResult.IsSuccess(data: indexName) : ApiResult.IsFailed();}
重新绑定别名接口这里有4个细节点:
别名使用searchkey,只会有一个Index[searchkey-yyyyMMddHHmmss]会跟searchkey绑定.
优先把已绑定的Index查询出来,方便解绑与删除。
别名绑定在Elasticsearch虽然是原子性的,但是不是数据一致性的,因此得先Add后Remove。
删除旧得Index免得占用过多资源。
/// <summary>/// 重新绑定别名/// </summary>/// <returns></returns>[]public ApiResult Rename(SearchKeyRanameRequest request){var aliasName = typeof(SearchKey).GetRelationName();var getAliasResult = _elasticClient.Indices.GetAlias(aliasName);//给新index指定别名var bulkAliasRequest = new BulkAliasRequest{Actions = new List<IAliasAction>{new AliasAddDescriptor().Index(request.IndexName).Alias(aliasName)}};//移除别名里旧的索引if (getAliasResult.IsValid){var indeNameList = getAliasResult.Indices.Keys;foreach (var indexName in indeNameList){bulkAliasRequest.Actions.Add(new AliasRemoveDescriptor().Index(indexName.Name).Alias(aliasName));}}var result = _elasticClient.Indices.BulkAlias(bulkAliasRequest);//删除旧的indexif (getAliasResult.IsValid){var indeNameList = getAliasResult.Indices.Keys;foreach (var indexName in indeNameList){_elasticClient.Indices.Delete(indexName);}}return result != null && result.ApiCall.Success ? ApiResult.IsSuccess() : ApiResult.IsFailed();}
查询接口这里跟前面细节得差不多:
但是这里有一个得特别注意的点,可以看到这个查询接口同时使用了should和must,这里得设置minimumShouldMatch才能正常像SQL过滤。
should可以理解成SQL的Or,Must可以理解成SQL的And。
默认情况下minimumShouldMatch是等于0的,等于0的意思是,should不命中任何的数据仍然会返回must命中的数据,也就是你们可能想搜索(keyname.pinyin=’chengong‘ or keyname.standard=’chengong‘) and id > 0,但是es里没有存keyname='chengong'的数据,会把id> 0 而且 keyname != 'chengong' 数据给查询出来。
因此我们得对minimumShouldMatch=1,就是should条件必须得任意命中一个才能返回结果。
在should和must混用的情况下必须得注意minimumShouldMatch的设置!!!
/// <summary>/// 作品搜索列表/// </summary>/// <param name="request"></param>/// <returns></returns>[HttpPost][Route("search")]public ApiResult<List<SearchKeyGetResponse>> Get(SearchKeyGetRequest request){var shouldQuerys = new List<Func<QueryContainerDescriptor<SearchKey>, QueryContainer>>();int minimumShouldMatch = 0;if (!request.KeyName.IsNullOrWhiteSpace()){shouldQuerys.Add(a => a.MatchPhrase(m => m.Field("key_name.pinyin").Query(request.KeyName)));shouldQuerys.Add(a => a.MatchPhrase(m => m.Field("key_name.standard").Query(request.KeyName)));minimumShouldMatch = 1;}var mustQuerys = new List<Func<QueryContainerDescriptor<SearchKey>, QueryContainer>>{a => a.Range(t => t.Field(f => f.Weight).GreaterThanOrEquals(0))};if (request.IsSubsidiary.HasValue)mustQuerys.Add(a => a.Term(t => t.Field(f => f.IsSubsidiary).Value(request.IsSubsidiary.Value)));if (request.SysTagIds != null && request.SysTagIds.Any())mustQuerys.Add(a => a.Terms(t => t.Field(f => f.SysTagId).Terms(request.SysTagIds)));if (request.EntityType.HasValue){if (request.EntityType.Value == ESearchKey.EntityType.AllNovel){mustQuerys.Add(a => a.Terms(t => t.Field(f => f.EntityType).Terms(ESearchKey.EntityType.Novel, ESearchKey.EntityType.ChatNovel, ESearchKey.EntityType.FanNovel)));}elsemustQuerys.Add(a => a.Term(t => t.Field(f => f.EntityType).Value((int)request.EntityType.Value)));}var sortDescriptor = new SortDescriptor<SearchKey>();sortDescriptor = request.Sort == ESearchKey.Sort.Weight? sortDescriptor.Field(f => f.Weight, SortOrder.Descending): sortDescriptor.Field(f => f.ActiveDate, SortOrder.Descending);var searchResult = _elasticClient.Search<SearchKey>(a =>a.Index(typeof(SearchKey).GetRelationName()).From(request.Size * request.Page).Size(request.Size).Query(q => q.Bool(b => b.Should(shouldQuerys).Must(mustQuerys).MinimumShouldMatch(minimumShouldMatch))).Sort(s => sortDescriptor));var apiResult = searchResult.GetApiResult<SearchKey, List<SearchKeyGetResponse>>();if (apiResult.Success)return apiResult;return ApiResult<List<SearchKeyGetResponse>>.IsSuccess("空集合数据");}
十、APM监控
虽然在上面我做了足够的实现准备,但是对于上生产后的实际使用效果我还是希望有一个直观的体现。
在之前公司做微服务的时候的APM选型我们使用了Skywalking,但是现在这家公司的运维没有接触过,但是对于Elastic Stack他相对比较熟悉,如同上文所说架构设计的输入核心为两点:满足需求与组织架构,秉着我的技术选型原则是基于团队架构,我们采用了Elastic APM + Kibana(7.4版本),如下图所示:
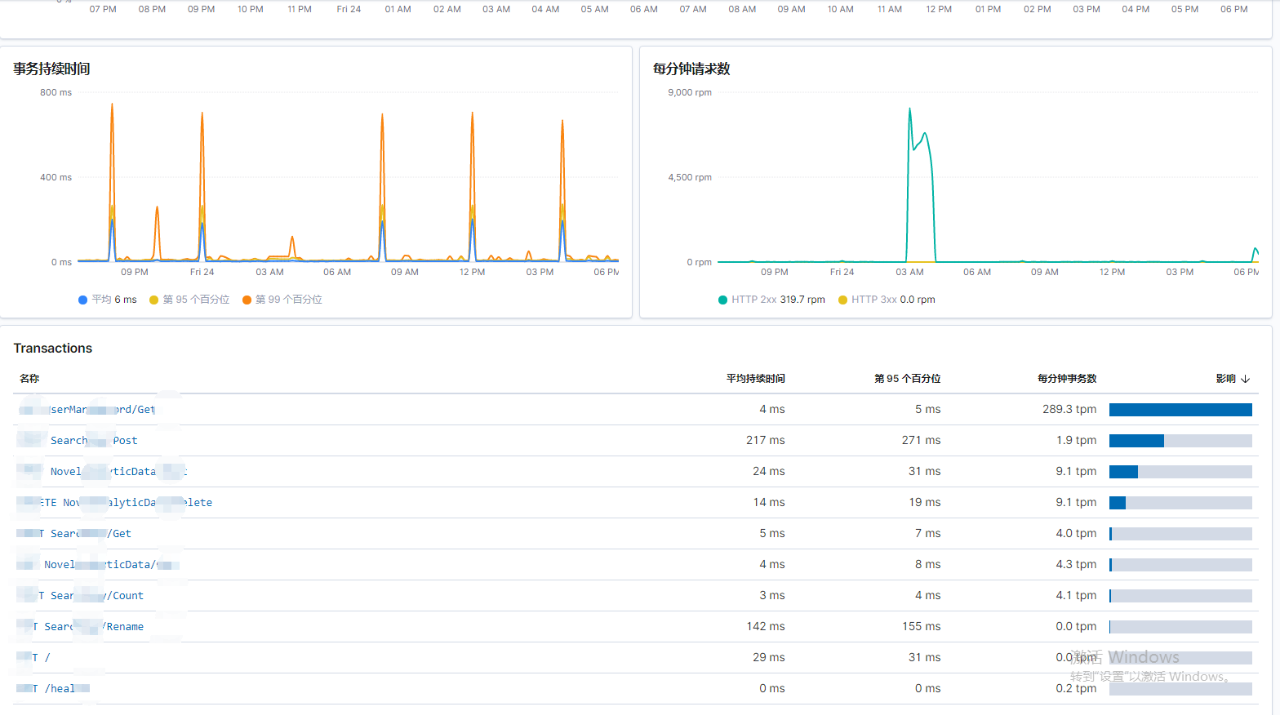
最后上生产的时候也是平滑无损的切换到Elasticsearch,总体情况都十分满意。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721