携程分布式缓存实践:最终一致和强一致性通吃!
GSF
2021-09-17 15:04:49
作者介绍
GSF,携程高级技术专家,关注高可用、高并发系统建设,致力于用技术驱动业务。
携程金融从成立至今,整体架构经历了从0到1再到10的变化,其中有多个场景使用了缓存来提升服务质量。从系统层面看,使用缓存的目的无外乎缓解DB压力(主要是读压力),提升服务响应速度。引入缓存,就不可避免地引入了缓存与业务DB数据的一致性问题,而不同的业务场景,对数据一致性的要求也不同。本文将从以下两个场景介绍我们的一些缓存实践方案:
注:我们DB用的是MySQL,缓存介质用的是携程高可用Redis服务,存储介质的选型及存储服务的高可用不是本文重点,后文也不再做特别说明。
经过几年演进,携程金融形成了自顶向下的多层次系统架构,如业务层、平台层、基础服务层等,其中用户信息、产品信息、订单信息等基础数据由基础平台等底层系统产生,服务于所有的金融系统,对这部分基础数据我们引入了统一的缓存服务(系统名utag),缓存数据有三大特点:全量、准实时、永久有效,在数据实时性要求不高的场景下,业务系统可直接调用统一的缓存查询接口。
我们的典型使用场景有:风控流程、APP入口信息提示等,而对数据一致性要求高的场景依然需要走实时的业务接口查询。引入缓存前后系统架构对比如下:

统一缓存服务的构建给部门的整体系统架构带来了一些优势:
-
响应速度提升:相比直接调用底层高流量的基础服务,调用缓存服务接口的系统响应时间大大减少(缓存查询接口P98为10毫秒)。
-
统一接口,降低接入成本:一部分业务场景下可以直接调用统一缓存服务查询接口,而不用再对接底层的多个子系统,极大地降低了各个业务线的接入成本。
-
-
服务压力降低:基础平台的系统本身就属于高流量系统,可减少一大部分的查询流量,降低服务压力。
整体而言,缓存服务处于中间层,数据的写入方和数据查询方解耦,数据甚至可以在底层系统不感知的情况下写入(见下文),而数据使用方的查询也可在底层服务不可用或“堵塞”时候仍然保持可用(前提是缓存服务是可用的,而缓存服务的处理逻辑简单、统一且有多种手段保证,其可用性比单个子系统都高),整体上服务的稳定性得到了提升。
-
数据准确性:DB中单条数据的更新一定要准确同步到缓存服务。
-
数据完整性:将对应DB表的全量数据进行缓存且永久有效,从而可以替代对应的DB查询。
-
系统可用性:我们多个产品线的多个核心服务都已经接入,utag的高可用性显的尤为关键。
接下来先说明统一缓存服务的整体方案,再逐一介绍此三个关键特性的设计实现方案。
我们的系统在多地都有部署,故缓存服务也做了相应的异地多机房部署,一来可以让不同地区的服务调用本地区服务,无需跨越网络专线,二来也可以作为一种灾备方案,增加可用性。
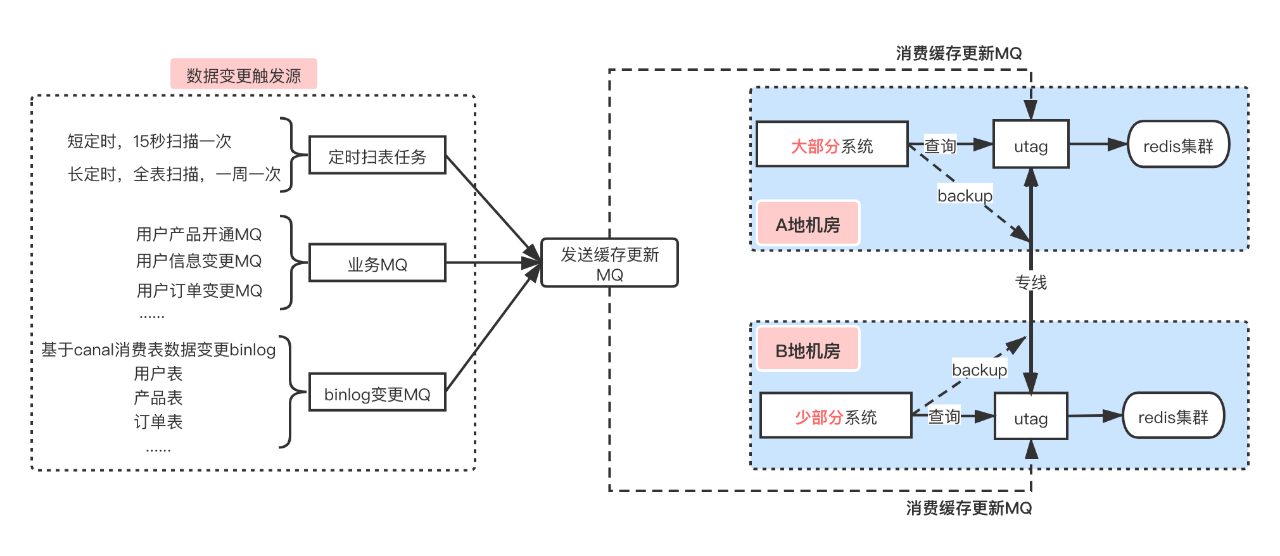
对于缓存的写入,由于缓存服务是独立部署的,因此需要感知业务DB数据变更然后触发缓存的更新,本着“可以多次更新,但不能漏更新”的原则,我们设计了多种数据更新触发源:定时任务扫描,业务系统MQ、binlog变更MQ,相互之间作为互补来保证数据不会漏更新。
此外为了缓存更新流程的统一和与触发源的解耦,我们使用MQ来驱动多地多机房的缓存更新,在不同的触发源触发后,会查询最新的DB数据,然后发出一个缓存更新的MQ消息,不同地区机房的缓存系统同时监听该主题并各自进行缓存的更新。对于MQ我们使用携程开源消息中间件QMQ 和 Kafka,在公司内部QMQ和Kafka也做了异地机房的互通。
对于缓存的读取,utag系统提供dubbo协议的缓存查询接口,业务系统可调用本地区的接口,省去了网络专线的耗时(50ms延迟)。在utag内部查询redis数据,并反序列化为对应的业务model,再通过接口返回给业务方。
为了描述方便,以下异地多机房部署统一使用AB两地部署的概念进行说明。
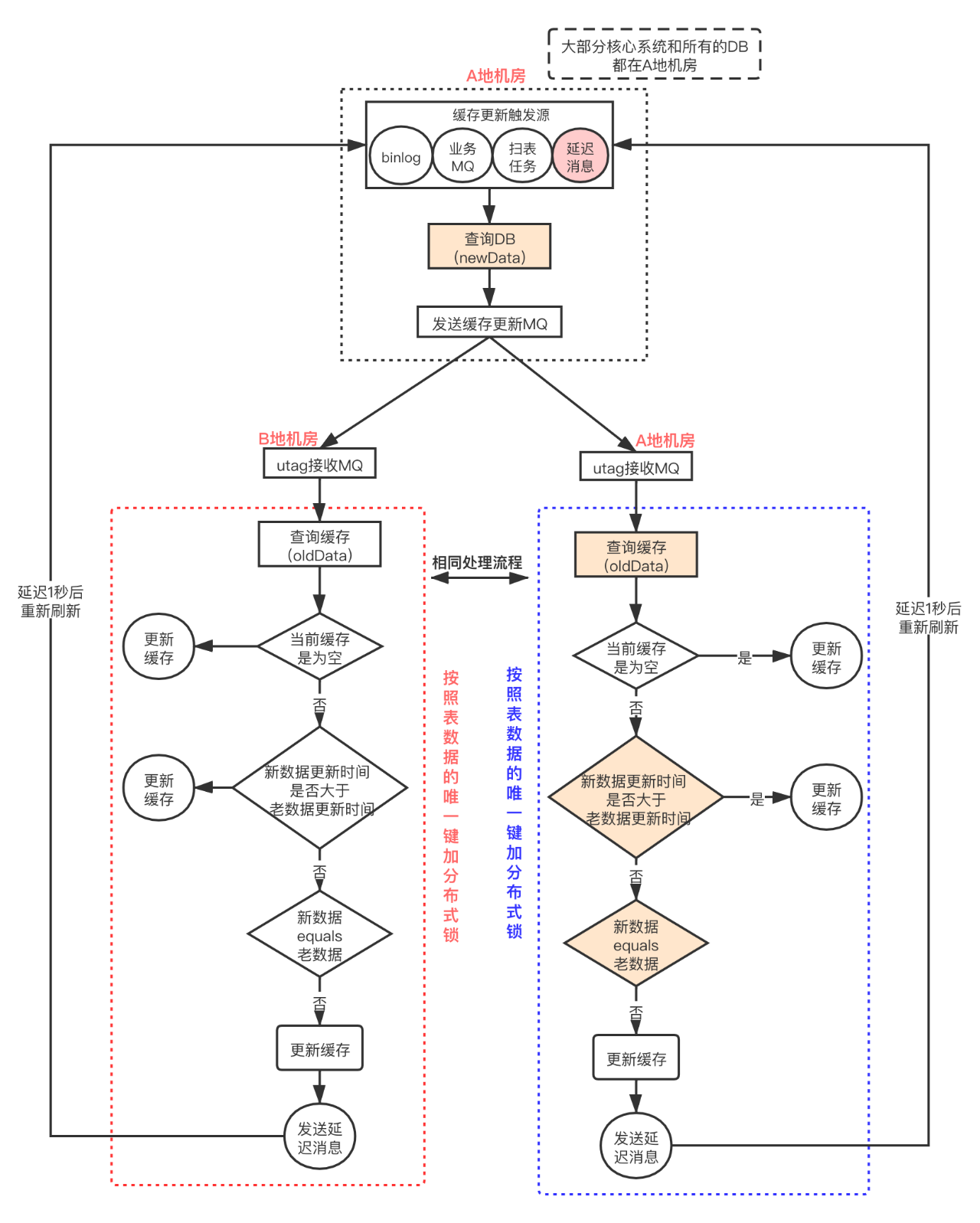
不同的触发源,对缓存更新过程是一样的,整个更新步骤可抽象为4步:
-
step1:触发更新,查询DB中的新数据,并发送统一的MQ
-
-
-
由于我们业务的大部分核心系统和所有的DB都在A地机房,所以触发源(如binlog的消费、业务MQ的接收、扫表任务的执行)都在A侧,触发更新后,第一步查询DB数据也只能在A侧查询(避免跨网络专线的数据库连接,影响性能)。查询到新数据后,发送更新缓存的MQ,两地机房的utag服务进行消费,之后进行统一的缓存更新流程。总体的缓存更新方案如下图所示:
由于有多个触发源,不同的触发源之间可能会对同一条数据的缓存更新请求出现并发,此外可能出现同一条数据在极短时间内(如1秒内)更新多次,无法区分数据更新顺序,因此需要做两方面的操作来确保数据更新的准确性。
若一条DB数据出现了多次更新,且刚好被不同的触发源触发,更新缓存时候若未加控制,可能出现数据更新错乱,如下图所示:
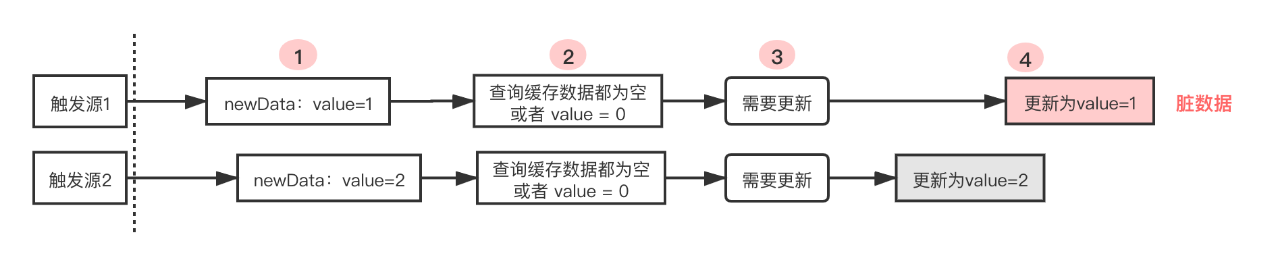
故需要将第2、3、4步加锁,使得缓存刷新操作全部串行化。由于utag本身就依赖了redis,此处我们的分布式锁就基于redis实现。
即使加了锁,也需要进一步判断当前db数据与缓存数据的新老,因为到达缓存更新流程的顺序并不代表数据的真正更新顺序。我们通过对比新老数据的更新时间来实现数据更新顺序的控制。若新数据的更新时间大于老数据的更新时间,则认为当前数据可以直接写入缓存。
我们系统从建立之初就有自己的MySQL规范,每张表都必须有update_time字段,且设置为ON UPDATE CURRENT_TIMESTAMP,但是并没有约束时间字段的精度,大部分都是秒级别的,因此在同一秒内的多次更新操作就无法识别出数据的新老。
针对同一秒数据的更新策略我们采用的方案是:先进行数据对比,若当前数据与缓存数据不相等,则直接更新,并且发送一条延迟消息,延迟1秒后再次触发更新流程。
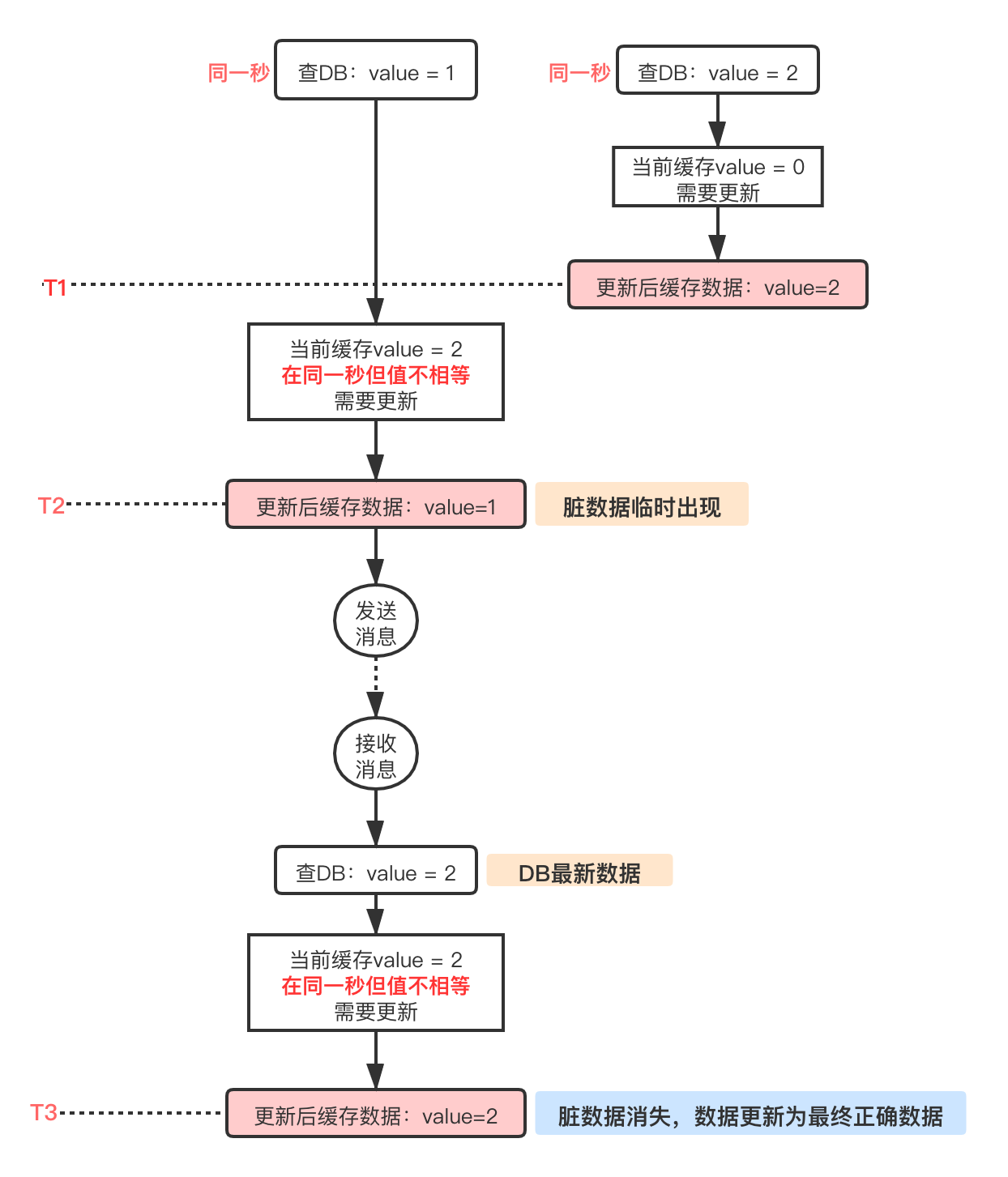
举个例子:假设同一秒内同一条数据出现了两次更新,value=1和value=2,期望最终缓存中的数据是value=2。若这两次更新后的数据被先后触发,分两种情况:
-
case1:若value=1先更新,value=2后更新,(两者都可更新到缓存中,因为虽然是同一秒,但是值不相等)则缓存中最终数据为value=2。
-
case2:若value=2先更新,value=1后更新,则第一轮更新后缓存数据为value=1,不是期望数据,之后对比发现是同一秒数据后会通过消息触发二次更新,重新查询DB数据为value=2,可以更新到缓存中。如下图所示:
通过以上方案我们可以确保缓存数据的准确性。有几个点需要额外说明:
其实不用延迟消息也是可以的,毕竟DB数据的更新时间是不变的,但是考虑到出现同一秒更新的可能是高频更新场景,若直接发消息,然后立即消费并触发二次更新,可能依然查到同一秒内更新的其他数据,为减少此种情况下的多次循环更新,延迟几秒再刷新可作为一种优化策略。
因为删除操作和update操作无法进行数据对比,无法确定操作的先后顺序,进而可能导致更新错乱。而在数据异常宝贵的时代,一般的业务系统中也没有物理删除的逻辑。
可以将查DB、查缓存、数据对比、更新缓存这四个步骤全部放到锁的范围内,这样就不需要处理同一秒的顺序问题。因为在这个串行化操作中每次都从DB中查询到了最新的数据,可以直接更新,而时间的判断、值的判断可以作为优化操作,减少缓存的更新次数,也可以减少锁定的时间。
而我们为何不采用该方案?因为查询DB的操作我们只能在一侧机房处理,无法让AB两地系统的更新流程统一,也就降低了二者互备的可能性。
-
DB数据模型上增加版本字段,可严格控制数据的更新时序。
-
将update_time 字段精度设置为精确到毫秒或微秒,提升数据对比的准确度,但是相比增加版本字段的方案,依然存在同一时间有多次更新的可能。
-
上述数据准确性是从单条数据更新角度的设计,而我们构建缓存服务的目的是替代对应DB表的查询,因此需要缓存对应DB表的全量数据,而数据的完整性从以下三个方面得到保证:
1)“把鸡蛋放到多个篮子里”,使用多种触发源(定时任务,业务MQ,binglog MQ)来最大限度降低单条数据更新缺失的可能性。
单一触发源有可能出现问题,比如消息类的触发依赖业务系统、中间件canel、中间件QMQ和Kafka,扫表任务依赖分布式调度平台、MySQL等。中间任何一环都可能出现问题,而这些中间服务同时出概率的可能相对来说就极小了,相互之间可以作为互补。
2)全量数据刷新任务:全表扫描定时任务,每周执行一次来进行兜底,确保缓存数据的全量准确同步。
3)数据校验任务:监控Redis和DB数据是否同步并进行补偿。
统一缓存服务被多个业务线的核心系统所依赖,所以缓存服务的高可用是至关重要的。而对高可用的建设,除了集群部署、容量规划、熔断降级等常用手段外,针对我们自己的场景也做了一些方案。主要有以下三点:
如上所述,我们的服务在AB两地部署,两机房的缓存通过两地互通的MQ同时写入。在这套机制下,本地区的业务系统可以直接读取本地区的缓存,如果出现了本地区utag应用异常或redis服务异常,则可以快速降级到调用另外机房的服务接口。具体方案如下图所示:

本地业务系统通过dubbo调用本地的utag服务,在utag的本地处理流程中,查询本地缓存前后分别可根据一定的条件进行服务降级,即查询另一机房。
为了避免循环调用,在降级调用前,需要判断当前请求是否来自本地,而此功能通过Dubbo的RpcContext透传特定标识来实现。除此之外,还建立了两机房的应用心跳,来辅助切换。
缓存更新流程通过MQ来驱动,虽然公司的MQ中间件服务由专人维护,但是万一出现问题长时间不能恢复,对我们来说将是致命的。所以我们决定同时采用Kafka和QMQ两种中间件来作为互备方案。默认情况下对于全表扫描任务和binlog消费这类大批量消息场景使用Kafka来驱动,而其他场景通过QMQ来驱动。所有的场景都可以通过开关来控制走Kafka或者QMQ。目前该功能可通过配置管理平台来实现快速切换。
在极端情况下,可能出现Redis数据丢失的情况,如主机房(A机房)突然断网,redis集群切换过程出现数据丢失或同步错乱,此时很可能无法通过自动触发来补齐数据,因此设计了全表快速扫描的补偿机制,通过多任务并行调度,可在30分钟内将全量数据完成刷新。此功能需要人工判断并触发。
以上介绍了我们最终一致性分布式缓存服务的设计思路和要点,其中的关键点为数据准确性、数据完整性、系统可用性的设计。除此之外,还有一些优化点如降级方案的自动触发、异地机房缓存之间、缓存与DB之间做旁路数据diff,可进一步确保缓存服务整体的健壮性,在后续的版本中进行迭代。
强一致性分布式缓存目前主要应用在我们携程金融的消金贷前服务中。随着我们用户量和业务量的增涨,贷前服务的查询量激增,给数据库带来了很大的压力,解决此问题有几种可选方案:
1)分库分表:成本和复杂度相对较高,我们场景下只是数据查询流量较大。
2)读写分离:出于数据库性能考虑,我们的MySQL大部分采用异步复制的方式,而由于我们的场景对数据实时性要求较高,因此无法直接利用读写分离的优势来分担主库压力。
综合来看,增加缓存是更加合适的方案,我们决定设计一套高可用的满足强一致性要求的分布式缓存。接下来介绍我们的具体设计实现方案。
缓存的处理我们采用了较为常见的处理思路:在更新操作中,先更新数据库,再删除缓存,查询操作中,触发缓存更新。

在此过程中,若不加控制,则会存在数据不一致性问题,主要是由于缓存操作和DB更新之间的并发导致的。具体分析如下:
如下图所示,查询时候若缓存已经存在,则会直接返回缓存数据。若查询缓存的操作,发生在“更新DB数据”和“删除缓存”之间,则本次查询到数据为缓存中的老数据,导致不一致。当然下次查询可能就会查询到最新的数据。这种并发在我们服务中是存在的,比如某个产品开通后,会在更新DB(产品开通状态)后立即发送MQ(事务型消息)告知业务,业务侧处理流程中会立即发起查询操作。此场景中数据库的更新和数据的查询间隔极短,很容易出现此种并发问题。
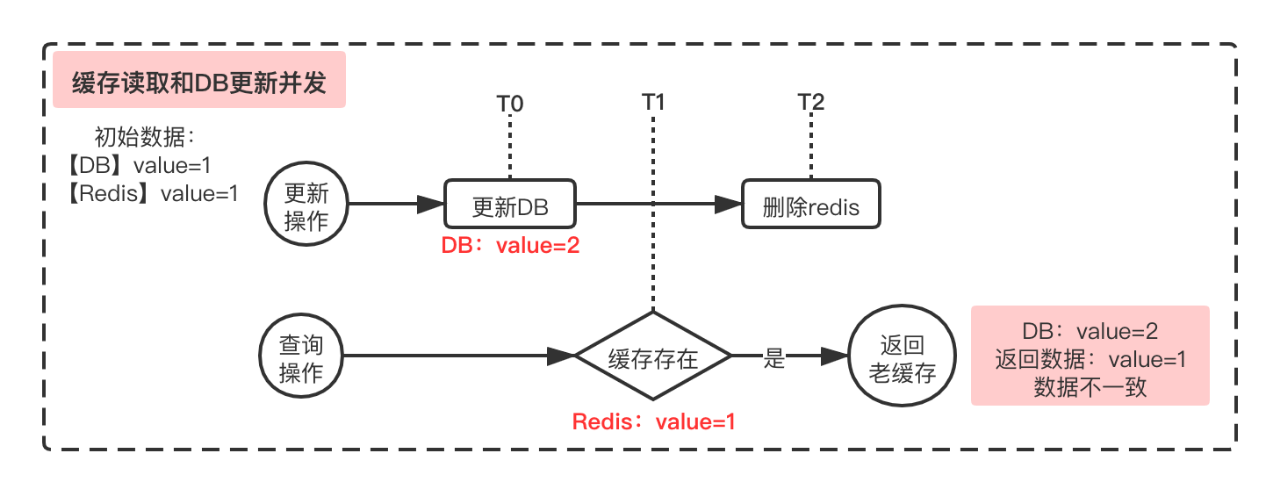
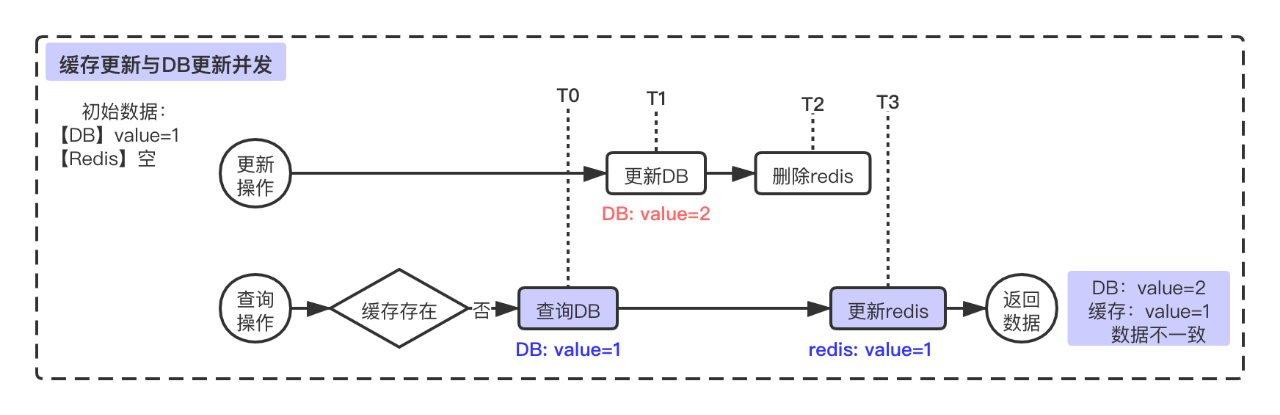
如下图所示,查询的时候,若缓存不存在,则更新缓存,流程是先查询DB再更新Redis。若更新缓存时候,出现以下时序:查询DB老数据(T0时刻,DB中value=1)→ 更新DB(T1时刻,更新DB为value=2)→ 删除Redis(T2)→ 更新Redis(T3),则会导致本次查询返回数据及缓存中的数据与DB数据不一致,即接口返回和更新后的缓存都为脏数据。若T2和T3互换,即更新DB后,先更新Redis,再删除Redis ,由于缓存被删除在下次更新可能会被正确更新,但本次返回数据依然与DB更新后的数据不一致。
基于以上分析,为了避免并发带来的缓存不一致问题,需要将"更新DB"+"删除缓存"、"查询DB"+"更新缓存"两个流程都进行加锁。此处需要加的是分布式锁,我们使用的是redis分布式锁实现。加锁后的读写整体流程如下:
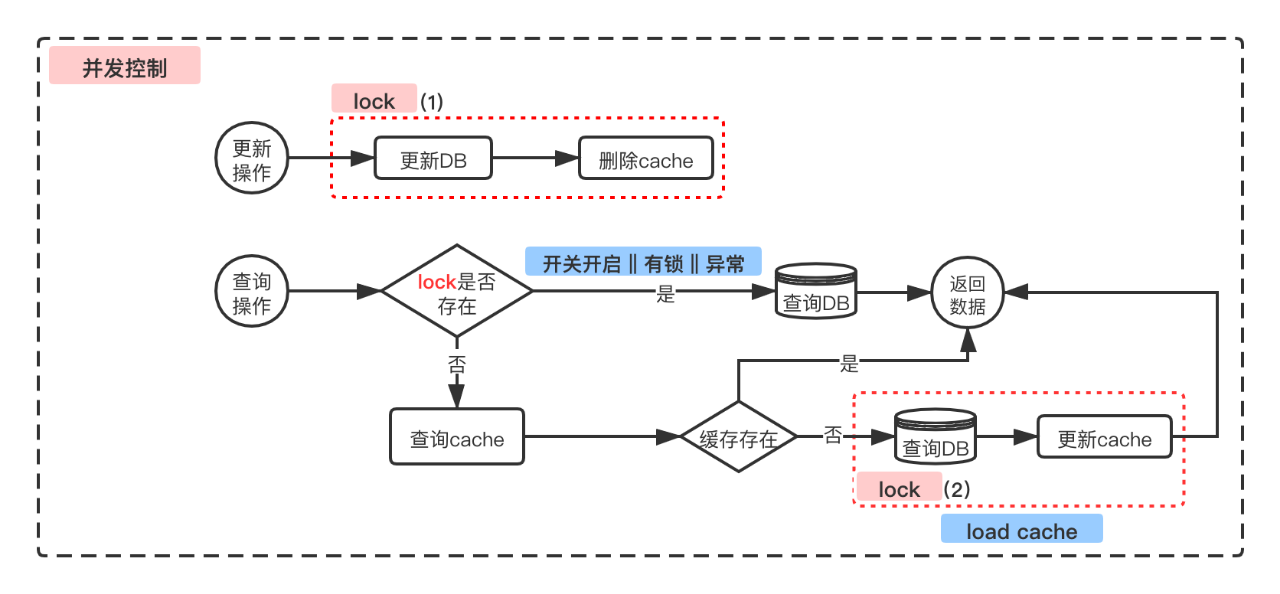
如上图所示,有两处加锁,更新DB时加锁,锁范围为"更新DB"+"删除cache"(图中lock1),更新缓存时加锁,锁范围为"查询DB" + "更新cache"(图中lock2),两处对应的锁key是相同的。基于此方案,对于上面所说的两种并发场景,做针对性分析如下:
查询操作流程中,先判断lock是否存在,若存在,则表示当前DB或缓存正在更新,不能直接查询缓存,在查询DB后返回数据。之所以这么做,还是由场景决定的,如前文所述,我们场景下的基本处理思路是,缓存仅作为“DB降压”的辅助手段,在不确定缓存数据是否最新的情况下,宁可多查询几次DB,也不要查询到缓存中的不一致数据。此外,更新操作相对于查询操作是很少的,在我们贷前服务中,读写比例约为8:1。
此处另外的一个可行方案是可在检测到有锁后可进行短暂的等待和重试,好处是可进一步增加缓存的命中率,但是多一次锁等待,可能会影响到查询接口的性能。可根据自身场景进行抉择。
此外,为了进行降级,在锁判断前也增加了降级开关判断,若降级开关开启,也会直接查询DB。而降级主要是由于redis故障引起的,下文详述。若检测是否有锁时发生了异常同样也会直接查询DB。
查询操作流程中,若缓存不存在,则进行缓存的更新,在更新时候先尝试进行加锁,若当前有锁说明当前有DB或缓存正在更新,则进行等待和重试,从而可避免查询到DB中的老数据更新到缓存中。
其中lock2的流程(load cache),我们是同步进行的。另外一个可行的方案是,异步发起缓存的加载,可减少锁等待时间,但是若出现瞬时的高并发查询,可能缓存无法及时加载产生从而频繁产生瞬时压力。可根据自身场景进行抉择。
以上为我们的整体设计思路,接下来从实现的角度分别描述一下基于本地消息表的缓存删除策略,缓存的降级和恢复这两个方面的具体方案。
在更新操作中,在锁的范围内,先更新DB,再删除缓存。
其中锁的选型,我们采用与缓存同介质的redis分布式锁,这样做的好处是若因为redis服务不可用导致的锁处理失败,对于缓存本身也就不可用,可以自动走降级方案。
此外,更新流程还要考虑两点:锁的范围和删除缓存失败后如何补偿。
方案一:事务提交后加锁,只锁定删除缓存操作。对原事务无任何额外影响,但是在事务提交后到删除缓存之间存在与查询的并发可能性。
方案二:在事务提交前加锁,删除缓存后解锁。在满足一致性要求的前提下,锁的粒度可以做到最小,但是增加了DB事务的范围,若redis出现超时则可能导致事务时间拉长,进而影响DB操作性能。
方案三:在事务开始前加锁,删除缓存后解锁。锁的范围较大,但是能满足我们一致性要求,对单个DB事务也基本无影响。且对同一个用户来说,贷前数据的更新并不频繁,锁范围稍大一些是我们可以接受的。
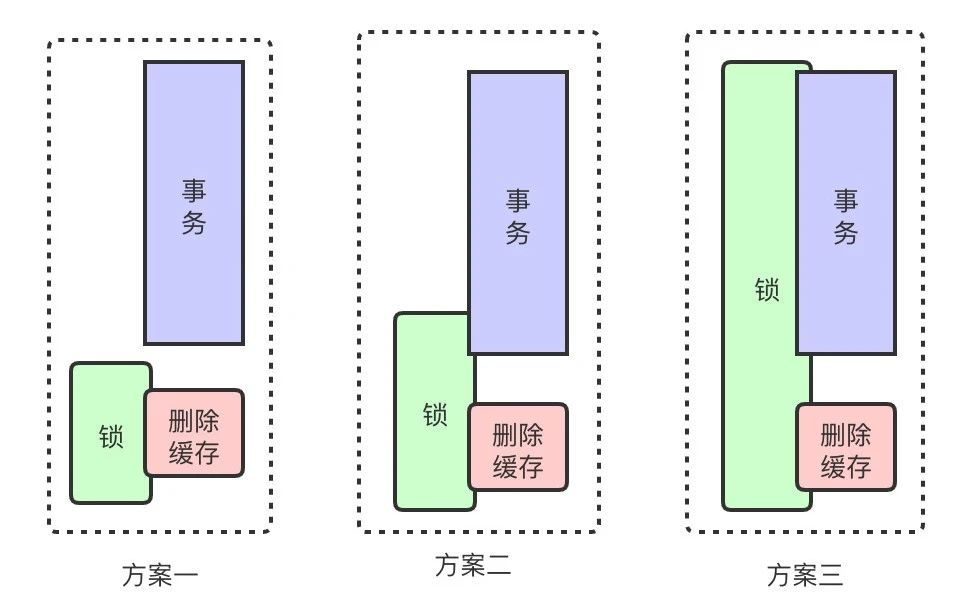
立足自身场景,权衡一致性要求和服务性能要求,我们剔除了方案二,默认情况下使用方案三,但是若在事务开始前加锁失败,为了不影响原业务流程(缓存只是辅助方案,redis故障不影响原应用功能)会自动降级到方案一,即在事务提交后删除缓存前再加锁。而这种降级,若出现并发的查询操作,依然可能出现上述不一致的问题,但是是可以容忍的,原因如下:
通常情况下加锁失败是由于操作redis异常或者锁竞争引起的。
若出现redis异常,同时出现了并发的查询,而并发的两个操作时间间隔是极短的,因此查询时候,锁检测操作通常也是异常的,此时查询会自动降级为查询DB。
若极短时间内的redis集群抖动,事务执行前redis不可用,事务执行后redis恢复,而此时在加锁操作还没有完成前恰巧又进行了并发的查询操作,检测锁成功且锁不存在,才可能会出现查询出老数据的情况。这种是极其严苛的并发条件。
而加锁过程会进行重试(可动态调整配置),多次重试后可解决大部分的锁竞争情况。
综上,在上述锁降级的方案下,数据不一致出现的情况虽然无法完全避免,但是产生条件极其苛刻,而应对这种极其极端的情况,在系统层面做更加强的方案带来的复杂度提升与收益是不成正比的,一般情况下做好日志记录、监控、报警,通过人工介入来弥补即可。从该方案上线后至今两年多的时间内,没有出现过该情况。
另外要考虑的问题是,如果更新DB成功但删除缓存失败要后如何处理,而此种情况往往因应用服务器故障、网络故障、redis故障等原因导致。
若应用服务器突然故障,则服务整体不可用,跟缓存就没多大关系了。若是由于网络、redis故障等原因导致的删除缓存失败,此时查询缓存也不可用,查询走DB,但需要可靠地记录下哪些数据做了变更,待redis可用后需要进行恢复,需要将中间变更的记录对应的缓存全部删除。
此处的一个关键点在于数据变更的可靠性记录,受到QMQ事务消息实现方案的启发,我们的方案是构建一张简易的记录表(代表发生变更的DB数据),每次DB变更后,将该变更记录表的插入和业务DB操作放在一个事务中处理。事务提交后,对应的变更记录持久化,之后进行删除缓存,若缓存删除成功,则将对应的记录表数据也删除掉。若缓存删除失败,则可根据记录表的数据进行补偿删除,而在redis的恢复流程中,需要校验记录表中是否存在数据,若存在则表示有变更后的数据对应的缓存未清除,不可进行缓存读取的恢复。
此外删除操作还要进行异步重试,来避免偶尔超时引起的缓存删除失败。此方案整体流程如下:
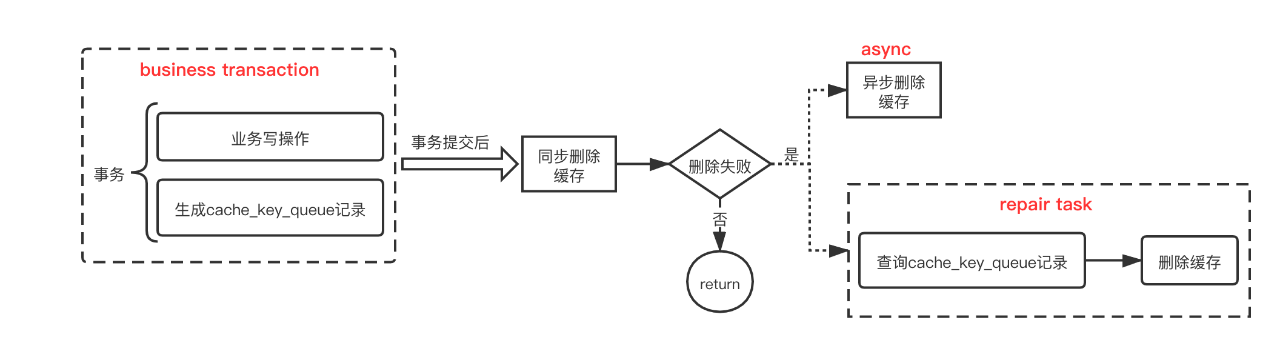
其中cache_key_queue表即为我们的变更记录表,放在业务的同DB内。其表结构非常简单,只有插入和删除操作,对业务DB的额外影响可以忽略。
CREATE TABLE `cache_key_queue` (
`id` bigint(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '主键', `cache_key` varchar(1024) NOT NULL DEFAULT '' COMMENT '待删除的缓存key', `create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', PRIMARY KEY (`id`)) ENGINE = InnoDB AUTO_INCREMENT = 0 CHARSET = utf8 COMMENT '缓存删除队列表'
基于以上分析,为了锁范围尽可能小,且为了尽可能降低极端的redis抖动情况下产生的影响,我们期望可以在事务提交后立即触发缓存的删除操作。为了能够对redis不可用期间发生变更的数据进行清除,我们需要可靠地记录数据变更记录。幸运的是,基于Spring的事务同步机制 TransactionSynchronization,可以很容易实现该方案。简单来说,该机制提供了Spring环境中事务执行前后的AOP功能,可以在spring事务的执行前后添加自己的操作,如下所示(代码和注释经过了简化):
public interface TransactionSynchronization extends Flushable {
void suspend();
void resume();
void beforeCommit(boolean readOnly);
void beforeCompletion();
void afterCommit();
void afterCompletion(int status);}
基于此机制,我们可以很方便且相对优雅地实现我们的设计思路,即在 beforeCommit方法中,插入cache_key_queue记录;在 afterCommit方法中同步删除缓存,若删除缓存成功则同步删除cache_key_queue表记录;在afterCompletion方法中进行锁的释放处理。若同步删除缓存失败,则cache_key_queue表记录也会保留下来,之后触发异步删除,并启动定时任务不断扫描cache_key_queue表进行缓存删除的补偿。需要注意的是可能存在嵌套事务,一个完整事务中,可能存在多次数据更新,可借助ThreadLocal进行多条更新记录的汇总。
除了上述锁处理流程中讨论的redis抖动问题外,还需要考虑缓存服务redis集群不可用(网络问题、redis集群问题等)。按照我们的基本原则,引入的缓存服务仅做辅助,并不能强依赖。如果缓存不可用,主业务依然要保持可用,这就是我们接下来要讨论的缓存的熔断和恢复。
熔断的目的是在redis不可用时避免每次调用(查询或更新)都进行额外的缓存操作,这些缓存操作会进行多次尝试,比如加锁操作我们设置的自动重试3次,每次间隔50ms,总耗时会增加150ms。若redis不可用则每次调用的耗时都会有额外增加,这对主业务功能可能会产生影响,降低底层服务的质量和性能。因此我们需要识别出 redis不可用的情况,并进行熔断。
我们的熔断判断逻辑为:每个redis操作都try-catch异常,并做计数统计(不区分读写操作),若在M秒内出现N次异常则开启熔断。我们的场景下设置为10秒内出现50次异常就熔断,可根据自身场景设置,需要注意的是如果redis请求次数比较少,则需要在配置上保证在M秒内至少出现N次请求。
此外熔断开关的配置是放在应用服务器的内存中,即单机熔断,而非集群熔断,这样做的原因是,redis服务不可用有可能是单机与redis服务的连通性问题导致,而在其他机器上依然可以访问缓存。
熔断之后的恢复策略相对复杂一些,需要区分缓存的读操作恢复和写操作恢复。具体如下流程如下:

判断逻辑为,连续发起特定的set操作N次,每次间隔一定时间,若都成功,则认为redis恢复。
此处需要注意的是,我们的redis集群是Cluster模式,不同的key会散落在不同的redis主节点上,因此最保险的做法是判断当前集群中所有的主节点都恢复才认为操作恢复,而简单的做法是每次探测恢复的set操作都设置不同的key以求能尽可能散列到不同的节点去。可按照自身场景进行方案抉择。
若redis恢复,缓存的写操作就可以恢复了。即可在更新操作中进行加锁、更新DB、删除缓存。但是此时读操作还不能立即恢复,因为redis不可用期间发生了DB变更但是缓存并没有变更,依然为老数据,因此需要将这部分老数据剔除后才能恢复读操作。
-
step3:校验挤压的cache_key_queue记录
轮训查看cache_key_queue表中是否有记录存在,若存在记录则认为当前有不一致的缓存数据,需要等待定时任务将暂存的key表记录对应的缓存全部删除(同时也会删除cache_key_queue表记录)。
若当前不存在cache_key_queue记录则可恢复读操作。
以上阐述了redis缓存的自动熔断和恢复方案。需要明确的是,能够进行熔断是有前提条件的,即应用完全去掉缓存,DB还是可以抗住一段时间压力的,否则一旦出现缓存服务故障,流量全部走到应用,超过了应用和DB的承受能力,将服务压垮,后果更加严重。所以不能强依赖熔断机制,不能强依赖缓存,而这就需要接口限流等其他手段来从整体上保证服务的高可用。此外可进行定期压测,来锚定服务性能上限,进而不断优化对各种策略和资源的配置。
以上描述了我们强一致性缓存方案的设计思路及一些实现细节。基于该方案,我们核心数据库的QPS降低了80%,缓存的命中率达到92%。而该方案的关键是通过加锁来控制读写,从表面上看会牺牲一些性能,但是实际上高缓存命中率同样弥补了此缺陷,缓存的建立使得我们服务查询接口AVG响应时间降低了10%左右。

以上分别描述了我们的最终一致性和强一致性缓存设计和实现思路。两套缓存方案侧重点各有不同:
最终一致性场景的基本思路是:读缓存优先,数据可以容忍暂时不一致,因此重点在及时补偿。
强一致性场景的基本思路是:读DB优先,缓存仅作为“DB降压”的辅助手段,在不确定缓存数据是否最新的情况下,宁可多查询几次DB,也不要查询到缓存中的不一致数据。
此外,我们的最终一致性缓存方案是独立的缓存服务,而该强一致缓存方案,是需要嵌入到应用系统中去使用的。方案的选择需要立足于自身场景,希望我们的分享能够给大家带来一些启发。
来源丨公众号:携程技术(ID:ctriptech)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721