
一、前言
现在还依稀记得去年双11在支付宝作战室,接近0点的时候,所有人都盯着值班室的秒级监控大盘,当交易峰值曲线慢慢爬升,最后变得无比陡峭,值班室的同学都很激动,欢呼声伴随着爬升的曲线达到了顶峰,58.3万笔/秒,也是新的交易峰值记录,但相比往年动辄翻一倍,涨30%~40%,增长率还是小了很多。
2010年双11的支付峰值是2万笔/分钟,到2017双11时变为了25.6万笔/秒,再到去年的58.3万笔/秒,是09年第一次双11的一千多倍。
要抗住这么大的支付TPS,蚂蚁做了很多顶层架构的设计和底层实现的优化,其中最为最核心的就是LDC架构。
二、什么是LDC
LDC 的全称为: Logic Data Center, 逻辑数据中心,之所以叫LDC,是跟传统的IDC( Internet Data Center )相比而提出来的概念。
IDC 相信大家都很清楚,就是物理的数据中心,说白了就是能够建站的物理机房。
LDC(逻辑数据中心),核心架构思想就是不管你物理机房部署是怎样的,比如你可能有三个IDC,分别在二个不同城市(常说的两地三中心),在逻辑上是统一的,我逻辑上看成一个整体,统一协调调配。
三、为什么会出现LDC
LDC是为了解决什么问题?还得从架构的演进说起。我们用具体的应用推演一次。
1)单体应用架构
先看如下图所示的单体应用架构,请求到网关接口,网关接口直接调应用或者服务,服务调存储层查询或写入数据,一竿子捅到底。
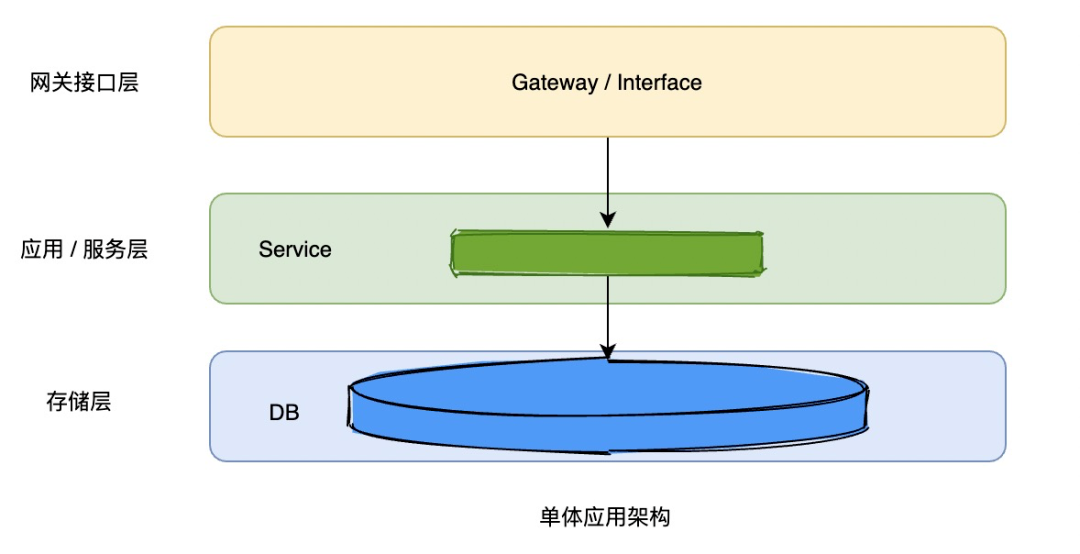
这种架构模式最大的风险是服务、存储都是单点的,访问容量和性能受限于存储和应用的容量和性能,容灾方面,一旦发生故障只能死等单点应用或存储的恢复。
2)分布式架构
后来工程师们开始对应用做水平拆分,对服务做垂直拆分。
水平拆分应该都很熟悉,就是加服务器,每台服务器都部署实例,垂直拆分就是把服务按域做拆分,比如一个交易系统,有商户域、商品域、用户域、订单域等,拆分成多个微服务,服务解耦,服务可以独立发布,应用的复杂度会更高。
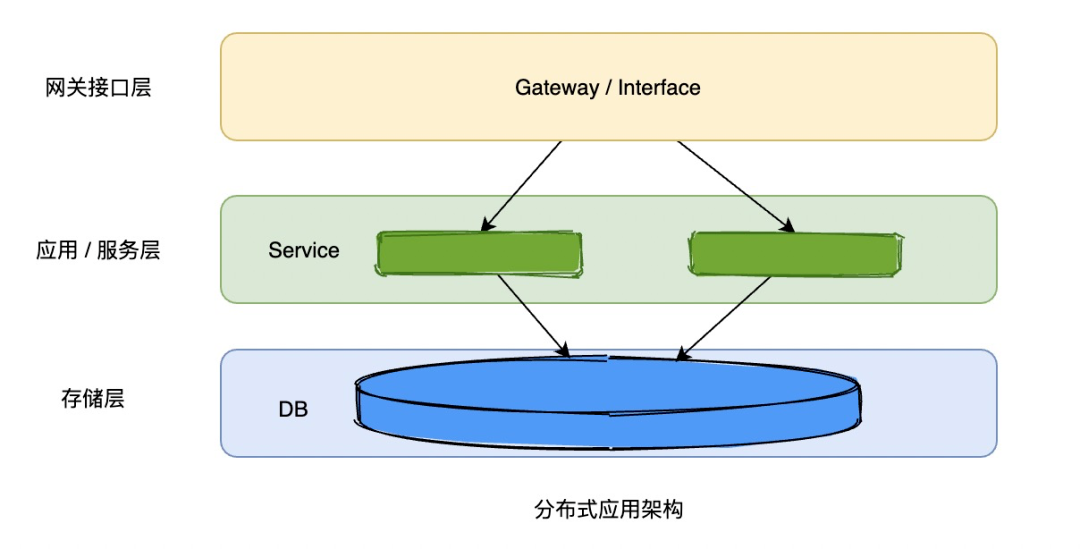
这个分布式架构解决了服务单点的问题,某台服务器宕机,服务还是可用的,但是存储层还是单点的,而且随着业务增长,扩容加的机器越多,大家发现查询写入效率耗时到一定阶段反倒是变慢了,分析发现存储层出现了性能瓶颈。上面图只花了2台服务器连接数据库,真实分布式系统可能几十百来台,甚至上千台,如果都连一台DB,连接数、锁争用等问题, SQL性能变慢可想而知。
3)读写分离架构
后来的事情大家也都知道,互联网公司开始纷纷做读写分离,把读请求和写请求分开。
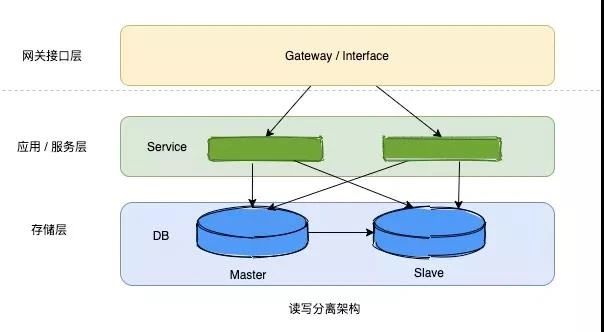
读写分离这里面隐含了一个逻辑,那就是数据写入之后,不会立即被使用。
数据从写入到被立即使用有个时间差,等从库同步数据才会被读取,实际统计发现,常规的应用,90%的数据确实在写入之后不会立即被使用,当然我这里说的立即的时间单位是ms,一般同步延迟也就是几毫秒,不超过10 ~20ms。
4)分库分表分布式架构
但是这个架构并没有解决写的问题,随着业务量的增长,写数据成为了瓶颈。分库分表应运而生,分库分表的中间件开始变得流行起来,现在基本成了中大型互联网公司的标配。
基本思想就是把数据按照指定维度拆分,比较常见的是userId维度,例如取userId的后2位,可以拆分成百库百表,也有的除以指定模数取余数,例如除以64取余,可以按余数范围0-63拆成64个库。
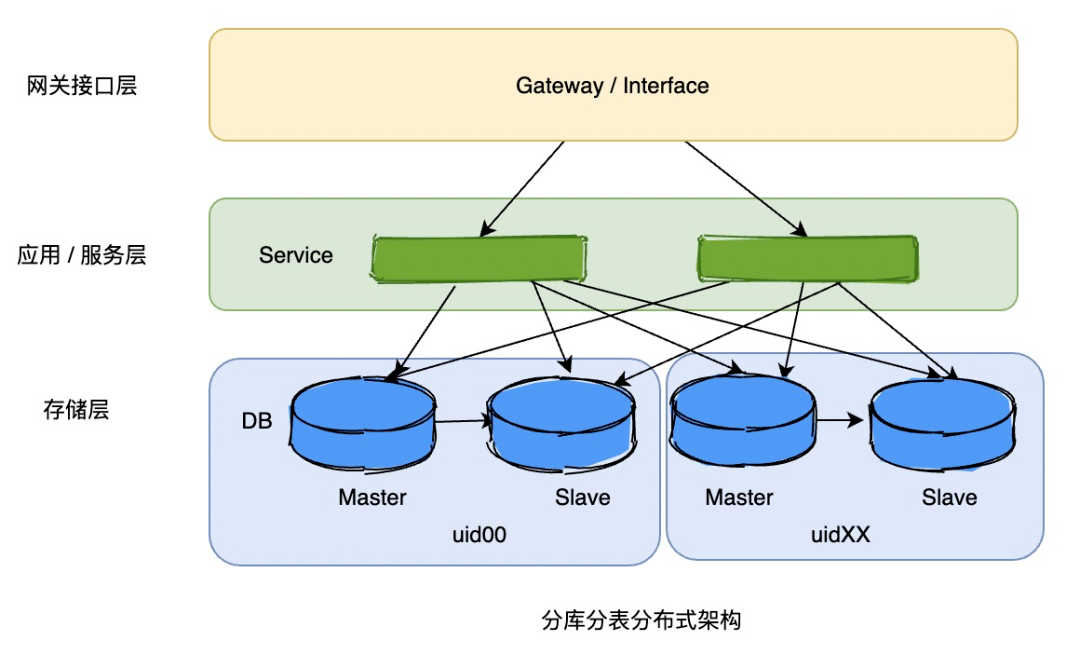
关于分库分表,很多人都知道有垂直拆分和水平拆分二种(上面说的垂直和水平是系统的拆分,这里指的是存储的),垂直拆分就是按照业务维度拆分,把同一个业务类型的表放到一个库,经常会按领域模型的概念拆分,比如订单库、用户库、商品库等,水平拆分就是把大数据量的表(库)切分成很多个小数据量的表(库),减小库和表的访问压力,可以和系统的水平垂直切分比一下:

为什么叫水平和垂直呢?其实很好理解,你想象一张用户表,里面放了很多字段,如下图:

那垂直拆分,就是垂直从中间划一刀,把蓝色的用户信息表和右边绿色的订单信息表拆分成2张表。库拆分成用户库和订单库。
水平拆分,就是水平划一刀,把数据量降低。
大家看到这,是不是以为问题都解决了,上面分库分表之后,如果应用层面扛得住,数据库层面的确能做到并发量到万这个级别。但是容量要再上一个数量级就有点困难了。
5)单元化分布式架构
因为一个库实例是被所有应用共享的,也就是你每增加一台机器,数据库连接就会相应的增加一些,增量是至少机器设置的最小连接数。
①为什么应用需要连接所有的数据库实例?
网关层的流量可能走到任何一台服务器,比如A用户的请求到服务器上了,这时服务器一定要有A这个用户userId 分片的数据库连接,否则要么把流量路由走,要么执行失败。
分库分表只是解决了单库单表访问压力的问题,但是由于每一台服务器都同时连接所有的分库实例,到一定阶段是没发继续扩容的,因为库实例的连接数有瓶颈。
②数据库存在瓶颈应该怎么弄?
相信聪明的你们其实已经猜到了,那就是按userId 分片在应用层就做隔离,在网关层流量路由的时候把指定uid分片的流量路由到指定应用单元执行,这个应用单元流量内部自消化,如下图:
比如uid = 37487834,最后二位是34 属于 00-49范围,那用户流量直接路由到00-49这个应用分组,在这个单元内的完成所有数据交互的操作。

这样uid 00-49 这个分组单元中的应用只用连userId 00-49 分库的数据库,uid 50-99分组单元的应用也是如此,数据库的连接数一下直接降一半,而且还可以拆分单元,现在是2个单元,最多可以拆分到100个单元。
而单元是LDC中核心概念,下面重点说一下单元这个词的具体含义。
单元在蚂蚁有个名称叫做 Zone,Zone内部署的是完整的服务,例如,一个用户在一个Zone内可以完成一整套业务流程,流量不需要其他Zone 来提供服务,拥有完成一整套服务的能力,在单个Zone就能完成一整套业务,是逻辑自包含的,这样有什么好处,某个Zone如果出现故障,路由层直接把这个Zone流量转移到其他Zone,接受这个Zone流量的其他几个Zone可以分摊流量,流量调拨很方便。
下面这张图是蚂蚁Zone 按照地区和userId 分片的部署架构示意图,做了一些简化,实际Zone部署单元会稍微复杂一点。
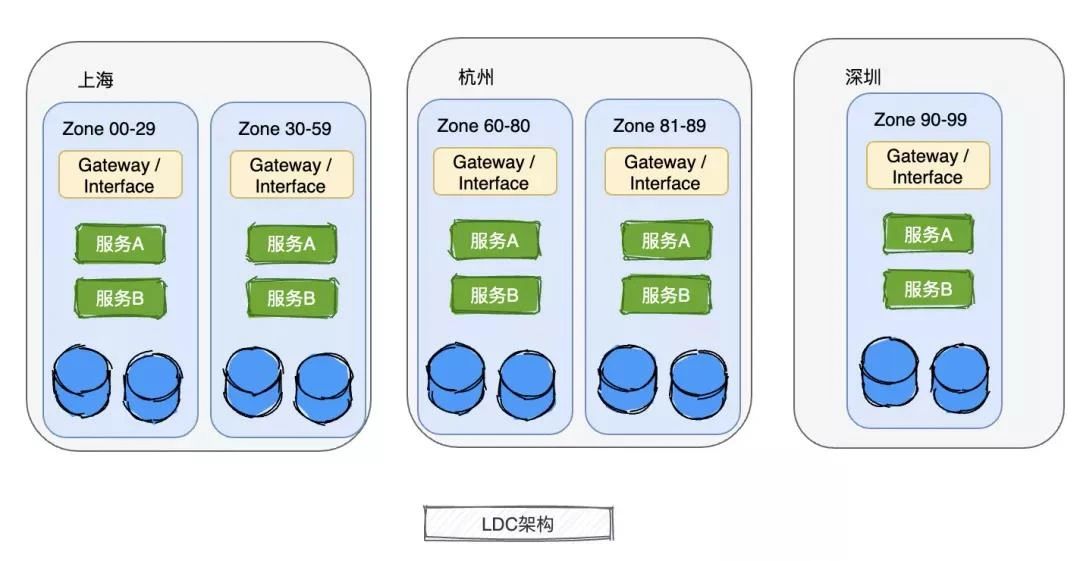
上面介绍的Zone 是有能力完成uid维度的一整套业务流程的,应用互相依赖的服务都由本Zone提供,服务之间的调用都在本Zone内完成的。但是聪明的你可以会想到一个问题,有的数据不能按照userid维度拆分,全局只有一份怎么搞,比如配置中心的数据,那是集中存储的,全局只有一份配置,配置后也是全局生效。
其实在蚂蚁内部,Zone一共分为三种:RZone、GZone、CZone
RZone: 上面说的逻辑自包含的,业务系统整体部署的最小单元,能够按照userId维度拆分服务和库的都部署在RZone内。
GZone:GZone是Global Zone,听这个名字,也知道,GZone的服务和库全局只会部署一份,一定是在某个机房的,异地也会部署,但是只是为了灾备,不会启用。
CZone:CZone比较有意思,为什么会有CZone,是为了解决GZone的弊端而产生的,上一篇《从B站崩了看互联网公司如何做好高可用》架构文章里面讲过,跨城调用,因为距离原因耗时比较高,如果GZone的服务部署在上海,杭州机房的服务需要用到GZone部署的服务,只能跨城跨机房调用,很可能一个服务有很多次rpc调用,这样耗时一定会很爆炸,那怎么弄?在城市与城市之间架起一座数据同步的桥梁,CZone就是起到了桥梁的作用,负责把GZone的数据在城市之前同步,C是city的意思。
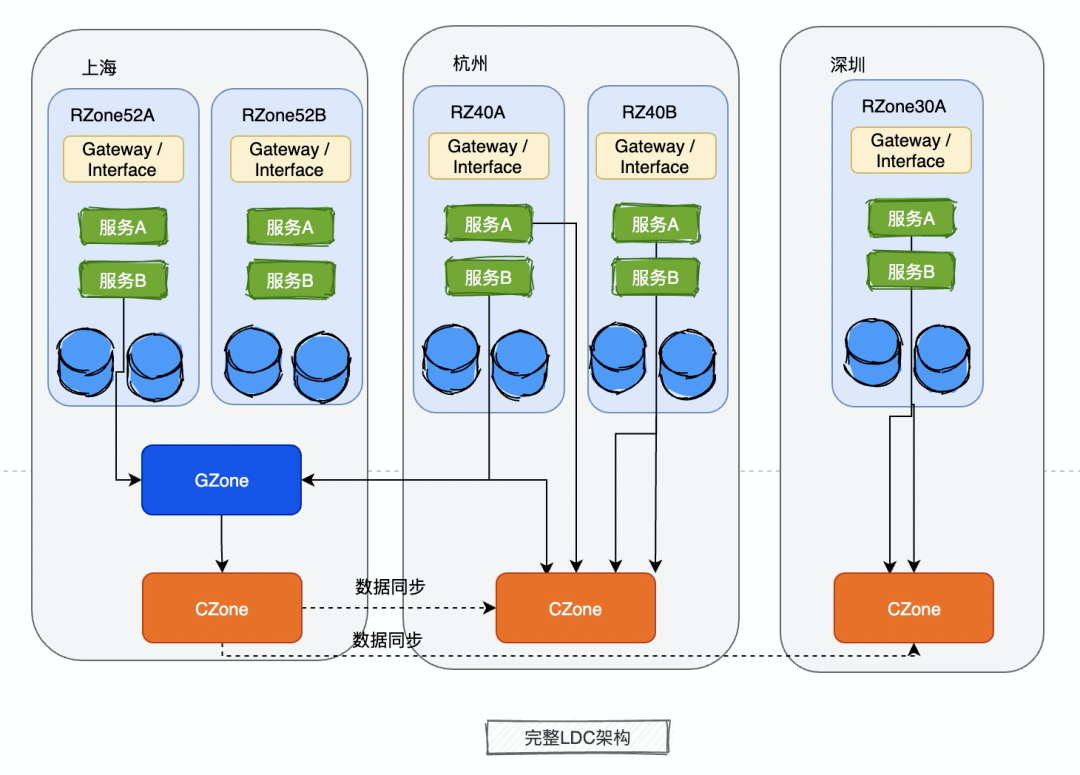
也是因为前面我提到的“写读时间差现象”,写入GZone的数据,允许一定的延迟,同步CZone同步给其他CZone。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721