
作者介绍
杨森,达达集团DevOps & SRE 负责人,专注于提升分布式系统的稳定性和可观测性、弹性容量、故障自愈、多云容器架构及效能平台建设。
面对节假日常规促销、618/双11购物节、以及去年初疫情全民线上买菜购物等配送业务订单量的暴增时期,我们通过智能弹性伸缩架构和精细化的容量管理,有效地做到了业务系统对配送全链路履约和服务体验的保驾护航和进一步提升,同时业务低峰期的极限缩容又将弹性发挥到极致,使得我们在成本控制方面获得了不错的收益。
本文将分享在业务量激增和云原生技术升级改造的背景下,达达在弹性伸缩架构方面的探索和推广、精细化的容量管理和策略优化、多云环境和多运行时的适配、指标可观测等方面的实践和收益。
一、弹性容量的重要性及自动扩缩容初探
时间要回到2019年的某次常规促销,鲜花业务待接单在短时间内陡增,消息队列有积压告警后研发先后手动扩容了服务A、B来增加队列的消费能力,之后服务A、B以高于日常N倍的量请求服务C某个接口,继而加剧了服务C集群负载同时该服务的接口响应在逐渐变差,服务C的集群机器开始CPU告警,研发联系运维扩容,接下来等待了19分钟后运维介入扩容了2台服务C(1台成功1台失败),此刻服务C集群中有一半机器CPU被打满,另外一半机器CPU接近80%,App端请求服务C的接口超时,线上业务开始受损,接下来的11分钟,运维扩容x台机器又全部失败,最后只能通过手动拉起上线后,业务才彻底恢复。

复盘整个故障过程,引发了更多的灵魂拷问,比如常规促销是否也需要压测以确保容量是足够的、扩容SOP及成功率和效率的保障、故障处理流程优化、业务设置降级开关等等, 其中容量规划及扩容成功率、效率是运维侧首当其冲要复盘跟进解决的。
如果没有压测,那么如何解决容量规划的问题?
我们的思考是通过弹性容量来应对压力的变化。

上图中,黄线所代表的传统容量规划,在应对时刻变化的业务需求时,要么是资源不足造成系统性能不足,要么是资源浪费。而绿线所代表的弹性伸缩可以实现 “哪些服务应该在哪个时间点扩容多少实例” 以自适应应对业务需求的变化, 这正是我们想要做到的弹性容量。
自动扩缩容之所以可以顺利开展,得益于我们在配置管理引入Apollo、基于Consul实现服务注册发现和数据源高可用、基于OpenResty+Consul的网关实现了upstream节点热更新,并做到了节点无状态。
我们给每个服务设置了一个基准值(最小实例数),并借助于Falcon集群水位告警+弹性配置 实现了第一版的自动扩缩容系AutoScaler,具体如下:
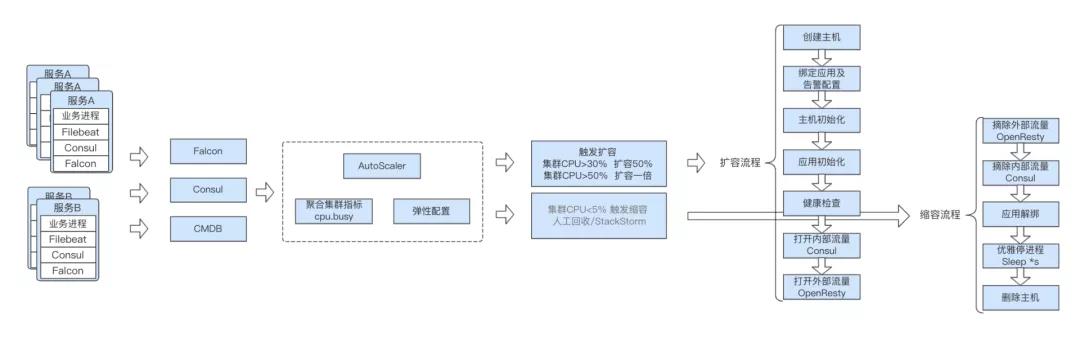
AutoScaler弹性配置如下:
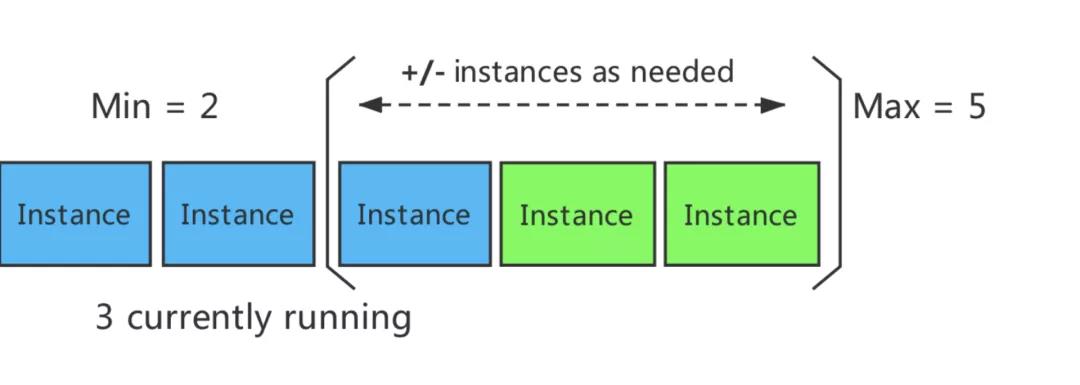
最小实例数:默认2,可调整
扩容:
缩容:
集群CPU水位<5%,告警通知,触发StackStorm回收线上一半实例,且剩余实例数>=最小实例数
第一版弹性扩缩容AutoScaler上线后,主流程的头部服务在高峰期会自动触发扩容,而业务低峰期时更多的服务都在缩容,这表明部分服务之前的容量是过剩的,借助于弹性似乎可以寻找到服务之间合适的比例,成本方面也可以得到一定的平衡。
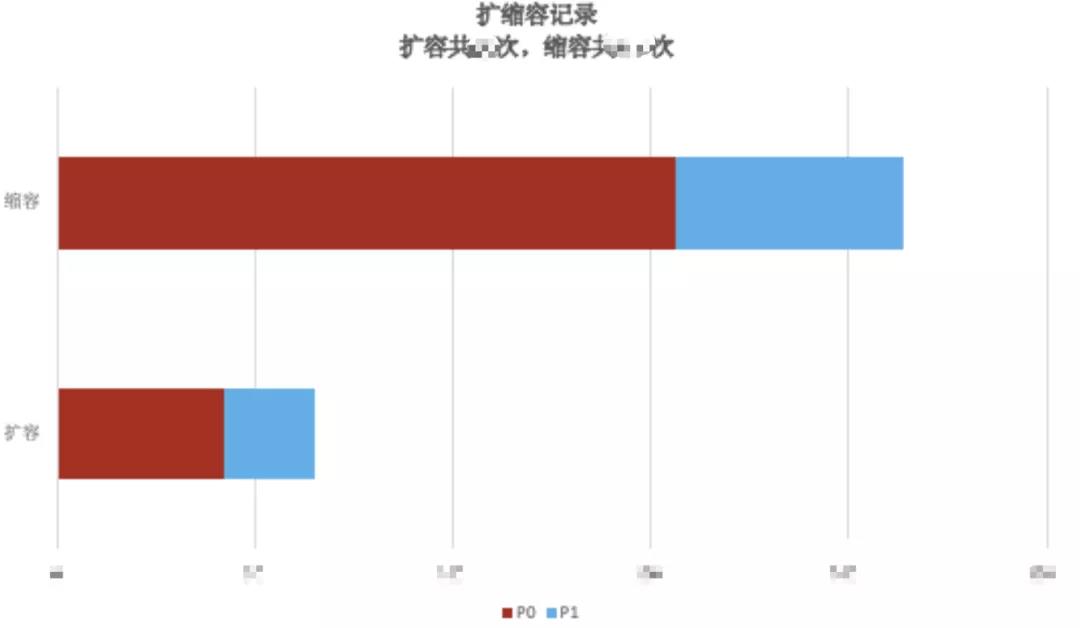
然而,仅仅靠集群CPU水位指标是无法覆盖更多业务场景的,比如某些业务队列积压需要扩容更多的消费者、连接池打满、单机离群(CPU使用率偏高、磁盘IO、网卡进出、错误日志数、接口响应超时等有明显差异的)、单机QPS 等场景需要更多的指标,迫使我们往更深层次考量和设计更加灵活智能的弹性架构。
二、智能弹性架构的思考和设计
毫无疑问,精细化的容量管理对系统持续稳定运行和云成本控制至关重要,而弹性架构又是实现这一问题的核心点。
但是,弹性架构和自动伸缩是一定需要结合实际业务场景来考虑,“从上至下思考,从下至上执行”,我们对问题的分析和拆解如下图:
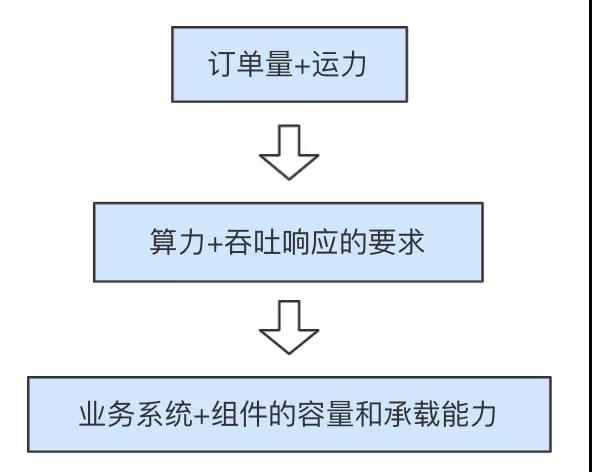
我们需要面对的是,在配送业务订单量和运力之间的实时供需匹配关系下,为保证发单、派单、接单、取货、路径规划和送达等配送全流程各环节的履约 而对业务系统算力和吞吐响应提出稳定性的要求,即底层业务系统和相关组件的容量 需要时刻能稳定地承载上层各种业务。同时,又可以在业务低峰期的时候自动收回冗余资源且不影响用户体验。
这就如同无人自动驾驶这样的场景:既要感知实时路况的同时,也考虑不同时段可能遇到堵车等突发情况,又要满足不同年龄层次的乘客对时间、费用和舒适度的体验要求,还要尽可能省电省油。
自动驾驶系统体系架构图如下:
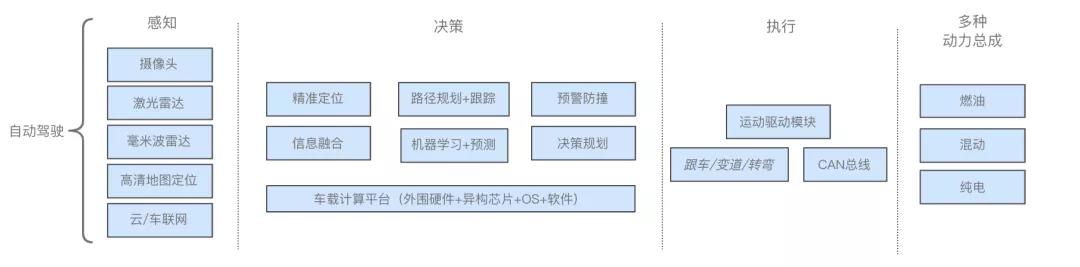
参考如上自动驾驶的架构,且弹性系统需要满足如下需求:
弹性覆盖更多核心服务,且研发可以自助配置弹性策略
支持大促压测链路服务的自动扩容
支持除cpu.busy以外的指标,比如消息队列长队、连接数、DiskIO、错误日志数、接口响应时间、服务端不可达比例等
自定义缩容及极限缩容,以降低成本
弹性对云原生技术改造过程中多运行时、多云的支持
于是,我们围绕 “感知” - “决策” - “执行” 设计了如下弹性伸缩架构:
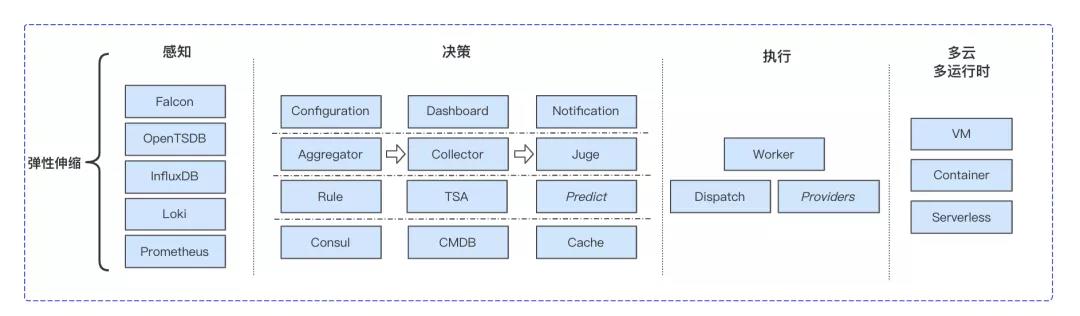
没错,以上即我们从自动驾驶获得的灵感,弹性系统需观测到每个环节涉及服务及关联消息队列等组件相关指标,也就是输入是某个metric,结合策略及时序数据分析,执行相应策略以保障配送全流程的履约率和体验。
感知部分是为了接入更多已有的业务系统观测指标(某个metric),且能适配多种时序数据库。
Falcon:系统监控,如cpu.busy、cpu.switches、mem.memused.percent、disk.io.util、ss.timewait、net.if.total.packets等指标,以及集群机器这些指标的方差来衡量是否离群
InfluxDB:定制化的中间件将服务与服务、服务与缓存和队列的请求及耗时统计均存入Influxdb中,用于monitor业务指标监控
Loki:对info、error日志收集后存入Loki,并直接在granfa上形成metrics,比如error中某个class的Exception异常(对应一类业务场景)的指标数据
Prometheus:支持在云原生技术升级改造过中使用到的Docker和Kubernetes的核心指标监控
OpenTSDB:目前在集群指标聚合时会把多种时序格式统一转换成opentsdb格式形成metric
决策部分是弹性伸缩架构的核心,分为如下几个模块:
Configuration:弹性规则配置入口,研发可自助配置当前服务的最小实例数、所在链路、所在云、扩缩容指标、阈值、速率和开关

Dashboard:弹性扩缩容运行情况实时展示(每个服务当前在线实例数、期望实例数、弹性扩缩实例数、实例成本)
Notification:扩缩容消息通知到企业微信、发送每日扩缩容汇总邮件

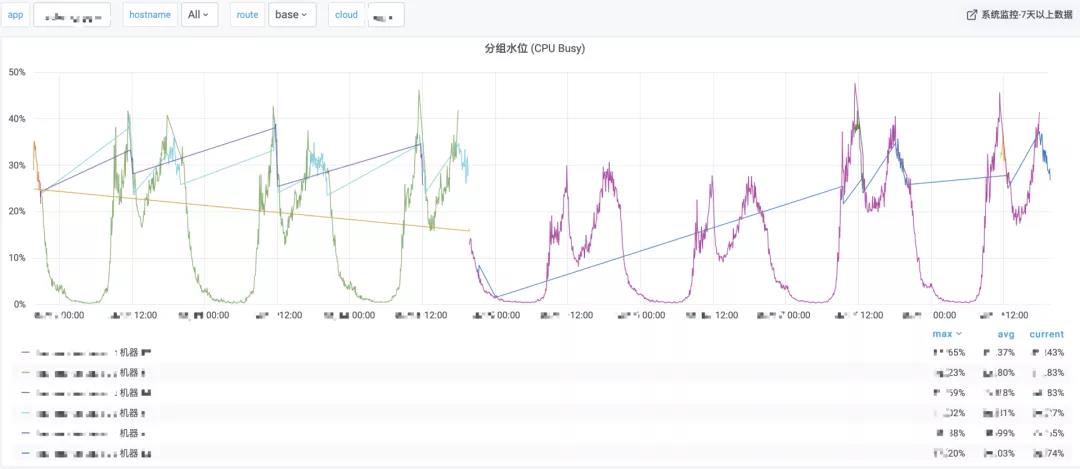
Aggregator:计算并聚合集群指标, 如下图是某服务集群基础分组的cpu.busy的平均水位
Collector:时序数据统一转换到opentsdb并生成metric
Juge:决策引擎
desiredInstances=ceil(currentInstances*(currentMetricValue/desiredMetricValue))
Rule:弹性扩缩总控平台,Configuration的汇总并存入CMDB
TSA:目前采用的是MA3、MA5并结合TP50、TP90做时序数据分析
CMDB+Consul:服务元数据,供Aggregator和Collector计算和生产metric
Cache:缓存Collector和Jude历史数据和决策,辅助下一次决策下发和算法预测
有效执行是弹性容量落地的保障,为了应对上百个服务及对应不同的发布引擎,我们对worker设计了Dispatch和Providers模块:
Dispatch:并发执行扩缩容流程及上下线操作、重试策略、日志审计、以及缩容流程的优化点(和schedulejob的对接加入防止将正在运行的节点回收、跳到白名单机器等)
Providers:抽象统一的扩缩容接口,以适配多种发布系统(deployng、tars、k8s、serverless等)
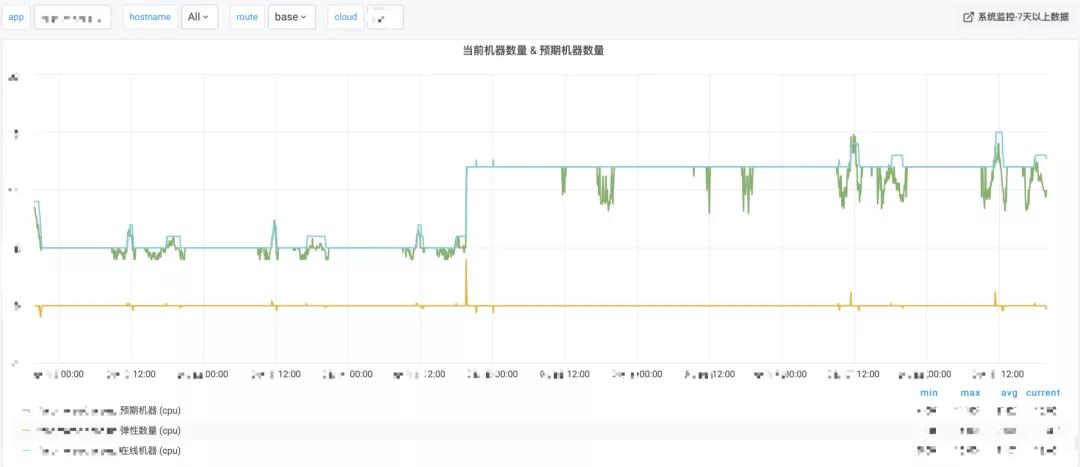
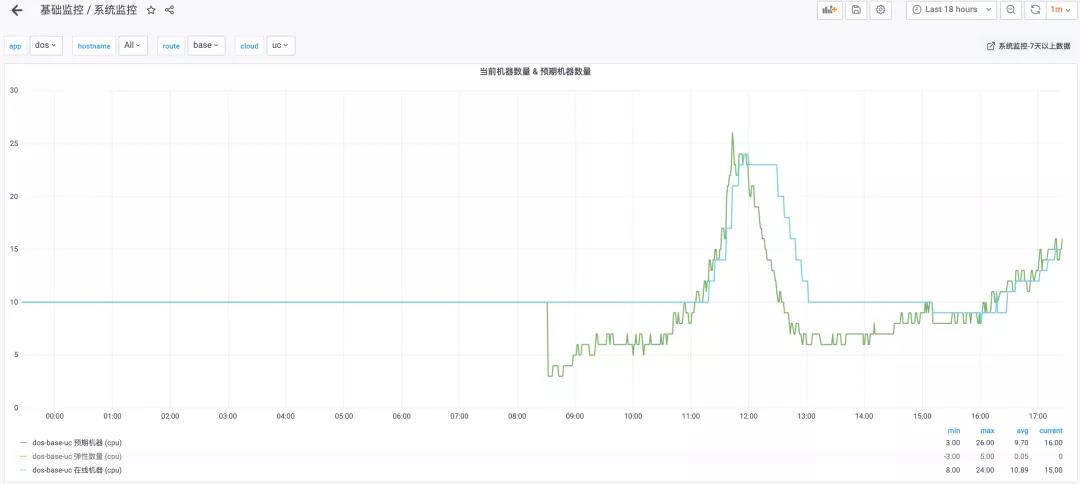
当前弹性扩缩容系统AutoScaler仅用于生产环境的无状态服务,如下图所示,AutoScaler准确捕捉到业务压力的上升趋势并扩容了合适的实例数,上升曲线拟合效果达到预期。
三、弹性扩缩容的落地实践
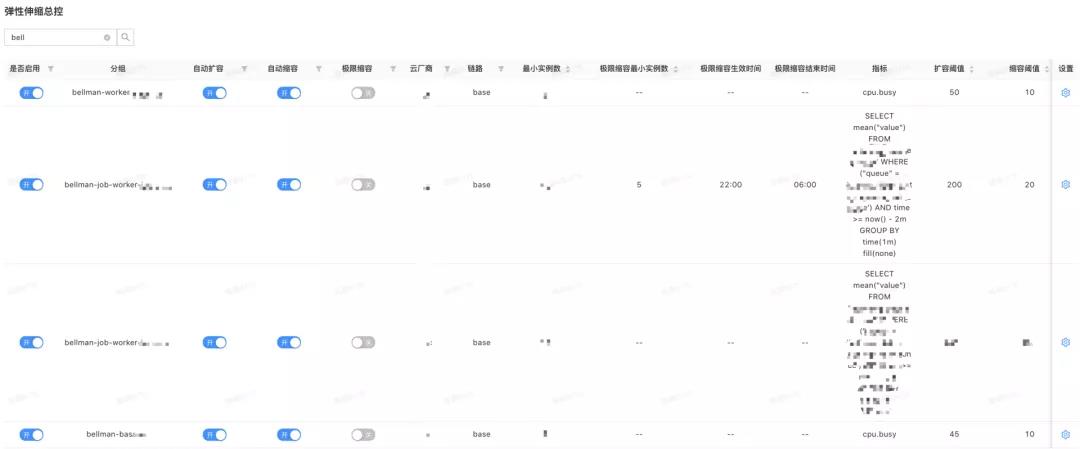
在弹性伸缩系统AutoScaler落地和推广过程中,我们通过在Rule加入更多的字段和开关,更好的满足了业务研发对扩缩容的新需求:
支持基础链路base和压测链路benchmark
支持应用分组group
支持多云cloud
支持分时段的极限缩容
支持多metric协同,并且通过sql语句可适配多种metric,比如队列长度
SELECT sum("value") FROM "*_queue_*" WHERE ("queue" = 'XXXX') AND time >= now() - 5m GROUP BY time(1m) fill(null)
弹性伸缩总控配置面板如下图所示
这里,着重分享3点我们在落地弹性扩缩容过程中遇到的问题和经验。
扩缩容系统能不能随时随地正确的工作,是需要通过经常演练才能确保的。
实际过程我们遇到的情况有如下几点:
弹性核心功能和策略是否如期生效,metric数据聚合的准确度,以及分时段缩容 及多metric协同;扩容实例需要考虑已有节点的多可用区的分布情况,尽量做到多可用均分打散。
对下游发布系统、云资源、扩缩容也需要一并验证,发现问题点和瓶颈点并及时解决。我们曾遇到过账户余额不足、云主机无资源、发布系统多任务有瓶颈、缩容了正在跑job的节点、缩容了不该缩容的节点(其他业务有写死固定IP到/etc/hosts的情况)、缩容太多触发了中间件的兜底策略等。
扩容时刻要坚决扩容,缩容需要应对流量徒增情况,我们引入速率ratio参数有效控制了缩容的速率,从2.3节的图可以证实生产环境自动缩容是缓慢下降的。
不能无止尽无脑的扩容,要有刹车机制:我们和每个服务的研发负责人确认服务的实例最大上限,防止数据源连接池耗尽或者打爆。同时我们也会监控DB的连接和负载并及时做好垂直拆分的预案。
观测大规模并发扩容时,服务依赖的缓存、队列、DB的连接数、主从复制等是否有压力或延时,新加节点是否会造成超时以及线上服务响应有无剧烈抖动等。
每日跟踪扩缩容的核心指标:扩缩容成功率、效率、成本趋势可视化。
为了平衡扩容带来的成本增加,业务低峰期或夜间的极限缩容功能可以有效平衡,毕竟业务是有明显的时间区段。
极限缩容是精细化容量管理的关键点,同时也是弹性系统实现降本的核心点。
极限缩容本身并不复杂,它是把最小实例数在另外一个时段段调成了一个更为激进的数字,难点在于要在这个时间段结束后有效地把最小实例数扩容恢复到原来的数,如下图,即要在06:00新扩容10个实例且要确保100%扩容成功。

如何保证100%成功率?我们一直在努力优化扩容流程的每个环节,包括购买VM、环境初始化步骤和一些base image内置到主机系统镜像、主机启动后预ping全网节点以削弱流表下发延迟带来的和其他已有主机建连的失败概率等等。
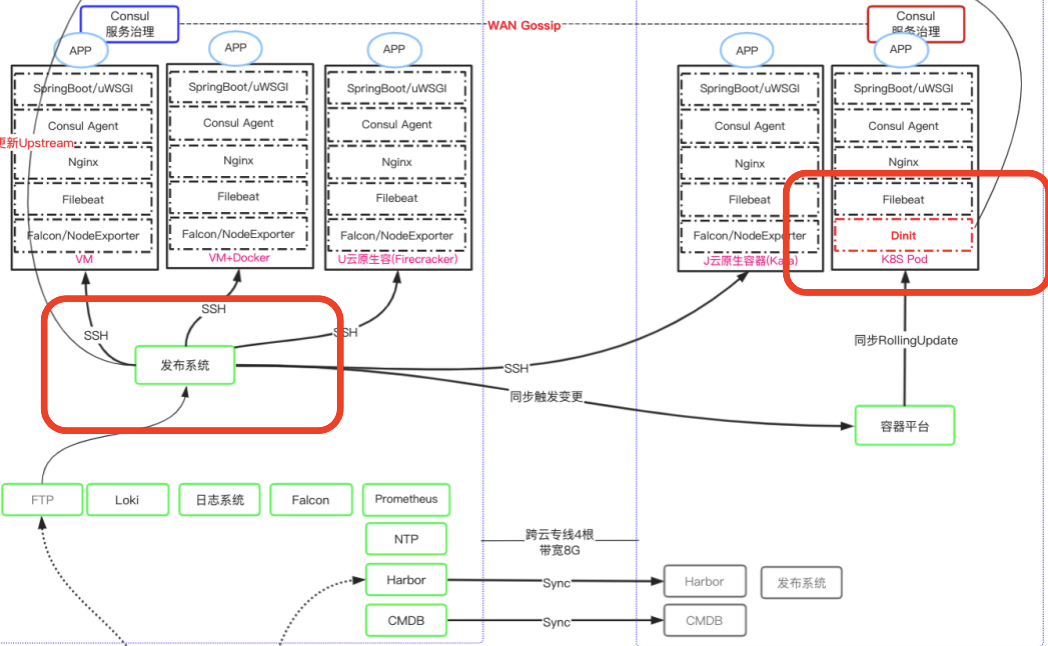
为了实现更确信的扩容成功率和效率,我们引入Container、Kubernetes和Serverless安全容器等云原生技术。
为了兼容并支持VM、VM+Container、Kubernetes、Serverless安全容器等多种运行时
为了保持扩缩容流程标准化的延续
为了实现扩容优雅上线、缩容优雅下线,进程中止/宕机立即停流量止血
我们选择了单Container/Pod多进程的方式,并自研的PID 1进程:从基于dumb_init的shell脚本、再到借鉴systemd守护进程方式的entrypoint,再到当前用go重构的dinit。

通过dinit,我们很好的实现了以下功能
进程管理:容器内多进程的依赖管理,实现进程启动/销毁的顺序和进程存活管理
流量控制:Pod的健康检查通过后会自动推送当前节点到Consul上;Pod被Kill时,dinit会先停外部流量及内部流量,再杀服务进程,实现优雅销毁
原地重启:Kubernetes不支持Pod原地重启,dinit可以实现服务进程就地重启
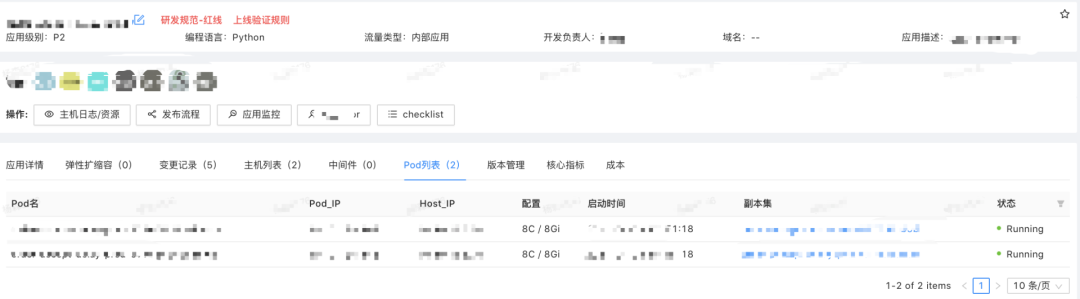
在实际落地过程中,我们在算法部门推送的极限扩缩容及多运行时的方案,且极限缩容也为算法部门服务云主机成本带来大幅度的降低。在发布方面我们做到了变更逻辑同步触发,用户体验和业务响应也做到了一致性保证。目前我们正在配合算法部门一起推进算法模型服务部署到Kubernetes,力求容量性能和成本之间的平衡做进一步提升和优化。

四、总结和展望
弹性扩缩容系统已经稳定运行了将近20个月,企业微信每天都可以收到许多服务自动扩容/缩容的消息推送,AutoScaler一直在后台默默地工作着,为系统稳定性保驾护航。

目前弹性扩缩容系统仍具有非常大的提升优化空间:
时序数据分析后的决策和实际情况仍有一定程度的滞后,比如连续扩容的情况,我们希望容量在一定程度上是可以预测出来的,且最小实例数也是会随实际情况变化的,目前基于facebook prophet的Predict模块正在设计开发中,希望可以自适应做到提前预测并执行扩缩容;
优化并提升TSA模块,以便可以有效地检测识别出异常点,辅助问题定位并最终生成决策,目标是实现全自动的故障自愈。
感谢运维团队小伙伴在弹性伸缩架构方面做出的努力和贡献,感谢算法团队在弹性扩缩容及极限缩容落地过程中的给予的支持和协作。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721