
本文根据张磊老师在〖deeplus直播第263期〗线上分享演讲内容整理而成。(文末有获取本期PPT&回放的方式,不要错过)

今天分享的主题是微博数据库资源调度平台的架构实践,是我们内部启动的⼀个项⽬。主要实现的功能有两个:⼀个是资源的智能调度,⼀个是成本优化。都是⾮常实⽤的场景。
⼀会⼉我会从4个⽅⾯来做下具体介绍:
项⽬启动的背景。
包括微博当前数据库资源的规模现状和运维⼈员配⽐,我们对资源治理的期望和⽬标,以及我们对资源调度的理解。
然后介绍⼀下这个调度平台的宗旨和使命。
就是我们希望通过这个平台达到什么⽬的,希望它解决我们哪些痛点。
再重点介绍⼀下平台的架构选型、实现⽅式、逻辑设计和核⼼功能。
最后分享两个案例。
来说明我们是如何通过这个调度平台实现应对热点事件和成本优化的。
一、背景
先来看下微博资源规模的现状:
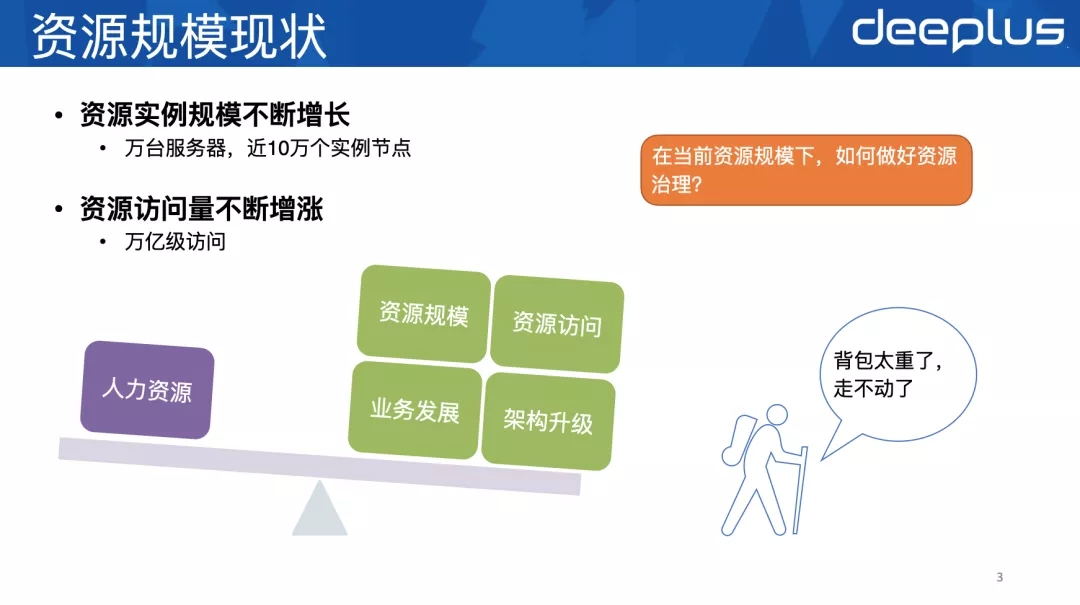
从两个维度来看:⼀个是整体资源体量,⼀个是资源使⽤的种类。整体资源体量上,服务器规模还是⽐较⼤的,全⽹服务器达到了万台⽔平,总实例数近10万个,总访问量在万亿级别,资源使⽤的种类也⽐较丰富多样,关系型数据库有MySQL、PostgreSQL,缓存类有Redis、Memcached,消息队列有Kafka、MCQ、Qservice等等。
运维⼈员配⽐⾮常低,或者说⼈均运维实例数⾮常多,差不多每个⼈要管理1500个实例,这个数量已经⾮常⼤了,如果没有借助⾃动化、标准化的运维⼿段,是很难管理好这么多实例的。
如此规模下如何做好资源治理是我们每天都在考虑的问题。
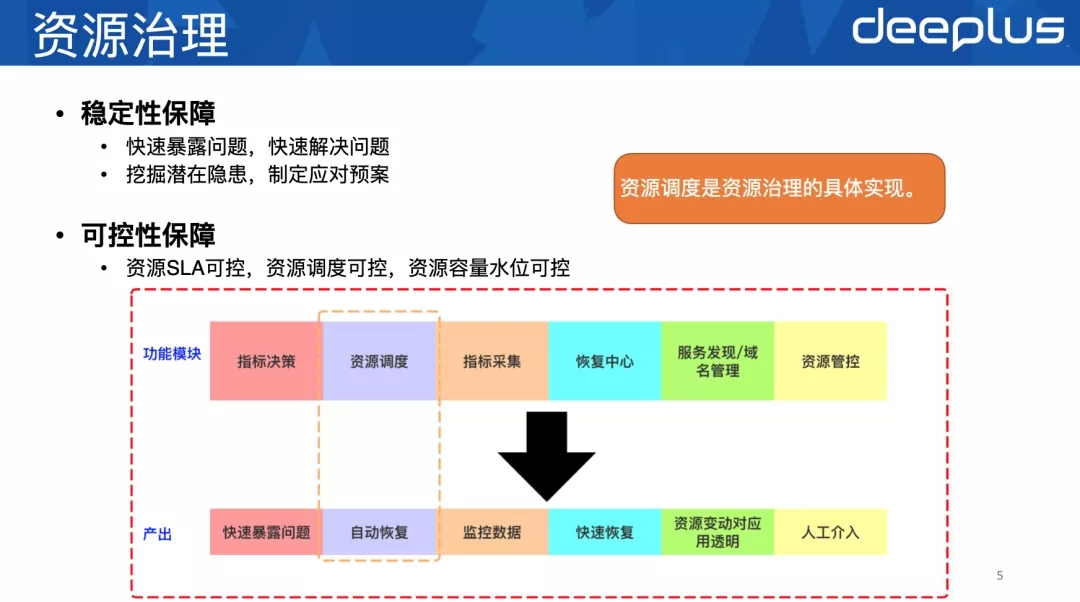
资源治理是个⽐较抽象、概括的说法,我们需要拿很多东⻄界定它才能让它具像化。⼤家可以按照这个思路来捋下:
1)资源具体指什么(定义)
服务器,MySQL、Redis等这样的服务,服务发现、域名,Agent代理
资源治理的⽬标是什么(⽬标)
稳定性保障
快速暴露问题,快速解决问题
挖掘潜在隐患,制定应对预案
可控性保障
资源SLA可控
资源调度可控
资源容量⽔位可控
2)怎么治理(⽅法论)
通过资源调度实现
3)怎么衡量资源治理的好坏(SLA)
满⾜业务的SLA
资源治理⾥⾯也包含很多细分领域和模块,⽐如数据采集、指标决策等等。这些问题都找到答案后,我们对什么是资源治理就有个⼤概的轮廓了。
上⾯提到 资源调度是资源治理的具体实现,我们要想做好资源治理,就要做好资源调度。
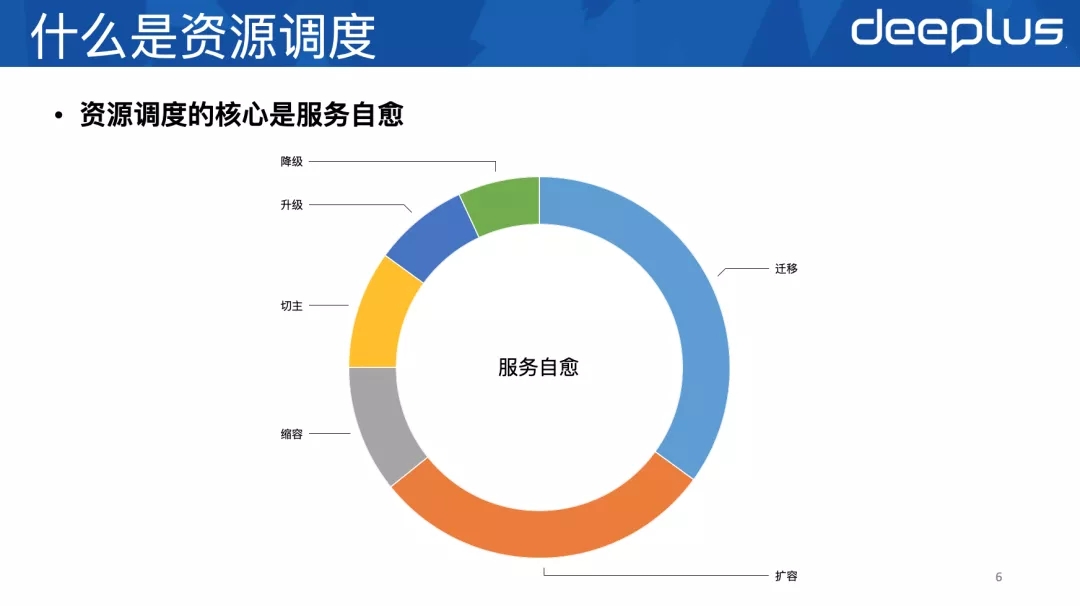
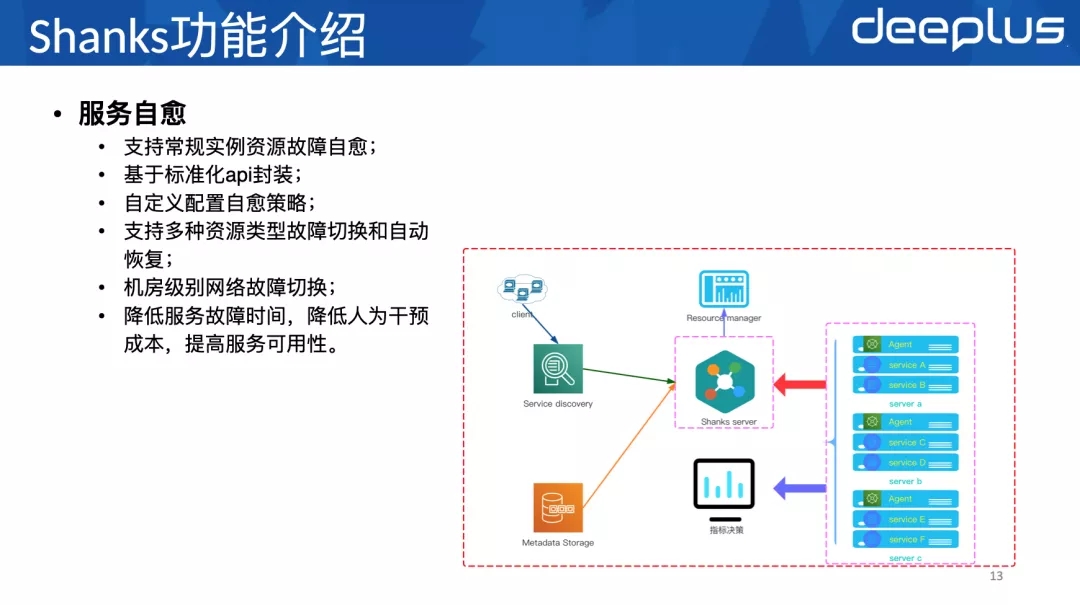
我们⽇常对资源的很多操作,都可以抽象成对资源的调度。⽐如:切主、升级、迁移、扩容、缩容等等。资源调度的核⼼是服务⾃愈。只有服务⾃愈覆盖范围⾜够⼴,资源运维的规模才可能⾜够⼤,服务访问质量才可控,资源治理才可以真正落地。我们⼈均运维的1500个实例,就像运维15个实例⼀样,因为99%的情况都被服务⾃愈覆盖了。
今天要介绍的这个资源调度平台叫Shanks,它把我们⽇常运维中遇到的资源和操作都抽象成标准化的类,然后和周边⽣态⼀起保障资源治理有序进⾏。周边⽣态有很多,⽐如恢复中⼼、资源云、指标决策系统等等。
Shanks资源调度平台
现在介绍⼀下Shanks的整体架构,可以分成四个部分:
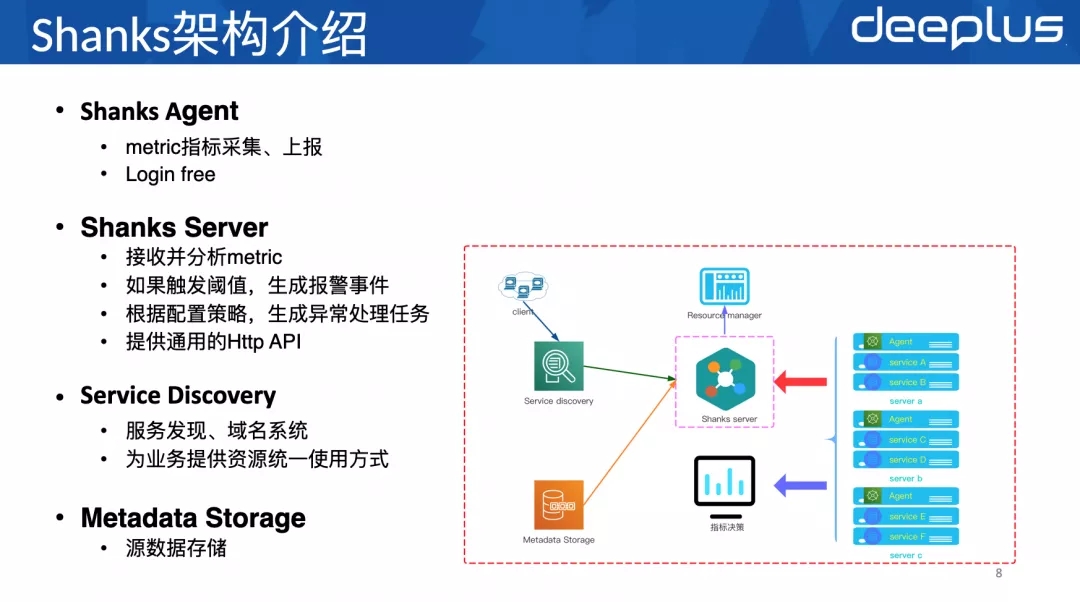
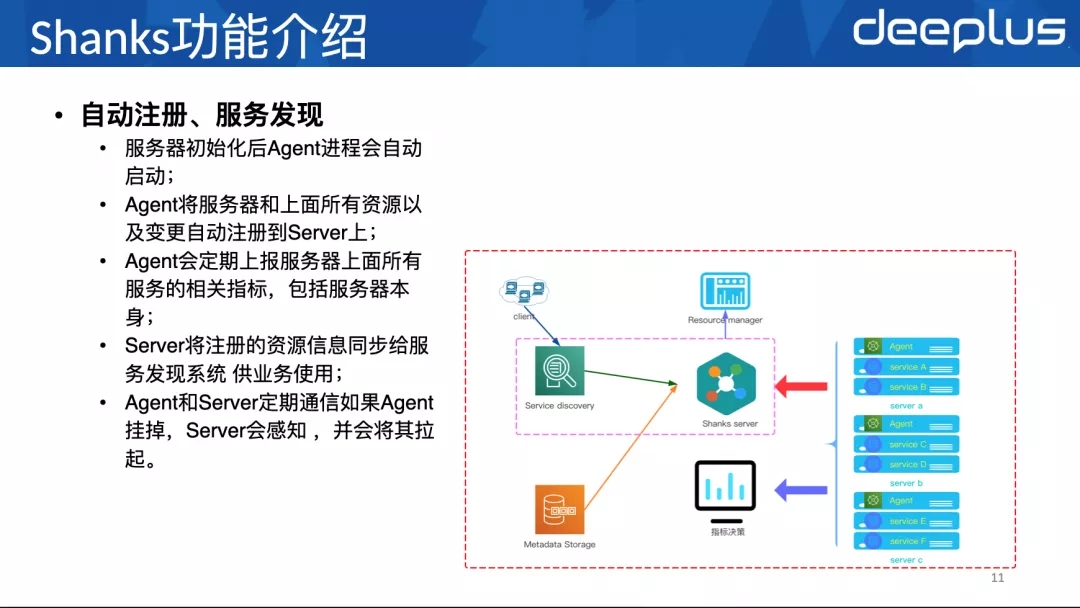
其中Shanks Server和Shanks Agent的代码是放在⼀个⼯程下的,上线的时候,会同时⽣成Shanks Server和Shanks Agent两个⼆进制包。然后Shanks Server会部署在指定的服务器上,Shanks Agent会部署在所有服务器上,所有服务器上的Agent都是⼀样的。
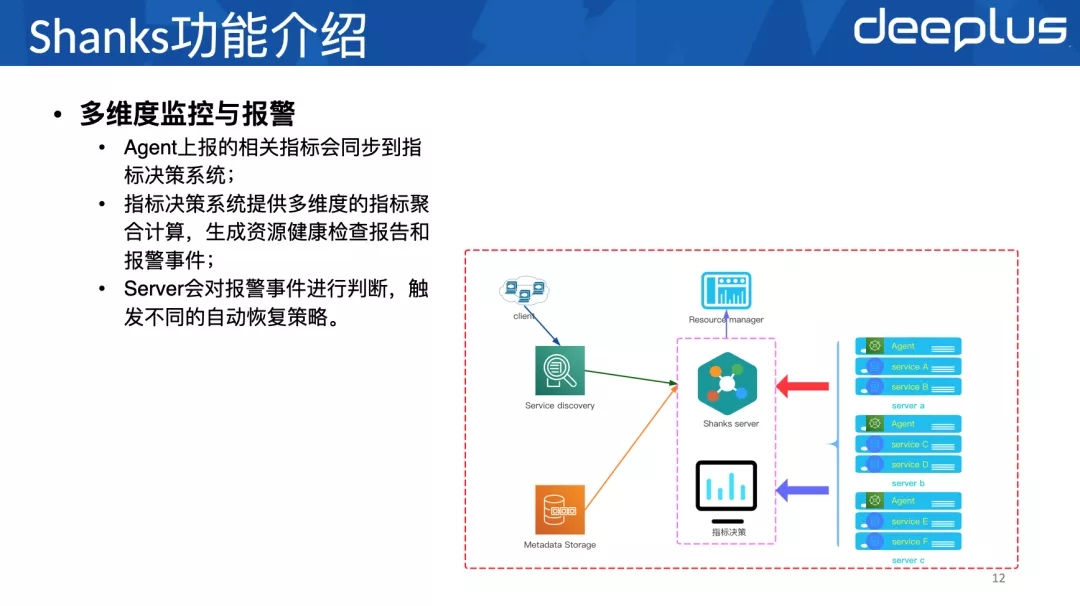
Shanks Agent负责metric指标采集、上报给Shankks Server和指标决策系统(采集包括服务器本身的指标,还有上⾯服务的指标)。指标决策提供监控看板和基于采集指标的分析数据。同时,Shanks Server下发的命令,可以通过Agent直接执⾏。
Shanks Server是主要的资源调度者,调度的接⼝通过Http API暴露出来,Agent收到Server的指令后,实施具体的调度内容。⽐如迁移某个实例,Server会发出迁移指令,然后Server先执⾏找机器逻辑,找到⽬标服务器。让⽬标服务器上的Agent执⾏新实例部署,搭建主从关系,上线。然后让源服务器上的Agent下线⽼实例,迁移结束。
下⾯要介绍的是Shanks的五个主要功能:

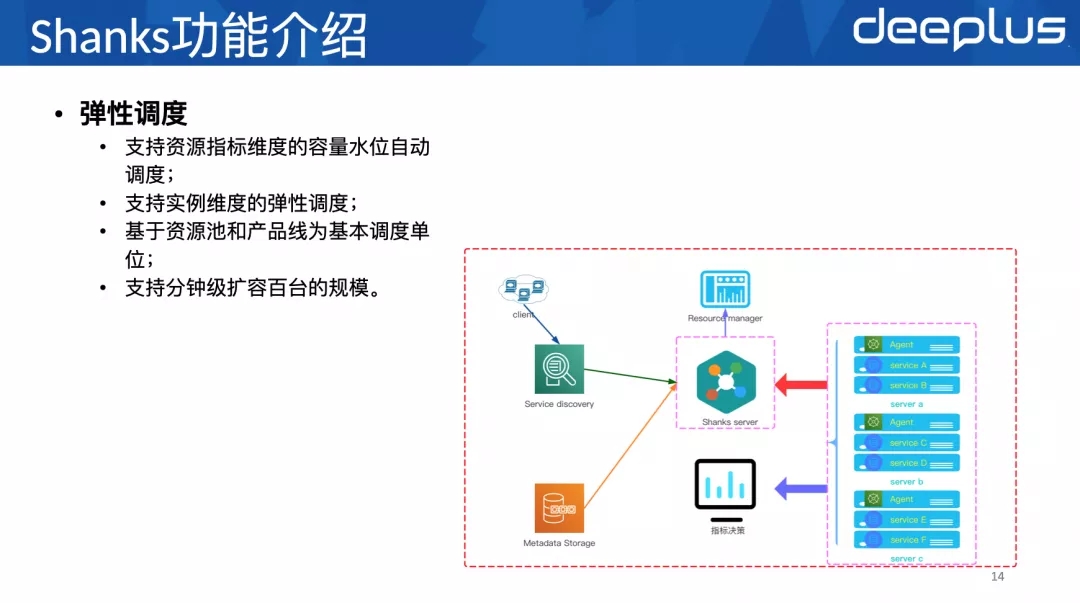
其中弹性调度可以从两个维度来理解:⼀个实例维度,⼀个配置维度。
实例维度是指当某个具体实例冗余度不⾜的时候,弹性调度会通过扩容实例个数来增加冗余度。
配置维度是指,当某个具体实例已⽤内存快达到配置的最⼤内存的时候,弹性调度会通过修改配置增加最⼤内存。
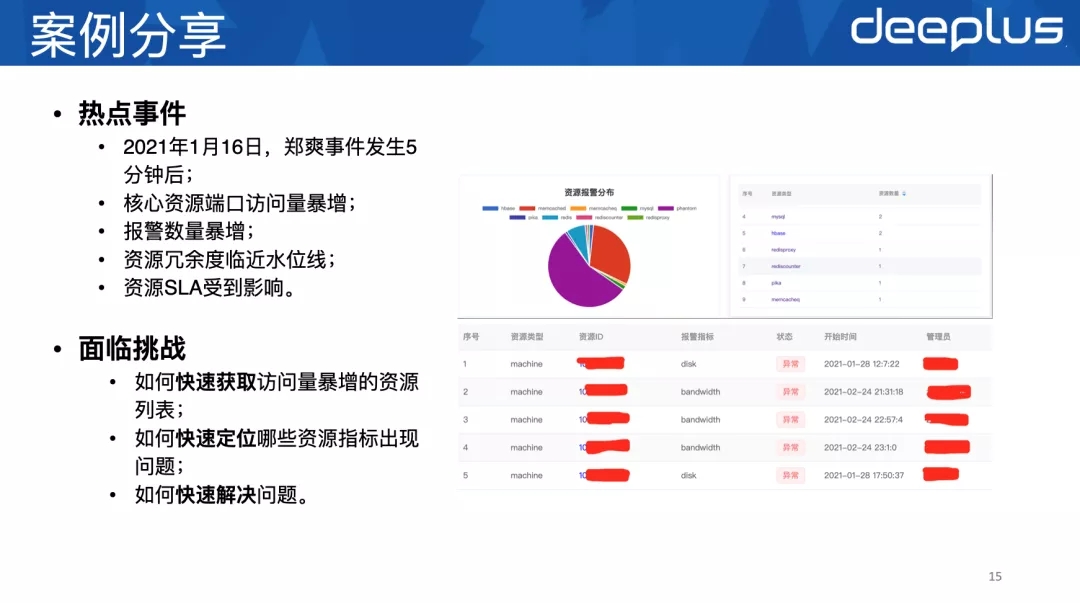
案例分享
当某个资源实例触发了报警事件,这个实例就会被打标,我们通过标签就可以检索出哪些实例触发了报警阈值,哪些指标有问题。
成本优化还是从两个⽅⾯来把控:⼀个是提⾼资源利⽤率,降低冗余度;⼀个是提⾼资源智能调度的能⼒或者弹性扩缩容的能⼒。这两点做好,就能把成本优化到很理想的状态。

上⾯就是这次分享的全部内容。谢谢⼤家。
Q&A
Q1:若干个计算任务如何分配给若干个服务器,使得所用的服务器数量尽可 能少?
A1 :对于计算任务的调度和我们今天分享的 对于资源的调用有点类似,都 是通过调度逻辑合理利用已有的物理资源(CPU、内存、存储等等)。我们采 用的策略是预分配策略,根据agent采集上报的指标信息,我们很容易知道当前 物理资源的占用情况,我们可以根据这个情况,来对需要调度的资源进行调 度,但是调度采用预先分配的策略,比如我计划把资源a(这里的资源可以理解 成具体的服务,比如mysql、redis,或者具体的计算任务)部署到物理空间B 上,这个资源a需要多少物理资源我是预先在物理空间B上标记好,下次再进行 调度的时候我看到物理空间B的资源(CPU、内存、存储)剩余就是已经减去 资源a的了。对于计算任务也是类似的场景。这个策略的迁移是需要做好资源隔 离。
Q2:听完分享,感觉shanks很像 service mesh,方便说下选择自研的考虑吗?
A2 : service mesh是这几年比较新的东⻄,service mesh里面涉及到的服 务发现的场景确实和今天谈到的服务发现很像。提供这种功能的工具确实有很 多,比如consul、etcd,我们选择自研的原因很简单,一是本身实现起来不 难,二是我们运维的资源类型很多,有些定制的需求,自研可能更容易实现。
Q3:服务效率的评价标准应该怎么定呢?
A3 : 服务效率可能从投入产出比来说会好些,比如我投入10个人,开发了 3个月,做出了这套调度系统,我们利用这个调度系统,每年可以节省非常可观 的开销,这中投入产出比或者服务效率是容易让人接受的。如果我投入10个开 发了2年才做出了这套系统,我们利用这个系统,每年节省的开销很有限,那我 们就认为服务效率不够好。我们在项目启动的时候确实衡量过这个成效,原则 就是尽可能快的做出能覆盖80、90%的场景。然后快速迭代。
Q4:请问下老师有哪些常用的资源调度策略?优缺点可以简单说一下吗?
A4 : 模式大体可以分为两种,一种是隔离类的资源调度,比如资源绑定, 资源容器化;一种的非隔离类的调度,比如我把很多资源部署在一台物理服务 器上。调度策略上,我们大体有几个原则:一是平衡策略,一是近地缘策略。平衡策略就是,把资源使用率高上面的服务调度到资源使用率相对低的地方。近地缘策略是指,优先选择同机房、同可用区的服务器作为目标服务器。我们 在选择目标服务器的时候有一套打分机制就是基于上面的策略来做的。
Q5:跨云怎么进行统一资源调度?
A5 : 跨云的场景现在已经很常⻅了,我们也同时用了多个厂商的云资源。每个厂商都会提供通用的API来实现相应的功能,所以从调度上看没什么区 别,唯一的区别是跨云的网络延时会有点⻓,控制好这个就ok了。
Q6:你们团队的组织架构能否介绍下哈?
A6 :我所在的部⻔是基础平台,里面可以分为应用运维、资源运维、大数 据运维、基础组件这几个大的方向。
Q7:请问老师,如何划分资源粒度呢?
A7 : 一个资源实例或者一个进程是我们调度的最小资源粒度,比如一个 mysql实例。比资源实例大一个级别的是一组实例,比如一个mysql集群,里面 可能有几个实例,比一组实例大一个级别的是一类资源,比如全网所有的 mysql。
获取本期分享PPT
请添加小助手微信号:dbachen
↓点这里可回看本期直播
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721