

今天的内容分享将主要包含以下四个方面:
介绍京东到家的订单履约业务背景
在业务背景的基础上说明订单的底层存储方案
基于存储方案的数据异构设计与实践
面向复杂度的架构设计方法论
简单来看,面向复杂度的架构设计方法论与上面3个部分没有直接关系,把这部分内容放到文章中来讲,主要是因为数据异构本质上也是解决了软件的写入复杂度问题。在这个基础上,我们向上抽象一层,来讨论一下面向复杂度的架构设计方法论。
一、京东到家订单履约业务背景
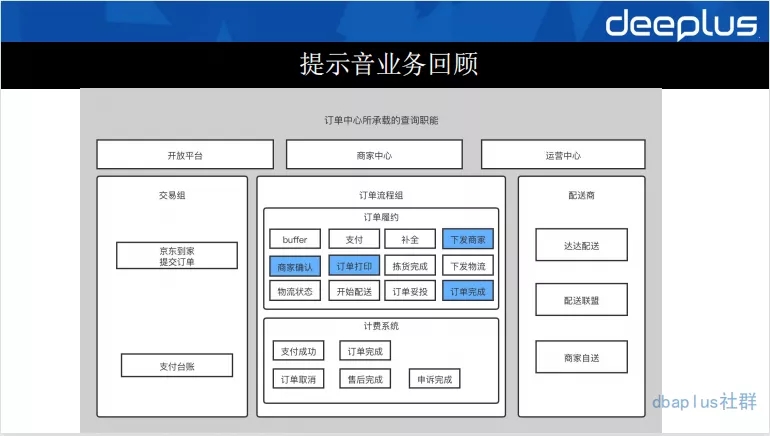
从用户提交订单到服务履约系统,我们大致经历了支付、下发商家、商家确认、订单打印、拣货、下发物流、配送、妥投等环节。这是一个基本的新零售履约流程。这里,我标蓝了一些流程。比如:下发商家、订单打印等环节。主要是因为这些环节是我们要和商家交互的功能点,当我们把订单下发给商家时,首当其冲的环节是商家要确认这个订单,并且开始履约流程。但是,在我们的实际业务中,商家在大促期间往往会出现履约瓶颈,忙到看不到我们下发的订单,甚至不忙的时候也会看不到我们的订单已经下发到他们的系统中,商家需要一个提示功能。这也就是我们的提示音需求。
提示音需求需要不断的查询底层存储ES,并提示给商家有订单到达了,需要他们去履约,如果商家没有看到,就不断查询,不断提示。就是这样的一个循环查询量级,在大促期间,订单量级增大,查询量级增大。基本上每次大促都会把我们的ES查到CPU飙高,甚至出现不可用的情况。为了保护履约系统,我们做的临时方案是做一个功能开关,在大促期间对提示音功能降级。可是这样的降级并不是我们想要的。因为最终商家还是收不到提示。导致履约质量下降。于是我们就面临一个问题“存储组件无法支撑大促时提示音业务的查询请求量。
二、底层数据源的职责分工

要解决我们面临的查询量级问题,就必须首先分析一下底层的存储方案。以上,是我对到家订单履约系统底层存储的一个整体概括。
Redis在履约系统中主要承载的一个职责是worker跑批任务的存储和查询。因我们在系统中大量运用了跑批任务来实现最终一致性的一个设计,而Redis的Zset结构正好满足了这样的需求,将时间作为分值,不断的提供近期任务的查询是Redis充当的根本职能。这里解释一下Redis为什么没有承载过多的查询职能。Redis虽然性能更好一些,但是,在数据量和查询复杂度上,没有ES支持的好,关键点是我们的查询条件复杂度是比较高的,所以,Redis没有承载过多的查询职能。
MySQL在履约系统存储中的职能是持久化存储订单数据,这里主要还是使用其强大的事务机制,以保障我们的数据是正确写入的。这是其他的两个组件所不支持的。
从履约流程上来看,我们将数据做了冷热分离,热点数据是我们在履约中的订单(也就是未完成的订单),而完成的订单,由于其使用率不会太高,所以,我们称之为冷数据。这样的一个拆分也就是上图中对应的业务库和历史库。业务库是热库,而历史库则是冷库。这样的一个冷热分离思想,使我们的单库单表数据量级维持在千万级别。从而避免了对应的分库分表复杂度。
从部署架构上看,我们对业务库进行了大量的主从分割。其中biz slave是我们的业务库从库,它也会承载一些履约中的订单查询职能。接下来的big data slave集群则是大数据抽数据用做统计分析。最后的delay slave设置延迟一定时间消费binlog则是为了防止master被误操作而兜底的。比如有人错误执行了删除db的命令,这样的一个延迟消费的机制就可以利用binlog进行兜底回滚。
ES在数据存储中承担了几乎所有的查询职责,这主要取决于它支持复杂查询,并有天然分布式的特点。在数据量复杂度解决方案上,避免了MySQL分库分表的复杂度。这里我们一共有3个ES集群。其中HOT ES和Full ES也是进行了冷热分离,这样对我们的查询流量进行拆分。有助于保证履约系统的稳定性。
而第三套集群Remind Elastic Cluster则是为了解决我们上述提示音的问题。在有提示音集群之前,我们所有的提示音查询流量都是打到热集群的。也正是这样的一个访问量需求,导致了我们的热集群时有发生CPU飙高,接口响应缓慢,卡顿业务线程。所以,我们对热集群进行了进一步的拆分,于是就正式提出了提示音单独集群的方案。
三、写入复杂度问题
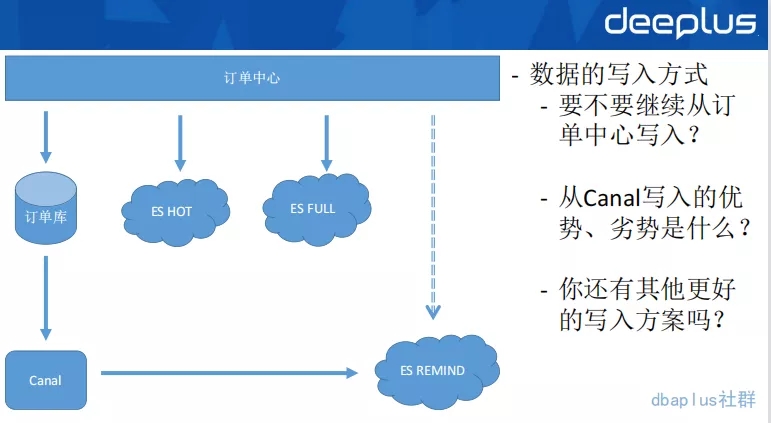
当确定冗余一套提示音集群以后,我们面临的问题就是上述这样的一个写入复杂度问题,从图上来看,我们在拆分这套集群之前,订单中心每次操作一次订单写入。面临的是3个数据源的写入工作,这对研发人员是非常不友好的,维护难度过大。于是,我们就开始考虑用异构中间件的方式来去写入这套ES数据。
异构中间件的优势是屏蔽了数据同步的复杂度,但是随之而来的是数据写入链路可靠性、及时性等问题。而且,数据传输本身一般都具有高可用的需求,之前高可用在业务应用上,因为业务应用的集群方式本身是计算高可用的。但异构中间件则要在这高可用、可靠性、及时性三个维度上满足我们的要求。
四、数据异构产品选型
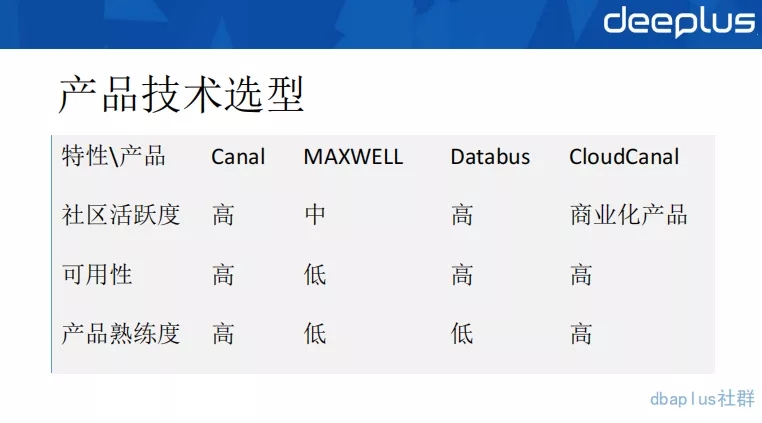
在上述分析之后,我们也陆续调研了一些异构产品,在数据类型支撑上没有太大差别,常用的存储组件,这些异构中间件都是支持的。所以,我们更在意以上3个指标。社区活跃度代表了后续的维护性以及开源产品快速的问题响应,可用性方面的需求是非常强烈的,最终采用Canal的根本原因还是在学习成本和熟练度上。
Q&A
Q1:订单表中,如果有一些商品id,那么同步到ES中也是id吗,不会关联出name打成宽表存到ES吗?
A1:具体的映射字段需要在Adapter中配置映射即可,存入到ES中的情况也与配置的映射是直接且唯一关系。是否宽表要在实际应用中把控字段的个数。
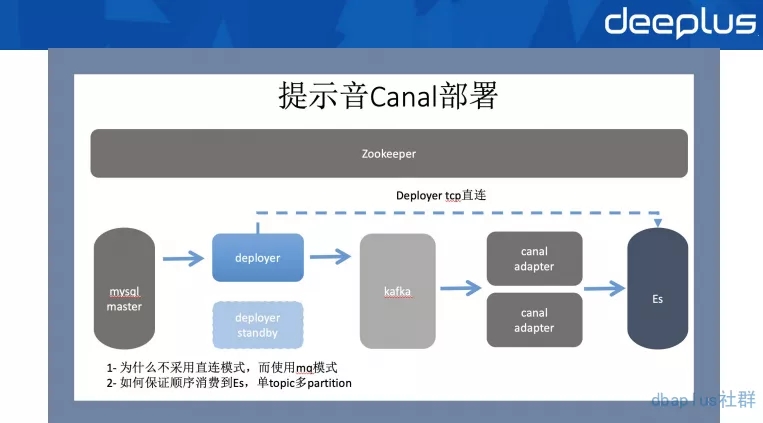
Q2:Canal部署deploy主从和canal-adapter有没有遇到官方的bug?有,改动了哪些?
A2:遇到过Column not match的异常.具体看Canal的TSDB来解决。
Q3:这套复杂度方法论如何落地到实际应用?
A3:需要对系统进行4R视角拆分、识别复杂度类型并按照架构设计环的方式来评定需求。
Q4:平时的Canal有消息延迟吗?
A4:有一定延迟的,binlog的数量、网络等因素,都会造成一定的延迟,所以,建议异构还是要建立在业务数据可延迟的基础上的。
Q5:我主要用canal-adapter读取Kafka中的binlog日志然后写到数据库中,Kafka中有多个表的日志,我rdb目录下的yml文件只配置了一个表的为什么其他的表也会同步?
A5:Yml的作用是配置映射关系,具体的过滤职能在Deployer的Sink配置。
Q6:异构数据是直接同步原表吗,还是做了关联?
A6: 做了关联,直接在Adapter中配置对应映射关系即可。
Q7:请问为什么不直接增加热集群的节点和分片,而是重新建一套ES集群呢?
A7: 这里主要还是一个数据拆分的思想,如果通过提高配置来解决访问量问题,那么,随着业务量级增加,流量混在一起,对应的ES集群流程会呈现不可评估的情况。本质上还是一个数据存储职责的问题。
Q8:如何保证Zookeeper的高可用?
A8: Zookeeper本身就是高可用的,如果想在机房或异地方面做高可用,建议做主备同步、多集群部署等手段。
Q9:新集群的查询请求峰值是多少?
A9: 大约2000-4000 QPS。
Q10:怎么把握冗余尺度呢?
A10: 冗余的维度在机器、机房、地区、国家是不断增加的。维度越大,对应的高可用方案越可靠,但是,对应的费用以及实现复杂度也会变高。因为这种冗余方案肯定会有数据copy。
获取本期分享PPT,请添加小助手微信号:dbachen
↓点这里可回看本期直播
阅读原文








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721