
本文根据蔡岳毅老师在〖2020 Gdevops全球敏捷运维峰会〗现场演讲内容整理而成。

(点击文末“阅读原文”可获取完整PPT)
HBase属于非结构化数据存储的数据库,在实时汇总计算方面也不合适。

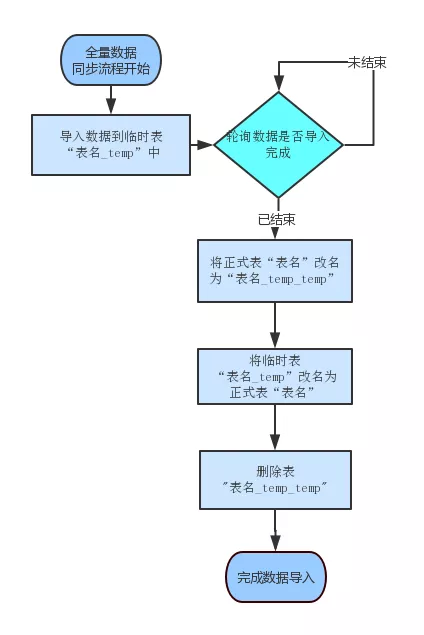
清空A_temp表,将最新的数据从Hive通过ETL导入到A_temp表;
将A rename 成A_temp_temp;
将A_temp rename成 A;
将A_ temp_temp rename成 A_tem。
清空A_temp表,将最近3个月的数据从Hive通过ETL导入到A_temp表;
将A表中3个月之前的数据select into到A_temp表;
将A rename 成A_temp_temp;
将A_temp rename成 A;
将A_ temp_temp rename成 A_tem。

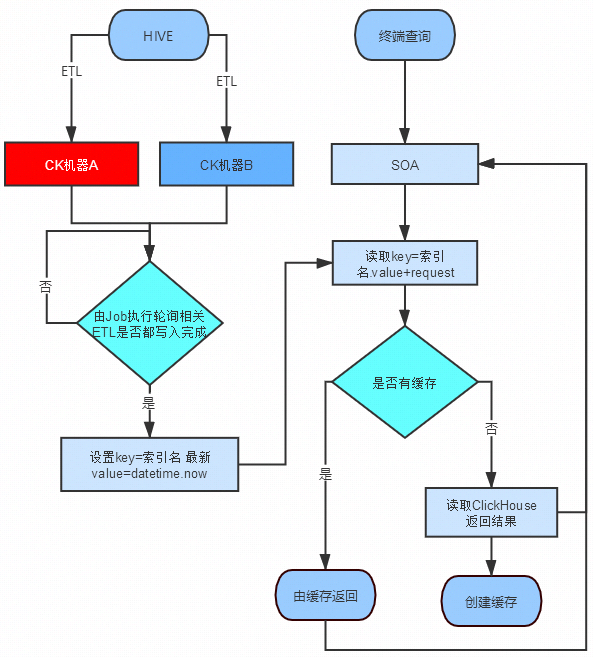
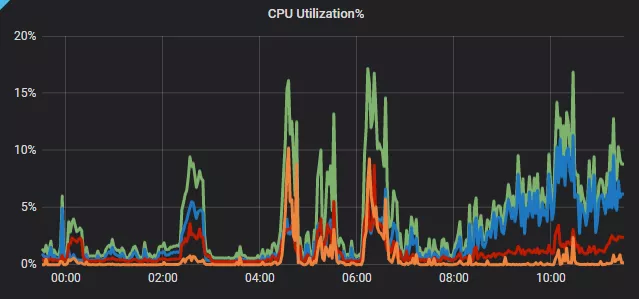
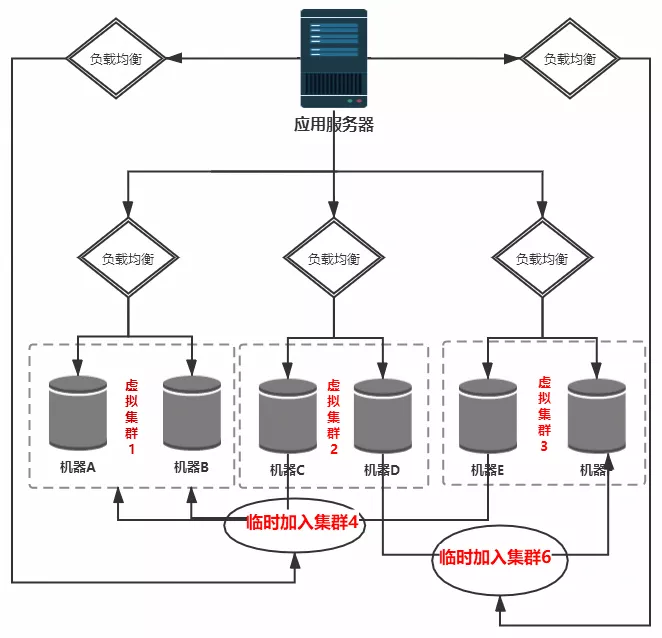


Q&A








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721