
本文根据肖博老师在〖deeplus直播第230期〗线上分享演讲内容整理而成。(文末有获取本期PPT&回放的方式,不要错过)

大家好,我是肖博,今天给大家分享的主题是《大规模多存储场景的数据库选型与服务平台建设之路》,主要围绕vivo在数据库选型和服务平台的实践来展开,希望能给大家带来不一样的启发。
今天的分享主要分为以下三个部分:
自我认知的革命
需求驱动的数据库选型
服务驱动的平台化建设
一、自我认知的革命
我们先来回答一个问题,DBA是谁?
官方的定义是从事管理和维护数据库管理系统DBMS的相关工作人员的统称,属于运维工程师的一个分支。DBA的核心目标是保障数据库管理系统的稳定、安全、可靠。
那在开发、测试或者老板的眼里DBA是谁呢?
可以看到上图这个圆圈里有些标签,写着DBA技术能力强,任何时候、什么问题都能搞定;时间很忙(虽然不知道在忙什么);制定了各种流程规范,这个不让用,那个方案不行,总是说 NO等等。
这些贴在DBA身上的标签时间久了之后,有些DBA也会以这些标签来标榜自己,但大家有没有仔细想过,DBA到底是谁?当然,思考DBA是谁和经典的哲学问题“我是谁”还是有区别的,思考这个问题主要可以分两个方面:
你知道DBA在别人心目中的印象吗?
你知道DBA的工作带给公司、产品带来的影响吗?
带着这两个问题,我们接着看下DBA的日常工作。

第一块工作是保障数据库产品稳定、可靠、高效、安全地运行,解决数据库的问题,类似于救火队员,平时不动声色,关键时刻冲在第一线,当然运维性质的工作都是这样的。
第二块是通过流程规范、管控平台逐步地完善运维体系,防患于未然,未雨绸缪,提前做好规划工作。
第三块是数据库的架构设计与选型,这里看起来比前面的两个要高级一些,我们都知道好的系统是设计出来的,所以设计工作很关键也很重要,这个部分对个人能力的要求会相对高一些。
最后一块是数据架构的治理,这个是什么意思呢?其实大家平时都会说,数据是公司最宝贵的资产,那么DBA就是负责维护和管控这座金矿的人,深入数据内部管理,更好地理解数据,把数据运用起来。当然这方面的工作可能不是DBA去做,只是DBA个人发展的一个方向。
上面讲的这两部分都是大家普遍认知的内容,也都是大家常规的认识,那我们这一章节叫做“自我认知的革命”,那接下来我们会讲一讲,如何突破认知,重新定义DBA。

如何对DBA的认知进行革命呢?首先我们把DBA和数据库管理系统DBMS当作一个产品来进行打造,DBA不再是专门维护和管理 DBMS的运维管理人员,DBA本身也是这个产品的一个模块。
那么我们产品定位是提供数据库服务能力;服务对象有,开发、测试、架构师、管理者等有数据库需求的用户;这款产品的价值输出有哪些呢,主要是满足业务诉求的DBMS和用户满意的数据库服务。
将这些打包成一个整体后,我们就可以打造属于DBA的品牌,把产品能力和价值映入用户的心中。这样做有什么好处呢?
强调DBA本身的价值,DBA的个人能力也是一种产品;
DBA和数据库管理系统的关系变化,不再是管理和被管理的关系,而是统一的关系,都是为业务提供有价值的数据库服务;
DBA不再是用户眼里那个总是说NO,或者躲在幕后的英雄。而是以产品运营的方式将能力最大化输出,以解决用户麻烦的思路去看待问题,更好地服务公司的业务。
二、需求驱动的数据库选型
现在我们来讲第二部分,需求驱动的数据库选型。首先来看一个概念,什么叫业务场景?业务场景一般指企业和商家需要在用户某个特定的环节中,适时提供给消费者可能需要的以及关联的产品或服务。
一般来说用户使用我们的产品后,都会获得反馈。首先用户需要接触和使用到我们的产品或者服务;其次用户使用后,要么是满足了用户的需求,要么是解决了用户的问题或者在使用过程中遇到了一些困难或者障碍,这样我们就可以得到用户对产品的反馈,并形成一个循环。
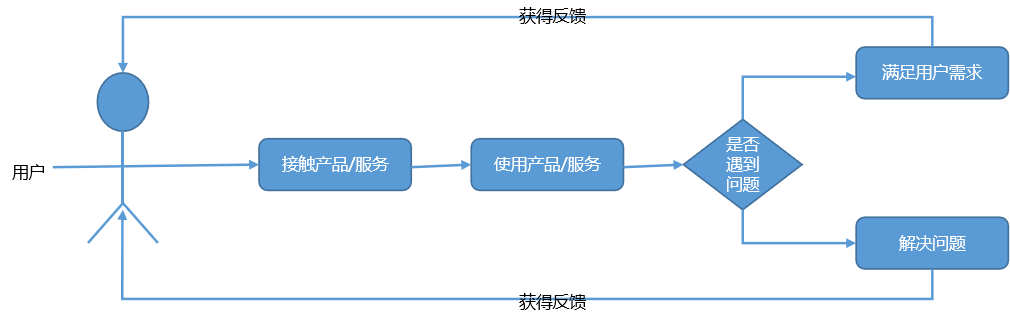
总的来说,业务场景是需求的灵魂,并且需求不是凭空出现的,是基于业务场景出现的。简单总结就是:【“谁”在“什么环境下”,“干什么/遇到什么问题”,“如何解决这些问题”,“产生什么样的价值”】,这点在后面讨论数据库选型和服务平台建设时,是很关键的的一个套路。
接下来说我们的业务场景,这里主要针对的是依附于vivo手机的场景,不包括硬件产品。从软件产品生态来看,主要分为以下六类:
推荐场景:应用商店、信息流、音乐、视频、小说等
账号系统:全系业务场景
广告场景:信息流、应用商店、小说、视频等
交易场景:音乐VIP、主题、云服务、游戏等
下载场景:应用商店、系统升级、主题等
推送场景:信息推送、天气、闹钟、语音助手等
上面是一些vivo产品的截图,有在使用vivo产品的同学可以试用下。应用场景分类之后,我们来看下,针对这些业务场景如何进行数据库服务选型。
1)数据库画像
这里我们使用了雷达图这个工具,把各种数据库抽象成为五个方向的能力,并列举了一些常见数据库产品:
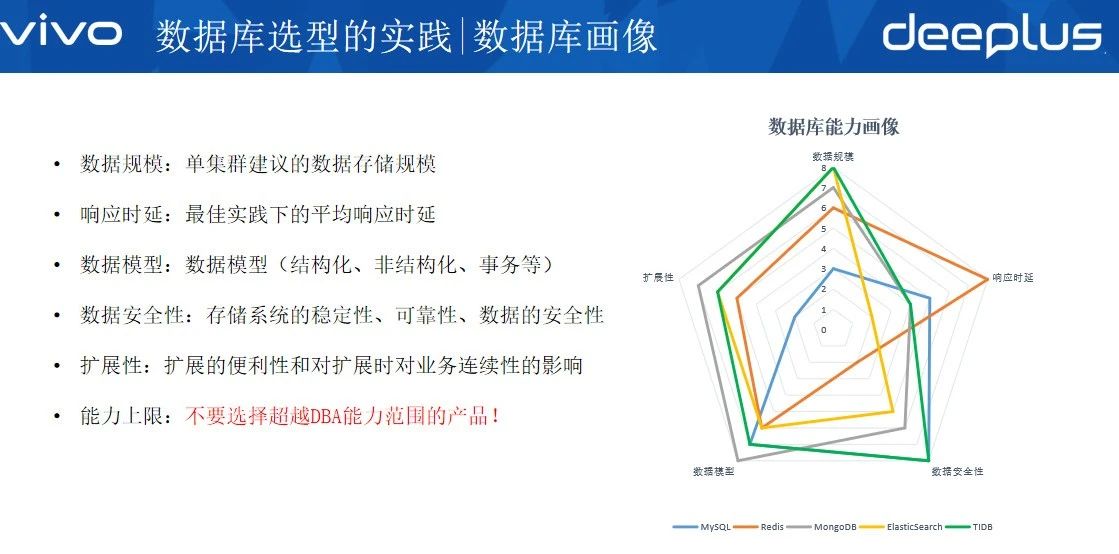
第一个是数据规模,单集群建议的数据存储规模。针对业务场景,看看这个场景下的数据规模如何,关于这点没有绝对的建议,只需按照业界的最佳实践来做就行。
第二是响应时延,最佳实践下的平均响应时延。这个很好理解,看你的业务场景是用户业务还是离线业务,是同步的还是异步等。
第三个是数据模型,这部分比较关键,主要指的是结构化、非结构化、事务等,可以抽象为数据模型,或者业务模型都可以。举个例子,前面提到的账号或者交易的场景,这种数据肯定需要关系型数据库来支撑的;前面还提到的推荐业务,可能有几千个特征或者标签,这种时候用关系型数据库来支撑就不太合适。
第四个是数据安全性,指的是存储系统的稳定性、可靠性、数据的安全性。这也比较好理解,当然绝大多数系统都标榜自己的稳定性和可靠性如何如何,但只需要从原理上仔细对比就可以看出差异,比如使用Redis就不能保证数据一定不丢失,这是由它本身内存这种易失型介质导致的。
第五个是扩展性,主要是指扩展的便利性和扩展时对业务连续性的影响。这个主要还是看业务,如果业务的数据量在未来有扩展的需求,那这个就要重点对待,有些数据库产品的扩容是很痛苦的或者扩容的过程中对业务的影响并不能做到业务无感知。
这就是用雷达图把数据库产品进行抽象对比,这样就能看出是数据库产品的特长在哪儿,方便我们去做选型。
最后一点不在这个雷达图里面,但是至关重要,就是DBA的能力范围,不要做超越DBA能力范围的选型。回到前面对 DBA+DBRMS的定义,如果DBA不能cover住这个数据库产品,那么对外暴露出的就是一个不稳定的、不靠谱的产品,不仅影响公司业务还影响公司口碑。所以在能力范围内做事情,不反对尝鲜,但针对生产环境还是要谨慎对待。
最后总结下就是 什么样的业务在什么场景下需要解决什么问题,用这个逻辑和上面的雷达图去套,去做选型。那接下来我们看看vivo目前用到了那些数据库产品。
2)vivo落地的数据库产品
可以先看这个图:
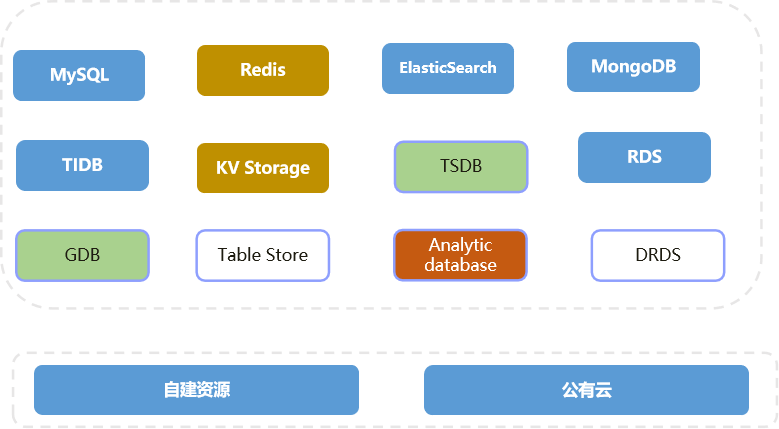
标注蓝色的为目前用得比较多的,黄色的是我们自己做过改造开发的,红色是OLAP部分但目前不在我们团队,绿色是少量试用或者是特定场景使用的。
MySQL:关系型数据库
RDS:公有云厂商提供各种数据库
Redis:KV数据库(缓存)
ElasticSearch:搜索相关业务
MongoDB:文档数据库
TIDB:分布式关系型数据库
KV Storage:KV数据库(持久化存储)
TSDB:时序数据
GDB:图数据
三、服务驱动的平台化建设
接下来谈服务驱动的平台化建设,还是之前的产品思路,我们先看我们的用户是谁。
软件开发工程师:在软件设计实现中完成数据存取的需求
测试工程师:在软件测试中通过测试数据的构造完成测试任务
数据库管理员:满足业务的数据库各种服务需求
产品经理等:数据报表、数据修订等需求
当然,以上几类用户并没有先后顺序的区别。这块可能和有些公司建设数据库服务平台时有些区别,因为我们不仅要满足数据库管理员即DBA的需求,也涵盖了公司所有对数据库有需求的用户。从当前实践结果来看,不论是PV还是用户数,都远超DBA,大概90%以上的用户是非DBA。
那么用户会在什么样的场景下用我们的服务?
开发环境:在开发环境进行迭代开发业务功能,对性能和可靠性要求一般,但有比较频繁的变更需求
测试环境:在测试环境验证服务的功能、性能,测试过程中对可用性和性能有要求,非工作时间各种要求较低
预发环境:在生产环境验证服务的功能,对数据库可用性、性能等要求一般
正式环境:在生产环境提供稳定、可靠、高效、安全的数据库服务
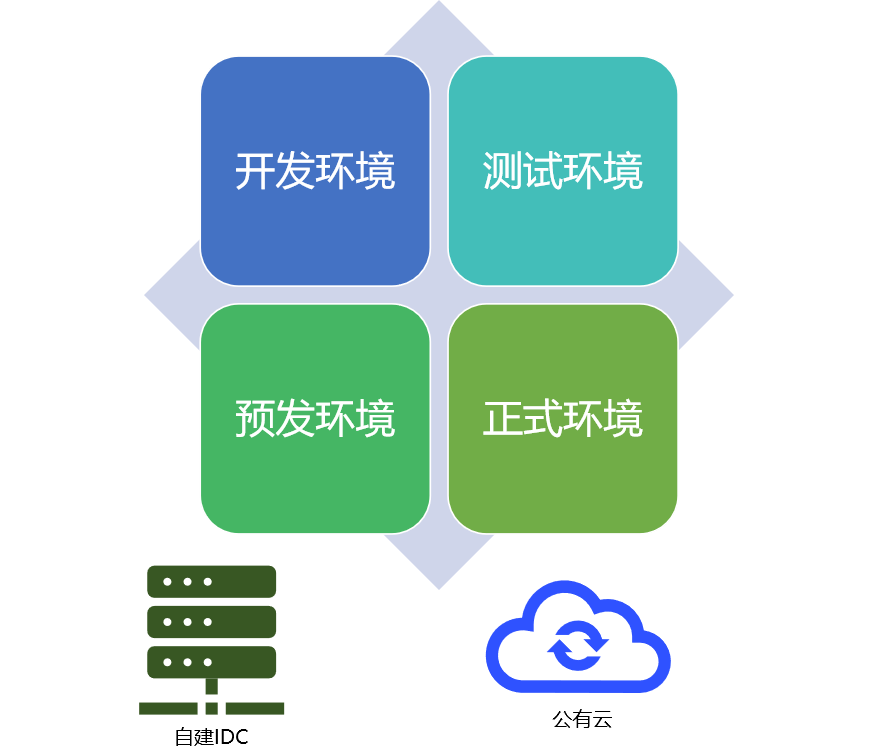
这张图最下面还有两块,一块是自建的IDC,一块是公有云的场景,这个主要是和vivo的业务场景有关系,公有云场景主要服务于海外的用户。
这里还有一部分没有在图中展示,我们知道在海外做经营,有些区域的数据合规法比较严格,不能和国内有网络上的互联互通,这部分一般会做单独的隔离处理,针对这部分还需要做单独的处理,由于内容比较复杂,就不展开讲了。
接下来讲四类用户在四种环境中是如何使用数据库产品的,这个主要包括了数据库产品的全生命周期,从数据库服务的创建到最终下线的全流程。
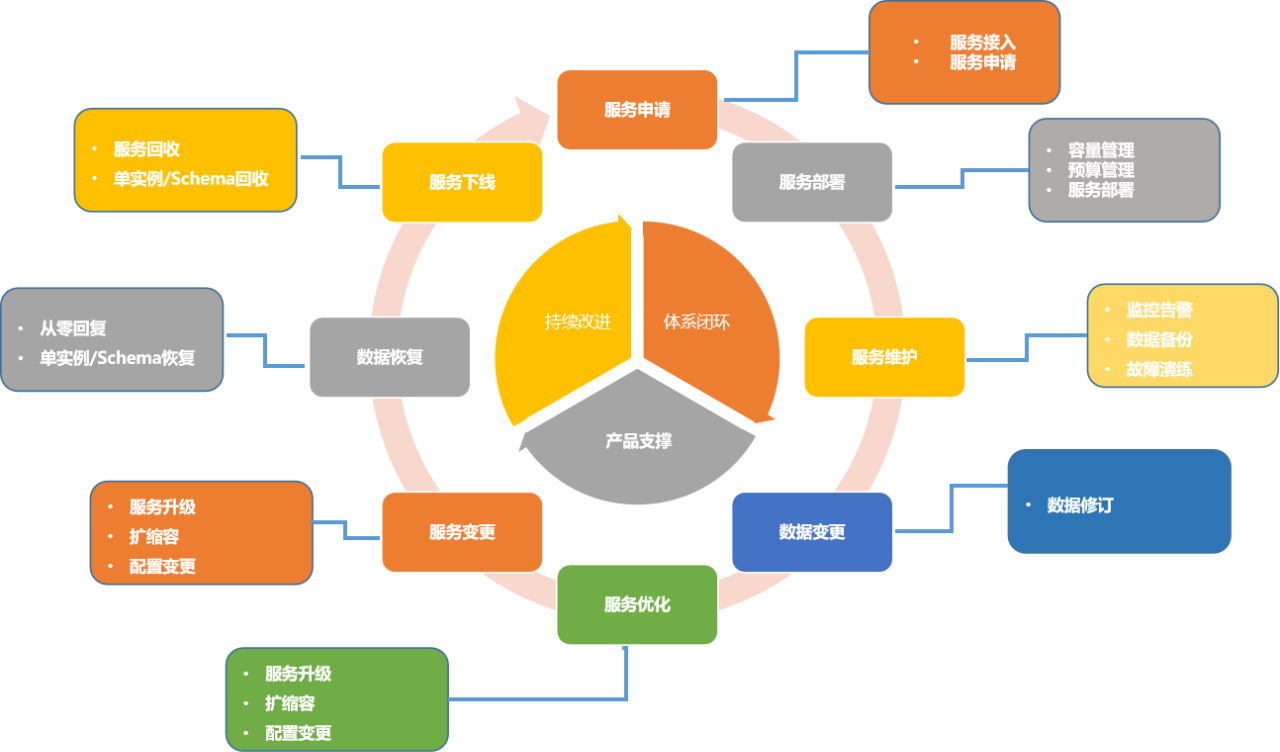
这个图里面的箭头和方向可以忽略,只是表述了全生命周期会经历那些环节,这些环节之间没有先后顺序。
服务申请包含了服务接入、服务申请;之后的服务部署包括了容量管理、预算管理、服务部署;到了维护环节,有一些监控告警、数据备份、故障演练等操作;业务运行过程种可能有些数据的变更或者数据导出等操作;还有服务的优化,比如服务升级、配置变更、扩缩容;后面的数据回复包括,单实例/Schema恢复、从零恢复;最后的下线回收,这就是整个的环节。
前面我们分析了用户、场景、产品使用的环节,本质来讲是在做需求分析。这些分析完之后我们需要做产品的目标定位以及思考产品的建设思路。
最后我们的产品的愿景定义如下:
打造交互便捷、体验良好、功能完备的智能存储管理平台
打造业界一流的高可用、高性能、低成本的 数据存储产品与服务
关于产品设计和建设的思路,有以下三点:
不以DBA视角主导产品设计,零基础也可以玩转数据库,这一点也是最关键的,不会先入为主,见过很多建设数据库服务平台的开发&设计人员本身就是DBA,会有先入为主的思路,做了很多默认的思路,那我们现在着重强调这一点,希望不论是刚入行的开发或者DBA,还是摸爬滚打了很多年的老鸟都能轻松的使用数据库。
重视用户交互体验,平衡可靠性、易用性、操作效率,这块我们配备了产品经理做产品设计,每半年也会做详细的用户满意度调研,收集用户的意见
机器学习、混沌工程等只是实现产品功能的一种方法,这块之所以拿出来讲,我们不会标榜我们做的是什么 AIOPS还是什么,这些方法只是我们在解决这类问题的一个方案,如果用机器学习或者深度学习解决更好,我们就用,反之如果传统的方案能更好的解决,我们不会为了做AI而做AI。

接下来我们看下,平台的架构设计,这个是简化了之后的平台架构图,中间灰色部分的关联图隐藏了,因为关联关系比较复杂,蓝色是我们自己开发的,绿色的是公司现有的能力。

整体思想主要有以下四点:
抽象公共服务(工单、权限等)
AGENT负责元数据、监控数据、巡检任务的上报执行
共建公共能力,不重复造轮子
统一用户接口,屏蔽公有云与自建IDC区别

前面讲到我们的用户会在多种环境使用我们的数据库产品,那一般情况下,测试开发环境和生产环境是会做网络隔离的,vivo也是这么做的,为了解决这个问题,我们做了很多的改造和适配,主要有以下几点:
统一权限与接入Portal,不要测试开发一套环境,生产环境一套环境,这样割裂的操作对用户体验有很大的伤害
生产环境与测试开发环境隔离
统一元数据管理
这个架构我做下简单的介绍,这里的Tomcat代表的是我们的平台服务,因为我们的平台服务是用Java写的,整个平台里面的数据库从功能来看,主要分为两类,一类是 提供给我们用户用的数据;一类是我们平台自己用的数据库。平台用的数据库就是我们的元数据,这块一定要统一,因为在权限和资产管理上必须要统一。
前端在接入层需要带上环境的标志,接入网关根据环境标志进行流量路由,因为生环境的Tomcat服务是没有办法直接管理测试环境的数据库环境的,所以我们在开发&测试环境也需要部署我们的平台服务。
我们给数据库定义了很多套餐,按照套餐来分配并且这些套餐是和环境有映射关系的,这样我就可以用一套代码通过环境和用户的需求来管理资源。

最后我们看下我们目前已经建成的一些能力,上层主要分为 可用性、效率、成本、安全四块。中间的部分是我们的数据存储产品,这块就不详细展开讲了。
Q&A
Q1:请问这个平台有用到开源框架嘛,多少人开发的,用了多久?
A:数据库服务平台的架构比较通用,后端服务为Spring Boot框架的微服务架构,前端采用的是Vue,部分组件如SQL审核、SQL优化、容量预测等组件采用了Golang或者Python编写;平台从2018年下半年开始建设,历经约2年时间,参与平台研发的同学5-7人左右。
Q2:如何顺利实现云下IDC数据迁移到公有云上,数据库之间如何验证?
A:云下IDC迁移到公有云上,这方面公有云厂商提供了很多的工具,如阿里云提供的DTS工具,此类产品一般自带数据一致性校验功能。当然也可以使用一些业界通用的工具去校验数据,另外不论系统做哪种层面的数据校验,最好让业务也进行配合验证下。
Q3:用了运维平台后,对于DBA来说,除了处理工单日产工作外,还有哪些技术栈需要学习/储备的?DBA需不需花大精力参加进来开发维护平台?
A:日常变更的操作更多的是开放给开发人员来自助操作,目前我们这边的数据库服务平台由专门的开发同学负责,不是DBA兼职进行开发,DBA未来更多的往技术运营方向发展,深入业务线,为业务的架构、设计等出谋划策。
Q4:能否就多种数据库的统一访问服务如何构建指点一下?
A:这块目前还在构想中,需要很多的底层基础能力支撑,比如正在建设的各种数据存储产品、存储中间件,当这些产品都成熟稳定后,可以再上层抽象一层数据库网关,结合数据模型和流量模型进行调度,对外暴露固定的几种访问接口即可。
Q5:你们做过哪些数据库的扩容?如何实现的?扩容时有没有数据的迁移?
A:目前平台已经支持的有 MySQL、Redis、ElasticSearch的扩容,其他数据库组件扩容还在建设中,扩容过载中均涉及到数据迁移操作。MySQL的扩容目前支持两种,升级套餐和增加只读节点,Redis的扩容包括增加单实例容量和增加集群节点两种,增加集群节点需要大量的数据迁移操作,这方面做的优化比较多。
Q6:DBA后期的职责定位是?
A:给业务提供数据库解决方案,解决数据库疑难杂症,数据库服务运营等。
Q7:数据库中间件开发需要具备什么能力?我在工作中遇到一个问题,我们测试数据需求很大,测试数据要到多个项目的数据库中查询,然后查询结果写到我们测试的库里。目前采用的方式是写好了SQL语句查库,查询涉及700多张表。查询结果往往好几个小时还回不来。请问有没有能够提高效率的方法?数据库是MySQL。
A:数据库中间件编程来说,我们团队目前用到的有Golang和C++,初次之外还需要对网络、系统、OS内核、分布式等理论知识需要较深的掌握。多表联合查询性能较低的话,单从数据库层面来看解决方案有限,可以考虑一些 ELT的方案。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721