
一转眼,两年过去了,这样的事件还是日常工作中频频发生。
说两个今年的案例,毕竟还热乎着。
上个月,我们某个产线系统遭遇了一次数据库宕机事件,整个控制台服务停止响应近一小时。
事后复盘,在场所有人都觉得不可思议,为什么呢?因为MySQL是双主互备模式,如果一台数据库挂了,应用服务应该是无感知才对。怎么会把整个服务都搞挂了呢?
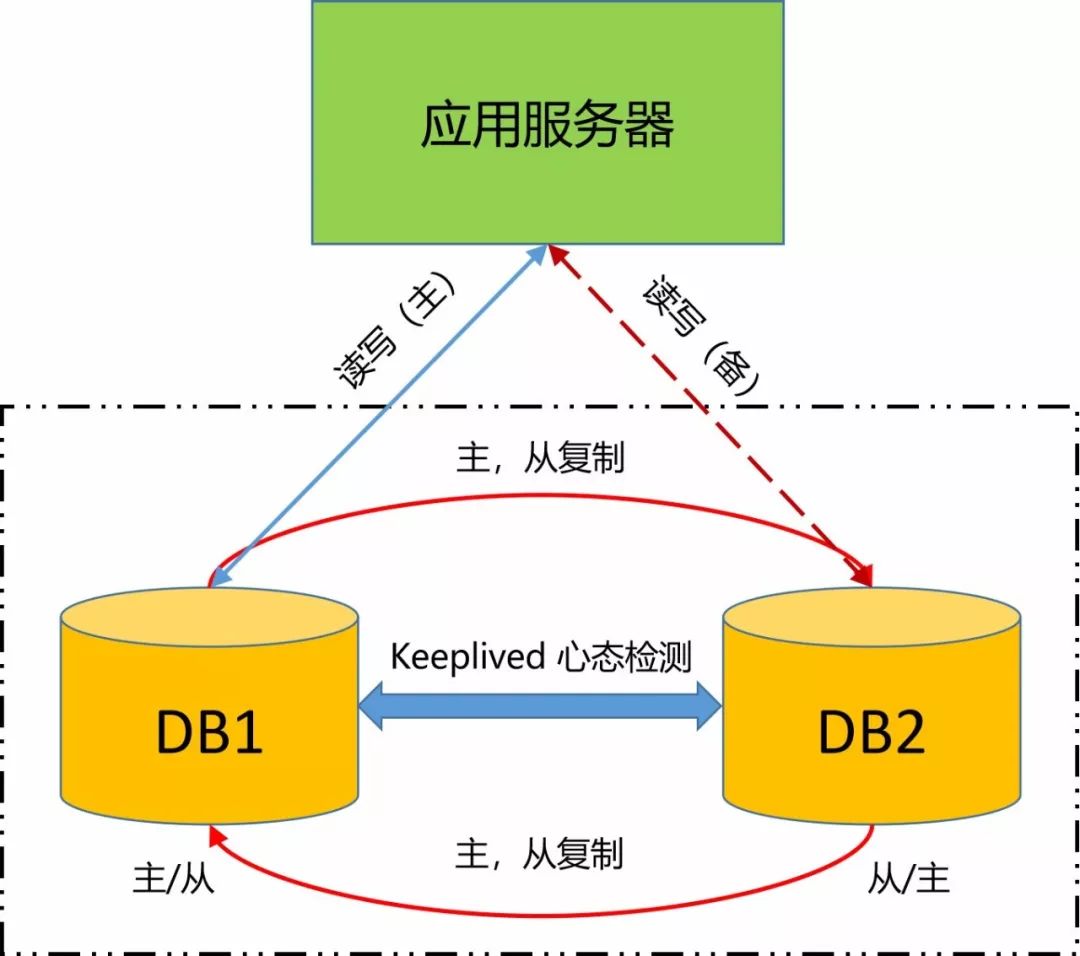
经过排查发现,虽然MySQL运行在双主互备模式之上,但为了节省资源,测试环境部署的是MySQL单节点,可能运维在发布的时候不知道要修改JDBC连接模式,直接在配置文件中搞了个直连单节点,就丢到产线上去了。
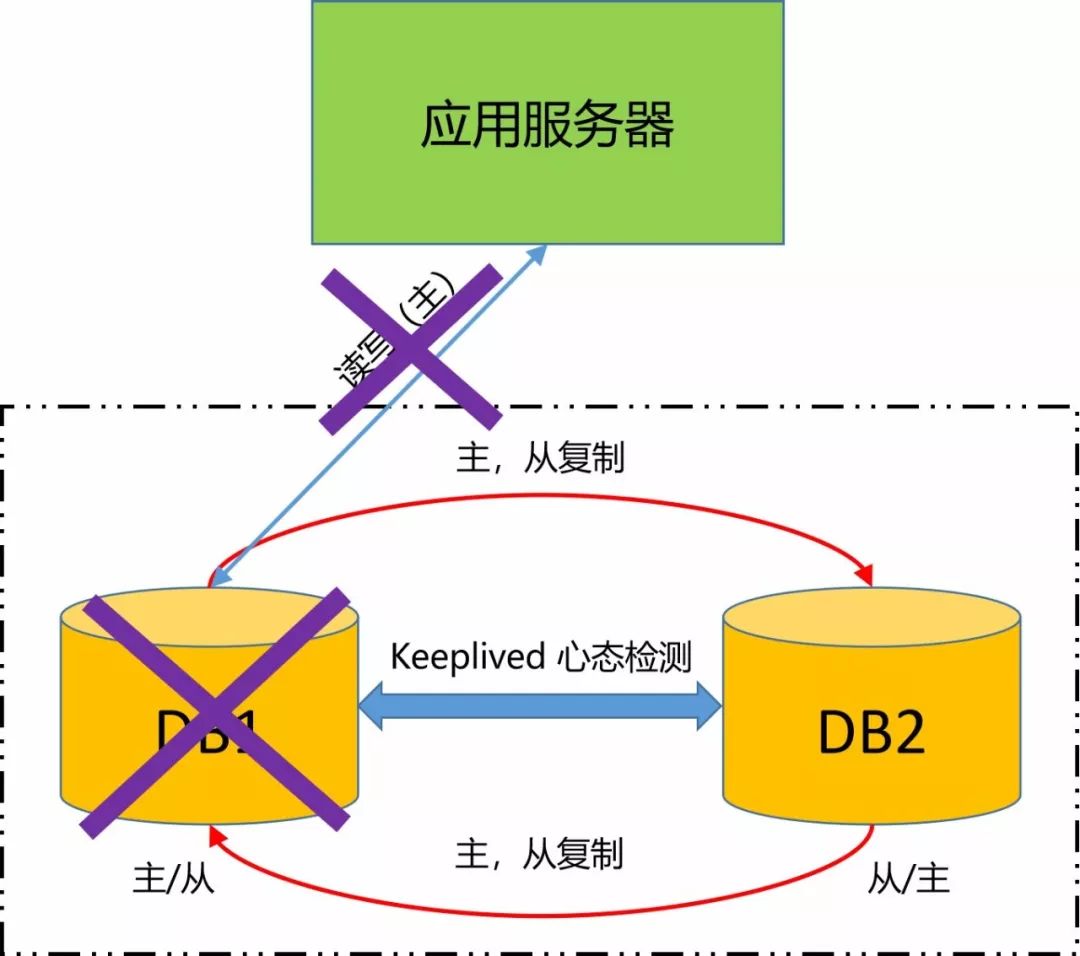
发布后,业务与开发都进行了功能性验证,自然都顺利通过。
直到在产线跑了一年后,数据库主库挂了,服务停止响应了,大家才发现。
说完了数据库,再说一个与应用服务器有关的案例。
上周的某个工作日,工作群里突然一阵大乱,有的人说OA系统卡死,几秒种后被抛到了登录界面,而有的人却说一切正常。
起初,大家都认为是网络抖动,或者是神打了个盹。但我不信邪,追查了一通,结果发现了蹊跷。
原来是某位运维的小伙伴,为了扩充资源,在没和任何人打招呼的情况下,直接重启了某台物理服务器,导致上面的近十台虚拟机受到影响。
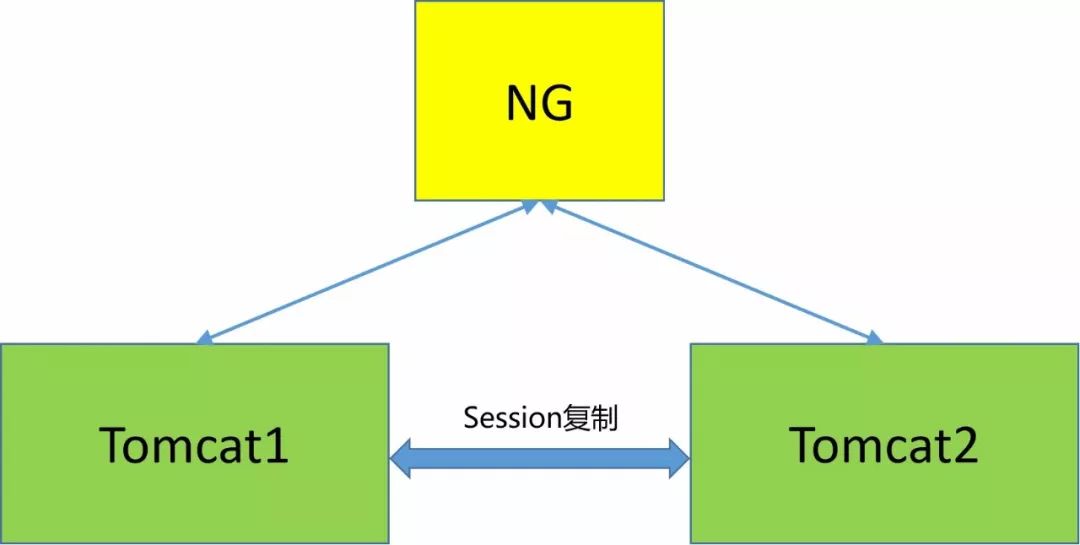
OA系统采用的是双节点模式,其中的一个节点恰巧部署在这台机器上。
问题来了,抛开人为故障的缘由不谈,既然是双节点,为什么一个节点挂了之后,有些用户会有感知呢?
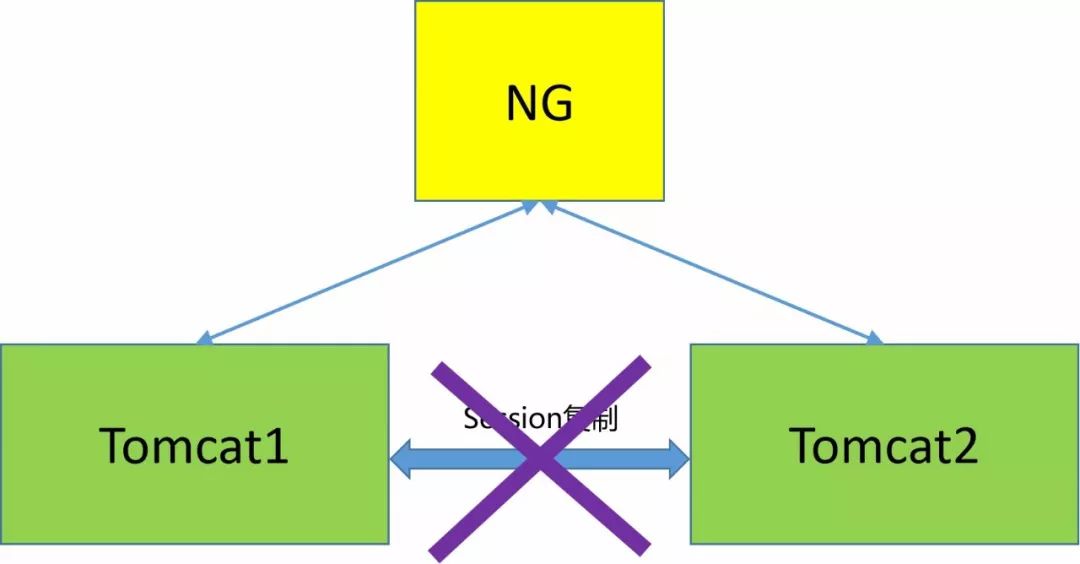
经过排查发现,两个Tomcat节点并未开启Session共享,所以才引发被重启的那个节点Session丢失,从而导致用户被抛到了登录界面。
为什么“理论高可用”屡禁不止?
我曾经多次在技术社交场合,与一些CTO、VP及架构师,甚至一线开发聊起过类似话题,但他们似乎都觉得这样的话题压根没必要讨论。为什么?
因为在他们眼里,发生这样的事完全是经验、能力与责任心的问题。
在我看来,经验多、能力强与责任心高的人才是可遇不可求的,尤其对那些中小型企业,无论成本还是规模,都不具备吸引这些人的属性,就算你有幸拥有几位这样的高手,基本也都被投入在业务一线的阵营中,不仅每天琐事缠身,忙得脚打后脑勺,而且还要顾及团队成员的成长,除非是一些重大技术决策与实施,一般不可能每件事都亲力亲为。
所以,当某位小伙伴突发一些所谓的 “技术疏漏” 事件,只要不把公司搞死,从情感上还是可以接受的。
扯完大道理,我还是结合自己的经验来谈谈。
在健身圈里,有好多健身者只练上肢肌肉,不练腿部肌肉。这也可以理解,毕竟健身是一件非常枯燥而急需自律的事情,你花同样的时间和精力,腿部肌肉再发达,也不得不套在衣裤里,秀给谁看?但是手臂肌肉就不一样了,你穿短袖的时候,手臂肌肉可以露出来,穿长袖时,手臂肌肉也能透过衣物显现出轮廓来。
但那些健身老司机都明白,如果你不练腿部肌肉,时间一长,你的身材就像《神偷奶爸》中的格鲁一样,不仅缺少美感,而且还会影响上肢的训练。
你想,所有的上肢训练都需要压在两条腿上,下盘不稳,怎么玩得起来?
因此,我们常说:“要练上肢,先稳下盘,只有下盘稳了才是真男人!”
同样的道理,一套系统,一套稳定的系统,一套稳定而高效的系统,就好比一个人的身体,上肢是应用,下盘是基础。
在追求 “快速迭代” 的今天,业务功能的 “快上线,别出错” 似乎变成了标准配置,也成为了衡量技术团队价值高低的一把尺,但这背后需要有强大的基础服务支撑,而这些基础服务却需要大量的金钱、精力的投入。
设想下,想要获得资源的投入,就需要得到决策高管们的认同。
假如你跟老板说,给我加100个人和100台服务器,我能搞出几个爆款功能,只要你曾经有不错的业绩,外加与老板之间有信任的基础,估计这事就成了。但假如你跟老板说,给我加100个人和100台服务器,我要对DevOps平台进行改造,相信很多老板都会问:“啥意思?啥叫DevOps?这对我的业务增长能带来什么帮助?”,你随即挺直了腰板说:“肯定有帮助啊!IT投入是一种价值投资!”。
想必很多老板都会愤然站起,并对你来一个手势:“Get Out!”
这叫 “秀才遇着兵,有理说不清” ,这也正常,一来是很多IT人的口舌普遍都很笨拙,想举重若轻地把一个技术问题给没有技术背景的领导说明白,比登天还难,二来是在一家业务驱动型的公司里,如果你想通过数字化的方式,呈现出技术投入和业务收益之间的量化关系,那你的抗击打能力要强,否则你会很容易精神崩溃。
长此以往,系统的发育变得畸形,像极了一个 “只练上肢,不练下盘” 的健身者。
平时穿着长裤,露着带有肌肉线条的手臂,看似一切都很正常,但对方给你来个扫堂腿,立马摔个四脚朝天。
不过,这些很多公司的技术负责人都不承认,不信你随便找一家公司的技术负责人来问,你们公司的系统高可用吗?他一定会拿出一堆图和数据,告诉你,我这里固若金汤,啥事没有。
但跟你混熟之后,或者你直接进入内部一看,基本都是千疮百孔,摇摇欲坠。如果你非要寻其根源,基本就是 “缺钱、缺人、没时间”。
在这篇 #讲个 '理论型' 高可用架构的故事给你听# 的文章里,我有提到想学 “饿了么” 搞随机故障测试,结果怎么样呢?
搞了一次,大家都觉得有点鸡肋,放弃了。
咦?为什么呢?先来晒一下当时的方案。
在决定启动做这件事之前,我们先明确了3个目的,一是论证是否存在理论高可用,二是验证是否能快速发现问题,三是当发现问题之后,是否能快速解决问题。然后再确定了3个测试场景,一是随机断网,二是随机断电,三是随机弱网络。
一切就绪,拿什么系统开刀?直接在产线上搞嘛?
有人提议拿交易系统,而且必须上产线,否则没有意义,话音刚落立即有人反对,理由也很犀利,“出了事怎么办?你确认没问题吗?”
一群人没经验的人,你看我,我看你,无法回答,算了,放弃。
那就拿某非交易系统,在仿真环境搞吧。问题来了,虽说是仿真系统,但无论是应用节点数量,还是服务器性能配置,都与产线有很大不同。比如数据库,仿真系统就是只有2个节点,一主一备。
就在要进入僵局的时候,我提议:“既然大家都没经验,要不就先试试看,然后咱们基于实践再来复盘。”
赞同,当天晚上就风风火火地搞起来了。结果如何?一切正常。
无论是应用,还是数据库,乃至中间件,轮流断网、断电及网络丢包,只要还有一个节点活着,似乎业务都能正常访问。
瞧瞧,咱们的系统太高可用了。
有句话说得好,“来得早,不如来得巧”,就在我们随机破坏测试执行后的第二周,被测系统就在产线来了一场罢工,原因是某节点宕机之后,负载均衡策略没有生效,导致部分用户收到404。
咦?不是随机破坏测试的时候测过吗?通过排查,才发现NG的配置与环境部署,生产与仿真完全不同。
从结果看,这一记耳光很响亮,对大家的打击不小。
在复盘时,有人提出,我们重新梳理仿真环境,无论配置、节点、部署,都改成与生产一样,并在仿真环境按生产环境要求添加监控。也有人提出反对,觉得与生产同步完全不可能,人力和物力都不允许,何况我们的仿真环境是用来做业务验证的,如果用它来承担随机破坏测试,会不会对业务部门产生影响?另外,这才刚刚触碰到非交易系统,如果是交易系统,又该如何去做?
最终,大家都觉得必须在生产上做,这件事情才会有意义。但该怎么做?
在服务、环境、灰度及监控不完善,经验不足的情况下,这个课题还要不要继续下去?
还是歇了吧,等条件成熟的时候再做吧。
我曾问过很多人,为什么你们费尽心思要招有经验的人?回答基本一致。
一是探测地雷,仰仗他的经验,能避免他曾经踩过的坑不在这里重现。二是降成提效,仰仗他的经验,能够用更少的资源、更快的效率达到目标。
更重要的是,我们期望这些有经验的人,能够慷慨地将自己的经验传授给那些经验尚浅的年轻人,从而达到团队整体实力提升的效果。
想得挺好,效果怎么样呢?
在我的经历中,无论你请谁来,无论你怎么为他配备资源,放心,他曾经踩过的坑还是会在这里重新踩一轮,那些栽过的跟头也继续要栽一次,甚至踩得更深,栽得更狠。
这是为什么呢?
当然,不排除我身边都是一些倒霉鬼,或者引进的人都是水货。但相比之下,我更愿意相信是因为客观环境因素的不同,从而导致原有经验的可落地性变差。
怎么理解这句话?我来说个亲身经历的案例。
去年,我写过一篇 #故障:一场由虚拟化存储引发的分布式缓存性能悲剧# 的文章,详细描述了一次由虚拟化存储引起的分布式缓存故障。
在文章发布后的第二周,就曾有读者提出质疑:“核心中间件,居然出现如此小儿科的故障,你们上线之前不做高可用与性能的测试吗?”
我的回答是:“我们不仅在上线初期做了非功能性混合场景测试,而且每周还会做常规性压力测试。值得一提的是,代理层的核心代码是团队中某架构师从以前公司带来的,声称这套系统曾经历过 “双11” 的洗礼,流过血,流过汗,值得信赖。
无论怎么想,似乎都会相信这套系统是可靠的、高效的。但万万没想到,在稳定运行很长一段时间后,却无声无息地死在了I/O争抢上……
因为事故的影响范围太大,在事故复盘的过程中,业务方老大吐槽,“我平时偶尔也参加你们的技术评审会,最常听见的词就是 ‘高可用’、‘高性能’,看了大家是很重视的,也确实做了很多工作,但为啥一遇到实际场景,就不奏效了呢?”
我当时正在气头上,直接回了句,“是啊,我也想知道啊,等明天我打个电话问问服务器,为啥他突然间发脾气,不高可用了。”
就因为这件事,整整一周,团队的士气都很低落。
事情过去一个月后,我请团队小伙伴喝酒,一来缓解下情绪,二来提升下士气。
酒桌上,我端起酒杯走到那位负责缓存的架构师面前,说:“别一脸颓废,搞咱们这行遇到这种事情不是很正常吗?一切都过去了,后面咱们再慢慢改进。”
他笑了笑,端起酒杯站起来,说:“哎……我一直对这套系统很有信心,没想到出这种事,觉得太丢人了,搞得好像我只会耍嘴皮子似的。”
我拍了拍他,说:“别担心,下次神会与你同在。”
自从有了互联网+这个名词之后,似乎到处都能看到或听到各种高可用架构,并且还会有个看似很牛逼的人告诉你这个系统架构多么牛逼,用某某框架你的系统就会起飞,但仔细想想,这对你来说有用吗?
因为他们只给你指了一扇门,告诉你通过那扇门你就有多牛逼,但钥匙在哪里呢?而且也没有告诉你,在走到那扇门之前,用什么方法才能把我从现有的坑里拽出来?
记得在某技术大会上分享的结尾词,我说过这样一段话:
为什么别人的高可用架构,用到我这里不起作用了呢?
因为真正的高可用压根就不用纠结架构设计,更不用纠结是否有大厂用过,对于一般的企业来说,只需要把注意力放在代码的健壮性、主备设计及环境治理上就行了,不需要其他的。
忽略了这几点,还谈什么高可用呢?
当然,有的人天生内心强大,把理论高可用也当成一种高可用,没毛病。
作者:王晔倞
来源:吃草的罗汉订阅号(ID:kidd_wyl)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721