1)甩锅心法第一则:立字据

Big Ball of Mud,中文名称“一坨翔”。自打我入行以来,就一直在和这一坨翔做搏斗。此处略去一千字,反正相信我,哥肯定是吃过翔的。虽然不少翔是自己拉的。
有太多文章谈论这个问题了,每次满怀热情的打开,然后看到结尾要么就是告诉你要拆微服务,要么就是告诉你我这有个什么样的中间件产品,你要不要用一用。你妹啊,如果知道怎么拆,需要来看你的文章么…… 咱不多废话了,严肃起来。

Big Ball of Mud 的系统有三种死法:
因为性能不满足要求而死,这个时候需要懂内核懂数据结构的架构师来好好做一下拆分,让系统更符合计算机体系结构,最大化利用硬件资源。各种新式的中间件就是在这个领域不断革命。
因为业务逻辑复杂得 hold 不住而死,开发效率慢到爆。
因为软件架构不符合组织架构,导致团队间吵架吵到死的,这个时候老板重新思考什么样的组织架构才是合适的(大 boss 通过组织架构划分,他绝对是最终极的架构师)。
计算机体系架构因为其是确定性的,这个结构调整相对好做。我们见过很多实际的例子,通过调整代码的结构,使得 cache miss, branch prediction rate,data locality 大幅优化,而性能数倍提高。
我的梦想就是,找到一种拆分系统的原则,使得其能够和业务架构非常贴合。从而减少让焦油坑一般的厚重的业务逻辑代码也可以变得充满美感。对计算机有兴趣的青年,不应该最后都到基础架构的领域里去造轮子。Eric Evans 对于 Core Domain 的说法深得我心。
然后就开始了找赤脚大夫,抓药方的不归路。
一、看看这些药方
在那个还有 CRC 卡的年代。面向对象设计,领域模型这些是被寄予厚望的。在曾经的 javaeye 论坛上,如红小兵一般的当年的我,也是很激情澎拜地参与着模型是应该贫血还是充血的争论。
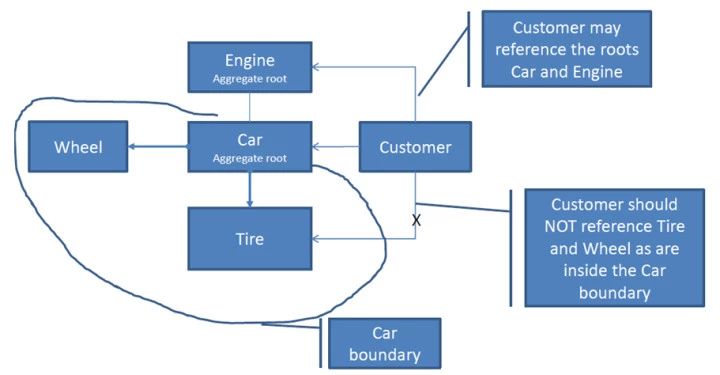
大部分尝试使用领域模型的项目,好一点的只是在代码里多了一个 model 目录,倒没有付出什么成本。差一点的是把整个数据表重新定义了一个 xxxBO 的对象,然后每次都要多一次对象的字段拷贝。逻辑写来写去只看见增删改查,哪里有什么领域模型可言?
领域模型说穿了就是一个 AggregateRoot,就说要维护一个 model 的概念完整性(conceptual integrity)。比如一个账单上的账要是平的,某个条目上多了,另外一个条目就要少了。这些业务上的恒定规则(invariant)需要被封装到对象内部被保护起来,以免数据出现逻辑上的错乱(和并发无关)。有多少系统有复杂的业务规则需要这么封装的?其实很少。
面向对象流派发展到后来又出现了 qi4j (Qi4j Community)以及 DCI (Lean Software Architecture)。
概念其实都是一样的,一个对象来承担不同上下文的职责是会膨胀的,完全没有必要把参与不同业务流程的不同职责,强行塞到同一个对象里。
我们应该要把对象按照不同context,把逻辑拆出来。但是等 James Coplien 这些大牛们想明白的时候,微服务已经主宰世界了。
在微服务的世界里,服务的拆分代替了类的设计,变成了主要的建模工具。至于一个服务自身是贫血还是充血的,已经没有人在乎了。
最常见的药方长这个样子:
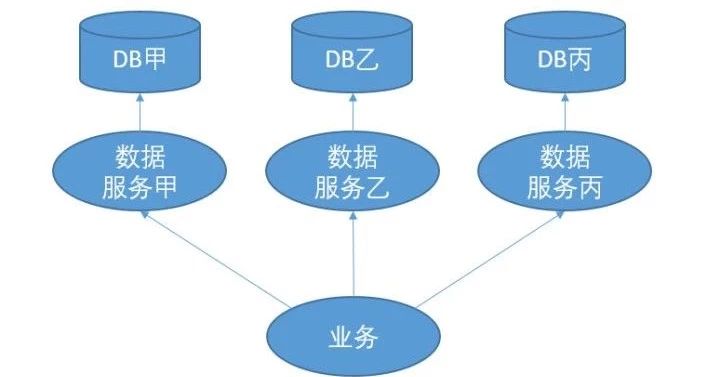
这个药方在不同时期,被不同的大夫,以不同的名字开过。还记得当年的 .NET Web Service,SOA 吗?把各种 RPC 技术往 DB 前面一挡,咱就服务化了。
我一直就纳闷了,你一个远程调用的 DAO 有什么贡献?业务代码里写 http://mysql.xxx 和写 http://rpc.xxx 有本质区别?
当然数据服务可以处理分库分表,缓存同步等问题。但是那些本质上都是非功能性需求,是一个业务无关的轮子。对于业务代码的贡献就是把非业务的逻辑给剥离出去了而已。
比卖 RPC 方案(WS-xxx 标准当年也养活了不少人那)更可恶的厂商,是那些兜售 ESB 的厂商。
也许这些所谓的流程引擎,可以在 OA,运维部署工具等特定领域减少开发工作量。打着提高开发效率的做一个平台,来托管业务逻辑的行为是可耻的。
Udi Dahan 的一个评价特别静精辟,这些做得好,最多就是一个VB6,做得不好就是场灾难。
曾经自己拉一坨这样的翔,然后含着泪喂给伙伴们吃完之后,从此看见 BPM/ESB 这样的字眼就特别紧张。
构造一个平台,和发明一门 PHP 这样的语言差不多复杂。上面需要有调试,编辑,版本管理,版本 diff 等一系列的支持。
大部分的公司内部系统,没有足够的资源去把这些东西给做完善来。如果不是面向特定的场景(数据处理,OA,运维),而是一个非常通用的系统,其效果只能比 PHP 裸写逻辑还要糟糕。
安利一下,世界上最好的流程调度和编排工具:PHP,没有之一。
另外一个流派的口头禅是耦合。你看,RPC 是邪恶的。服务之间调用耦合太严重了。我们需要引入队列来解耦。Fred George 同学甚至把这种通过消息异步解耦的系统架构推上了神坛的高度。
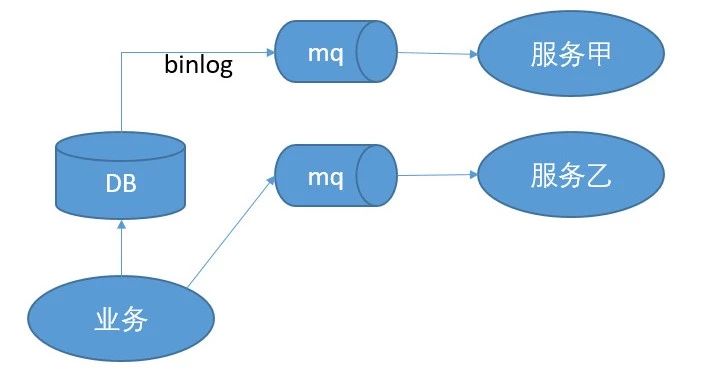
看架构图,我们都是兴奋的。这种太好了,我业务都不用感知到这些下游服务的存在了。你们自己去订阅我的消息队列就好了。但是一旦用到实践中,就发现你根本没法直接用起来。
常见的借口是这样的:
消息处理的可靠性:kafka 后面最常见的业务是什么?其实是一些看趋势,做智能分析的业务。如果你不用在乎少几条数据没处理,大可以用这种异步架构。如果你要出财务报表?那还是老老实实用DB吧。
消息处理的及时性:你别把 kafka 用到主流程里。这个消息要是被延迟了,会死人的。RPC 还是“可靠”一点。
业务本来就是同步的:我是一个手机 app,我的端的交互接口就是需要在操作了之后,同步得到服务甲乙丙N个服务的处理结果。没有这些数据,操作完了的界面上就看不到剩余配额,看不到账单,看不到xxx。你 mq 能给我返回值么?我擦……
当然做为一个理想追求的你来说,觉得这些都不是问题:
消息处理的可靠性:消费的时候如果失败了不提交offset就行了嘛。挂了会从上次失败的地方重试的。最多重,不可能丢的。再说了,还可以实时对账,隔天对账嘛。
消息处理的及时性:就好像 RPC 服务不会挂一样。异步无非就是多了 mq 这一跳而已嘛。我拍胸脯,保证不挂,行不行?我给你做压测,保证p99的延迟低于xyz毫秒。
业务本来就是同步的:doXXX() 这样的接口就不应该返回具体的界面数据。应该是doXXX()给个成功和失败,然后 getX(),getY(),getZ()。如果消息还在异步处理中,大不了显示的counter还没有+1,或者我就干脆写一个“还在处理中”就好了嘛。
世界上的人都是你这样有理想的人该有多好哇。不过相信我,大部分同学会认同,异步化没有帮他们解决什么问题,反而搞出一堆麻烦事情来。你说让他们去找产品,把需求改成异步的?扯淡吧……
以 Greg Young 同学为代表的大夫,最喜欢的就是跟你说“我这有一个蓝色的小药丸,你吃不吃?”。他的药丸长这个样子:
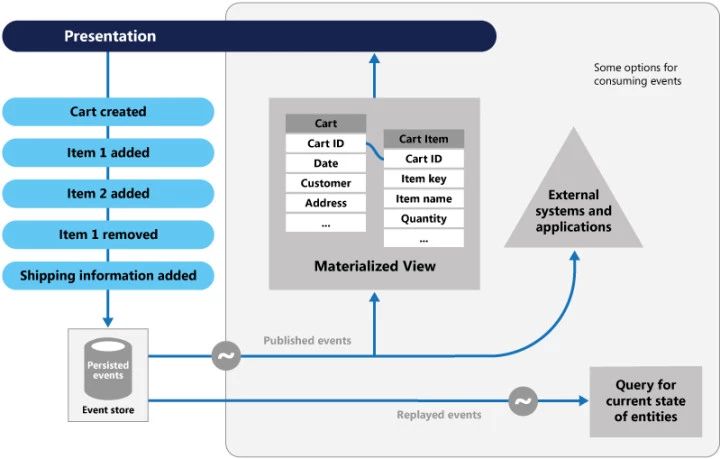
你们都做错了,业务逻辑要以 command/event 为中心,而不是以 state 为中心。难怪你们都写出来的是一坨翔。你看哥的这种 event handler 的模式,多么牛x。
我们知道丝袜可以治疗静脉曲张。但是不代表人人都应该穿丝袜。到底 Event Sourcing 怎么就解决了复杂业务逻辑的问题?我就是不用 event sourcing,我也可以在业务代码里产生事件并写 mq 啊?
Greg Young 的说法是如果你的业务不是以 event 为中心的,那么这个 event 你怎么知道是对的呢?
来来来,我们看看 accountant 都是怎么工作的:

会计是从来不用橡皮擦的。只有我们的系统是以 append only 的 event 为基础的,我们才是可信的。我擦,好有道理的样子哦。
但是我相信你从激动里回过神来,尝试了三五天之后,肯定会放弃在你的生产环境里吞下这个小药丸。简单来说,就是不值得。
大部分的人都不是在做高并发写入,同时又具有复杂业务逻辑的事情。大部分人的工作就是增删改查,把数据按照业务逻辑算对了而已。没有对冲基金,证券交易所这种的业务上下文,Event Sourcing 就是 over design。
事实上所有的 DB 都是 Event Sourcing 的。我们只是把这部分有挑战的工作,托管给了 Oracle 那帮聪明的家伙了而已。
只有当悲观锁(事务),乐观锁(单行事务,update xxx=zzz where version=1)都玩不转了的时候,我们才值得把状态从 DB 迁移到业务代码里,自己来管理状态的并发写入。
刨去了 OLTP 部分用Event Handler的模式,Event Sourcing的另外一部分故事,不过是前面异步化方案的新瓶装旧酒而已,仍然有同样的问题,不是所有人“都愿意”被异步化的。
这是一个技术问题,更一个团队合作方式的问题。
二、出发看看我们怎么做吧
我们从解决方案出发,妄图通过不断尝试不同的药来解决问题。
这种从解决方案出发的态度随处可见,比如问啥叫微服务?服务多微才叫微服务?JSON+HTTP 好,还是 Protobuf 好?RPC 好还是走消息队列好?
不要问什么是微服务,要问微服务能够给你带来什么。如果不知道什么叫”好“,你怎么知道哪个好呢?
从老板的角度来说,他们真正只在乎两件事情:
系统要稳定,别挂
出活要快,我让你们加什么功能,赶紧就给加上
然后他们假装会在乎
少用一点机器和带宽给公司省点钱
别出错,让用户的体验好一点
实际上打心底里,最重要的还就是前两点。少用一点机器根本不用你上 Protobuf 来省出来,消息队列再怎么高效,都没有本质的提升。
什么叫质的提升?
某厂一个小姑娘带着老板的尚方宝剑去各个业务组敲打一圈,一下子收归几千台空闲机。这就叫质的提升。
当我们得知真相之后,正在做各种性能优化的码农的心是崩溃的。和稳定性与交付速度相比,性能和成本绝对不是什么值得在台面上讨论的问题。
即便要解决这个问题,也轮不到用技术手段来解决。就像中国的银行有所谓的“窗口指导”一样,领机器的时候卡严一点,比什么都管用。
用户体验也是一样的。
互联网企业最常做的事情是灰度,拿一部份用户做小白鼠。另外一个常见的做法是最终一致性,碰上点故障那就是最终也一致不了。个别用户碰到一点奇葩的现象实在是太平常了。
老板们关心是大部分用户的体验是不是好,至于长尾的体验,实在是顾不过来的。
业务逻辑是不是写得非常完善,事务处理是不是天衣无缝。这个都不是最重要的事情。让系统来解决99.9%的事情,剩下的0.1%,交给RD和客服去处理就好了。
这对有手写raft协议的追求的人来说是一件很崩溃的事情,但是这个是对大部分业务来说最经济的选择。不需要你搞一个多完备的东西出来,偶尔出错就出错呗。
那么稳定性和交付速度就是最重要的两个指标了。
把一个单体应用切分为多个进程,独立部署是必然的。
我们应该拆分成,咳咳,独立的微服务。这不是废话么。问题是怎么拆?我现在觉得,其实怎么拆都行,因为都比合在一起要强。

单体应用的最大问题是它一个部署就阻塞了所有其他人的上线。
而众所周知,我们谁都没有测试,至少是没有可以保证业务不挂掉的测试。
真正的冒烟测试,都是用上线灰度的方式来做的。剩下的功能测试,是接下来数天里用线上开关的方式逐步地放量来做的。线下的测试么,我就呵呵了,你懂的。
单体应用的存在,使得每个功能可以被分配到灰度时间变少了。这么多公司都在拆微服务,最重要的收益是让每个模块能够独享自己的灰度时间,从而大幅减少因为上线破坏旧的功能引起的故障。
无论怎么拆分,都会比合在一起要好。这里“好”,指的是少出故障。实际上是怎么切的,反而不是那么重要的事情,只要能切得开,哪怕你是复制一份代码呢?
我的判断是,90%的一坨翔不是因为业务自身有多么多么复杂。而是因为不懂得拒绝,总是做老好人,什么事情都干。
就是因为你总是做劳模,替所有人干所有的事,屎盆子才会扣在你的头上。要想避免一坨翔,要从学会甩锅开始做起。传你五条甩锅心法,保平安:
立字据;
透传;
让他们来取;
如果还是要我推,我就和你们同归于尽;
相信队友。
所有这些招数,和上篇里列举的那些架构模式没有本质区别,不过是换了一个说法。
但是我们这次很明白自己的需求是什么。提高团队的自主性,不要被周边系统连累。一个需求,尽量一个团队搞定。减少跨团队沟通的需要,提高所有人的效率。
如果开的药方可以做到这一点,就是一个好药方。
1)甩锅心法第一则:立字据
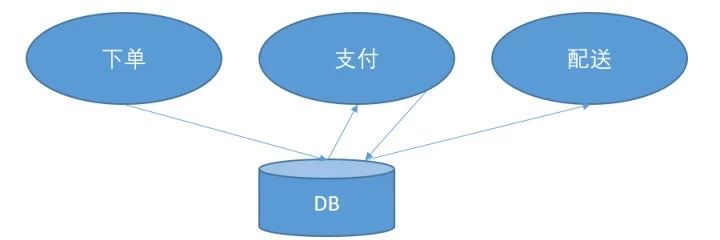
哪怕是亲兄弟,也要明算账。坚决不要和其他的服务共用db。我的是我的,你的是你的。
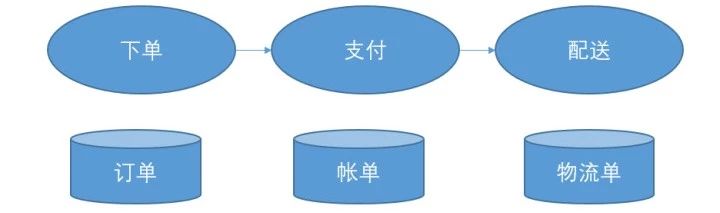
各做各的业务,你要存什么,你自己存去。别挤到一个庞大的Order表里。让你和其他的服务之间,有明确的起止边界,是甩锅最重要的事情。
当出了问题的时候,你的责任非常清楚,看看输入,看看输出,一目了然。要不然某个Order上的字段错了,到底是谁写错了都搞不清楚,大家都有读写权限。
最极端的情况,流程的每一个步骤都可以切出一个独立的服务出来。
让每个服务有自己的存储,自己独立去面对最终客户,目的是为了让有需求来的时候,每个服务的团队可以更快响应。他们上可接客户,下可接存储,拥有了最大的自主性。
而与其他的团队之间也有很清晰的接口(连产品经理都可以说得出来的),从而最小化了沟通成本。
其实所有在数据库里有 1:1 关系的表都有类似的问题。
我们可以选择一个表n个字段。也可以选择把表分为两个,然后1:1对应。从快速试错,满足业务需求的角度,拆分出独立的表是更优的做法。
也就可以表达为,如果要加一个功能,优先选择建一个新的模块,把这个特例的需求搞定。而不是去修改现有的表,把功能写到现有代码里。
代码重用,从来就不是老板们关心的事情。快速实现需求才是。
从90年代的OO理论,到现代的微服务。我觉得最大的进步就是大家觉醒了,快速实现 != 代码重用。
与其给场景A加两个字段,给场景B加三个字段。不如连同代码和数据,一切都切分出去好了。
2)甩锅心法第二招:透传

在查询接口上最恶心的事情是要把一堆杂七杂八的东西都放在一起返回。甚至很多数据都不属于你,是别的团队提供的。
要想减少你替别人做嫁衣(想一想,对方年终奖会分给你多少?),最佳的办法是甩锅。
与其让别人返回一个enum给你,然后你吭哧吭哧地翻译成中文,拼装出其他需要的数据。直接开一个map透传的接口,你要给用户什么数据,你自己搞,爷不伺候了。
因为你提供的是透传的接口,后端的系统有什么字段要加,也不会再来找你了。
无论前台是一种什么形式:
富客户端,JSON API;
HTML页面;
IFRAME拼装的页面。
都有办法从前到后透传,技术上都不是问题。如果可能,尽量让客户端取多次,在前台界面拼装。
如果可能的话,让一个团队为最终结果负责,而不是做成两个团队来接力的模式。接力掉棒了,就会有扯皮的事情。
3)甩锅心法第三招:让他们来取
做业务流程的同学,总是会被其他的兄弟部门找过来。你能不能在用户下单的时候,调我一下接口,做个xyz啊?你能不能在送达了之后,把配送时间写到某个redis里,我们数据分析要用哇?
别做老好人,学会拒绝。
凡是和我的本质工作不相关的,请不要让我来实现。我把事件放到kafka里,你们自己来拿。RPC 和消息队列最本质的区别,不是网络开销,不是提高并发,而是职责的反转。
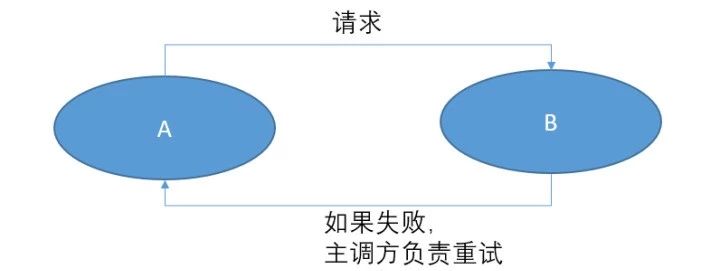
在 RPC 模式下,责任是在 A 团队的。如果 B 挂了,A 要负责重试。如果 B 一直挂,A 团队的负责人要接告警,然后打电话给B团队的人。
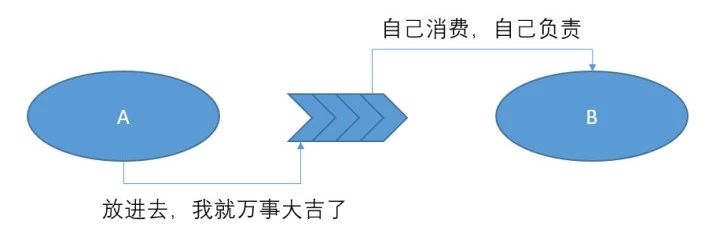
在消息队列的模式下,A是甩锅甩得很彻底的。没有人会闲的没事,帮 B 去监控一下他消费的offset。那不是我的责任,是你的责任。
B有两个常见的借口:
我不知道怎么消费队列,我给你个http接口,你来call一下,能有多难;
队列里的数据不全啊,我还需要xyz。
别慌,该甩的锅,坚决要甩。不能有妇人之仁。
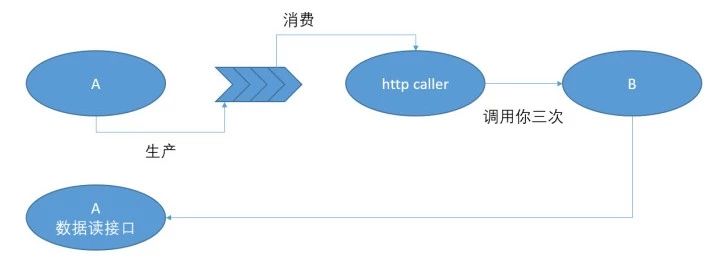
让消息队列的团队,额外提供一个 http caller 帮助残废的B去消费数据。怎么消费好搞,让 B 自己和基础架构的人去谈。A,概不负责。
如果消费的时候需要一些关联的数据,A提供读的接口,B自己来取。
如果单条读太慢,可以提供批量读的接口。
用户调用你的RPC的接口也不会把所有的数据都给你啊,还不是要读数据库么。为什么消费队列的时候就指望队列里有你处理逻辑的所有需要的数据呢?
在某个时间点上要发生的事情,不一定要一个地方都写完了。把事件放入队列,让相关方自己来取。他们自己去负责自己的事情,去取自己需要的数据。
4)甩锅心法第四招:与之同归于尽
好说话的合作伙伴,通过透传和写队列,都可以搞定。但是世界并不是这么简单的:
我的强依赖他们的数据啊,他们的返回值我需要用;
我给用户的返回值上的数据是他们提供的,走消息队列搞不定啊;
这个事情现在不发生,晚一点就没意义了。走队列没收益嘛。
确实是我自己的业务逻辑需要,比如我需要读订单,需要读用户信息。你能够让db的读接口也走队列么?肯定不行嘛。
总是会有一些服务和别的服务不一样,你是甩不掉的。你们必须紧密协作,完成共同的kpi。
问题是如何判断,你依赖的服务是真的必要的强依赖,还是强赖着不走?我现在觉得最有效的手段是,问他愿不愿意跟你同归于尽。

做为A,你去问B这个问题:如果你挂了,我也连累地挂了。然后每分钟几百万的损失你来承担,ok不ok?
如果B的答案是ok,我们共同来担这个责任。这就是真爱哇。如果B犹豫了,你就知道这是个假的伙伴。因为稳定性是老板最关注的事情,只有拿这个去切,才能真正切开。
如果你问B,你愿不愿意走Kafka?B肯定会说,RPC不是走得好好的么。
哪怕在你的返回值上,有B提供的数据,也是同样的问题。还是问你自己这个问题。当B挂的时候,你是宁愿这个字段是空呢,还是让整个接口都挂掉?
部分字段为空,大不了体验受损,也肯定是好过整体故障的。
这个“you jump, I jump”的问题,不仅仅对接口这个级别有效。更可以深入到字段的级别。
也许A必须及时调用B,哪怕B挂了,A确实要负责B的重试。因为A和B共同推动了业务流程的前进,不把棒可靠地交到了B手里,A和B都没有好果子吃。
但是并不代表,B提的一切要求就是合理的了。也许B给你提了一个20多个字段的接口,未必每个字段都是必须的。还是同样的做法,问问你自己,是希望某个字段为空,还是要死保稳定性。
在稳定性的高压下,一切同步接口都有变成异步的可能。哪怕99%正常的时候是同步调用,在那1%的故障场景下,所有人都可以接受一个异步的体验的,总好过挂掉的体验。
而现在的中间件技术,提供的是要么全RPC,要么全异步的非黑即白的解决方案。并没有特别好的现成的方案来支持“平时是同步的,故障时改成异步的”这样的用法。
5)甩锅心法第五招:相信队友
和外部的系统打交道,我们一般有这么两招:
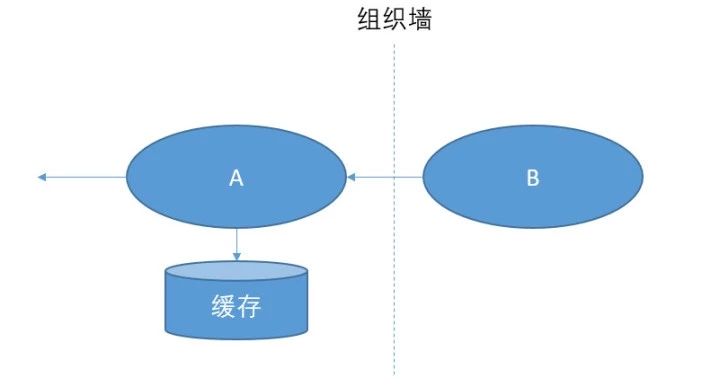
缓存一份对方提供的数据。提高访问速度,在B挂掉的时候,提供兜底方案。
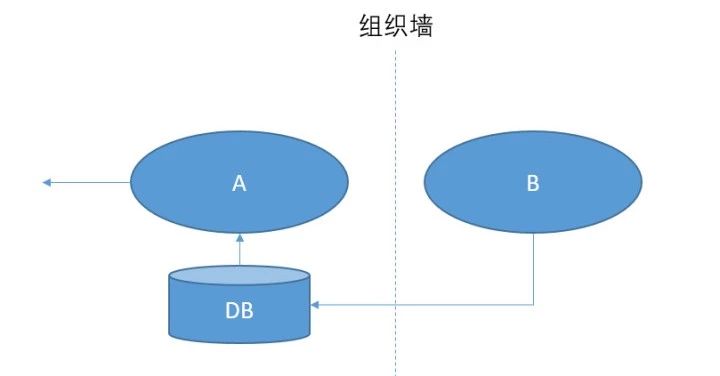
第二种做法是不直接依赖 B,只订阅 B 的变化,写入自己的数据库。
这两种模式在你挂了,没法让B来背锅的场合是可以的。
比如 B 是一个外部的国企。你就把B的可用性的责任,背到了自己的身上。如果 B 是你的队友,你要相信他们。你依赖的缓存是同机房的某台机器,B 也可以把他的服务部署到你的机房啊。依赖自己的缓存,和依赖B没有本质区别。
从全公司的角度来说,大家都做一份缓存,只是多复制了一份数据而已。和 B 签订好 SLA,如果 B 挂了,慢了,让他们来背锅。
这种把一个存储前档一个数据服务的做法,有什么作用?
如果只是增删改查的话确实没有啥用。如果只是解决分库分表,那确实不如改名叫 dbproxy 得了。为啥要搞出这样的队友来?我自己依赖数据库不行么?
在前台应用比较丰富的情况,一些公共的业务上的规则要得到保证(比如全平台封禁)只能在中台来做。
甩锅第五招,相信你的队友,让他们提供 SLA,有些底,你是不用兜的。
三、总结
因为稳定性的需求,切分是绝对必须的。做好灰度发布是最最重要的事情。
切分就是一个学会拒绝做老好人,不断甩锅的过程。按照我给的几条心法,没有什么锅是不能往外甩的了。
最后解放思想,不要固守什么模式什么原则。评价好坏只有两条硬性指标:系统是不是稳定,是不是能快速响应需求变化。
愿各位少谈一点主义,多解决一点问题。各司其职,多写点代码,少开些会,早点下班。
作者:陶文
来源:逸言订阅号(ID:YiYan_OneWord)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721