
锦洋,负责饿了么蜂鸟APP的架构、研发等工作。目前关注的技术方向为移动端监控、移动端架构、移动端性能优化等方向。
在这个重视稳定性的年代,很多公司在移动端性能监控上花了很大的力气,对业务可用性监控的投入不足,但是移动端可用是由性能可用和业务可用共同组成,缺一不可。
因为业界性能监控已经比较成熟,有很多第三方的平台,所以避开性能监控不谈,下面介绍一下饿了么物流移动端在业务可用性监控体系建设上的一些探索。
饿了么物流移动端作为骑手直接使用的配送工具,需要每天承载千万量级的配送单量,骑手app具备以下三个特点:
时效要求高
网络环境复杂
重度使用
骑手需要在30分钟内将订单配送到用户手中,中间实施多次订单操作,可谓争分夺秒,如果遇到网络或者定位异常都可能导致有损操作,为了保证骑手的操作顺畅,我们需要将骑手整个配送过程纳入可用性监控体系建设中。
经过长期的探索,我们建立了一套自己的移动端业务监控体系:
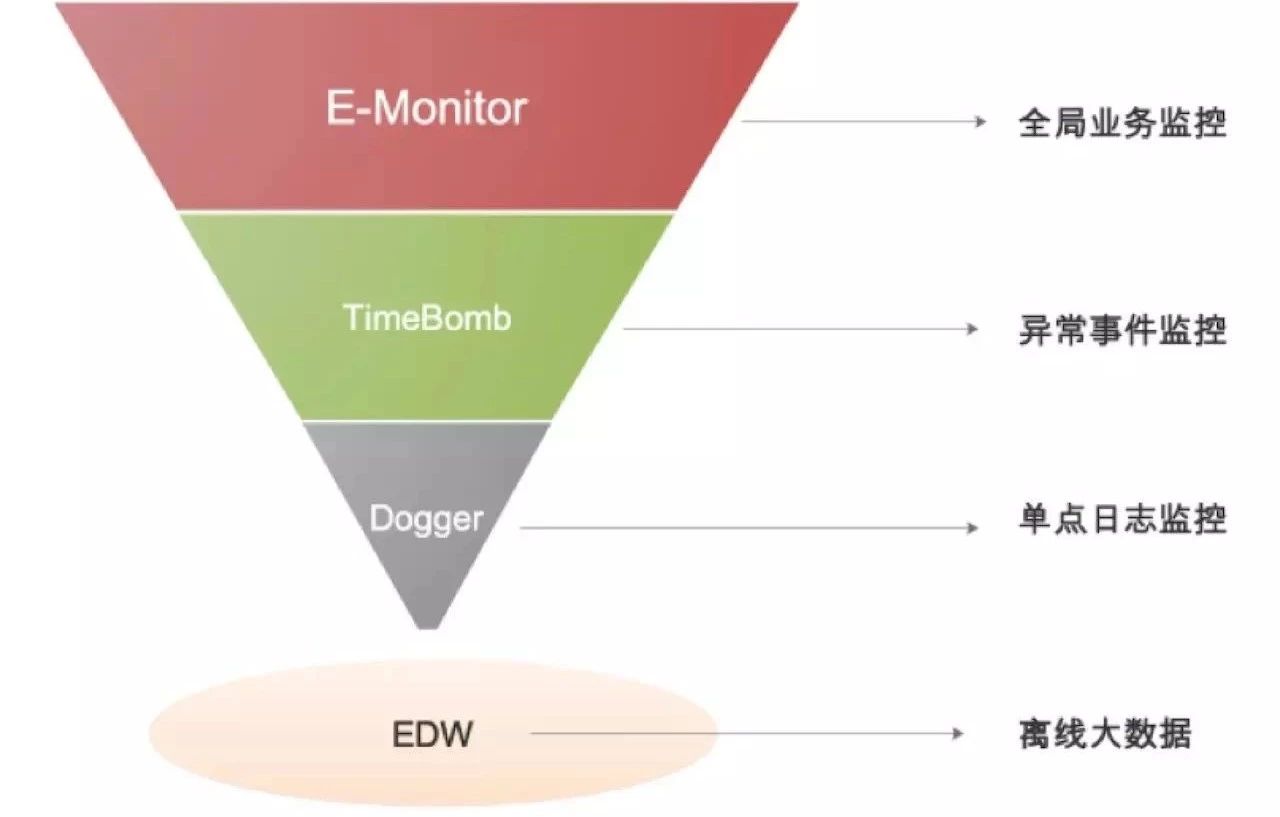
整个监控体系就像一个数据漏斗:
第一层 E-Monitor:全局业务监控,纵观全局,掌握业务大盘趋势;
第二层 TimeBomb:异常事件监控,定点插针,实时报警;
第三层 Dogger:单点日志监控,全量日志,还原现场;
第四层 EDW:离线大数据,T+1报表,大数据分析业务健康度;
下面给大家详细介绍一下这四层监控。
一、E-Monitor
大家都知道作为移动端本身不需要对接口监控敏感,因为后端有各种维度的API服务监控,但是App作为上层应用,接口的成功失败,并不能完全替代用户的感知,这是有调用方的特征决定的。
一次业务请求包含:准备请求数据->发送请求->网络链路->请求回调->解析->渲染。
任何一个环节的失败都可能代表着用户的一次交互失败,所以要想完全掌控线上大盘的核心功能使用曲线,完全依赖后端接口监控是不行的,必须要梳理调用链路,搭建客户端业务监控。

作为全局业务监控只看单个用户的数据是没有什么意义的,需要将所有用户的数据采集、存储、可视化。
这里数据的采集我们使用饿了么MT部门提供的Skynet作为采集和上传通道,它具备编译期AOP插入、序列化存储、针对移动端优化的对齐上传等特性,保证了数据采集上传的可靠、稳定。
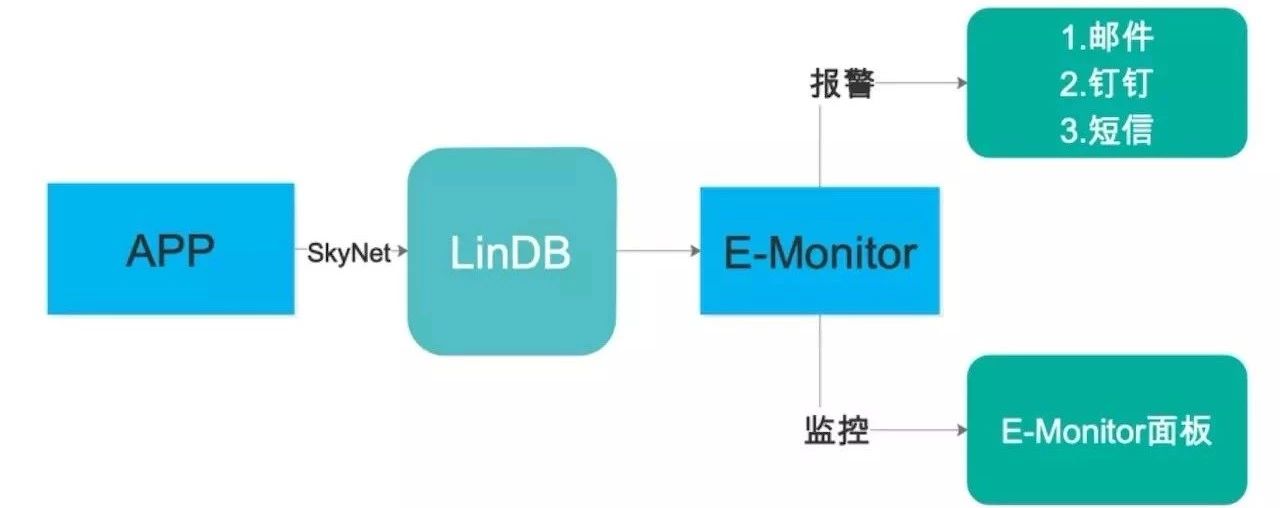
而在服务端的存储和可视化我们采用LinDB+E-Monitor的监控架构,LinDB是一款优秀的时间序列数据库,适合存储设备性能、日志等带时间戳的数据,能轻松处理高写入和高查询负载。
配合E-Monitor强大的可视化能力,可以完美展现骑手订单操作主流程的稳定情况、异常报警。
报警的策略如下图所示,移动端常用的是阈值模型和趋势模型配合同环比:

最终生成一个大盘的监控面板,这里因为铭感数据只放出了部分脱敏面板:
二、TimeBomb
TimeBomb,定时炸弹。从名字就可以猜到它和异常有关,它专门负责监控在规定时间和次数限定下没有达成用户交互结果的逻辑。
TimeBomb作为全局业务监控的补充,在排查异常中立下汗马功劳。它的设计初衷是通过简单的代码插入,由计数、时间间隔等条件触发异常事件上传,适用于:
登录多次登录不上
多次点击确认送达,都失败
定位一直报错
定位上传多次失败
任何接⼝口多次报错
等等...
总结来说,TimeBomb可以随意定义异常的监控力度,并且可以灵活的远端配置次数、时间、采样率。
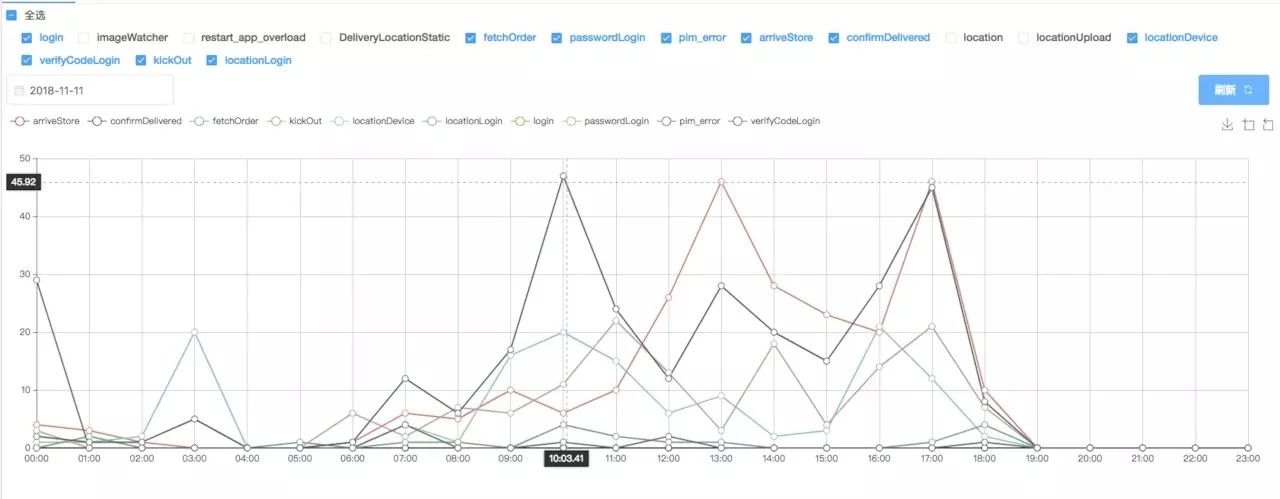
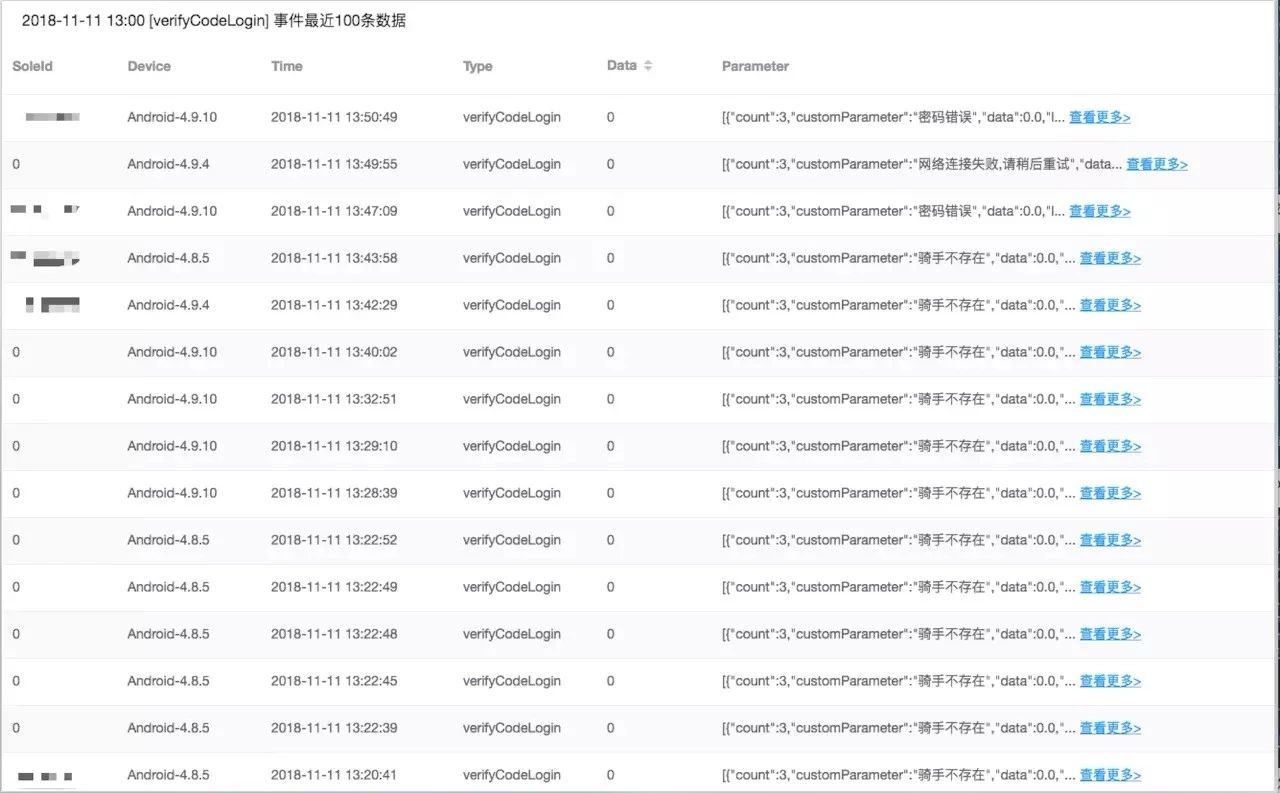
TimeBomb的数据采集和展示是通过我们自研的服务,主要包括两个功能:
根据选择的Tag和时间显示异常曲线;
选择节点之后就可以查看异常明细列表。在Parameter中查看异常上报的次数和时间配置还有上报的原因,点击日志拉取就可以拉取到用户的详细日志数据。
骑手App通过TimeBomb完成了很多异常问题的上报、修复、观测、优化、再观测,这是一个异常问题解决的正向循环,而且特别适合一些需要多轮验证的极端case的排查观测。
三、Dogger
Dogger包含两个部分:
Trojan日志写入上传SDK
Dogger-Service日志解析服务
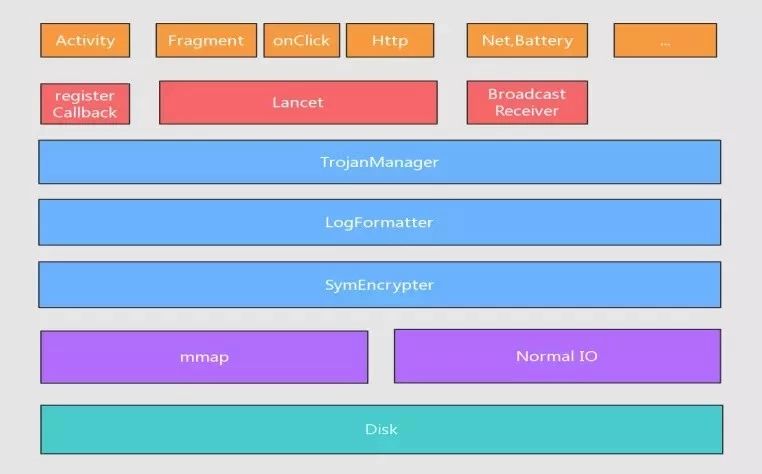
Trojan是一个面对高性能、极致体验要求下,产出的轻量级、高效率的移动端日志监控方案。
它就像一只听话的狗狗,在客户端默默的记录着用户的各项操作日志和技术性能埋点,最终在需要的时候,把日志抛上来,交给Dogger-Service解析。
通过完善的埋点,我们可以很快还原骑手的操作现场,借助对特定日志的横向分析,快速定位问题。
Trojan具备以下四个特点:
开发透明,使用者不需要关心日志文件的读写;
高效收集,采用AOP技术植入到埋点自动收集日志;实现高效的文件读写方式、毫秒级别的耗时;
敏感加密,对于用户相关的敏感信息,为保证日志的安全性,我们提供加密方式,比如说DES、AES;
流量开销低,日志写在本地,指定用户压缩上传。
Trojan的架构图:
Trojan用C的方式通过mmap(内存映射)的方案写入日志,对比java api的写入方式性能提高了一倍,低CPU、低内存消耗。
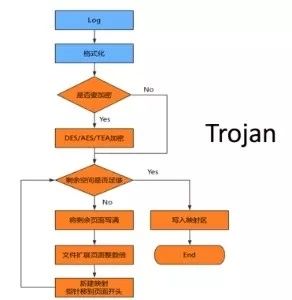
在性能监控这种大数据量写入的场景上满足了我们的需求,再配合文件的gzip压缩可以将日志这种多重复字母的文件达到50倍的压缩效果,实测一个43M的文件,压缩上传只要860kb。
1M以内的文件上传对移动端来说也是一个可以接受的大小,这也对未来trojan除了完成逻辑回放提供了可能。

经过三个版本的迭代,Trojan已经涵盖了用户的点击事件、页面生命周期、请求监控、流量、电量、内存、线程等方方面面。
文件的写入和上传都完成了,那一个几十M的文件该如何分析呢?下面就介绍一下我们的Trojan配套解析服务Dogger-Service。
Dogger-Service主要的功能分为三个部分:
ActionChart
全局展示骑手一天的页面跳转、电量、内存、网络切换、定位频率、特定请求频率等:
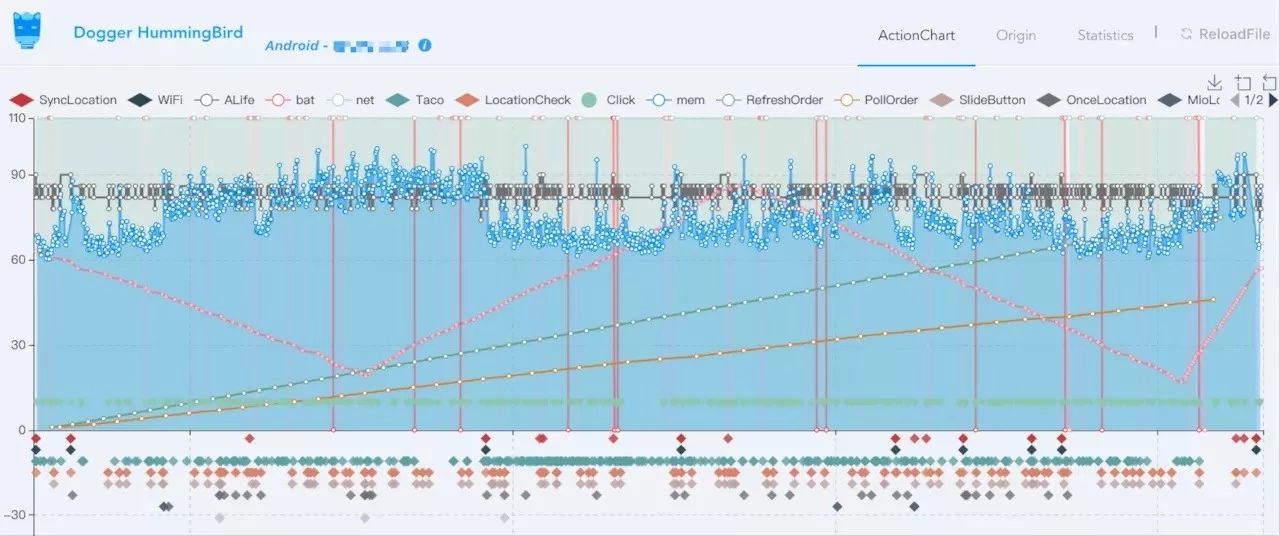
通过ActionChart我们可以直观的看出骑手在时空坐标系下的操作和资源使用情况,协助观察某个时间点出现某个问题的环境,这种全局掌控用户操作可能是行业内第一次达到。
Origin
可以轻松的完成百兆以内的文件解析和展示、按时间查找、全局高亮搜索等功能。
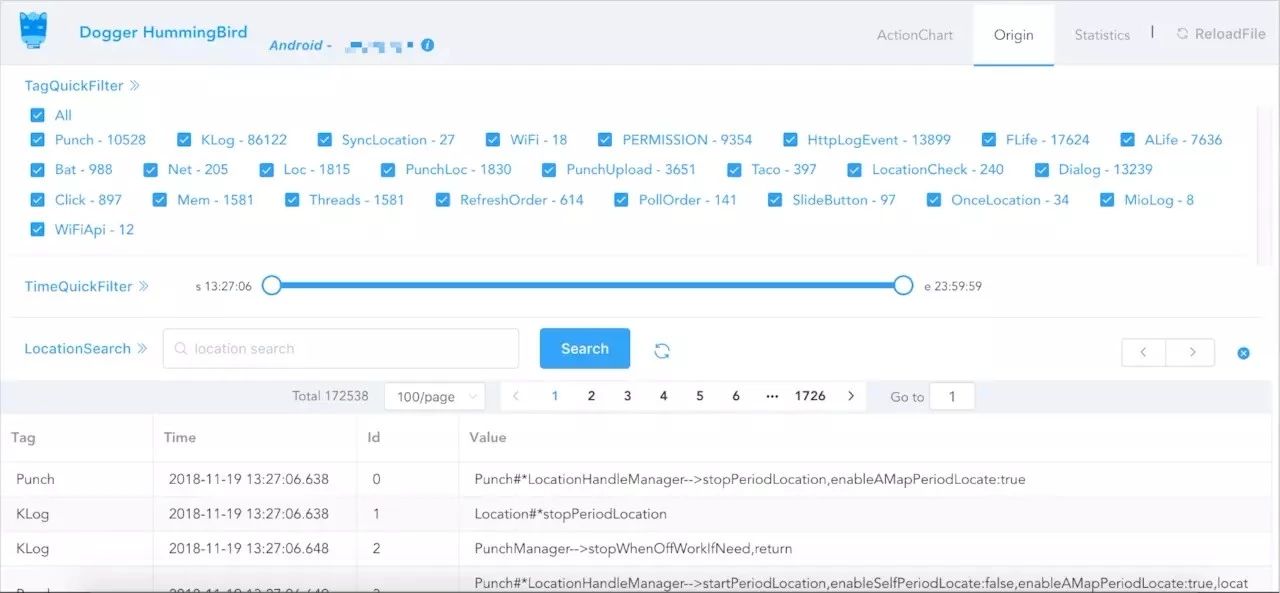
通过对原始数据解析,我们可以拖拽时间滑片,直接定位到某个时间段查看骑手的日志明细;也可以选择某个关注的Tag,或者直接通过关键字搜索高亮查找。
Origin模块让我们可以灵活的查找问题的蛛丝马迹,给定位问题的root cause提供了保障。
Statistics
统计模块是基于特定的Tag数据,数据挖掘分析和展示。当前实现了对电量,网络,流量,卡顿,请求,生命周期,内存,定位的数据分析。
比如下面的内存分析:

我们可以通过最长间隔,知道骑手有哪些时间段app是关闭着的,内存的峰值和低谷,平均内存各是多少,内存波动比较大的时间段是哪几个……波动大代表着资源开销可能异常,是需要仔细排查的点。
可以Loc Tag查看骑手的定位轨迹,分析是否有定位漂移或者定位失败情况。
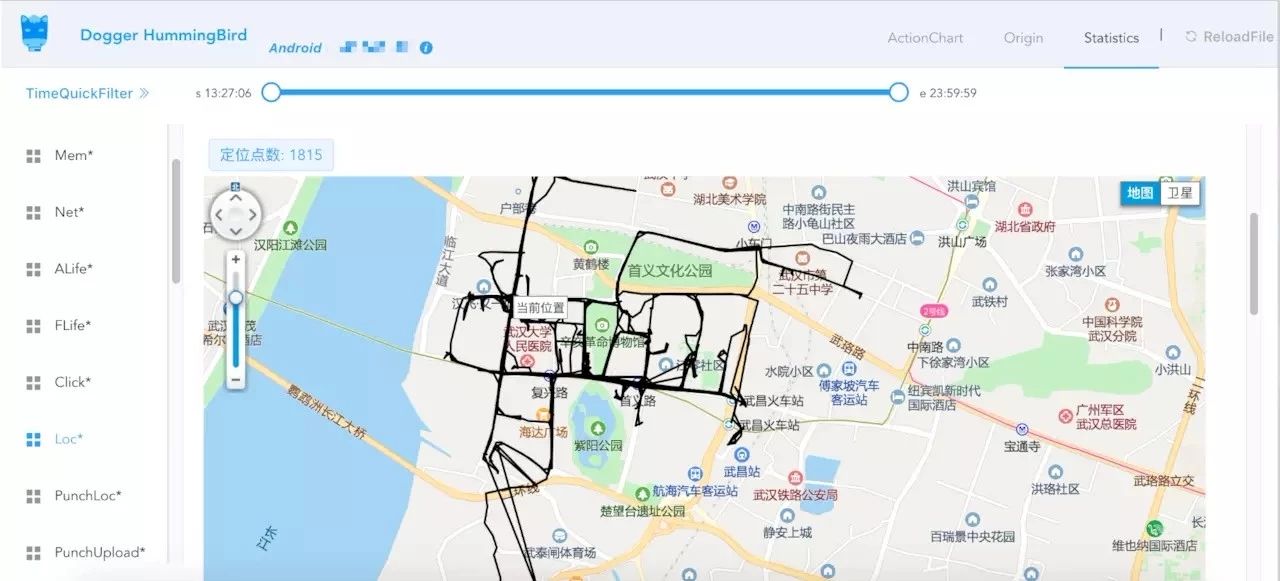
还可以通过PunchLoc Tag查看定位上传的失败占比,分析失败的原因是否和当时的网络状态有关。

通过THttpReq可以查看网络请求的Host和Path占比情况,方便优化请求流量。

Trojan和Dogger-Service组成了Dogger这个有机的整体,日志和解析配合,可以让我们在排查单个case的时候,对用户的行为了如指掌,丰富的埋点数据可以为我们的排查提供数据支撑。
目前Dogger服务中的日志写入sdk Trojan已经开源,欢迎交流学习。
参考链接:
https://github.com/eleme/Trojan
我们有了实时的全局大盘和异常监控,还有单个用户的全周期日志数据,这样就够了吗?
大盘的曲线正常,异常的毛刺消除只能代表业务大盘稳定,但是业务功能真实的质量还不能一概而论,这时我们需要对数据漏斗的终点——离线数据池进行大数据挖掘分析来做最后的监控兜底。
四、EDW
下面介绍一下最后一层监控EDW。
离线报表监控作为全局大盘的另一种视角,E-Monitor属于实时大盘监控,只能观察实时曲线趋势和昨天做对比,判断粗粒度的业务是否异常。
但是离线数据可以挖掘分析完整一天的数据,细粒度的判断每一个订单的健康程度,聚合定位失败的原因占比,获取复杂条件筛选出的各种比例,让我们从上帝视角观察整个业务线,评估线上业务健康度,分析趋势,表征产出,是移动端监控体系中不可或缺的利器。
公司大数据平台部自研的EDW为我们提供了优质的离线大数据服务,它融合了即时查询、数据抽取、数据计算、数据推送、元数据管理、数据监控等多种数据服务的平台型产品。
当前我们在流量、定位质量、骑手多设备使用、离线送达、推送质量、订单异常等关键业务场景都有完备的离线报表。
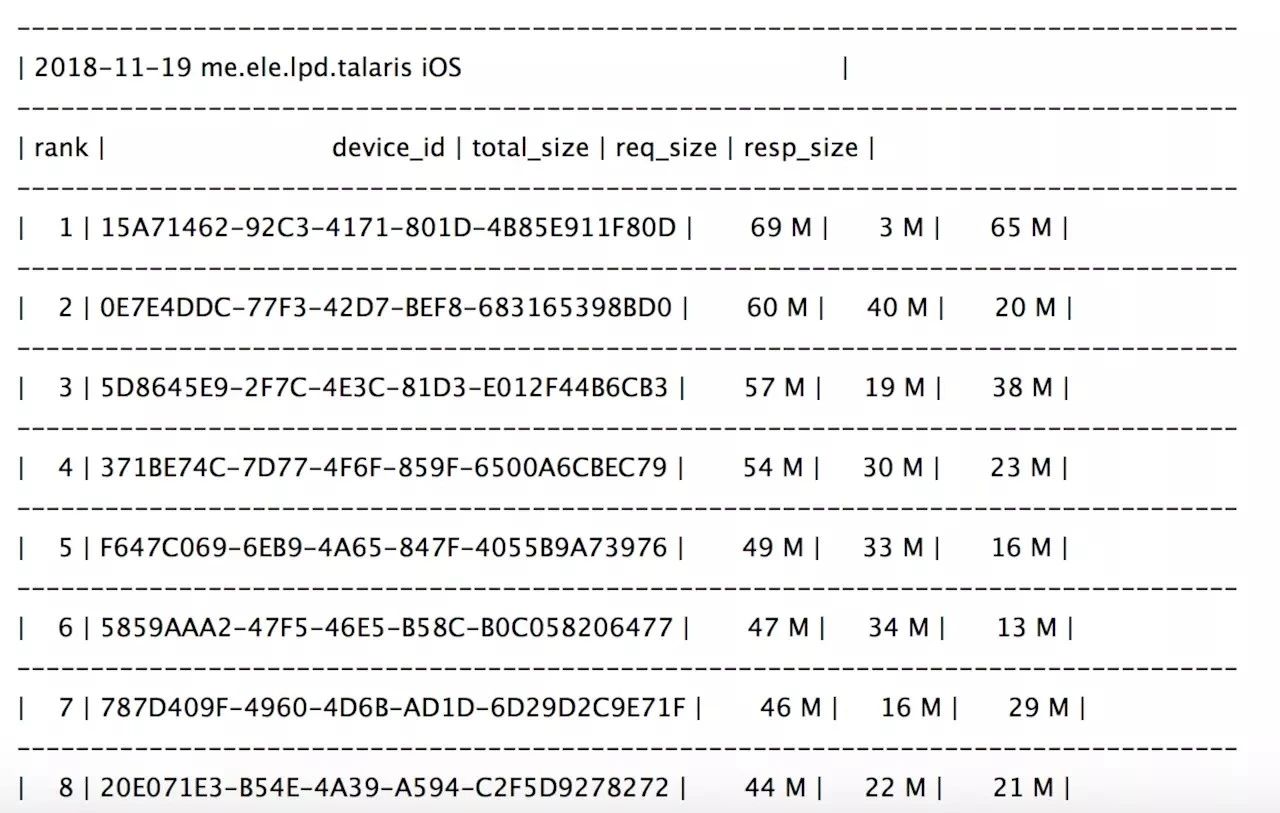
比如下图的流量报表,可以知晓线上流量消耗Top 100的骑手device_id 和流量数据,而排行第一的骑手response数据远大于request数据,通过Dogger拉日志后发现,骑手有多次下载app的行为:
而这幅图则是线上主流程的偏向业务的流转时长监控,因为数据敏感所以打码了:

这些报表可以说明线上业务的真实健康度,这一点能够让我们对全局的把控更有自信。基于离线数据的聚合分析,可以发现优化点,为改善方案提供依据。
五、实战
这里记录一下最近发生的一次网络层问题的排查过程,让大家直观感受这几层监控的作用。
Step : 1
我们的gafana的监控发现Android骑手的订单相关请求平均成功率降低到了98.69%,而正常请求成功率应该在99%以上。

上面说到grafana属于可用性全局监控,如果这边的数据异常,将会影响全盘,所以我们不敢怠慢,立马着手排查。
首先我们怀疑是DNS解析问题,我们通过EDW拉取了出现问题骑手的id,然后配置了Dogger的骑手日志拉取,经过分析发现,DNS失败的场景多发生在断网等弱网环境,属于正常情况。
而且我们发现日志上出问题的请求的requestID在后端的trace系统上都查不到,查看了skynet网络监控拦截器的代码:
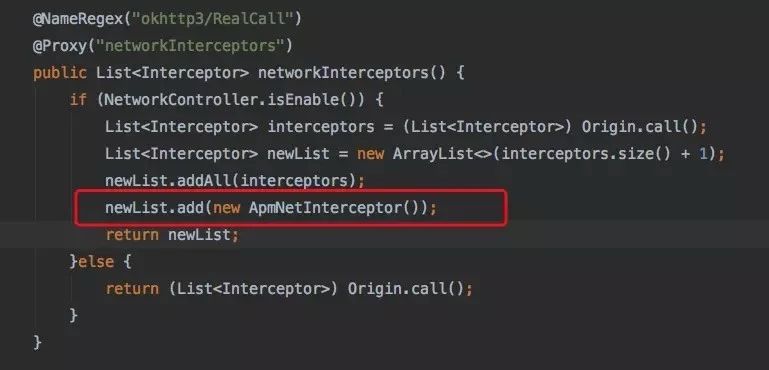
apmNetInterceptor插在最后一个,数据没有传上去,说明请求在发送前就已经抛了错,所以我们开始排查请求发送前的逻辑。
Step : 2
通过EDW抽取出现问题骑手,对他们的请求失败原因聚合,得到了ioException异常占比最大。
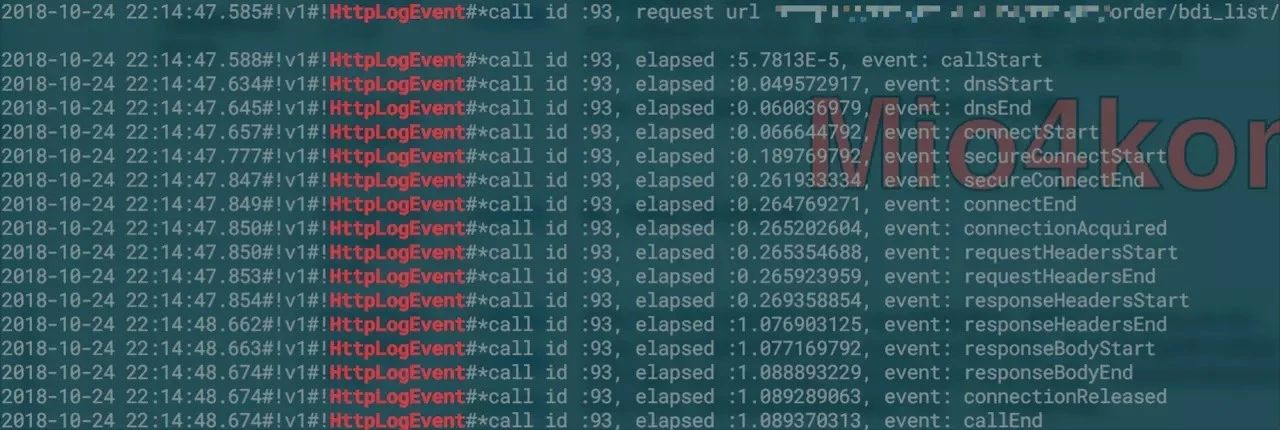
Step : 3
由于请求前的日志数据过少,所以我们升级了okhttp到3.11,使用EventListener来获取请求生命周期埋点,针对上报问题的骑手发了内测版本,希望获得出问题请求的链路明细。
完整的链路大致如下:
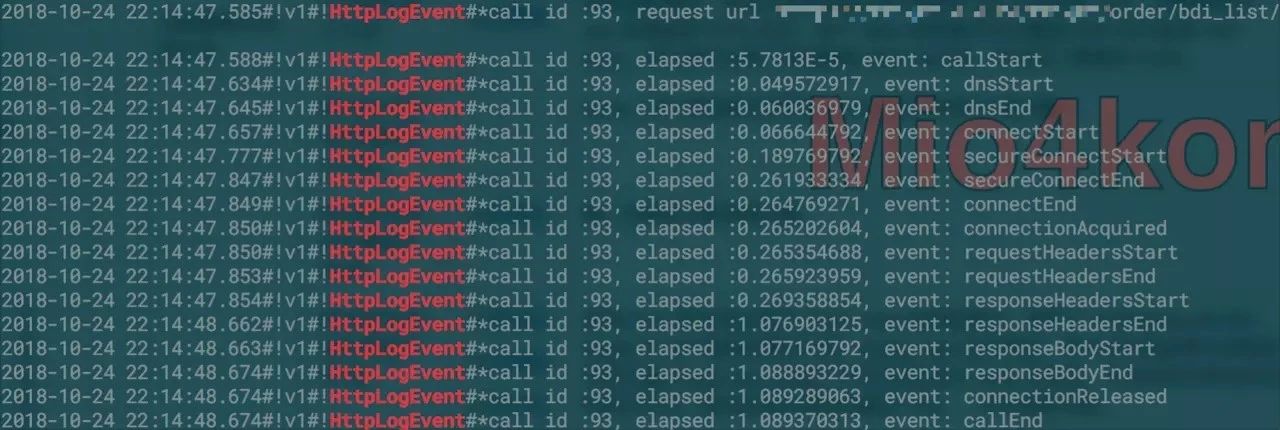
再次捞出有问题骑手的日志,发现有些时候网络状态是良好的,但是在responseHeaderStart之后会直接抛错或者是timeout:
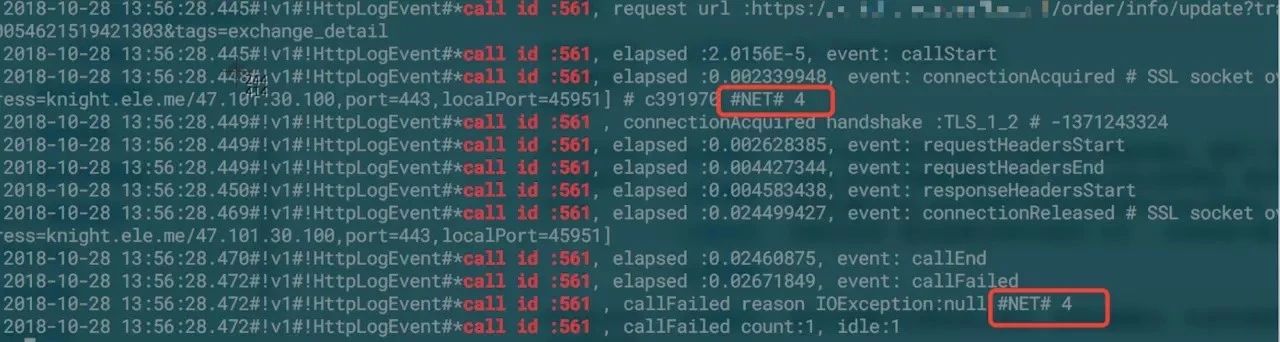
于是我们撸了多遍okhttp的源码,觉得应该是连接池复用的问题,复用了已经失效的连接。我们又加入IOException的stacktrace日志,发现一个奇怪的问题:

线上的请求走的竟然是http/2的协议,仔细阅读Okhttp握手相关的代码发现,Okhttp在https的情况下会判断服务端是否支持http/2,如果支持则会走http/2的协议,相关代码参见RealConnection.java的establishProtocol方法。
private void establishProtocol(ConnectionSpecSelector connectionSpecSelector,
int pingIntervalMillis, Call call, EventListener eventListener) throws IOException {
if (route.address().sslSocketFactory() == null) {
if (route.address().protocols().contains(Protocol.H2_PRIOR_KNOWLEDGE)) {
socket = rawSocket;
protocol = Protocol.H2_PRIOR_KNOWLEDGE;
startHttp2(pingIntervalMillis);
return;
}
socket = rawSocket;
protocol = Protocol.HTTP_1_1;
return;
}
eventListener.secureConnectStart(call);
connectTls(connectionSpecSelector);
eventListener.secureConnectEnd(call, handshake);
if (protocol == Protocol.HTTP_2) {
startHttp2(pingIntervalMillis);
}
}
复制代码最终发现的确是Okhttp在http/2上对连接池的复用问题存在bug,在StreamAllocation.java上:
public void streamFailed(IOException e) {
boolean noNewStreams = false;
synchronized (connectionPool) {
if (e instanceof StreamResetException) {
} else if (connection != null
&& (!connection.isMultiplexed() || e instanceof ConnectionShutdownException)) {
noNewStreams = true;
}
socket = deallocate(noNewStreams, false, true);
}
}
复制代码当协议是http/2的时候,noNewStreams为false,而在ConnectionPool.java的connectionBecameIdle就不会将这个connection从ConnectionPool中移除:
boolean connectionBecameIdle(RealConnection connection) {
if (connection.noNewStreams || maxIdleConnections == 0) {
connections.remove(connection);
return true;
} else {
}
}
复制代码结合前段时间,后端将路由层切换了公司的SoPush服务上,而SoPush是支持Http/2的,切换的时间和曲线异常时间吻合,可以确定问题就在这里。
线上使用的Okhttp版本还是3.8.4,在Okhttp 3.10.0版本之后,加入了对http2的连接池中的连接做了严格的ping验证,下面是changelog:

可以看到http/2才刚加Ping机制,所以OKhttp对Http/2支持有问题的版本是<3.10,但是即使使用了3.11的最新版本依旧有一定概率发生这个问题。
于是我们觉得先强制指定Android版本的协议为http/1.1,后面接入集团的网络库再支持Http/2。修改完再次发布内测版本,曲线恢复正常,问题解决。
这次网络层的排查,我们使用E-Monitor监控和分析问题严重程度,EDW离线数据过滤出问题骑手ID,Dogger单点日志灵活埋点验证修复方案,就这样,一次由第三方变动引起的客户端可用性异常解决了。业务可用性监控功不可没。
六、总结
以上就是饿了么物流移动当前在业务可用性监控领域做出的一些探索。
我们按照数据漏斗,从全量埋点、异常监控、单用户日志、离线数据,由面到点再到面,每一个切面都插入了不同纬度的监控,希望能做到全面覆盖业务,稳定性和质量兼顾。
因为我们深信,只有做好监控,才能做到可报警、可排查、可优化。
但是移动端可用性监控是一个长期建设的工程,需要不断的优化迭代,当前我们也面临数据冗余和性能监控冲突,监控本身带来的性能损耗等问题,未来我们也将在这些问题上做进一步探索、实践和分享。
作者:饿了么物流技术团队
来源:https://juejin.im/post/5c3577e0f265da616c65ca80
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721