
截止目前,用户数突破2.2亿,有超过3000万的问题被提出,并获得超过1.3亿个回答。同时,知乎内还沉淀了数量众多的优质文章、电子书以及其它付费内容。
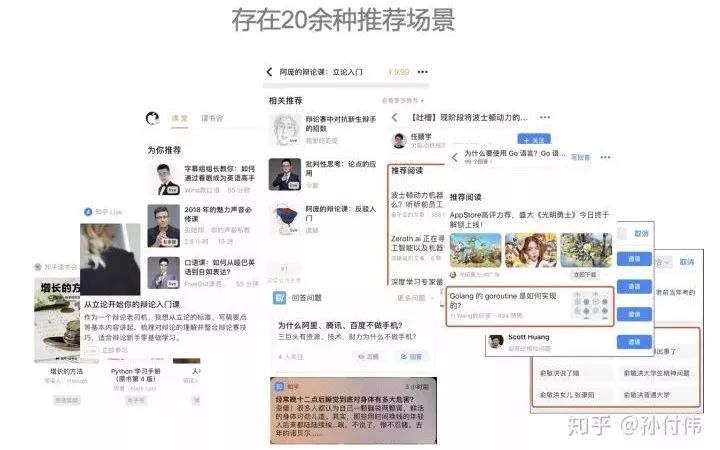
因此,在链接人与知识的路径中,知乎存在着大量的推荐场景。粗略统计,目前除了首页推荐之外,我们已存在着20多种推荐场景;并且在业务快速发展中,不断有新的推荐业务需求加入。
在这个背景之下,构建一个较通用的且便于业务接入的推荐系统就变成不得不做的事了。
在讲通用架构的设计之前,我们一起回顾一下推荐系统的总体流程和架构:
通常,因为模型所需特征及排序的性能考虑,我们通常将简单的推荐系统分为召回层和ranking层,召回层主要负责从候选集合中粗排选择待排序集合,之后获取ranking特征,经过排序模型,挑选出推荐结果给用户。
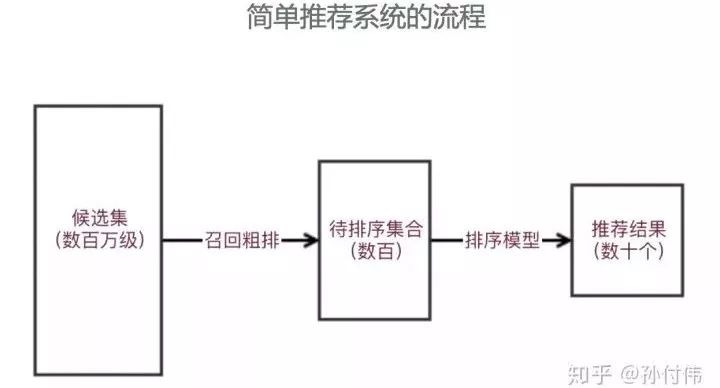
简单推荐模型适合一些推荐结果要求单一,只对单目标负责的推荐场景,比如新闻详情页推荐、文章推荐等等。
但在现实中,作为通用的推荐系统来说,其需要考虑用户的多维度需求,比如用户的多样性需求、时效性需求、结果的满足性需求等。
因此就需要在推荐过程中采用多个不同队列,针对不同需求进行排序,之后通过多队列融合策略,从而满足用户不同的需求。

从我们知乎来说,也大体是这样一个发展路线,比如今年的7月份时,因为一些业务快速发展且架构上相对独立的历史原因,我们的推荐系统存在多套,并且架构相对简单。
以其中一个推荐架构设计相对完善的系统为例,其总体架构是这样的。可以看出,这个架构已经包含了召回层和ranking层,并且还考虑了二次排序。
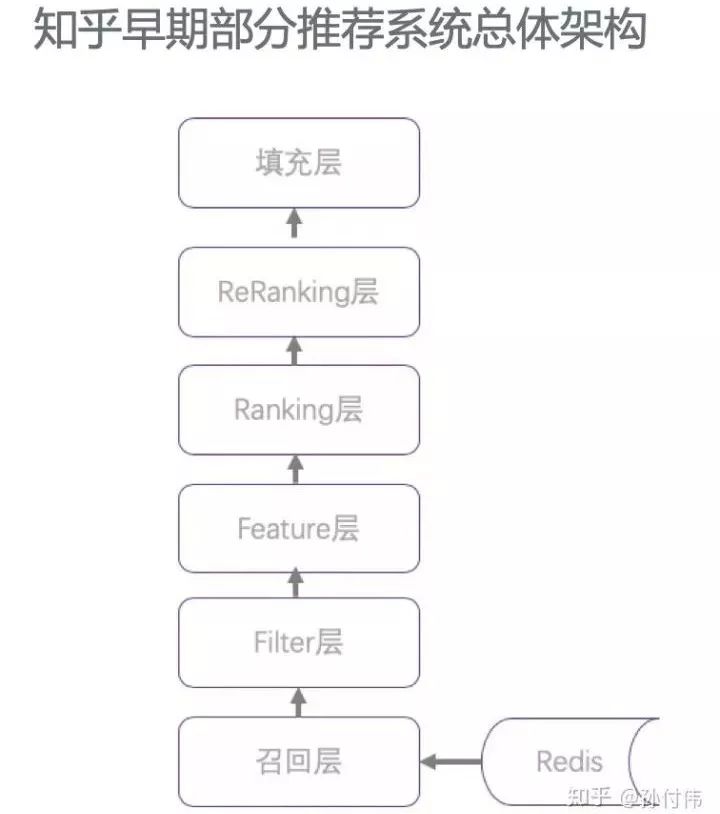
那么存在哪些问题呢?
首先,对多路召回支持不友好。现有架构的召回是耦合在一起的,因此开发调研成本高,多路召回接入相对困难。
然后,召回阶段只使用Redis作为召回基础。Redis有很多优点,比如查询效率高,服务较稳定。但将其作为所有召回层的基础,就放大了其缺点,第一不支持稍复杂的召回逻辑,第二无法进行大量结果的召回计算,第三不支持embedding的召回。
第三点,总体架构在实现时,架构逻辑剥离不够干净,使得架构抽样逻辑较弱,各种通用特征和通用监控建设都较困难。
第四点,我们知道,在推荐系统中,特征日志的建设是非常重要的一个环节,它是推荐效果好坏的重要基础之一。但现有推荐系统框架中,特征日志建设缺乏统一的校验和落地方案,各业务『各显神通』。
第五点,当前系统是不支持多队列融合的,这就严重限制了通用架构的可扩展性和易用性。
因此,我们就准备重构知乎的通用推荐服务框架。
一、重构之路
语言的选择
早期知乎大量的服务都是基于Python开发的,但在实践过程中发现Python资源消耗过大、不利于多人协同开发等各种问题。
之后公司进行了大规模的重构,现在知乎在语言层面的技术选型上比较开放,目前公司内部已有Python、Scala、Java、Golang等多种开发语言项目。
那么对于推荐系统服务来说,由于其重计算,多并发的特点,语言的选择还是需要考虑的。
架构上的考虑
要解决支持多队列混排和支持多路召回的问题,并且其设计最好是支持可插拔的。
召回层上
除了传统的Redis的KV召回(部分CF召回,热门召回等等应用场景),我们还需要考虑一些其他索引数据库,以便支持更多索引类型。
首先我们先看语言上的选择,先总体上比较一下各种语言的特点,我们简单从如下几个方面进行比较。
从性能上,依照公开的benchmark,Golang和Java、Scala大概在一个量级,是Python的30倍左右。
其次Golang的编译速度较快,这点相对于java、scala具有比较明显的优势。
再次其语言特性决定了Golang的开发效率较高,此外因为缺乏trycatch机制,使得使用Golang开发时对异常处理思考较多,因此其上线之后维护成本相对较低。
但Golang有个明显缺陷就是目前第三方库较少,特别跟AI相关的库。

那么基于以上优缺点,我们重构为什么选择Golang?
Golang天然的优势,支持高并发并且占用资源相对较少。这个优势恰恰是推荐系统所需要的,推荐系统存在大量需要高并发的场景,比如多路召回,特征计算等等。
知乎内部基础组件的Golang版生态比较完善。目前我们知乎内部对于Golang的使用越来越积极,大量基础组件都已经Golang化,包括基础监控组件等等,这也是我们选择Golang的重要原因。
但我需要强调一点,语言的选择不是只有唯一答案的,这是跟公司技术和业务场景结合的选择。
讲完语言上的选择,那么为了在重构时支持多队列混排和支持多路召回,我们架构上是如何来解决的?
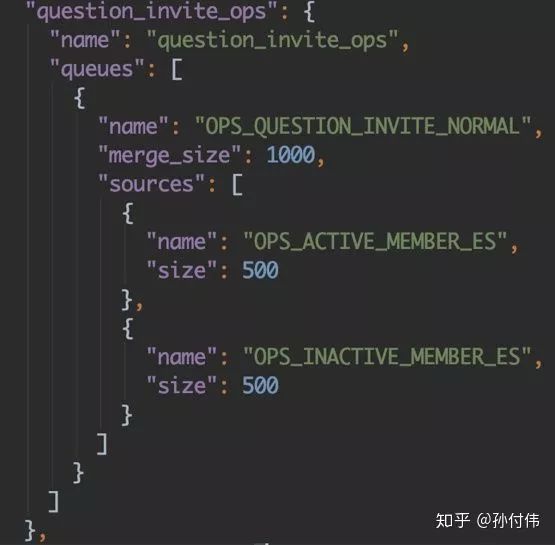
这点在设计模式比较常见,就是『抽象工厂模式』:首先我们构建队列注册管理器,将回调注册一个map中,并将当前服务所有队列做成json配置的可自由插拔的模式,比如如下配置,指定一个服务所需要的全部队列,存入queues字段中:
通过name来从注册管理器的map中调取相应的队列服务:

之后呢我们就可以并发进行多队列的处理:

对于多路召回,及整个推荐具体流程的可插拔,与上面处理手法类似,比如如下队列:
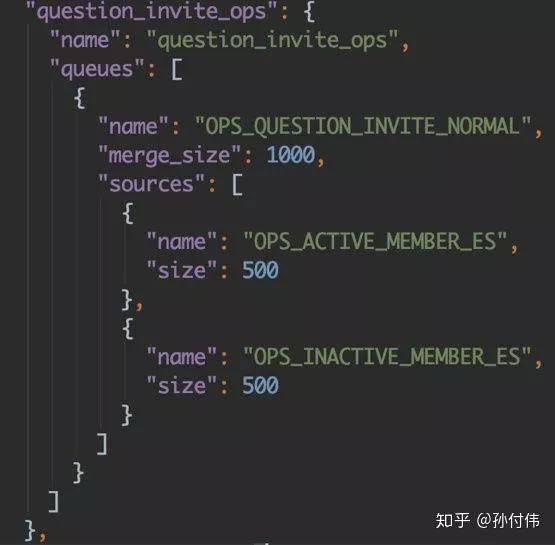
我们可以指定所需召回源,指定merger策略等等,当某个过程不需处理,会按自动默认步骤处理,这样在具体queue的实现中就可以通过如下简单操作进行自由配置:

我们讲完了架构上一些思考点和具体架构实现方案,下面就是关于召回层具体技术选型问题。
我们先回顾一下,在常用的推荐召回源中,有基于topic(tag)的召回、实体的召回、地域的召回、CF(协同过滤)的召回以及NN产生的embedding召回等等。
那么为了能够支持这些召回,技术上我们应该如何来实现呢?
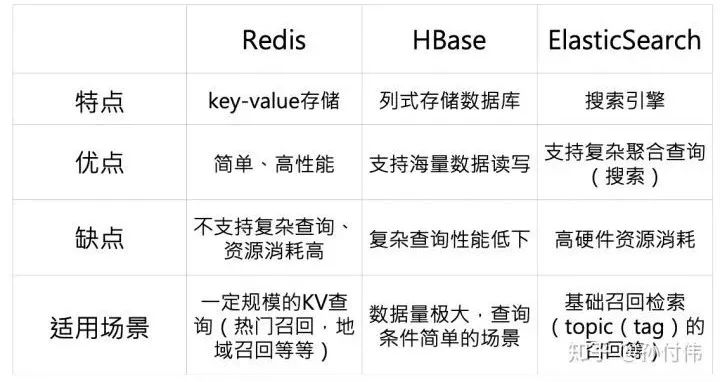
我们先从使用角度看一下常用的NoSQL数据库产品:
Redis是典型的k-v存储,其简单、并且高性能使得其在业内得到大量使用,但不支持复杂查询的问题也让Redis在召回复杂场景下并不占优,因此一般主要适用于kv类的召回,比如热门召回,地域召回,少量的CF召回等等。
而HBase作为海量数据的列式存储数据库,有一个明显缺点就是复杂查询性能差,因此一般适合数据查询量大,但查询简单的场景,比如推荐系统当中的已读已推等等场景。
而ES其实已经不算是一个数据库了,而是一个通用搜索引擎范畴,其最大优点就是支持复杂聚合查询,因此将其用户通用基础检索,是一个相对适合的选择。
我们上面介绍了通用召回的技术选型,那么embedding召回如何来处理呢?
我们的方案是基于Facebook开源的faiss封装,构建一个通用ANN(近似最近邻)检索服务。
faiss是为稠密向量提供高效相似度搜索和聚类的框架。其具有如下特性:
提供了多种embedding召回方法;
检索速度快,我们基于python接口封装,影响时间在几ms-20ms之间;
c++实现,并且提供了Python的封装调用;
大部分算法支持GPU实现。
从以上介绍可以看出,在通用的推荐场景中,我们召回层大体是基于ES+Redis+ANN的模式进行构建。
ES主要支持相对复杂的召回逻辑,比如基于多种topic的混合召回;
Redis主要用于支持热门召回,以及规模相对较小的CF召回等;
ANN主要支持embedding召回,包括NN产出的embedding、CF训练产出的embedding等等。
介绍完以上思考点,我们总体的架构就基本成型了,具体如下图所示:
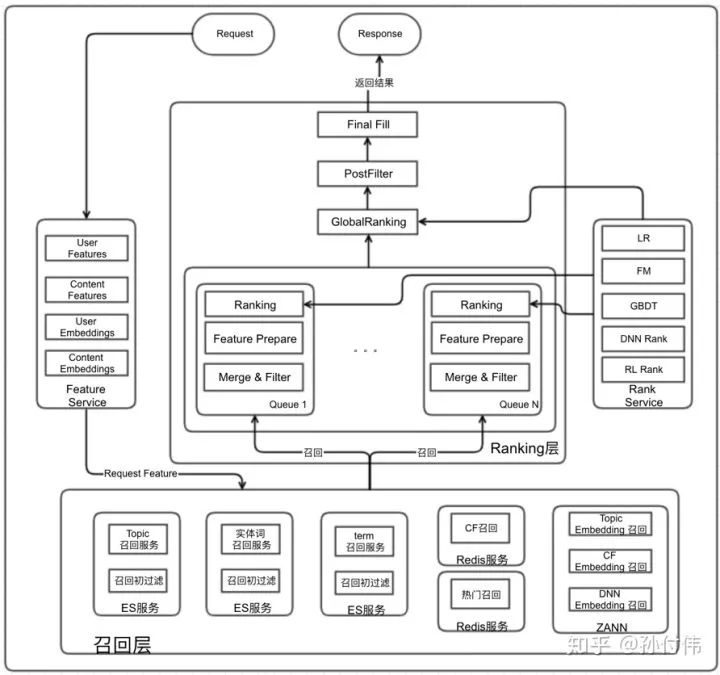
该框架可以支持多队列融合,并且每个队列也支持多路召回,从而对于不同推荐场景能够较好的支持。另外,我们召回选择了ES+Redis+ANN的技术栈方案,可以较好支持多种不同类型召回,并达到服务线上的最终目的。
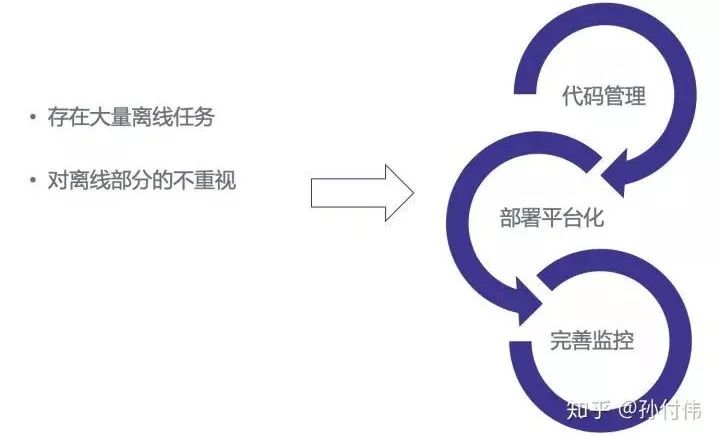
1)离线任务和模型的管理问题
我们做在线服务的都有体会,我们经常容易对线上业务逻辑代码更关注一些,而往往忽视离线代码任务的管理和维护。但离线代码任务和模型在推荐场景中又至关重要。因此如何有效维护离线代码和任务是我们面临的第一个问题。
2)特征日志问题
在推荐系统中,我们常常会遇到特征拼接和特征的『时间穿越』的问题。所谓特征时间穿越,指的是模型训练时用到了预测时无法获取的『未来信息』,这主要是训练label和特征拼接时时间上不够严谨导致。如何构建便捷通用的特征日志,减少特征拼接错误和特征穿越,是我们面临的第二个问题。
3)服务监控问题
一个通用的推荐系统应该在基础监控上做到尽可能通用可复用,减少具体业务对于监控的开发量,并方便业务定位问题。
具体如下:
针对离线任务和模型的管理问题:
在包括推荐系统的算法方向中,需要构建大量离线任务支持各种数据计算业务,和模型的定时训练工作。但实际工作中,我们往往忽略离线任务代码管理的重要性,当时间一长,各种数据和特征的质量往往无法保证。
为了尽可能解决这样的问题,我们从三方面来做:
第一,将通用推荐系统依赖的离线任务的代码统一到一处管理;
第二,结合公司离线任务管理平台,将所有任务以通用包的形式进行管理,这样保证所有任务的都是依赖最新包;
第三,建设任务结果的监控体系,将离线任务的产出完整监控起来。
针对特征日志问题:
Andrew Ng之前说过:『挖掘特征是困难、费时且需要专业知识的事,应用机器学习其实基本上是在做特征工程。』
我们理想中的推荐系统模型应该是有干净的Raw Data,方便处理成可学习的Dataset,通过某种算法学习Model,来达到预测效果不断优化的目的。
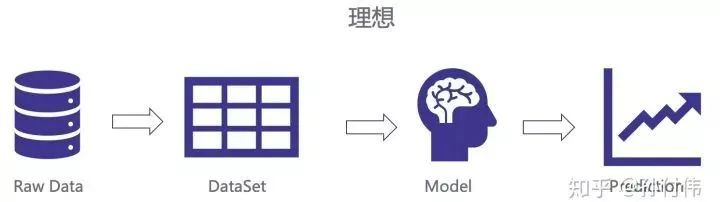
但现实中,我们需要处理各种各样的数据源,有数据库的,有日志的,有离线的,有在线的。这么多来源的Raw Data,不可避免的会遇到各种各样的问题,比如特征拼接错误,特征『时间穿越』等等。

这里边反应的一个本质问题是特征处理流程的规范性问题。那么我们是如何来解决这一点呢?
首先,我们用在线代替了离线,通过在线落特征日志,而不是RawData,并统一了特征日志Proto,如此就可以统一特征解析脚本。
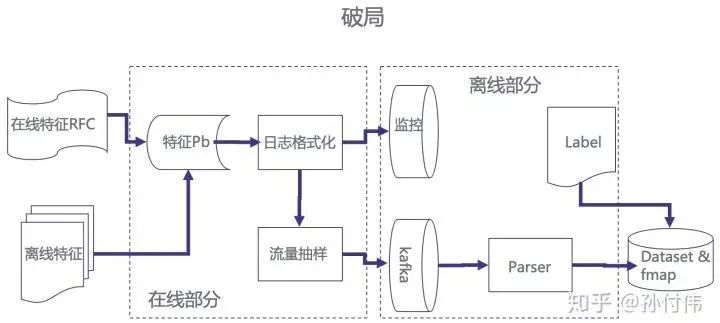
针对服务监控问题:
在监控问题上,知乎搭建了基于StatsD+Grafana +InfluxDB的监控系统,以支持各种监控日志的收集存储及展示。基于这套系统,我们可以便捷的构建自己微服务的各种监控。

我们这里不过多介绍通用监控系统,主要介绍下,基于推荐系统我们监控建设的做法。
首先先回顾一下我们推荐系统的通用设计:我们采用了『可插拔』的多队列和多召回的设计,那么可以在通用架构设计获取到各种信息,比如业务线名,业务名,队列名,process名等等。
如此,我们就可以将监控使用如下方式实现,这样就可以通用化的设计监控,而不需各个推荐业务再过多设计监控及相关报警。

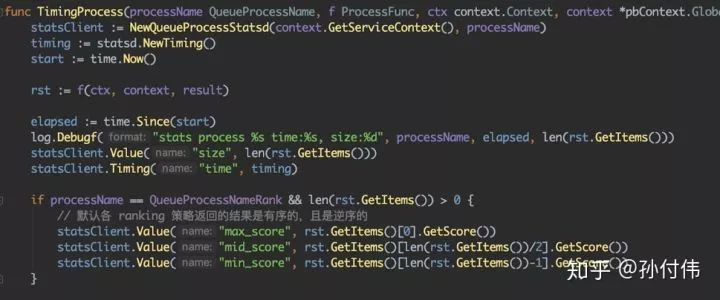
按照如上实现之后,我们推荐系统的监控体系大概是什么样子,首先各个业务可以通过grafana展示页面进行设置。我们可以看到各个flow的各种数据,以及召回源的比例关系,还有特征分布,ranking得分分布等等。

二、未来挑战
讲完了遇到的一些问题之后,我们来看一下未来的挑战。
随着业务的快速发展,数据和规模还在不断扩张,架构上还需要不断迭代;
随着推荐业务越来越多,策略的通用性和业务之间的隔离如何协调一致;
资源调度和性能开销也需要不断优化;
最后,多机房之间数据如何保持同步也是需要考虑的问题。
三、总结
最后,我们做个简单总结。
第一点,重构语言的选择,关键跟公司技术背景和业务场景结合起来;
第二点,架构尽量灵活,并不断自我迭代;
第三点,监控要早点开展,并尽可能底层化、通用化。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721