
一、背景
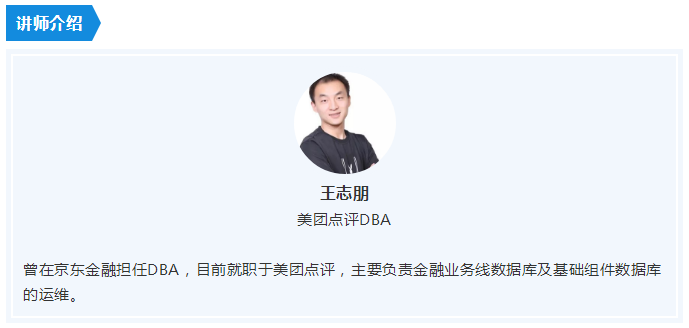
以MHA作为切换工具,CMDB管理元数据,结合中间件的高可用方案在MySQL生态中是比较常见的架构。在这个体系中,CMDB作为基础组件之一,不能再依赖这个架构实现自身的高可用,而需要一套自成体系的高可用架构保障。
2017年下半年开始,美团点评数据库计划全面升级上线5.7版本,也正是这个契机,基于MGR的CMDB高可用想法应运而生。
二、关于MGR
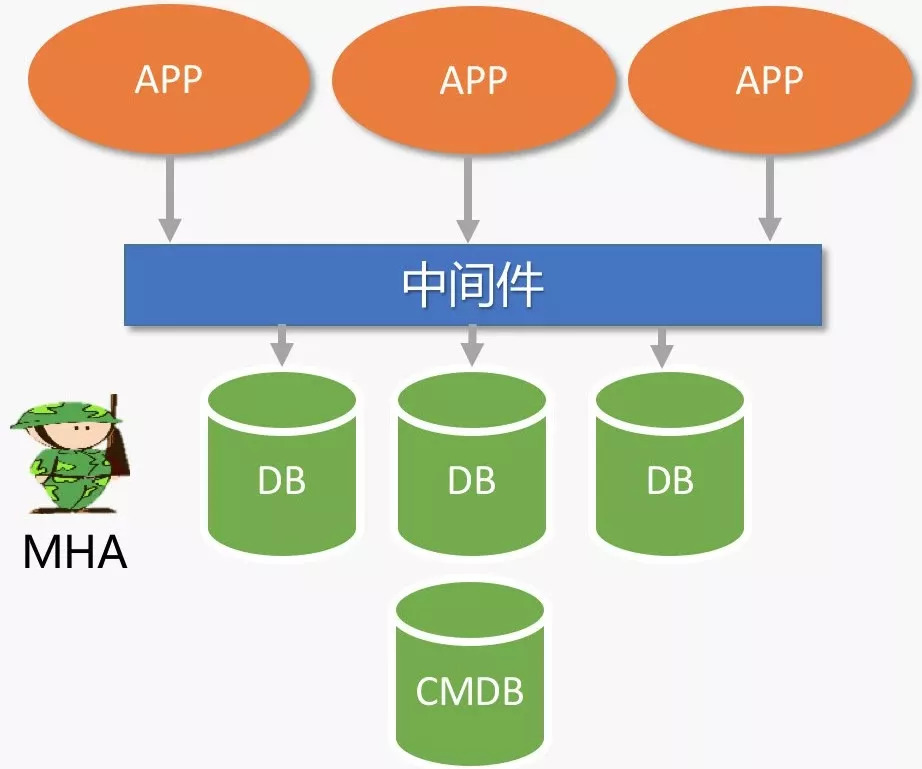
MGR是以Plugin的形式嵌入在MySQL实例中,插件内部实现了冲突检测、Paxos协议通信等。
可能有同学了解它与PXC很像,社区中关于二者的口水战也非常的热闹,具体二者的优劣与争端此处不表,但有一点值得说明,MGR集群当中,仍然是通过binlog实现节点同步的。这一点对DBA很友好,意味着我们可以很轻易的找回熟悉的主从的感觉(Still A MySQL)。

三、解决方案
MGR包括多主与单主两个模式,出于多主模式的一些已知问题以及实际业务场景的考虑,我们决定选择单主模式作为主要方案,即当主节点故障后,集群自动选举新的主节点,应用将写访问指向新的主节点。

那么具体的解决方案还有哪些需要考虑呢?
MGR的限制;
相关测试;
合理的参数。
只支持InnoDB存储引擎;
必须有主键;
binlog_format只支持ROW格式;
不支持save point(后修复);
……
官方给出了一些明确的要求及限制。针对这些限制我们要对线上要接入的数据库进行排查,调研可行性,规范其满足MGR的要求。包括收敛MyISAM存储引擎的表、无主键的表,应用逻辑中去除save point(新版本去掉此限制)等。
此外我们生产关心的问题,如网络抖动对MGR的影响、备份恢复工具可用性、Online-DDL可用性等,同样需要考虑在内。对此我们做了系统性的功能测试:

同时在测试中也对MGR的行为有了一些新的认识,比如MyISAM引擎、无主键的表等MGR明确不支持的场景,都是以一种“乐观”的方式处理,即允许你创建、Alter,但不允许写入数据。
同时在上面提到的测试中,我们也遇到了几个重要参数不同值的不同行为。比如group_replication_unreachable_majority_timeout这个参数,它真正的含义是MGR节点由ONLINE状态进入UNREACHABLE状态后(一般是由于网络抖动、节点异常等引起),等待相应的时间,如果仍保持UNREACHABLE,则将节点置为ERROR状态,即这个参数是UNREACHABLE状态的一个timeout,单位秒。
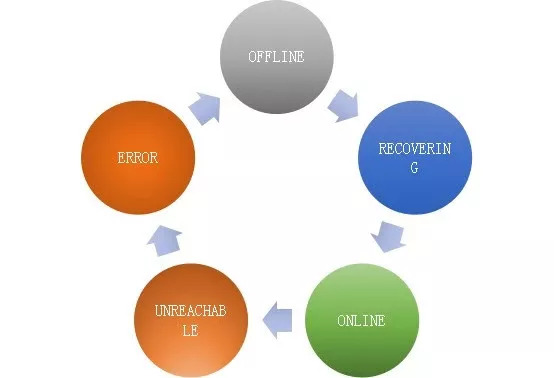
(MGR节点的几个状态)
该参数默认值为0,含义是无timeout,即无限等待,这在实际的生产环境中,如发生网络的异常,是个不可接受结果。
以下是我们根据官方的文档,以及实践过程中的一些问题,总结的参数,可作为一个参考:

最后我落实了三机房三节点MGR集群,作为高可用方案主体,同时向下扩展了一套主从集群,作为不可挽回问题的灾备。毕竟MGR作为新生儿,可靠性还有待验证,相信不远的将来我们也有足够的信心放弃回滚到主从的方案。

四、上线历程
美团点评从2018年以来,总共将三个系统迁移上线了MGR,包括流程系统、报表系统以及CMDB。

五、典型问题
在几个集群上线的过程中,我们也积累了一些问题,其中典型的几个在这里简单回顾一下:
在报表系统上线后,集群出现了一点诡异的状况:在某些时间点,节点不定时会出现UNREACHABLE的状态,严重时直接导致集群选主切换,而在此期间,机房机器网络并没有什么异常。

这个问题最初困扰了我们一段时间,通过对之前流程系统的对比,我们发现两个集群网卡的流量大小有些区别,且报表系统有比较明显的尖刺:
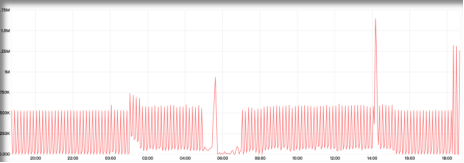
从这个分析角度出发,我们查阅文档,发现有参数可以做相关的优化,即group_replication_compression_threshold,含义是事务超过相应大小则在传输前进行压缩处理。下图为参数调整后的对比,由1.5M减少到15K。实际场景中异常状态发生次数确实减少了,但没有根除。
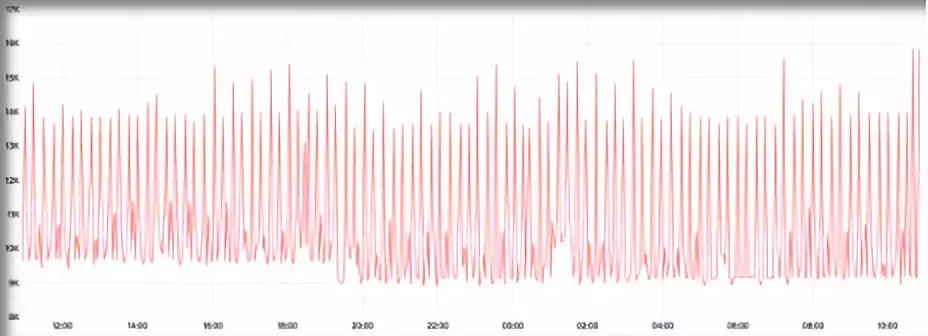
顺着这个思路我们做了一些测试,定位到了根本问题:大事务。
需要说明的是MGR的大事务有自己的“定义”,它的大事务与网络的传输时间有关,这就解释了为什么我们开启压缩后,节点异常状态次数减少的问题。最后我们通过限制事务的大小的方式,彻底解决了这个问题,同时也在业务逻辑上优化了大事务。以下是两个相关的参数:

第二个问题发生在一次节点下线演练的过程中,DBA开始演练操作后,开发同学突然反馈说后台Nginx由于请求积压,机器挂掉了。如下图Nginx可用率:
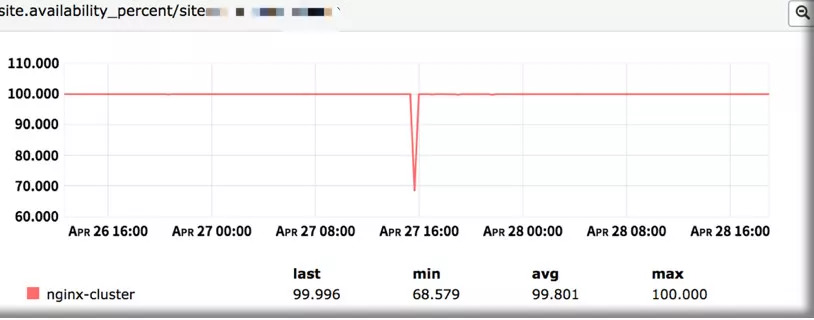
此时我们在DBA的慢查询监控中发现一个峰值,时间点基本吻合。下图为慢查询监控:
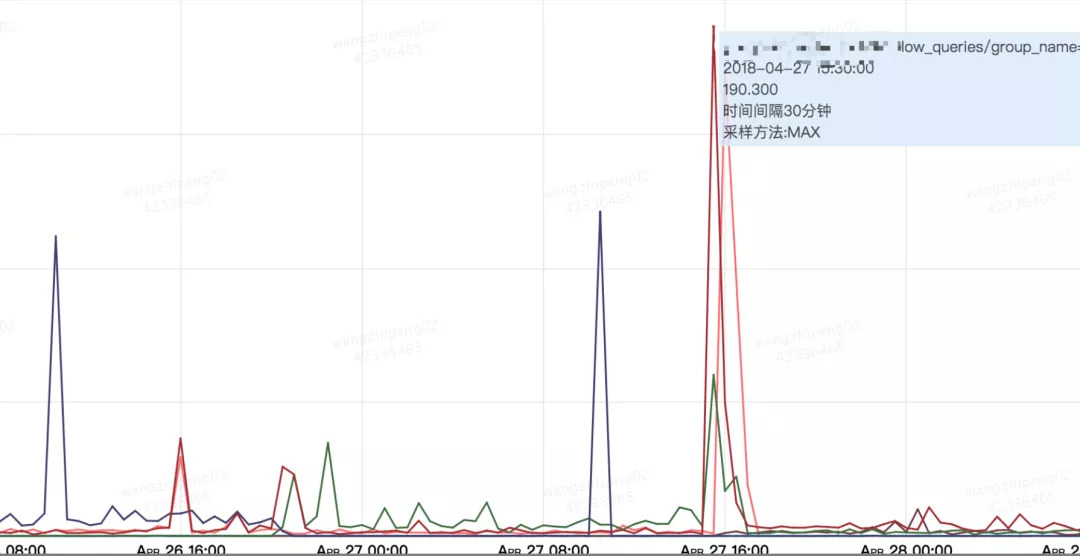
由此我们分析了这段时间的慢查询,发现这个SQL我们非常眼熟——MGR查询主节点的语句。正常这个SQL执行时间在毫秒级,故障当时执行了10s,而这个10s与stop group_replication这个操作的耗时基本吻合。

据此我们做了相应的测试验证了猜测:在MGR节点START和STOP过程中,当前节点的replication_group_member视图的查询全部hang住。这也就是解释了Nginx后台请求堆积造成的宕机。在此之后,我们在程序中查询这个视图时加入了超时的逻辑,解决了这个问题。
第三个问题发生在一次实际的机房故障中:CMDB主节点所在机房网络带宽减半,导致CMDB的MGR集群和一套业务主从集群几乎同时发生了切换,MGR的切换时间大概在3s左右,业务基本无感知,只发生部分报错,但业务集群切换发现回填CMDB失败。
究其原因主要是由于切换的逻辑仍然沿用DNS的连接方式,导致切换发生,DNS同步重新指向,而切换的应用程序对DNS新地址的解析迟迟未效。
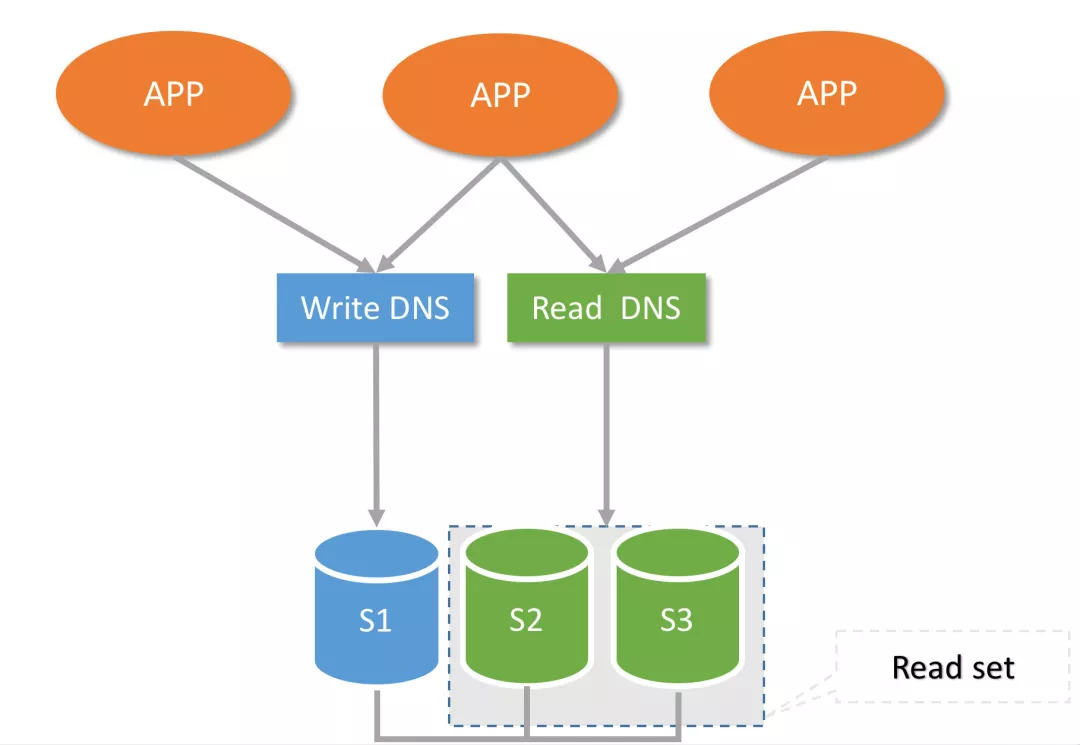
通过这次故障,也促使我们将所有核心CMDB访问全部迁移到内部开发的Smart Client端上。
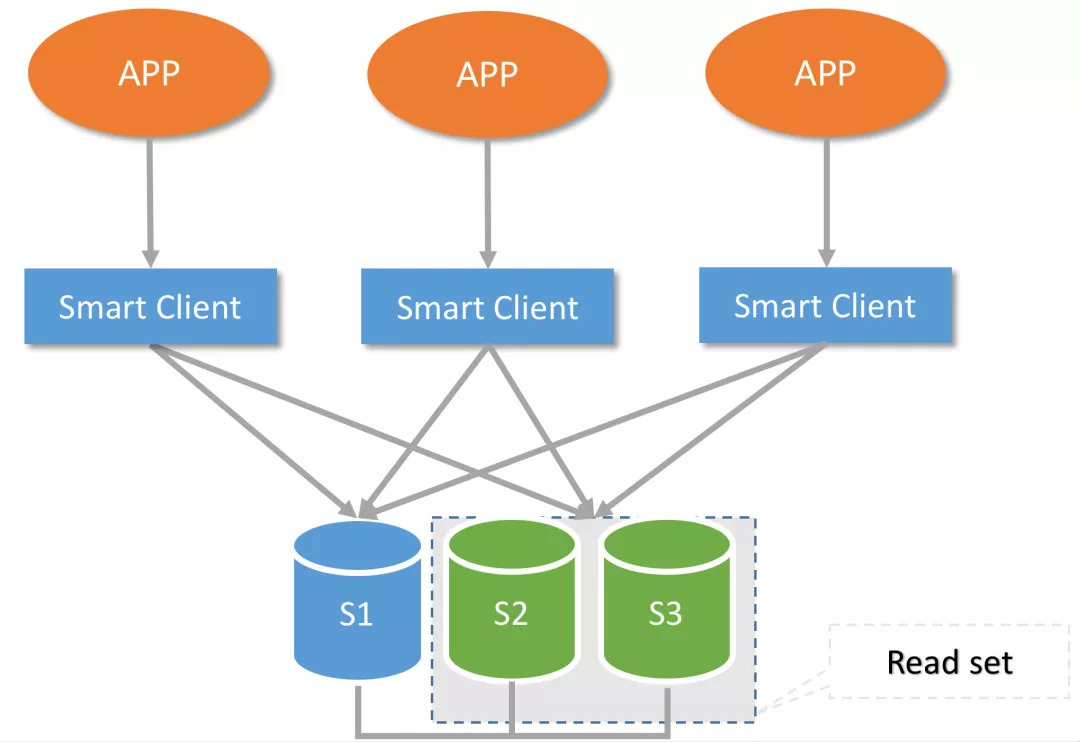
六、Smart Client
关于Smart Client,它是我们内部开发的一套Python连接API,是基于MySQLdb实现的一套MGR切换自动选主、读写分离的功能。对于熟悉Python访问MySQL的同学上手非常简单。
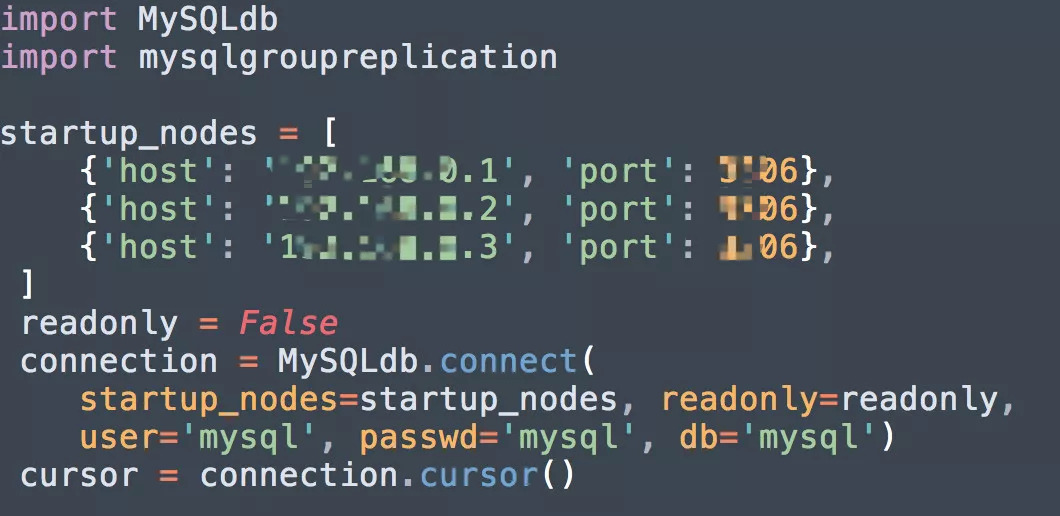
七、日常运维
关于MGR的日常运维,实际情况比较省心。
初始化除部分参数区别外,基本与主从集群差异不大。监控方面,我们除了加入系统和MySQL的基础监控外(对MGR兼容良好),还加入了MGR节点状态的监控,即非ONLINE状态的节点全为异常。同时会有同学问,延迟怎么监控?理论上MGR是个最终一致的集群,它内部没有延迟的概念,但我们可以通过监控待执行事务队列中数值,近似看做是一种延迟。

下图为线上一个集群的“延迟”情况,纵坐标为事务个数:
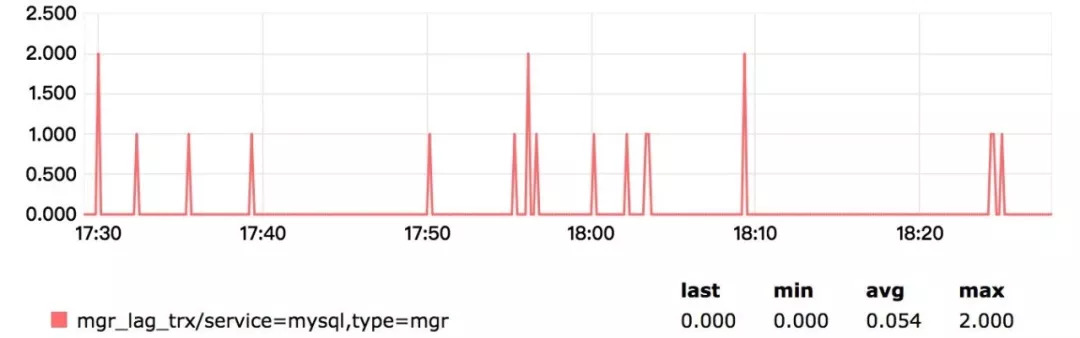
同时还有主节点与其他节点的GTID_SET差值也可以作为一定参考。
八、写在最后
通过我们一系列的线上演练,甚至包括部分高峰期的演练,以及一段时间的运行状态观察,MGR确实是一个稳定、可靠的高可用架构。虽然对于写入密集型场景不是非常友好,但相信还是可以为DBA的高可用方案提供新的思路。
MGR的要求:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-requirements.html
MGR的限制:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-limitations.html
参数配置:
https://dev.mysql.com/doc/refman/5.7/en/group-replication-configuring-instances.html
python工具包:Python MySQL Group Replication 使用
参考链接:https://km.sankuai.com/page/52289606








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721