
今天将和大家介绍常见的Redis架构、以往我在陌陌、去哪儿网做Redis时的一些经验,主要包括DBA日常维护MySQL或Redis时需要做的工作、如何根据日常工作和业务的需求来制定Redis架构,最后是分享一些好用的辅助工具,与大家共勉。
我们DBA在日常工作中主要会遇到这些问题:如何更好地了解业务和需求所在?如何根据业务需求设计良好的架构?……
日常运维如搭建实例、部署高可用、做业务、查询、元数据管理、监控与告警处理报警,这些还可通过一些人工来解决,但随着时间的推移,实例越来越多、机器越来越多、业务越来越复杂,这时我们就得要知道每个业务对应的Redis实例,以及其它MySQL实例需要借助自动化管理平台来简化工作。

面对业务需求(如一个业务要上Redis)时,DBA首先需要了解这个业务是干什么的。
去哪儿网有一个良好的习惯,就是DBA会深入业务线。以前我是负责机票系统的,几乎常年在机票的业务线待着,会去深入了解机票每个Redis是怎么用的,分清Redis使用时究竟是用在缓存还是存储上。
如果是用在缓存上,最大容量、报警、配置怎么配;如果是用在存储上,功能又该怎么管理。在使用缓存时是不是需要和业务沟通,每个Key有没有设置过期时间,如果没有设置,我则认为你是用来存储而不是用来缓存。
前期我们可以做一些规定,对后期管理做得比较严格,如果业务是用于存储的话,有可能导致无法写入等问题,所以一定要跟业务沟通,搞清楚业务需求的真正用途。
还有的业务需求过来,说需要600G甚至1T的容量,这时面对大容量的业务需求,我们要怎么搭建集群,并做好往后的扩容和维护。
还有的情况是业务需求容量很低,可能只需要1G,但是QPS达到了一百万,这时我们部署的多个实例,将包括这个实例怎么扩容、怎么管理,以及多个实例进来以后怎么用,这都需要有一个良好的架构。
了解完业务需求后还需要了解运维需求,因为开始搭建Redis架构后,业务可能用起来很爽,但是DBA维护起来则很难,整个架构升级都非常困难。
如何解决?首先我们要了解业务,建立一些元数据。因为业务非常多,每个业务有可能对应多个集群,通过建立元数据管理,就可以在问题出现时快速联系到业务方,这需要我们配合业务去共同解决。
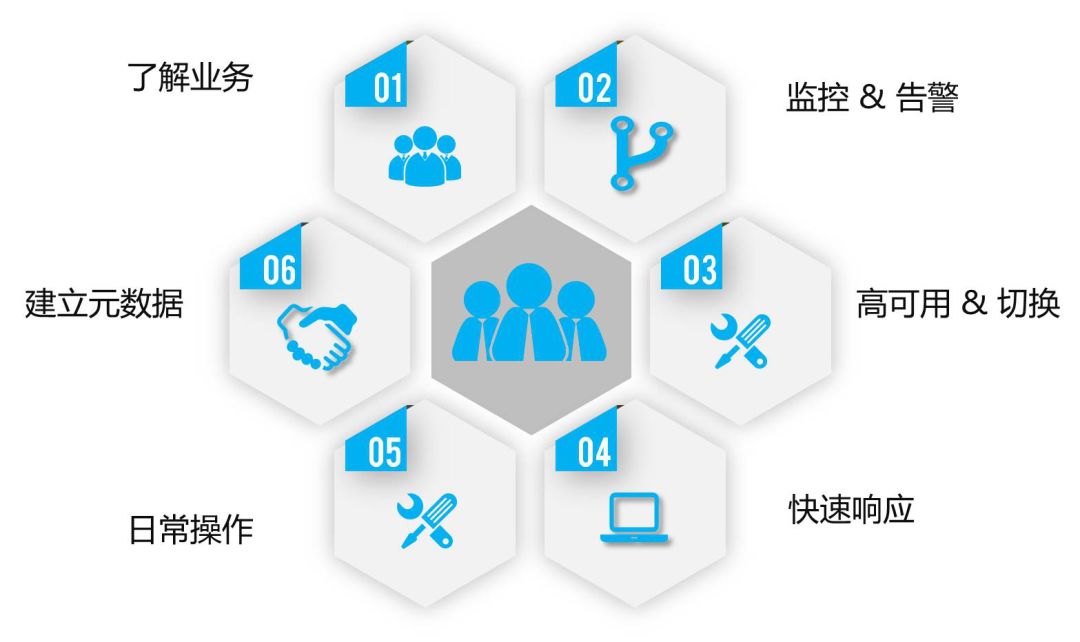
若是基于以前的人工运维,用自己的一些笔记或Wiki记录就足够了,但如果元数据记录到自动化管理平台,则可以把这些元数据收集起来,包括日常操作、上下实例、关闭实例、调整主从状态、清理数据等操作,这些都DBA需要去考虑。
此外,Redis后期的维护的操作能否在不影响上层业务使用的基础上简单地去做;监控报警、存储监控如何设置;高可用使用过程中机器非常多,有可能每天都会面临机器需要下线维护的情况,这时如何做在线切换;当机器宕机甚至整个机房都不可用时,如何在另一个机房快速重启……
做运维DBA是非常累的,7x24小时,光靠人来盯是不足够的,需要有良好的架构和运维平台相结合来实现快速响应。
在此之后,再通过了解自身的需求,开始思考如何设计一个良好的架构,以及在这中间即将面临的问题:
存储&缓存集群设计
扩容
高可用
运维平台
在如何设计一个良好的Redis架构上,我们给自己定了个小目标——实现财务自由,对此,在这个过程应该做到以下几点:
快。因为在业务快速发展中,我们每天都可能上线N个系统、搭建N套集群以及业务扩容。一个良好的架构,需要能够让业务在使用方面更加快捷与友好!
稳。随着集群数量与机器数量上涨,运维的过程中,几乎每天都会遇到扩容、机器搬迁、维护等需求。那么底层Redis集群的节点发生变化时,应该做到保证业务不受影响。
准。由于宕机、误操作以及其他原因,Redis都会发生切换,如何减少误切换带来的影响,这就需要一个良好的自动化切换的机制!
小目标定好,架构选型就该着手了。以下我们考虑到的一些点:

1、Redis主从or Redis Cluster?
Redis主从:稳定、维护简单,但扩容成本高,有可能在牵引的过程中业务受到影响。
Redis Cluster:维护成本高、扩容简单,相对来说较为复杂,卡死时需要研究源码,加节点操作也更困难。
所以在使用时我们选择一个Redis的主从,以及选用比较简单且稳定的版本,当然目前仍然使用2.8等,只要性能OK即可。
2、Proxy或者类似Proxy
可以隔离业务与底层Redis集群的关系,便于运维人员管理后台集群;
可以管理连接池;
可以控制HASH规则。
3、高可用
我们提供了一个Sentinel,当主机出现问题时,就可以自动地把从机提升上来。
4、元数据管理
包括前面提到的元数据,会考虑是用MySQL还是ZooKeeper来做,用ZooKeeper的好处是当节点发生变化时可以通知所有的业务端。
而对我们来说,用MySQL首先是更简单维护,也可以更清晰地看到哪个业务对应哪个节点信息。结果是,我们最初只用了ZooKeeper,随着后期的发展变成MySQL+ZooKeeper同时使用。
这是我们Redis架构访问实例的流程图,也是去哪儿近几年在使用的架构,中间有升级过。

一开始客户端通过Proxy集群,并根据Redis节点信息来访问Redis集群,比如一个Key过来之后是通过某些一致性的Hash来进行访问的,而Redis节点信息可以理解为是由Proxy集群或访问客户端打包到它们的业务客户端里。
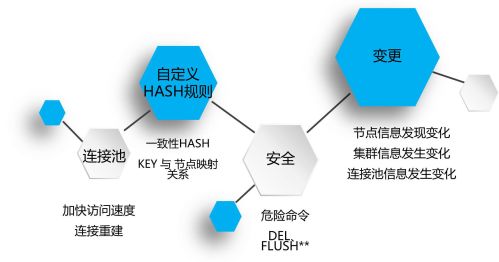
1、变更
因为我们给每一个业务定了一个Namespace,里面存了相关信息(一些主节点信息或连接池的大小都可在这里设置)。当客户端进来后,它首先从ZK里读取Redis的信息,并根据从Namespace处拿到这个信息,如果是拿到三个节点信息就可根据上面配置的连接池大小直接建立对应多少的连接,于是这时我们业务过来的时候就已经拿到这几个节点了。
如果这时业务又来了一个Key该怎么访问?这个Key首先在Proxy或者访问客户端中通过一致性算法来进行计算,就可以把某个Key分配到集群中的一个节点上。我们都可以拿到这个节点并操作里面的数据,但会存在一个问题:节点挂了怎么办?这里就需要启动我们的一组哨兵。
哨兵可以部署在多个机房,针对每一个实例分配一组哨兵(有可能每个实例有5个哨兵进行监控)。如果主节点挂了,我们可通过哨兵选举机制将Redis的从实例提升为主实例,老的实例起来之后可自动变更为从实例。但此时业务方并不清楚他们拿到的还是以前的老实例,只是发现现在连不进去了。
这时我们通过哨兵来进行ZK信息的修改,因为哨兵切换之后就能知道哪个是新主实例,我们修改对应的信息即可,修改完之后再触发客户端,我们就能让客户端知道知道现在的新主节点是谁,知晓了之后就会把连接进行重接,进而发现客户端连到新的地方了。这就是一个简单的Redis架构。
但这个Redis架构存在一个问题:如果是集群开始为三个节点,那如何从三个节点扩容到五个节点?因为所有的数据要重新做Hash规则,我可以先搭建五个实例起来,再按照我们自己写的同步工具和新的Hash规则来分析这三个实例的AOF文件,通过不停地分析AOF文件把这三组实例数据通过新的Hash规则Hash到五个节点上去,最后通过人工修改ZK信息,告知它现在已扩容到五个节点。
如果我们同步工具运行速度跟不上Redis的写入速度,就可能导致永远无法同步完成。因此,为了不影响业务运行,我们可以对这一块进行改造。
最初我们用了一个简单的一致性Hash,接着在这上面做了二层Hash,所以第一层Hash就是这个节点,第二层Hash就是可以为简单的取余,对我们而言,这样扩容就非常简单了,可以用主从搭建的模式。
2、自定义Hash规则
我们可以自定义Hash规则,如果一层Hash解决不了问题,就搭建二层Hash,再扩容某一个节点。与之前只能扩容三个节点相比,此时可以扩容五个节点,但在做二层Hash时就可针对每一个节点进行扩容,这对于运维来说非常简单,只需要搭建两个从库即可。
3、安全
安全方面表现为对客户端进行危险命令的屏蔽,不允许一来就是危险的DEL操作,包括更危险的FLUSH操作和一些新操作。
这些操作容易导致Redis发生卡顿,因此我们要对危险的命令进行过滤。所以在做DBA运维的过程中,当节点信息发生变化时,客户端能够自动更新,包括集群信息和连接池信息等。
4、连接池
基于连接池的规则,有可能某一个节点连接数过大,可能达到8至9千甚至上万个连接,而一个客户可能不需要那么多连接,并且里面很多连接是废弃的,所以就需要我们在MySQL里修改数据池的数量,让其能在监控异常时快速响应,并通过ZK来通知,这便不会对我们的业务产生影响。

1、一对一:一组哨兵就一个节点,维修成本低一些。
2、多机房分布式:更加灵敏和准确。
3、自动切换:前提是从库一般不提供服务,在主库发生宕机时,它会进行自动切换,将新的主节点信息通过ZK和配置中心推送到业务端,让从库提升为主库。
4、通知:包括ZK业务端自动的感应,包括在业务上线时需要人工做一次哨兵的切换,同时要检测高可用、机器是否可用、架构是否有问题等,这时就可以通过哨兵修改ZK,Proxy也将自动感知。
5、DBA入场:入场之后需要查看监控信息和报警信息,确认哨兵是否做到真正切换或者ZK信息有没有更新到,包括更新后业务端有没有收到等,若没有收到,需要人工再次检测,但这种机制对我们来说稍微简单一些,因为很多东西都可以通过工具来完成的。
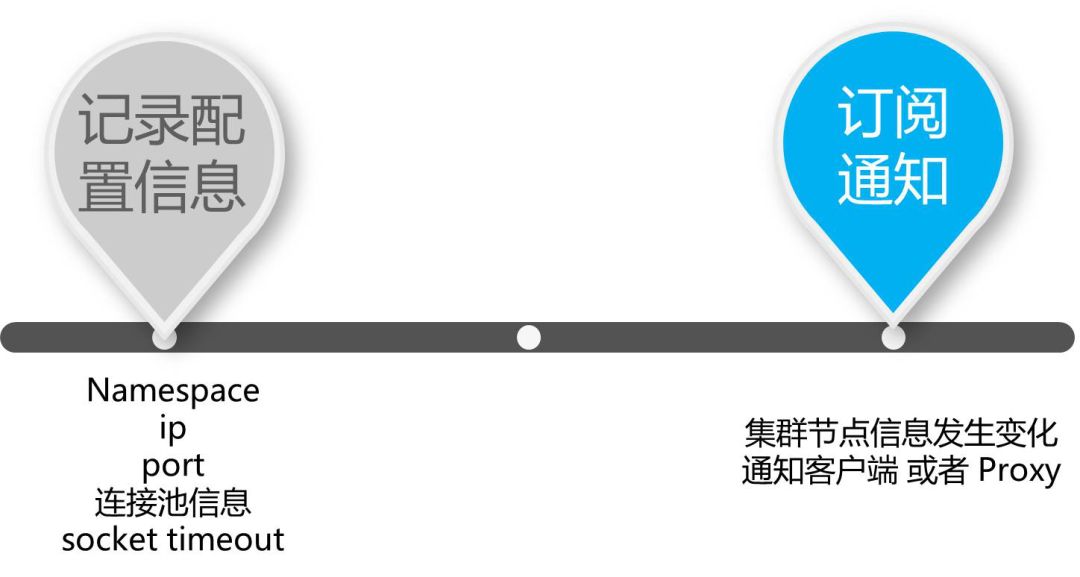
ZooKeeper主要负责两件事:记录配置信息和订阅通知。首先,它会针对每一个业务制定一个Namespace的概念,这样业务对应的多个信息都可以在这里设置。
此外,当集群节点信息发生变化后,会通过ZooKeeper来通知客户端或者Proxy,以进行快速的响应。但这有一个问题就是会在通知时有可能发生失败。
当我们设计了一个Redis架构之后可以如何使用呢?
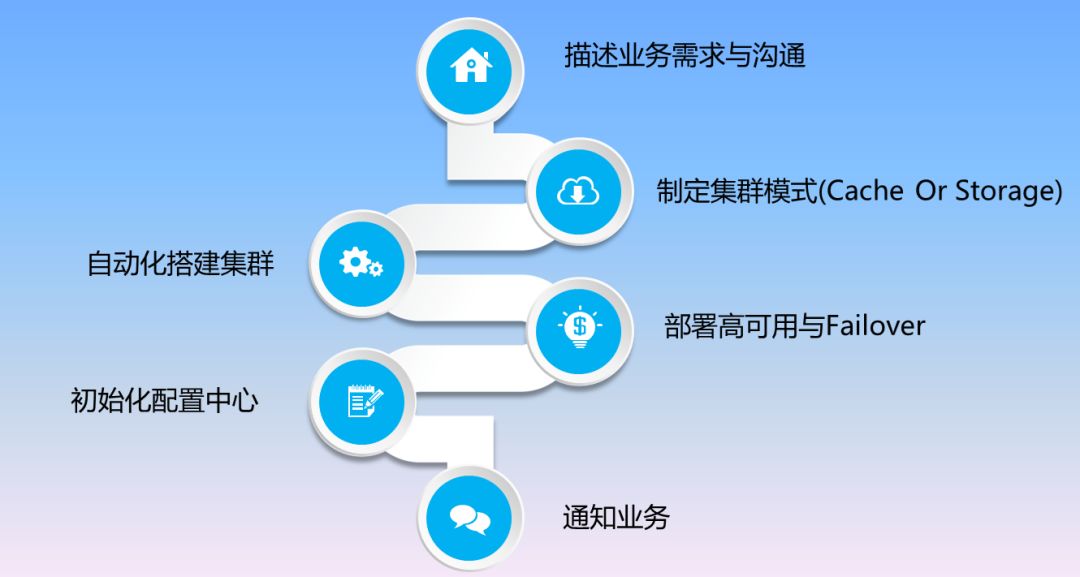
1、描述业务需求与沟通。我们要确认业务的使用场景、容量、QPS等一系列信息。
2、制定集群模式。要设置一个良好的集群,有可能需要十到二十个节点,需要在前期制定一个模式判断是否为缓存,如果不是,报警信息是不一样的,设置信息监控点也不一样。
3、自动化搭建集群。可通过自己的工具自把一些集群快速、自动化地搭建起来。
4、部署高可用与Failover。高可用部署一定要做好Failover机制,因为有可能布上去了但没有做到真正的精细化,这样人工上线时就会出现问题。
这里我们做了一个简单的工具,即我们搭建了一套集群(里面有一百个实例),但不可能把每个实例都做检测,所以我们可以对集群进行一个级别的界定,如果是核心集群,我挑90%自动做一次Failover,如果是非核心集群,则选择60%自动做一次Failover。
5、初始化配置中心,把信息都填进去。
6、最后通知业务集群已搭建好。
前文刚说了一下我们第一、二个版本的扩容方案与流程,这里再仔细梳理下。
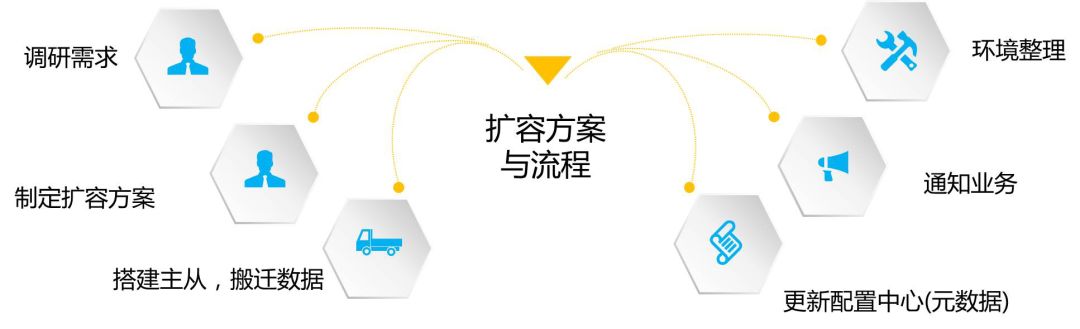
首先我们拿到一个业务,或许是压力扛不住、反应慢了、容量不够了或运维方触发,使得运维方检测到的实际内容一开始是10G,但我们监控出来时已达到15G,这时我们也许需要扩容了。
随着日益的发展,我们一开始只定义了10个G,但慢慢地超过了10个G、20个G,因为当Redis一个节点的存储量越来越大时,运维的成本也会越来越大。此外,10G以内做主从实例搭建是非常简单的,但如果是20G或30G,做一次的恢复时间很长,所以运维方也会触发一次需求。
如何做业务扩容,事实上业务并不关心,但对运维来说就很困难了,即刚说的第一种方案:自己写同步工具去扩第一层Hash。
当我们有两层Hash时扩容很简单,搭两个从库、三个从库就行了。但这里搭完后会有一个问题:数据存在多余的数据。
也就是说,当我们做环境整理、搭建主从,只需把数据迁移过去就OK了,接着更新配置,通知业务集群好了,让他们查看一下。可这里有可能一个集群由三个节点变为五个节点了,因为每个节点在扩容后存在一部分数据是垃圾数据,而这部分数据在做Hash时是不需要的,所以我们需要根据新的Hash数据,把老的信息清理掉,人工慢慢删除就不会影响业务,这样我们的容量也扩容完成了。
1、优点:
便于扩容:直接搭建从库即可。
便于调整:包括节点调整的信息、连接池的信息也可以控制,业务能做到自动感知。
维护简单。
稳定:利用有哨兵机制来进行保障。
2、缺点:
缩容复杂。三个节点怎么缩到两个节点,目前还没有想到好招,可以把最大内存调一调,比如把10个G调成5个G,当然实例个数保持不变。
客户端升级困难。因为需要把所有业务都升级一遍,所有我们目前使用的原则就是老的业务有可能还在使用第一个版本的Hash规则,新的业务则上第二个版本。
当有了一套良好的Redis架构后,我们是不是还需要其它的工具或平台来辅助DBA进行管理?这部分简单和大家介绍下心得。
我们可以做一些运维的小工具,包括部署相关的自动化小工具、平滑迁移、内存分析工具以及数据清理等。
除了简单的小工具,还可以上一些人工智能的东西。我们简单做了一个平台,可以帮助我们实现元数据、日常操作、监控& 告警、自动化等管理。其中:
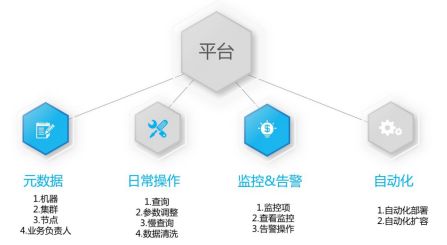
元数据的管理:包括对机器、集群、节点和业务负责人的管理。
日常操作:这些操作可提供给开发使用,包括查询、参数调整、慢查询和数据清洗。
监控&告警:对缓存来说,我们不设置最大内存的报警,正如前文我一直强调的,使用集群时要定义好到底是存储还是缓存,对这块进行分类后很多操作就可以在这个平台上进行。
自动化:包括自动化部署和自动化扩容。
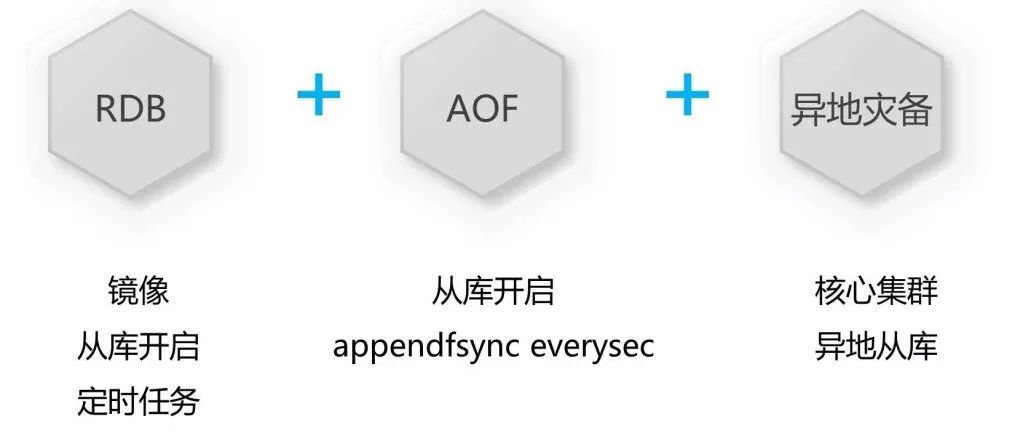
对DBA来说,备份是一项日常的工作,Redis也不例外,这里我们可以结合RDB+AOF的功能。因为主库有时可能压力比较大,而RDB有可能是半小时做一次,如果在这半小时内主库挂了怎么办?这时就可以开启从库。
那为什么把RDB和AOF两者结合?因为如果我们有RDB的时候数据有可能会丢失,而若只用AOF文件,这个恢复过程则非常慢。有的业务说,我可以允许丢一部分数据,但要能快速恢复。
因此我们选择了两者结合的方式,不仅恢复速度非常快,还能保证主从库都挂的情况下数据依然可以恢复,当然我们还有另一个机房可以用,这只是针对核心的来说。按理说,一般平时这两种方案的结合就满足我们的需求了。
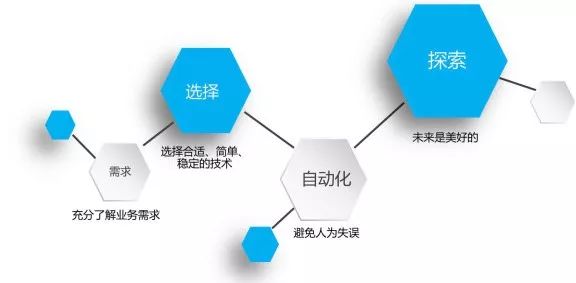
最后做个总结,我们一定要深入业务,知道Redis具体用在哪、怎么用,了解后可以选择更简单的、更适合我们的技术来做架构,包括做到良好的自动化。因为光靠堆人来运维会非常疲惫,如果有一个很好的管理平台和自动化工具来辅助我们,将会事半功倍。
而对于未来的探索,我们将对一些新技术进行调研。最理想的状态,是通过一些简单的自动化,让DBA们能够轻松一点,省点时间学习新技术,解决工作中其他的难题。
【问题1】Redis架构底下是一个机房放了一个哨兵,还是一组哨兵?
答:如果目前你们公司只有一个机房,那哨兵只能放在同一个机房。但如果你们公司像去哪儿网或是陌陌这种有好几个机房的话,就可以把哨兵放在不同的机房,其中每个机房放一个。举例来说,如果想要监控这个实例,有五个机房就部署五组哨兵,一组哨兵就是五个节点。
【追问】那如果把哨兵部署在多个机房上,哨兵发生脑裂了怎么办?
答:所以我们要通过部署基数,来更好地避免这个问题。
【问题2】如果把元数据放在ZooKeeper上,那ZooKeeper要和Redis放在同一个机房吗?
答:我们建议把一套ZooKeeper集群里的几个节点放在不同的机房,因为多机房有可能存在问题,这是不可避免的,但目前我们这样使用方面,从来没有出现问题,可以做到比一般的网络监控还要更加灵敏。
【问题3】老师您好,我在做Redis监控时有这样一个困惑:Redis根据不同的业务,它的QPS是不一样的,如何满足我们想去监控这个业务的Redis是否是异常呢?
答:每个业务的监控值设置不一样的数。
【追问】这样做设计起来会非常麻烦,而且业务在改变时那个值也不会去浮动,您这边有什么好办法呢?
答:首先我们可以通过管理平台来看到每个实例,这样就可以针对每个实例进行监控值的设置,包括QPS。我们可以设置两万报警、三万报警,如果这时我们的业务访问量比较大,假设可能是六万,那我们就设置到七万报警,这可以做到粒度很细,针对每个实例来进行设置。所以我们在搭建时就会了解“你这个业务的QPS大概是多少”,比如说我的QPS是六万的,可能搭建四个节点,也有可能业务最初给的初始报警数就是六万,一旦超过就可以报警,那我们就可以进行初始化,把这个报警的阈值设定出来。
【追问】也就是细化到实例级别?
答:对,细化到每个实例。每个实例的监控值都是不一样的。
【问题4】老师可否再讲讲PPT上关于异地灾备这块?
答:我们可以做一个核心集群,并在异地机房再搭建一套从库。
【追问】如果本地的机房挂掉之后是需要通知?
答:这时就有可能不用哨兵监控了,如果整个机房都挂了就需要人工了。因为这时的异地灾备就是整个机房都不能使用了,我觉得是需要人工介入的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721