
本文根据老师在〖deeplus直播:大模型 Agent 在 AlOps 的探索〗线上分享演讲内容整理而成。(添加助手vx:dbayuqing,获取直播回放地址)
一、AIOps与大模型Agent
1.AIOps的兴起与应用领域

在数字化转型的浪潮中,IT系统变得日益复杂,数据量呈爆炸式增长。微服务、云原生、ServiceMesh等新技术的崛起,带来了负载的服务关系依赖与海量的可观测数据,传统的IT运维方式已经难以满足现代企业的需求。AIOps正是在这样的背景下应运而生。
AIOps利用人工智能去解决我们运维过程中遇到的海量数据与复杂度的一些问题,能够帮助企业去提高IT运维的效率,降低的成本,提升我们的用户体验。
AIOps的重要性不言而喻,它帮助我们从海量的数据中快速识别问题,预测系统故障,从而提高系统的稳定性和可靠性。AIOps的应用领域非常广泛,包括性能分析、异常检测、事件关联和根本原因分析,以及安全运维等。
2.大模型Agent简介与特点

大型语言模型(LLM)是基于大量数据进行预训练的超大型深度学习模型。它们拥有强大的自然语言处理能力,但通常缺乏主动性和与现实世界交互的能力。为了克服这些限制,大模型驱动的Agent应运而生。
Agent可以理解为一种能自主理解、规划决策、执行复杂任务的智能体。它能够感知环境,通过自己的决策和行动来改变环境,并通过学习和适应来提高性能。
Agent 并不是一个新的概念,但是LLM 出现之后,Agent 对 任务的规划能力有了一个巨大的飞跃;大模型Agent结合了LLM的强大能力和Agent的自主性,使其能够主动规划任务、调用外部工具获取信息、执行操作,并根据环境反馈调整行动策略。
3.大模型时代的 AIOps
大模型的强项在于处理这种非结构化的数据,比如说自然语言等等的,对这些理解处理能力是比较好的,但是大模型有个明显缺陷,对于一个很简单的数据计算,它就没办法去得出一个正确的结论。
而AIOps 算法的强项正好在于对结构化的数据能够有很好的分析处理能力。
传统的AIOps 算法的灵活性较差,只能针对特定任务做大量的数据训练才能得到比较好的效果,而大模型者表现出一定的通用性,能够使用不同的任务场景,灵活性较高。
LLM 在自然语言处理和多任务处理方面具有显著优势,这使其在 AIOps 领域具有巨大的潜力。然而,传统 AIOps 算法仍然在特定任务和数据处理方面具有优势。

利用 LLM 和 传统AIOps 的特点,将LLM与AIOps 结合,让 LLM 出处理与人类交互的非结构化数据,AIOps 去处理结构化数据得到精确结论,然后让LLM 以更贴近人类语言的方式反馈给人类。
大模型时代 AIOps具备了与人沟通的能力。
它的交互的改变就是从我们传统的命令式或者UI变成了自然语言交互,之前是比较贴近于机器的工作方式,现在有了大模型的帮助,那么可以让它更贴近于人类的这么一种模式。
二、AlOps场景下的大模型Agent实践
上下文:

大模型是基于用户输入的上下文来预测输出结果,一般来说,输入的上线文越丰富,输出结果越精确。
上下文的质量决定了大模型输出的质量
大模型是基于公开的网络上的数据训练得到的,它是无法感知/了解企业内部私域知识的,我们需要利用上下文将内部的私域知识传统给大模型,才能让大模型输出符合企业内部事实的结果,将 “外地人”变为 “本地人”。
五大支撑:

在落地大模型Agent之前,企业需要做好充分的准备。这包括内容支撑、平台支撑、流程支撑、人才支撑和安全支撑。
内容支撑让大模型了解公司业务
平台支撑让大模型可以执行操作
流程支撑让大模型行为标准
人才支撑保障大模型落地效果
安全支撑保障企业内部数据安全
这些准备工作是确保大模型Agent能够有效运作的基础,确保大模型相关工作有序展开的关键。
2.大模型开发技术
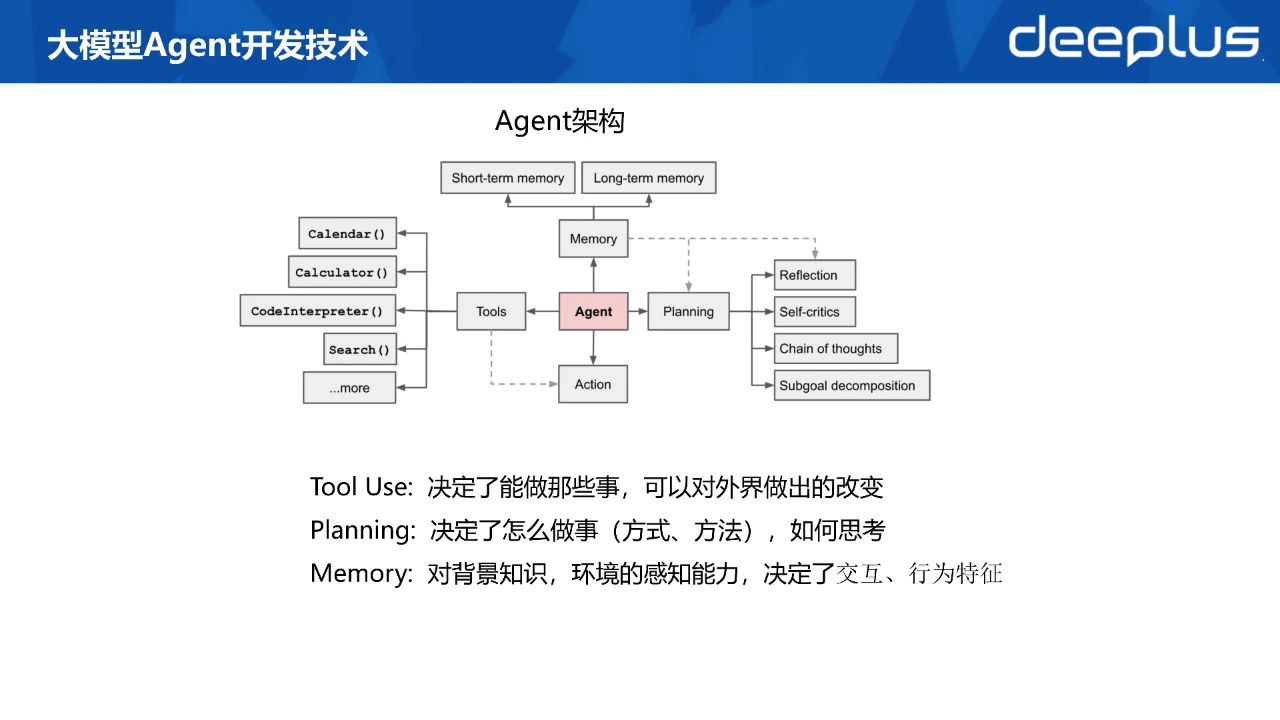
Agent可以理解为某种能自主理解、规划决策、执行复杂任务的智能体,它能够感知其环境,通过自己的决策和行动来改变环境,并通过学习和适应来提高其性能。
简单理解:Agent = Planning + Memory +Tools
大模型只能告诉你怎么做,而 Agent 可以直接帮你做。
五层基石理论:

第一层就是模型,我们常见的就是各种大模型,然后通过API去调用,发出一个指令,然后大模型根据你的指令返回一些结果。
第二层是 prompt模板,我们在prompt中可以引入一些变量,动态地为大模型提供额外上线文或参考知识。
第三层就是链式调用。我们通过chain 把多次大模型调用串联起来。使用的主要场景是
将上一次的模型输出作为下一个模型的输入。这样就能很好对大模型的一些缺陷进行一个弥补,或者是能完成更加复杂的一些工作。
第四层就是Agent,能自主执行链式调用,通过工具对外部环境产生作用。既能告诉你怎么做,还能帮你做。
第五层就是多Agent 协助,问题拆机,自动分工协作,帮人类完成更复杂的任务。
Agent落地的核心技术:
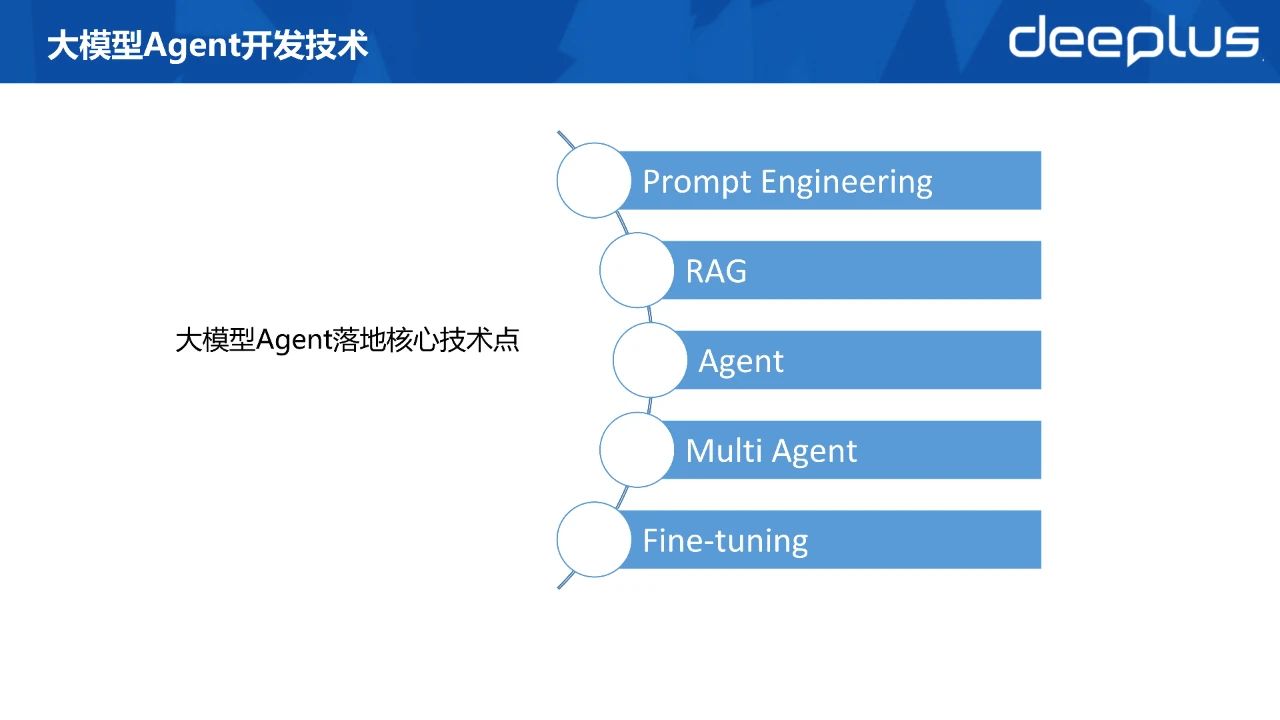
Prompt Engineering
RAG
Agent
Multi Agent
Fine Tuning
Prompt Enginerring
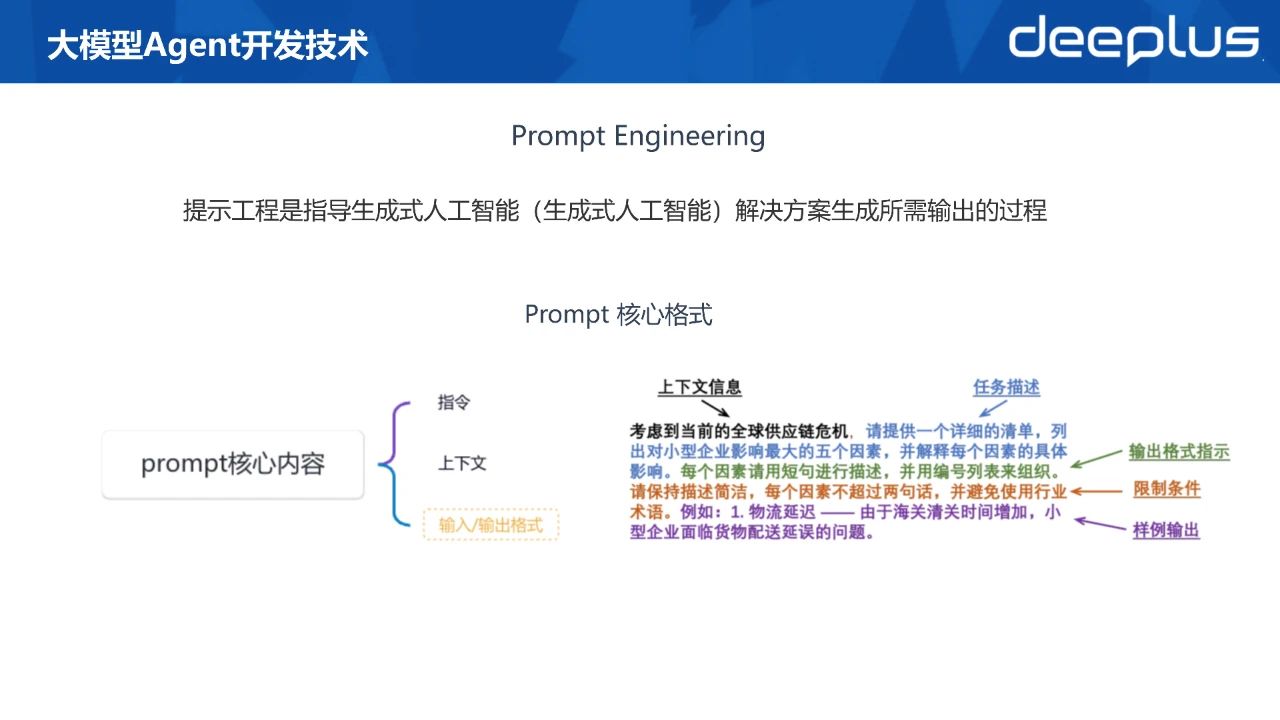
提示工程是指导生成式人工智能(生成式人工智能)解决方案生成所需输出的过程
提高精确度和相关性:精心设计的提示可以确保 AI 模型生成的结果既准确又与用户的需求相关,从而提升用户满意度。
提高效率:良好的提示可以减少获得所需信息或执行所需操作所需的交互次数,从而节省时间和资源。
安全性:良好的提示设计可以降低 AI 模型生成有害、偏见或其他不可取内容的风险。
定制化:用户往往有独特的需求,而提示工程则可以根据个人喜好和目标,实现与 AI 模型的定制化交互。
RAG:

检索增强生成技术,是一种将检索和生成相结合的自然语言处理技术。它利用大规模的语料库进行信息检索,为生成过程提供丰富的背景知识和上下文信息,从而提高生成结果的准确性和多样性。
RAG 是增强大模型能力的一种手段,当Prompt 无法达到我们想要的效果时,可以使用检索增强方案将内部的知识、经验等输入到大模型中,达到矫正大模型输出的效果
Agent 4 种设计模式:
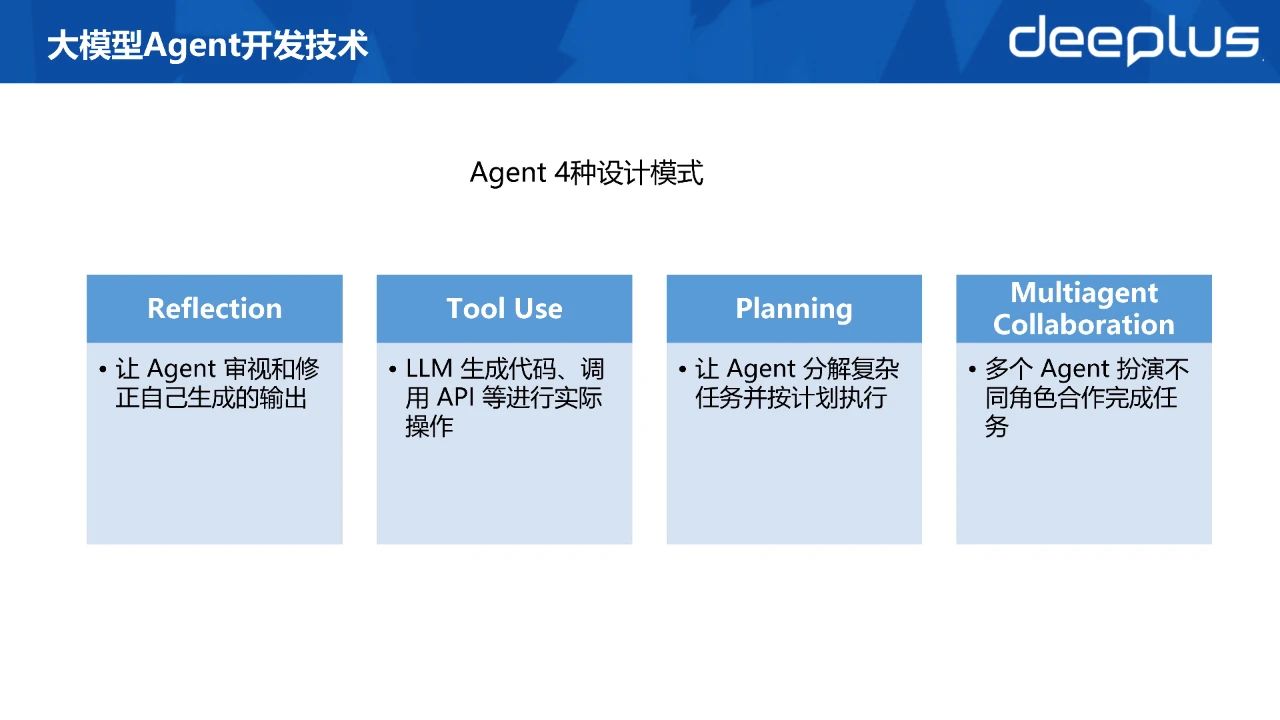
吴恩达教授提出的 4 种主流的 Agent 设计模式
Reflection: 让Agent 审视自己的输出
Tool Use: LLM生成代码、调用 API 等进行实际操作
Planning: 让 Agent分解复杂任务并按计划执行
Multiagent Collaboration: 多个 Agent 扮演不同角色合作完成任务
Multi Agent:

单一 Agent 能力有限,面临复杂问题时能力不足。在这种情况下,我们可以将一个复杂问题拆解为几个相对简单的子问题,由不同的 Agent 协作解决。
多 Agent 之间协作的实现方向目前主要有三种:
SOP 驱动的协作:用户定义明确的协作方式
LLM 驱动的协作:LLM 动态决策 Agent 间的协作流程
并行计算汇总:利用任务规划、分发、执行、提交、修正的链路,通过提交和修正Agent完成汇总和判断
微调技术:

RAG 与微调是常用来增强大模型输出的两种手段。
你如果是经过Prompt 和 RAG技术完全没法解决你的问题,这时候你要考虑是不是需要做微调了。Prompt 和 RAG 都是发生在指令发出后,而微调是发生在指令发出前完成的。微调可以赋于大模型不具备的新能力。
吴恩达教授曾提过 目前 90% 的场景都可以通过 RAG和增强背景知识解决,所以微调的时候要考具体场景,不能一概而论。
微调主要三大方向:
全量微调:把模型参数全部重新训练,全量训练的代价是最高的,
参数微调:可以微调部分参数,在某一条件下可以减少GPU内存的使用,同样能达到我的效果。
RLHF:人类反馈强化,对人类任务敏感的任务需要。使用 RLHF比较有名的就是ChatGPT 。
3. 实践技巧
什么样的场景可以使用大模型解决。

每次都需要做相同的三件事:
第一个就是收集,你需要知道你完成这个任务需要哪些信息;
把信息收集足够了,然后第二部分你需要指导大模型,你告诉它需要做什么;
然后最后一部分就是检查这个是不是正确。
因为这样大模型没办法就百分百正确,所以你的输出一定要检查。
所以我们在很多应用场景下都要考虑这个检查结果所带来的成本是多少,比如说让大模型去生成代码,但是这个代码你可能检查这个代码的时间可能是需要很久。
当完成这三步使用大模型比人工快的时候,可以考虑使用大模型。
怎么开始?

先确定一个比较小的工序或者小的步骤,让大模型去解决它,如果能解决,就逐步把小的工序在扩展,覆盖一个更大的流程,最终就是一个具体的工序到一个流程,再到一个闭环的场景。
具体工序比如说在故障里面,可以先做日志故障的定位,然后故障定位之后,可以考虑是不是其他的工序一块做了做成一个流程,就是故障税流程。故障处理完之后,是不是考虑做一个闭的故故障闭环的流程,能处理故障完成生成报告,还能跟进故障任务的解决情况。
RAG 与微调:

RAG 主要使用的场景是:
知识问答
内部背景知识
聊天历史
微调主要的场景是:
新领域(新的脚本语言)
特定领域的基础能力
特定能力的增强等
三、大模型Agent在AIOps中的落地场景

我们内部基于大模型 Agent 落地了很多场景,取得特好效果的有:内部知识库问答、CMDB 查询、故障助手等。
知识库问答:

我们将内部的文档流程文档、使用说明、故障预案等全部向量化,通过机器人问答的方式开放给内部用户使用。
基于Agent 记忆能力与多轮对话,可以实现根据用户反馈自动矫正回答
CMDB 查询:
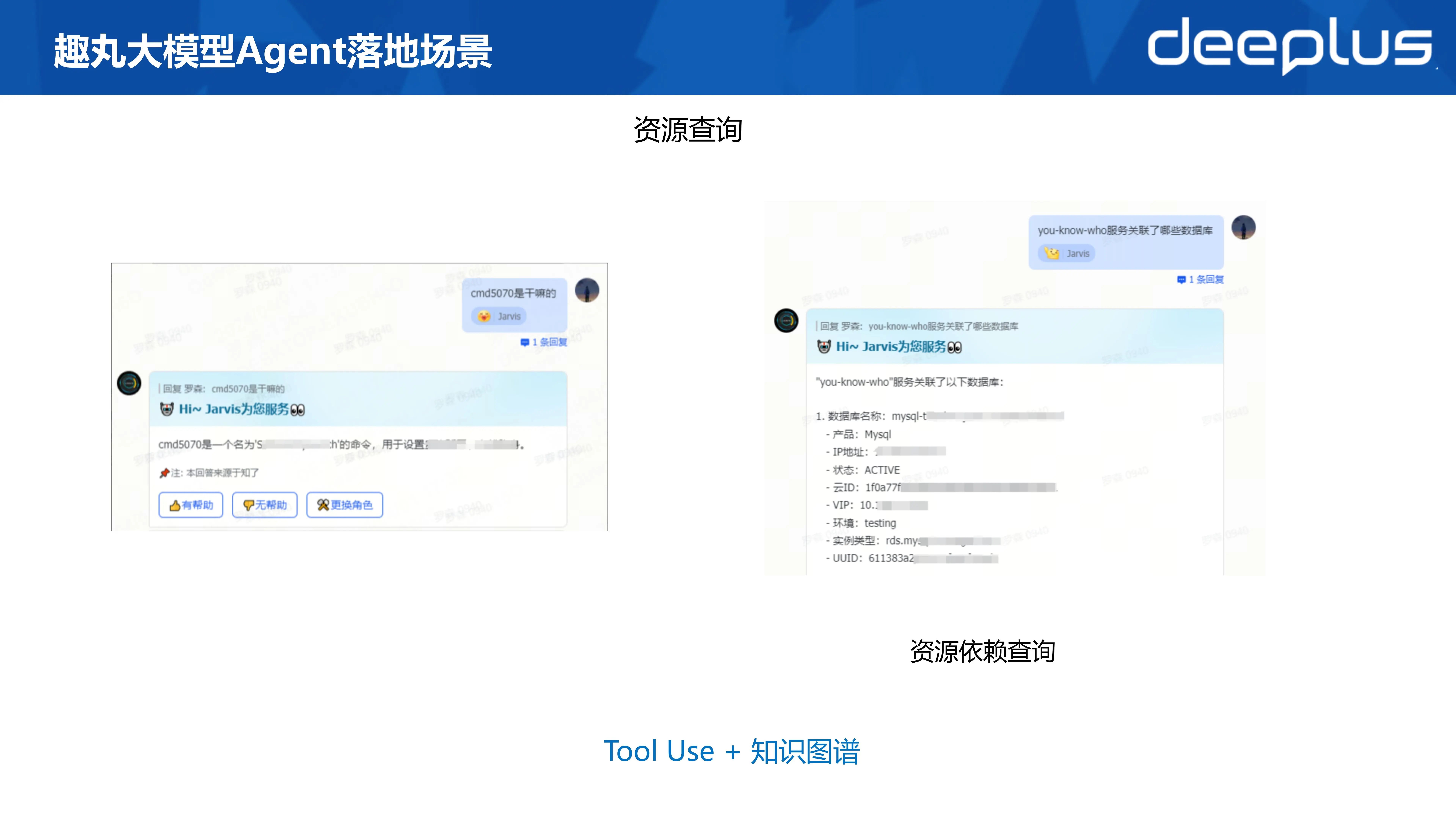
CMDB 查询,是一个知识图谱的落地场景。知识图怎么生成呢?需要我们将内部的资源对象做语意化的关系管理,比如 IP 和主机是绑定关系,应用和数据库是依赖关系分等。
通过自然语言对话可以查询公司内部所有资源。
故障助手:
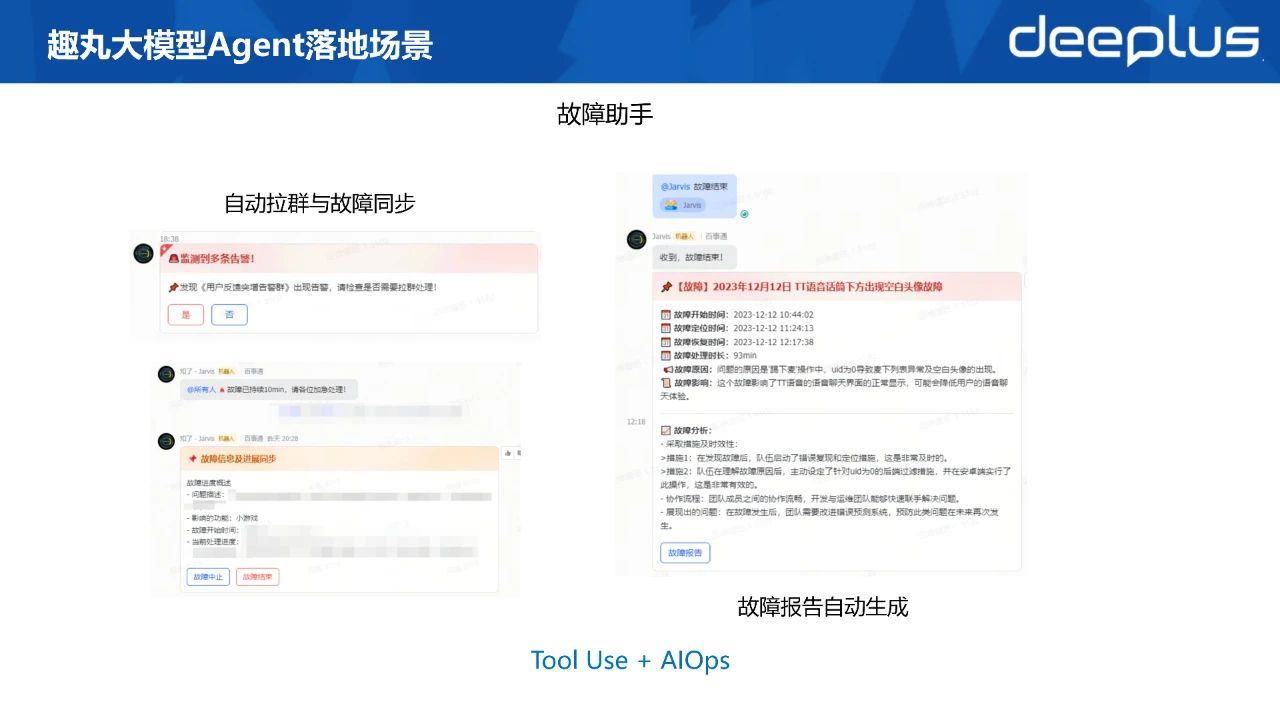
每个公司都有自己的故障处理流程,在发生故障时,将大家都拉到一个群里边开始去处理故障,需要谁协作,就不断拉人进来。
这会有个问题,比如后来进来的人,他不知道故障到底处理到什么地步了,那就需要去看之前的所有历史,比较浪费时间,我们的故障助手它会自动的去帮你总结之前群内所有人的聊天信息,每个10分钟总结一次,然后同步到群种现在故障处理到什么地步,进展是什么。
当用AIOps算法发现的大量用户反馈,比如说游戏进不去,或者是一些比如充值充不了,那么AIOps会得到把这个信息发送给大模型,大模型就开始去自动拉群。根据故障关联的这些模块去拉相应的人去进群一块去解决这个问题,然后定时的去互相同步。
当故障结束之后,它会生成这次故障的简报,然后生成最后的故障报告。
基于多Agent 协作的智能运维机器人:
其实我们能看到,无论是“构建 AI 应用的 5 层基石理论”还是吴恩达教授提出的 “4 种Agent 主流设计模式”都提到了多Agent 协作。
那为什么需要多Agent 协作呢?

对一个复杂的问题,我们常用的把问题分解成比较简单的问题,针对简单子问题再进行解决,最后汇总给出结论。
我们通过多Agent 协作,讲一个问题拆解,交给不同的Agent 分别解决,然后汇总给出结论。
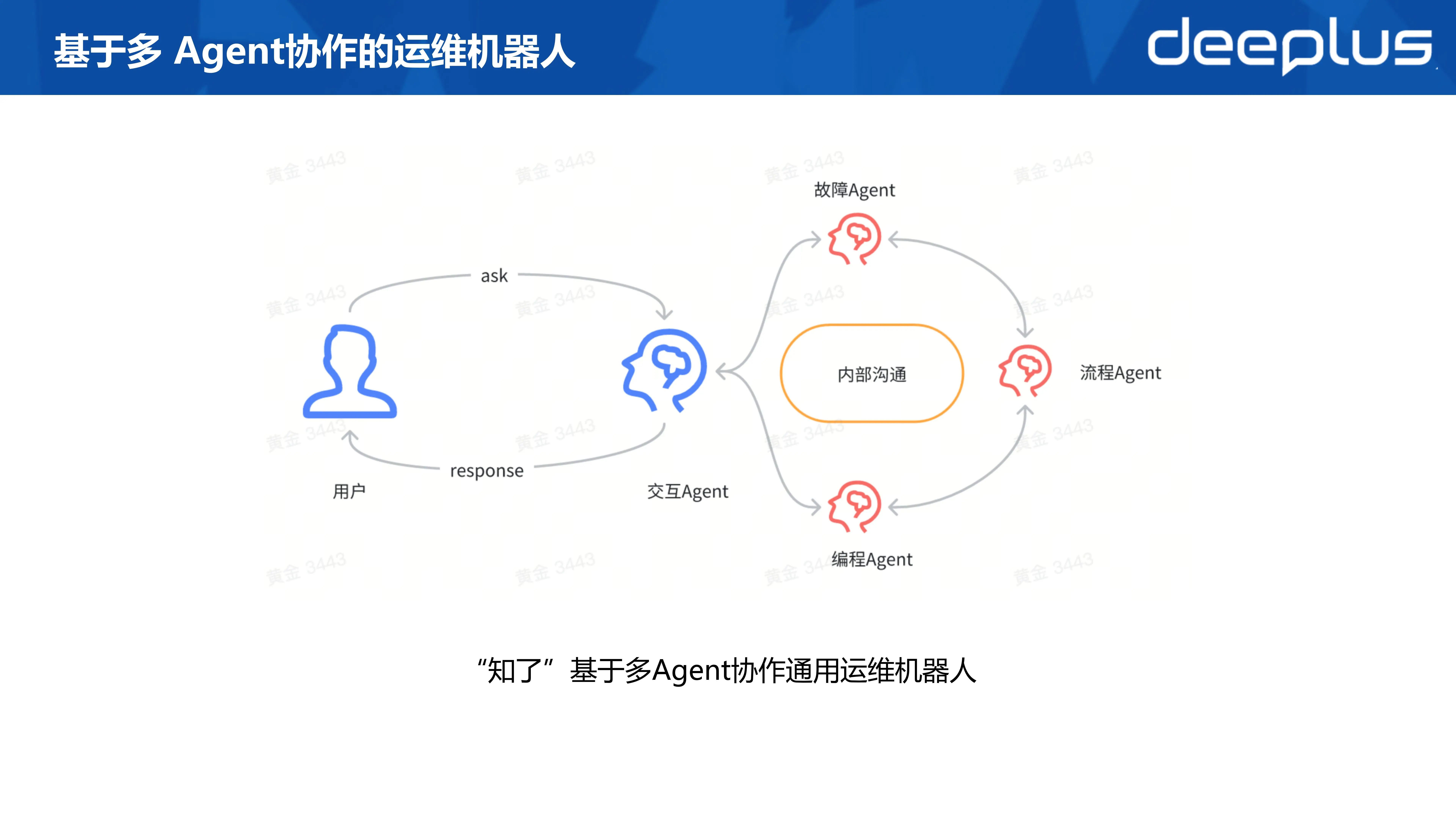
多Agent 协作的机器人更贴近人类的交互习惯,不需要先选择问题要使用哪个Agent,而是由系统自动分工协作,一站式解决。
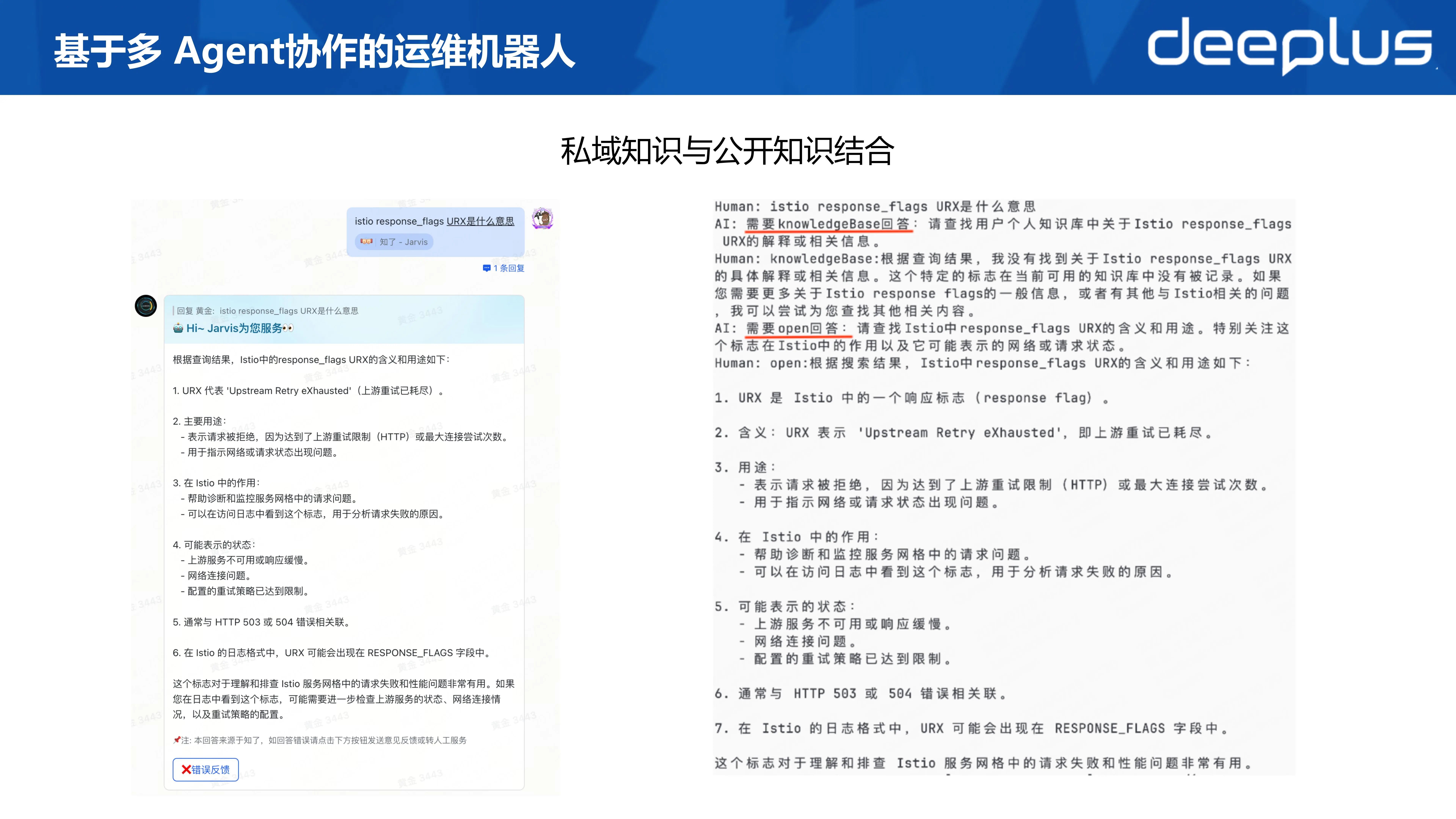
一个典型的场景就是我们可以将私域知识与公开域知识结合共同解答用户的问题。
Q&A
Q1:知识图谱有落地吗,是怎么生成的呢?
A:CMDB资源信息查询就是一个典型的知识库图谱落地场景。我们将资源与关系语意化并存储在图数据中,比如IP资源绑定到vm上,db被application依赖等等,然后就可以通过自然语言查询了。
Q2:大模型自动拉的是什么群?跟大模型的交互都是在群里吗?
A:发生故障时,大模型会自动拉起故障处理群,所有的故障处理相关的操作均在群中进行,中间如果需要拉其他人进群,大模型也可以帮助直接拉进群中,这样大模型才能根据群中人员的聊天内容复原整个故障处理过程,最终生成完整的故障报告。
Q3:运维操作很严谨,如何确保大模型提供的信息的准确性?如何事前测试?
A:和人工操作类似,如果一些影响严重类操作,一般需要多人检查确认后操作,有了大模型,人可以作为大模型操作的检查者,在一些变更类操作执行前有人类check后执行可以确保执行的准确性。
Q4:多agent的通信机制是怎么样的,纯靠大模型来选择吗?涉及工作流吗?
A:我们自己实现的框架可以支持多种方法,如果有标准的SOP流程则可以按照SOP来协作,如果没有,则有大模型自行决策。多agent之间通过共享聊天内容和记忆实现协作。由大模型或者workflow来决定是否继续以及下一个协作的agent是谁。整体我们是基于LangGraph实现的。
Q5:用大模型去抽取日志里的异常,日志量那么大,大模型处理的过来?
A:大模型用来处理非结构化的日志是比较容易,但是大模型有上下文长度限制;为了解决token数量问题,可以采取两种方案:
基于事件去截取固定长度的上下文,比如k8s pod崩溃发生时,截取最后 500 行。
对于应用日志,会有大量相似和重复的特点,通过相似性算法从大量日志中筛选出部分日志,然后让大模型去处理,这样既能兼容token限制,也能兼顾准确性。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721