
系统响应时间突增,CPU使用率明显上升
系统偶尔卡顿,大部分时间正常,但是过几个小时就会卡顿,影响正常请求
系统假死,服务还在运行,但是无法响应请求
内存占满,OOM异常
所有 Java 服务的线上问题从系统表象来看归结起来总共有四方面:CPU、内存、磁盘、网络。例如 CPU 使用率峰值突然飚高、内存溢出 (泄露)、磁盘满了、网络流量异常、FullGC等等问题。
所以,本文从以下四个角度,去分析如何排查线上问题,如果你也遇见过上面的这些问题,却无从下手相信你看完这篇文章,能够掌握线上问题的排查思路与工具方法,方便你遇到线上问题时,心中有数,不慌不忙,赶紧mark起来吧。
CPU,CPU使用率飙升,如何定位
内存,内存溢出、垃圾回收的问题排查思路与工具
IO,IO异常时,如何定位
网络,网络卡顿,网络不通的排查思路
先说结论,大部分工程师也许没有全面的性能问题诊断机会,解决线上问题,也没有所谓的银弹。多实践,多学习底层原理,才能让你拥有更丰富的经验。
使用到的工具
系统Mac OS 14.3 Jprofiler 14.0版本
一、问题定位
1、CPU
CPU 是系统重要的监控指标,能够分析系统的整体运行状况。监控指标一般包括运行队列、CPU 使用率和上下文切换等。
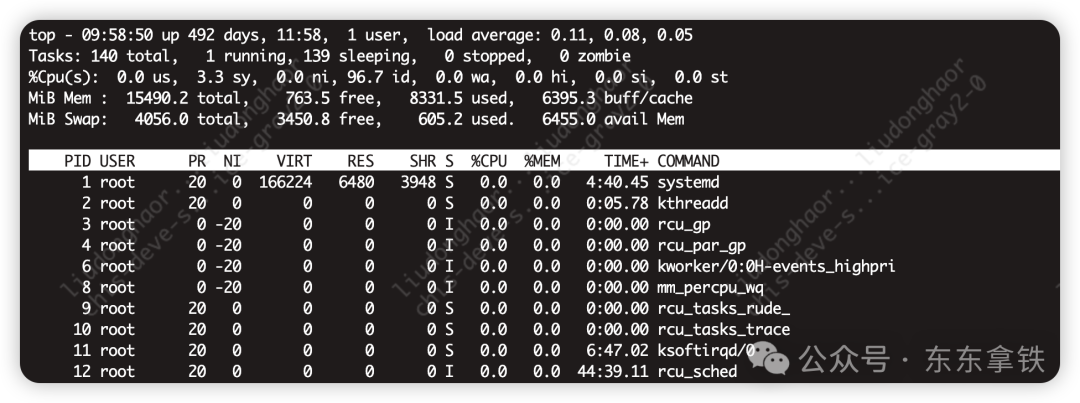
top 命令显示了各个进程 CPU 使用情况 , 一般 CPU 使用率从高到低排序展示输出。其中 Load Average 显示最近 1 分钟、5 分钟和 15 分钟的系统平均负载,上图各值为0.11,0.08,0.05
我们一般会关注 CPU 使用率最高的进程,正常情况下就是我们的应用主进程。第七行以下:各进程的状态监控。
关于线上的CPU问题,常见的问题有以下三种
CPU突然飙升
CPU使用居高不下
cpu占用高
往往都是业务逻辑问题导致的,比如死循环、频繁gc或者上下文切换过多。线上问题排查,为了能够保持现场情况,一般我们直接登陆机器,使用命令行进行排查。
当然,为了方便你更好的理解,我也提供了一个简单的示例代码,如下所示。
public class CpuTests {public static void busyThread(){Thread thread = new Thread(() -> {while (true){}},"*busyThread");thread.start();}public static void lockThread(Object lock){Thread thread = new Thread(() -> {synchronized (lock){try {lock.wait();}catch (InterruptedException e){e.printStackTrace();}}},"lockThread");thread.start();}public static void main(String[] args) throws IOException {BufferedReader bufferedReader= new BufferedReader(new InputStreamReader(System.in));bufferedReader.readLine();busyThread();bufferedReader.readLine();lockThread(new Object());}}
2、命令行排查
我们使用top -H -p pid来找到cpu使用率比较高的一些线程
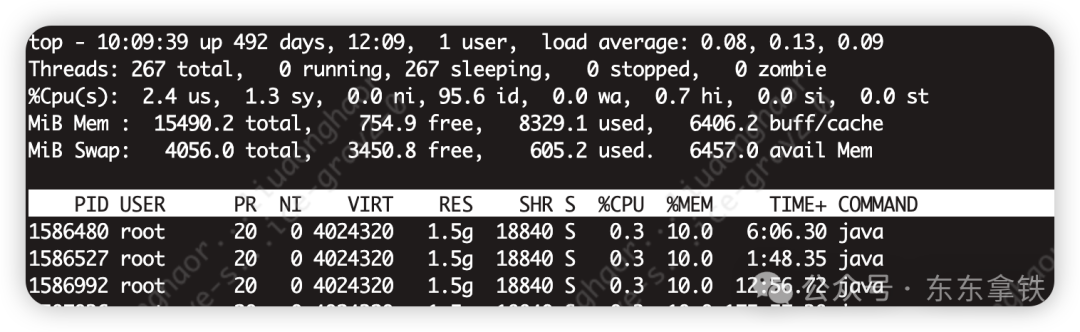
占用率最高的线程 ID 为 1586480,将其转换为 16 进制形式 (因为 java native 线程以 16 进制形式输出)printf '%x\n' 1586480pid得到nid
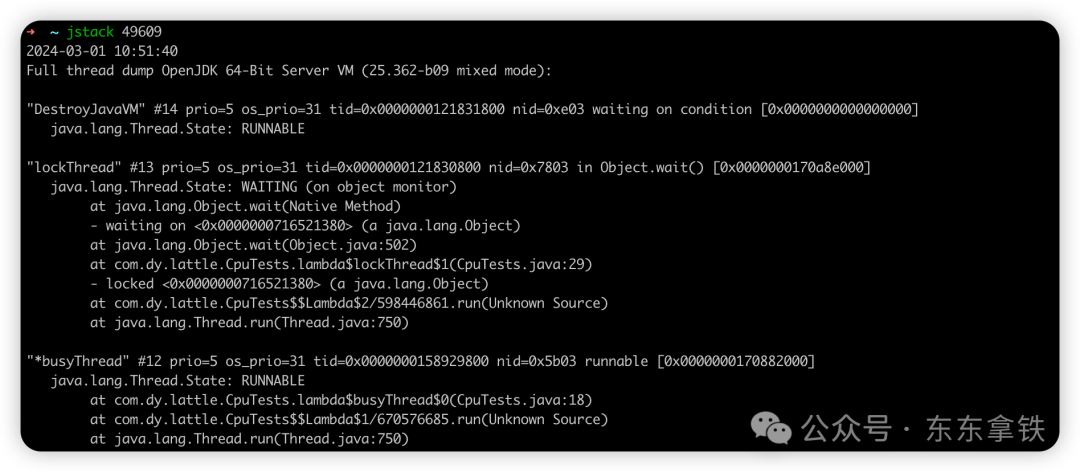
接着直接在jstack中找到相应的堆栈信息jstack pid |grep 'nid' -C5
注:因为我本地环境是Mac Os,且我们上面的例子比较简单,我们直接使用jstack 也可以看到线程情况
3、可视化工具
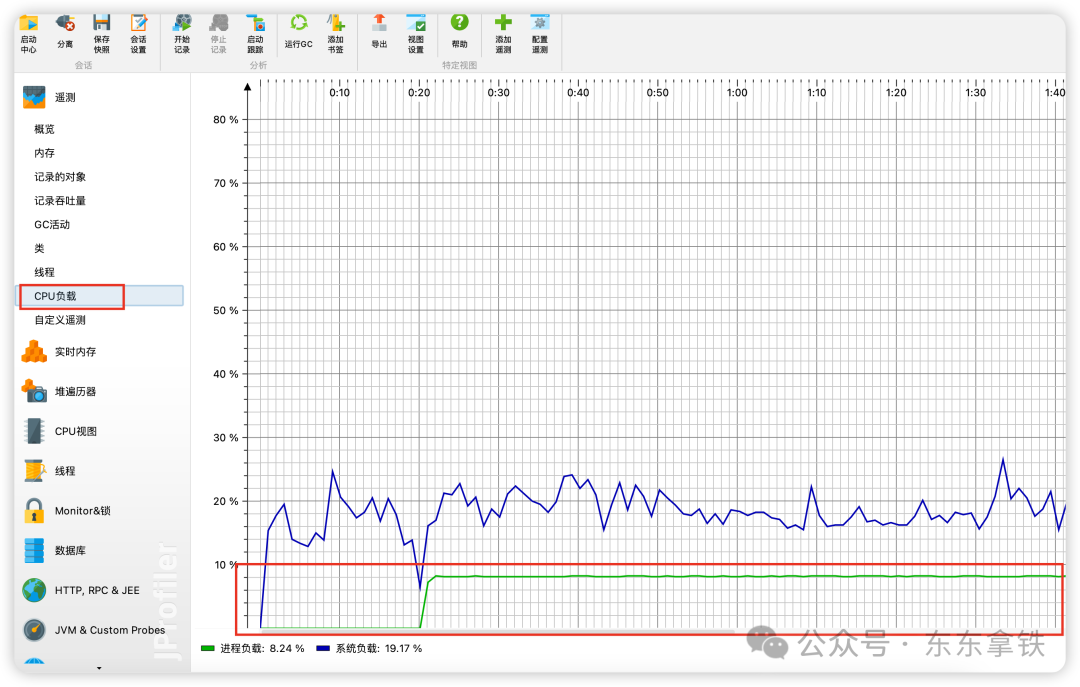
当然,也可以使用工具,直接可视化的查看线程情况
通过Jprofiler的cpu负载,我们可以看到cpu负载一直巨高不下,如果排除了流量上涨的可能性,那就需要排查代码存在的问题。
4、小结
当然,CPU问题,远远不是我上文例子这么简单,我们也仅仅介绍了最初级的问题排查思路。也有许多的工具,适合不同场景下的问题排查思路,比如:
vmstat,是一款指定采样周期和次数的功能性监测工具,我们可以看到,它不仅可以统计内存的使用情况,还可以观测到 CPU 的使用率、swap 的使用情况。但vmstat一般很少用来查看内存的使用情况,而是经常被用来观察进程的上下文切换。
pidstat,之前的 top 和 vmstat 两个命令都是监测进程的内存、CPU 以及I/O使用情况,而pidstat命令则是深入到线程级别。
多种工具结合,逐步缩小问题范围,才是真正解决问题的处理方法,当然,更多的工具留给你自己去做尝试了。
二、内存调优
线上内存,常见的有下面三类问题
内存溢出
内存泄漏
垃圾回收导致的服务卡顿
新生代 ( Young ) 与老年代 ( Old ) 的比例的值为 1:2 ( 该值可以通过参数 –XX:NewRatio 来指定 )
1、内存溢出
什么是内存溢出
当程序需要申请内存的时候,由于没有足够的内存,此时就会抛出OutOfMemoryError,这就是内存溢出。
下面我们来看一个例子
public class OomTests {static class OOMObject{public byte[] placeholder = new byte[640*1024];}static class OOMObject{public byte[] empty = new byte[64*1024];}public static void add(int num) throws InterruptedException {List<OOMObject> list = new ArrayList<>();for (int i =0;i<num;i++){Thread.sleep(500);System.out.println(i);list.add(new OOMObject());}System.gc();}public static void main(String[] args) throws InterruptedException {add(1000);}}
如下图可以看到,内存使用量持续飙升,超出最大堆容量后,出现OOM。
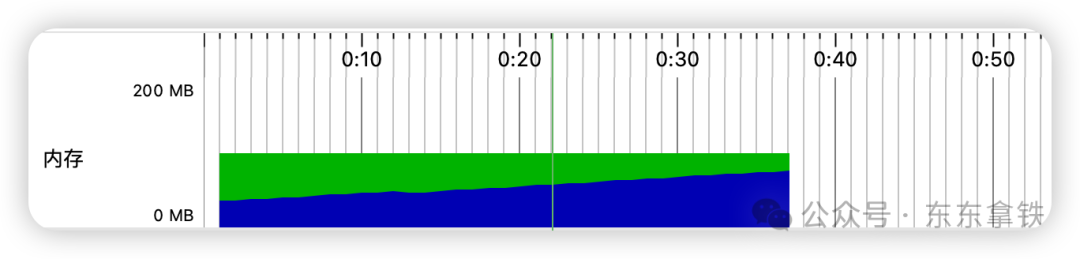
当然,可视化工具也可以直接看到出现OOM的堆栈情况。
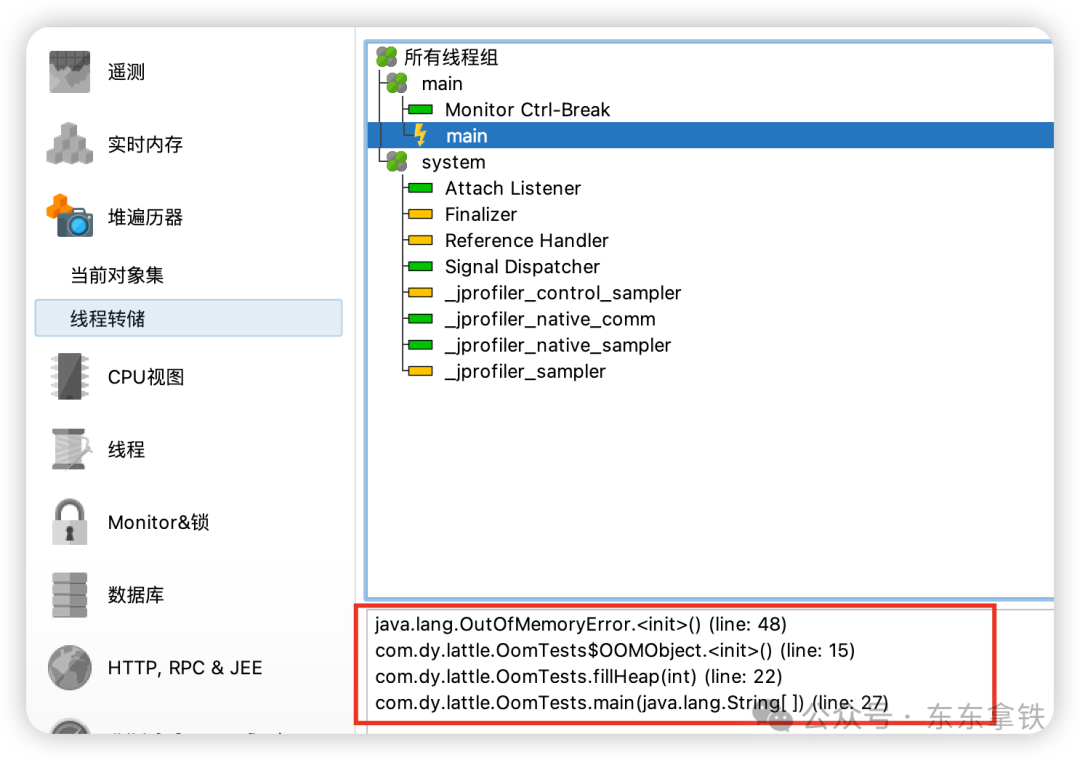
当然,上面只是本地的一个测试demo,方便演示工具如何使用。线上OOM问题排查,我们有两种方式
使用jmap命令生成dump文件jmap -dump:live,format=b,file=heap.hprof <pid>
JVM启动参数增加参数,当应用抛出OutOfMemoryError 时自动生成dump文件-XX:+HeapDumpOnOutOfMemoryError
通过Jprofiler,打开dump文件
选择最大对象,即可看到dump文件中最大的对象,也可以看到具体的引用情况。
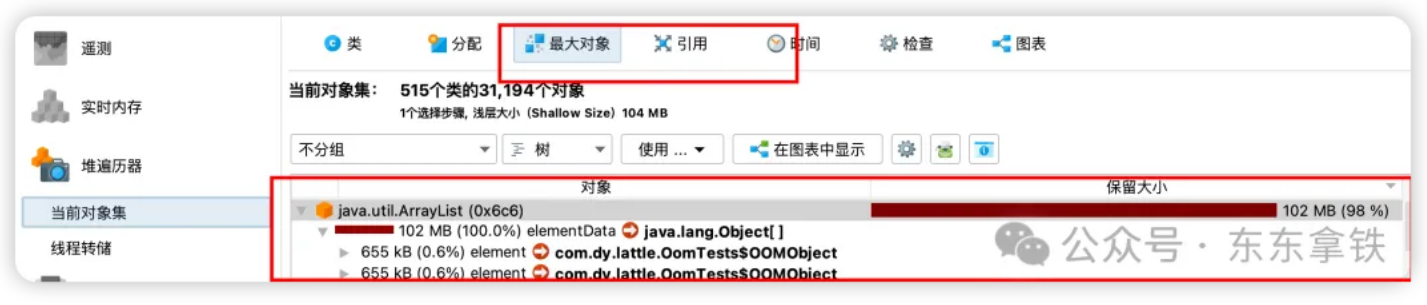
2、内存泄漏
内存泄漏指程序运行过程中分配内存给临时变量,用完之后却没有被GC回收,始终占着内存,即不能使用也不能分配给其他程序,就叫做内存泄漏(也就是相当于占着内存却不能被管理到造成内存的浪费) 内存泄漏短期内或者说轻微的不会有太大的影响,但内存泄漏堆积起来后却会很严重,会一直占用掉可用的内存,从而出现内存溢出的现象。
常见问题
可以复用的对象,每次都new,但也不会回收,比如客户端连接
文件流操作,但是没有正常关闭
排查思路可以参照上面内存溢出的情况,排查大对象即可
3、G1垃圾回收器
关于垃圾回收,常见问题主要有两点
时间过长,垃圾回收存在STW,时间过长则会导致影响请求
Full GC次数过多
我们的调优目标,自然也是围绕这两个来
响应速度
合适的吞吐量
G1(Garbage-First)是在JDK 7u4版本之后发布的垃圾收集器,并在jdk9中成为默认垃圾收集器。通过“-XX:+UseG1GC”启动参数即可指定使用G1 GC。从整体来说,G1也是利用多CPU来缩短stop the world时间,并且是高效的并发垃圾收集器。
排查垃圾回收问题,启动服务时一定要加上如下四个参数
-XX:+PrintGCTimeStamps :打印 GC 具体时间;-XX:+PrintGCDetails :打印出 GC 详细日志;-Xloggc:/log/heapTest.log GC日志路径-XX:+UseG1GC 使用G1垃圾回收器
分析系统运行情况
系统每秒请求数、每个请求创建多少对象,占用多少内存
Young GC触发频率、对象进入老年代的速率
老年代占用内存、Full GC触发频率、Full GC触发的原因、长时间Full GC的原因
主要工具jstat,如下命令就是监控gc情况,每秒采样一次,采样10次
jstat -gc 44017 1000 10
为了方便大家看到区别,我手动出发了一次full gc,大家也可以明显看到,FGC从0变为了1。

S0C/S1C、S0U/S1U、EC/EU、OC/OU、MC/MU分别代表两个Survivor区、Eden区、老年代、元数据区的容量和使用量。YGC/YGT、FGC/FGCT、GCT则代表YoungGc、FullGc的耗时和次数以及总耗时。如果看到gc比较频繁,再针对gc方面做进一步分析。
三、磁盘&IO
笔者主要做的都是web服务,几乎不涉及到读写文件,最多也就是日志打印会设计到io,但是这块由于框架优化,几乎没有太多的性能损耗,个人也没排查过io相关的问题,在这里仅作一个命令的介绍。
如果你有线上IO问题排查经验,也欢迎评论区与大家交流
df -lh 查看磁盘使用情况
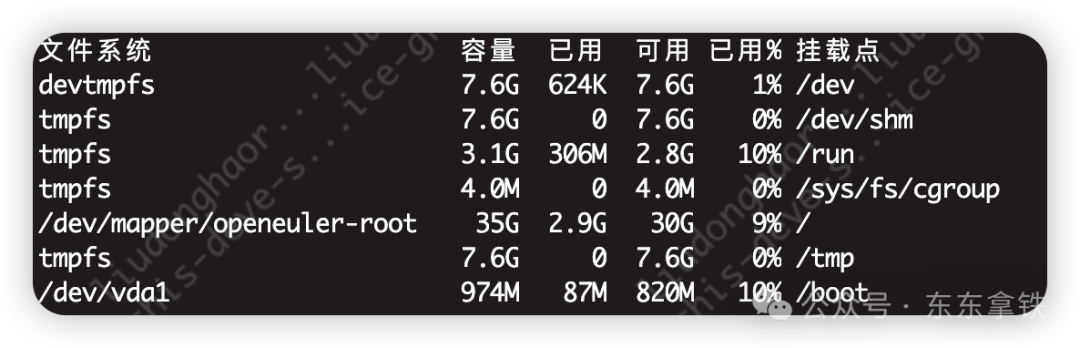
iostat 查看磁盘io
四、网络
1、查看TCP连接情况
常见问题 tcp队列溢出netstat -s |egrep "listen|LISTEN"
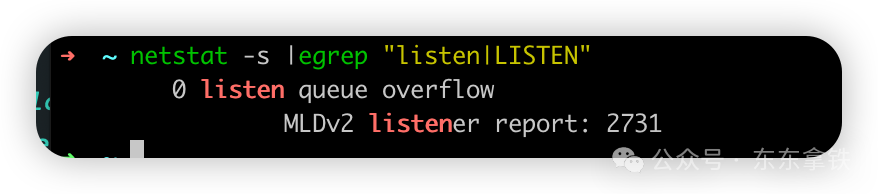
overflowed标识全连接队列溢出的次数,最前面是0,标识没有队列溢出的情况,网络环境正常。
2、网络是否连通
常见问题
rpc服务连接不上
数据库、Redis中间件连接不上
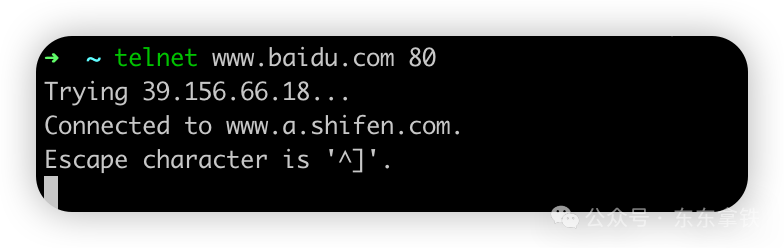
使用telnet ip/域名 端口号 来查看网络是否连接
如果出现下图内容,则证明网络已经连接
五、说在最后
关于本文给出的例子,你一定要实践一遍,都非常的简单,亲自去使用文中提到的工具,只有实践了,你才是真正入门了。
在一些比较简单的业务场景下,排查系统性能问题相对来说简单,且容易找到具体原因。但在一些复杂的业务场景下,比如开源框架下的源码问题,相对来说就很难排查了,有时候通过工具只能猜测到可能是某些地方出现了问题,而实际排查则要结合源码做具体分析。
线上问题排查可以说没有捷径,排查线上的性能问题本身就不是一件很简单的事情,除了将今天介绍的这些工具融会贯通,还需要我们不断地去累积经验,才能够快速成长。
不知道你在工作中,有没有线上问题排查的经历呢,或者还有没有其他的坑想与别人分享呢?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721