
评估过程与评估结果
作为解决大模型幻觉的利器,RAG的搭建简单,成本低,现在也有各种开源的RAG工具,像Langchain-chatchat、ragflow、qanything等,不用懂编程,直接就能上手部署。
不过这么多RAG工具,到底该怎么选?或者我们自己编写一个RAG,怎么知道好坏?
如何评估RAG的好坏是绝对绕不过的一个话题。
评估RAG除了能帮助我们选择更适合RAG工具,还能在优化RAG的时候让我们有据可依,通过评估可以知道应该如何优化和调整参数。
不过如何评估一个RAG可是个复杂的问题,大模型的结果不是固定的,就意味着这不是一道判断题或者数学题,每个问答都是作文题。
为了解决这个复杂的问题,一般评估可分为按组件评估(评估过程)和端到端评估(评估结果):
按组件评估就是把RAG看做一个工厂流水线,通过评估流水线中各个组件的性能,然后把这些组件的结果汇总成一个总的得分。
比如可以通过上下文相关性(问题和检索结果的关联程度)和上下文召回率(是否找到了最相似的结果)来评估检索阶段的成绩,通过答案和问题的相关性、答案和检索内容的相关性和正确性来评估生成阶段的结果是否及格。
组件评估一般是在测试阶段,可以便于通过设定标准答案和错误答案的数据集来详细验证RAG的结果。
端到端评估(结果评估)也至关重要,因为它直接影响用户体验。一般通过评估忠诚度(衡量了生成的答案在给定的上下文中的事实一致性)和答案正确性(避免错误的答案或者错误的格式)来评估流水线整体性能的度量标准。
评估框架
但是这些指标需要怎么应用在RAG程序里呢?别担心,有现成的。
Trulens
TruLens是一款旨在评估和改进 LLM 应用的软件工具,它相对独立,可以集成 LangChain 或 LlamaIndex 等 LLM 开发框架。它使用反馈功能来客观地衡量 LLM 应用的质量和效果。这包括分析相关性、适用性和有害性等方面。TruLens 提供程序化反馈,支持 LLM 应用的快速迭代,这比人工反馈更快速、更可扩展。
开源链接:https://github.com/truera/trulens
使用手册:https://www.trulens.org/trulens_eval/install/

使用的步骤:
(1)创建LLM应用
(2)将LLM应用与TruLens连接,记录日志并上传
(3)添加 feedback functions到日志中,并评估LLM应用的质量
(4)在TruLens的看板中可视化查看日志、评估结果等
(5)迭代和优化LLM应用,选择最优的版本
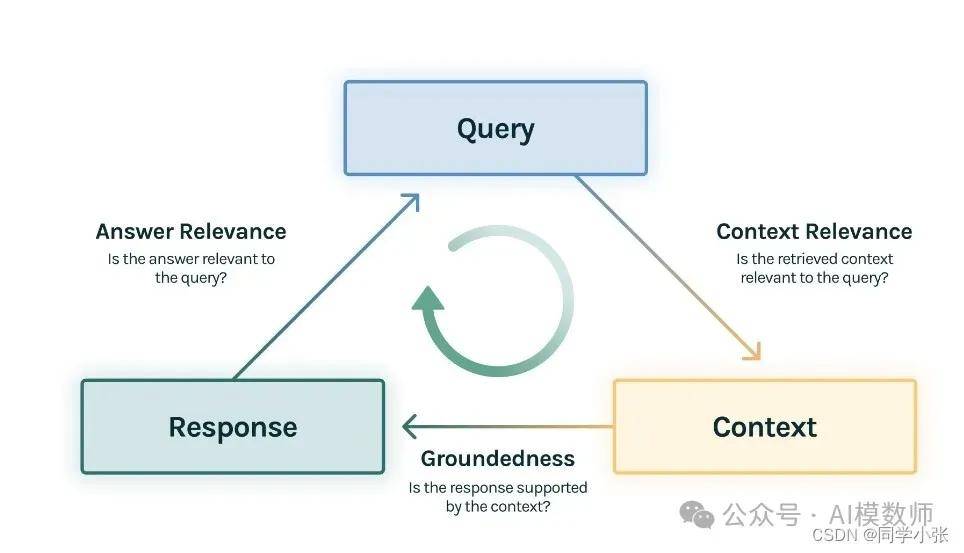
其对于RAG的评估主要有三个指标:
上下文相关性(context relevance):衡量用户提问与查询到的参考上下文之间的相关性
忠实性(groundedness ):衡量大模型生成的回复有多少是来自于参考上下文中的内容
答案相关性(answer relevance):衡量用户提问与大模型回复之间的相关性
TruLens的好处就是对RAG的评估不需要有提前收集的测试数据集和相应的答案。
RAGAS
RAGAS应该是最著名的RAG评估框架了,最初是作为一种无需参照标准的评估框架而设计的。这意味着,RAGAs 不需要依赖评估数据集中人工标注的标准答案,而是利用底层的大语言模型进行评估。
RAGAS包含四个指标,与Trulens的评估指标有些类似:
评估检索质量:
context_relevancy(上下文相关性,也叫 context_precision)
context_recall(召回性,越高表示检索出来的内容与正确答案越相关)
评估生成质量:
faithfulness(忠实性,越高表示答案的生成使用了越多的参考文档(检索出来的内容))
answer_relevancy(答案的相关性)

自动化评估
虽然有了评估的标准和工具,但是上面的方法只是告诉我们这些指标的结果。就像去医院体检一样,但是体检结果还是看不懂啊。但是RAG去哪找大夫解读呢?
最传统的方式还是进行人工评估,通过邀请行业专家或人工评估员对RAG生成的结果进行评估。他们可以根据预先定义的标准对生成的答案进行质量评估,如准确性、连贯性、相关性等。
这种评估方法可以提供高质量的反馈,但可能会消耗大量的时间和人力资源。只适合在测试评估阶段使用,在生产环境的监控中,可没办法一直依靠人工评估。自动化评估肯定是RAG评估的主流和发展方向,现在最常用的就是LangSmith和Langfuse了。
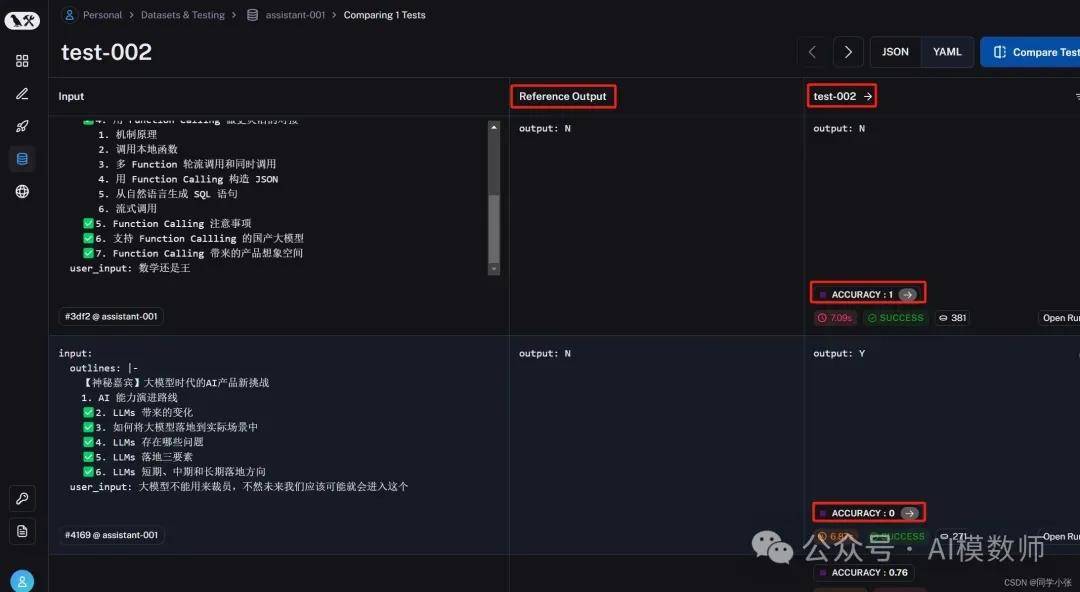
LangSmith
LangSmith是一个用于调试、测试和监控LLM应用程序的统一平台。会记录大模型发起的所有请求,除了输入输出,还能看到具体的所有细节,包括:
请求的大模型、模型名、模型参数
请求的时间、消耗的 token 数量
请求中的所有上下文消息,包括系统消息
Langfuse
Langfuse作为LangSmith的平替,可以帮助开发者和运维团队更好地理解和优化他们的LLM应用。通过提供实时的和可视化的跟踪功能,LangFuse使得识别和解决应用性能问题变得更加简单和高效。
主要是基于可观察性和分析技术来监控和优化 LLM 应用。它提供了一套完整的解决方案,通过收集、处理和分析 LLM 应用在运行过程中产生的各种数据,来生成实时的结果。
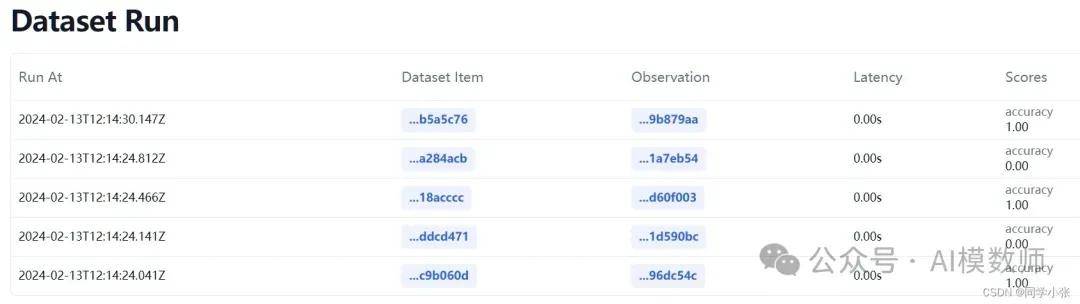
以上两个平台对RAG的评估,都可以自定义自己的评估函数。当然其也支持一些内置的评估函数。不仅可以开箱即用,还支持持续迭代和定制化,绝对 LLM 运维过程中必不可少的工具。
总结
随着人工智能技术的飞速发展,RAG工具的评估和优化已成为我们不可或缺的技能。TruLens、RAGAS、LangSmith和Langfuse等工具的出现,为我们提供了强大的支持,让我们能够更精准地评估和优化LLM应用,推动AI技术的进步。让我们携手并进,共同探索AI的无限可能!
在这个AI为王的时代,评估不再是选择题,而是必答题。掌握它,你就掌握了开启智能世界的钥匙。
如果未来的AI能够自我评估和优化,我们人类的角色将会怎样转变?是成为旁观者,还是成为引导者和创造者?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721