
关键词:分布式交易系统;统一监控;指标数据模型;librdkafka网络库
一、引言
海通证券新一代交易系统采用分布式总线架构,每个系统实例(即单节点,下文简称交易节点或节点)由若干组应用组件构成。生产环境部署多套交易节点,存在不同节点跨广域网(如异地机房)的情况。为了能对各节点各组件的运行情况统一观测,在满足预设条件时及时预警,我们设计实现了统一监控系统,图1为运行图例。本文对面临的问题和解决方案做一个设计回顾,总结实践后的经验和思考。
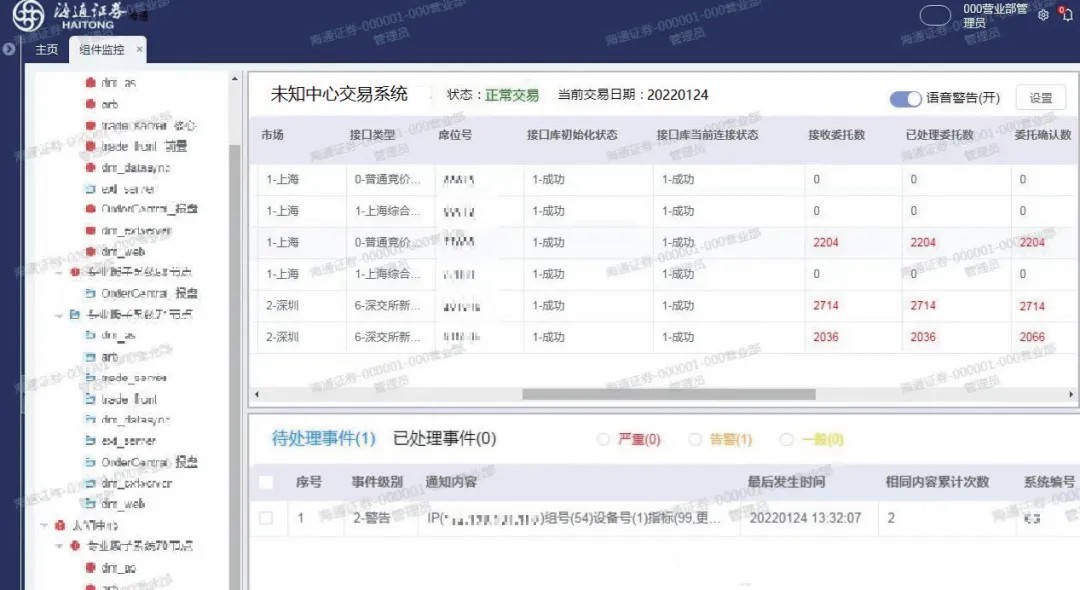
图1 统一监控系统运行图例
监控系统的设计目标是统一、实时、量化,借此保证分布式交易系统在生产环境的平稳运行。统一是指对所有节点、所有组件通过一个统一的入口监控。实时是指能在秒级延时内观测到被监控对象的监控指标。量化是指监控指标的数字化。
同时,在监控系统实时可观测、可统计的数据支持下,促进分布式交易系统在高可用、低延时等方面的迭代演进。
本系统的监控对象是交易节点内各组件进程的内部技术和业务指标。
对于公司统建监控(e海智维)已经聚合的应用系统无差别指标,如服务器操作系统磁盘、网卡、内存、CPU等监控,不做重复监控。
二、监控目标
分布式交易系统面临各组件监控指标各异、应用日志总量大、多节点跨广域网如何统一监控等问题,本章通过对监控对象分析,设计监控指标的数据模型,解决指标各异问题。然后本着对被监控对象侵入性最小的原则,对多节点、跨广域网的分布式交易系统,设计监控数据流,解决统一监控问题。
以一个交易节点为例,假设节点由n类组件构成,可视为m个进程。实际监控对象是这m个进程。
每类组件有自己的技术和业务指标,通过一个二元组(group_id, idx_key)及其device_id可表示节点内某个唯一的指标,其中group_id表示哪一类组件,idx_key是表示指标名。比如(25,pid)表示交易核心的进程号指标。device_id表示组成员编号,是指标的实例所以不必在本质的二元组内。
在实践中,我们发现有的组件情况稍复杂。比如报盘,group_id为53,假设二元组(53,1001)表示报盘的委托确认数,(53,1002)表示报盘的委托成交数。由于报盘应用对渠道(按对接的交易所网关类型分类) 、席位、交易所后端平台等参数可配置,我们希望被监控的指标能进一步细分,体现出不同报盘通道下的委托确认和成交数,比如我们想知道同一个报盘应用内上交所竞价、上交所综合、深交所竞价平台各自的委托确认数。所以唯一指标进一步调整为(group_id,idx_key, idx_subkey)三元组,为了兼容用不到idx_subkey的指标,idx_subkey被设计为数组的秩。用不到idx_subkey的指标,其值为0。对于报盘组件,idx_subkey就是报盘通道对应的通道数组下标。如,(53,1001,1)表示通道1的委托确认数,(53,1003,1)表示通道1的交易所接口类型,假设这里取值表示上交所竞价接口,(53,2001,1)表示通道1的席位信息S1,即上交所竞价的席位S1,他们都是通道1的细化指标,细到可以满足监控需求。
确定数据模型后,各类组件就可以按这个三元组的形式列出指标清单了。
本着对被监控对象侵入性最小的原则,交易节点内各进程通过日志文件输出2.1节设计的指标。然而单组件应用日志总量大(几十GB)且不可控,如果监控指标追加到应用日志中,显然浪费传输带宽和解析算力。因此我们设计了指标数据通过独立的监控日志文件数据流发布,由监控消费端组件聚合订阅消费,是典型的发布/订阅数据流模型。按单组件所有指标打印一次需1024字节、每5秒打印一次计算,独立监控日志每日的固定输出量为17.7MB。发布者除了从监控日志采集,还可从数据库等持久化介质采集。
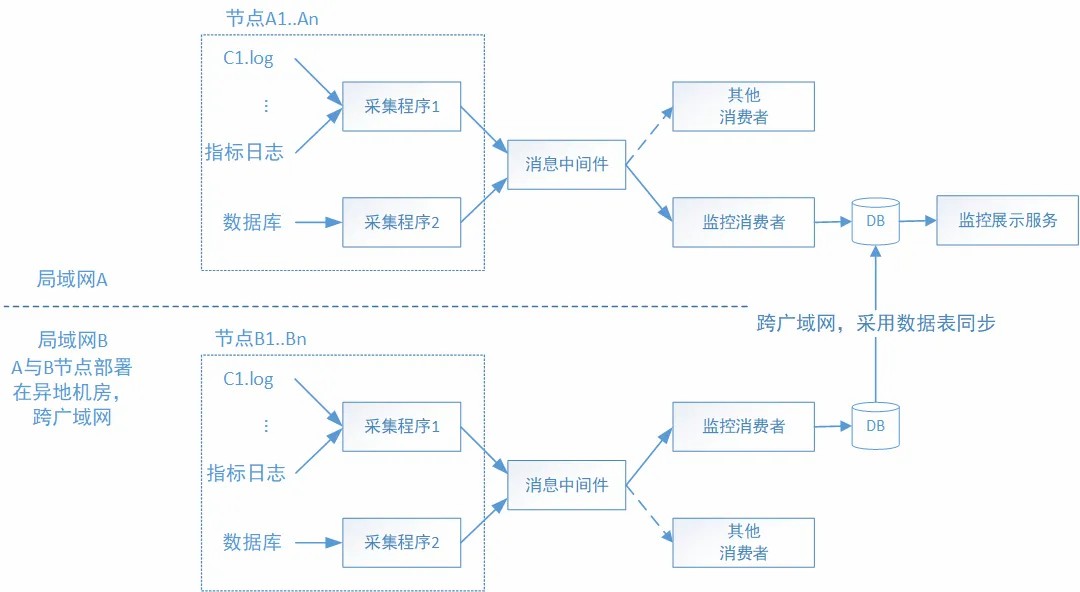
图2 监控处理数据流
分布式交易系统在生产环境,存在多个实例(即多个交易节点)跨异地机房部署。若只部署一个监控程序订阅所有机房的数据,存在数据量较大的跨广域网传输,在交易时间占用宝贵的网络带宽资源。为解决跨广域网节点的监控成本问题,同时考虑对所有节点统一监控入口的目标,我们设计了同一局域网内,采用发布/订阅数据流;跨广域网,把各局域网内监控消费者的处理结果,同步给主监控数据库,如图2所示。按每个指标物理表记录248字节计算,97个指标数据量预估约25KB/每5秒(因为源端每5秒输出一次指标快照)。同步处理结果的数据量可控,较直接消费原始指标的数据量大幅减少。
三、架构设计
在明确监控数据流后,为简化新增节点引发的监控部署问题,本章提出并重点介绍同一局域网内的监控发布/订阅环节数据流的系统架构,以及订阅端组件依赖的关键技术。
基于2.2节的订阅/发布数据流,在局域网内监控发布/订阅环节架构如下。
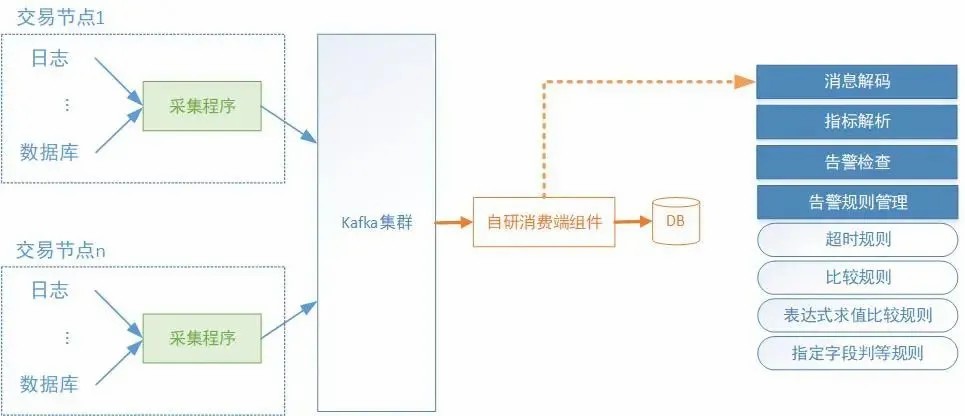
图3 监控发布/订阅环节的系统架构图
图3中,日志采集程序部署在每台被监控组件所在的服务器上。我们通过对采集程序的配置,增量扫描所需文件内容并发布到Kafka集群。
Apache Kafka是一款分布式消息总线,最初被设计用来解决LinkedIn公司内部的数据流问题。在海通证券,Kafka作为基础软件设施,应用在实时盯盘系统等多个场景。
订阅者采用我们自研的监控消费端组件。该应用基于C++编写,使用了两项关键技术栈,librdkafka网络库和海通自研的内存库。
监控消费端组件作为主题的消费者,需要和Kafka集群通讯并处理各种网络和来自Kafka集群的异常。为了降低开发难度,我们选用了librdkafka。
librdkafka是一款Kafka的客户端库,底层使用C实现Apache Kafka协议,对应用层提供生产者、消费者和管理者的API接口,由Magnus Edenhill设计实现并作为主要维护者。
从消费客户端角度,librdkafka内部设计实现了与Kafka broker之间的TCP通讯及应用层缓冲区管理、Apache Kafka协议,提供了便于应用开发的配置、主题订阅、消息回调、Rebalance事件回调、日志回调、统计回调等API。
作为消费者应用,使用librdkafka主要关注3件事。
第一件是设置bootstrap broker(启动代理服务器),也就是给谁发metadata(元数据)请求。Metadata请求由客户端发起,用来获取客户端关心的主题,应该从哪些broker请求。在metadata应答里,包括这些主题有哪些分区,每个分区有哪些副本,主副本在哪些broker等信息。任何一台broker都有这些metadata信息。在自研应用设置bootstrap broker时,一般设置1个以上,作为备选。
第二件事是订阅主题。在Kafka集群中,每个主题是分区的,每个分区可以有多个副本,其中只有一个主副本。每个副本存储在不同的broker。所有的主题消费和生产请求,都是给到主副本所在的broker。从副本只负责从主副本同步。在librdkafka收到metadata应答时,就知道哪些主题从哪些broker获取,并且创建与该broker通讯的线程、定时器、线程间通讯队列等资源。
第三件事是获取订阅消息。librdkafka使用FetchRequest请求获取订阅的消息,并通过rd_kafka_consumer_poll方法通知应用层。librdkafka通过重定向队列,将各个broker通讯线程收到的消息重定向到应用层消息队列,简化了应用层的处理。
另外librdkafka还考虑了Rebalance(消费端负载均衡)场景的处理。自研应用由于设计时对消息容量的控制,暂没必要考虑多个实例并行消费同一个主题。
通过使用librdkafka,阅读其源码,我们对如何使用Kafka有了更深的理解。
监控消费端组件使用海通自研的内存库处理Kakfa消息,以及处理结果的持久化。内存库的使用极大地提高了消费端的处理能力,保证了监控的实时性。
这套内存库基于共享内存,支持将从物理库中加载关系表到内存,并按需构建内存表索引。索引支持哈希和红黑树两种,可分别用于匹配查询和范围查询。内存库支持事务语义,并提供跨线程异步持久化的能力。
在该组件设计中,对容量可预估的数据,如指标结果、告警规则等,采用内存库快速查询、更新。对告警通知等容量不可预估的数据,不采用内存表,而通过跨线程队列持久化。
四、应用设计
监控应用需要根据各种规则预警,为减少因组件指标调整或监控规则改变引发的频繁升级问题,我们希望未来不管新增多少组件,只要按照约定的指标数据模型,配置或者快速修改极少量的代码就能发挥监控作用。本章介绍在自研消费端程序的应用层关键设计。
消息解码器是对JSON(JavaScript Object Notation)格式消息的解析。由于我们采用JSON作为Kafka消息的格式,按不同采集源根据约定的JSON格式解析提取消息。比如,日志采集消息解码器等。
对于约定的消息格式,这些(编)解码类,存在复用到其他项目的可能。
为了尽可能收敛n个组件m个指标带来的测试工作量,我们设计了指标解析器和告警检查器类。
指标解析器是对指标数据模型的解析,解析结果是生成2.1节数据模型下的KV(Key,Value)键值对。
之所以设计这个类是因为我们注意到对于每一类组件,指标解析后的目的是将一个个(K,V)对的指标,做告警检查。从消息解码器获取的指标原始串,在应用层的处理代码可简化为类似迭代器的方式处理。
为此,我们设计了CIParser基类,定义Next方法作为接口。子类采用接口继承,不同组件的解析器根据自己的指标格式特点提供逐个指标。解析特点不同的组件,只要继承CIParser,实现独有的指标解析就可以了。
对于指标解析的测试,也收敛为对CIParser继承类Next方法的单元测试。
告警规则引擎是指对解析出来的指标,根据告警规则,做检查决定是否告警。
告警规则采用内存表存储计算,支持盘中修改后实时加载到内存表,目前支持的告警规则有:
(1)无规则。
(2)比较规则。可用于数值型和字符型比较。
(3)超时规则。用于指标多久没更新。
(4)与指定表指定字段的判等规则。如用于版本号不匹配的告警。
(5)表达式求值比较规则。即根据表达式求值,再使用比较规则。如用于内存表容量监控。
告警检查类的设计是无状态的,提供规则检查接口。为支持连续n次告警,将持久化告警信息接口分离出来单独提供。
回归测试只要在充足的指标和规则案例支持下,对检查接口执行单元测试就可以满足我们最初希望的测试收敛。
五、性能
本节我们针对监控应用,分别测算了librdkafka压力测试和自研消费端组件的业务处理性能。结果如下:
表1 测试环境librdkafka性能数据

压力测试选取了两类典型的组件,在没有对librdkafka做任何参数调优的情况下获得数据。从结果分析,librdkafka(1.5.0)本身的吞吐量和延时足以满足监控需要。
表2 测试环境业务处理性能数据

该数据为自研消费端程序在收到librdkafka消息后的业务处理耗时,是基于内存表单线程处理的数据。
注1:以上测试使用3节点集群Kakfa,3副本。
注2:测试服务器配置:CPU Skylake 2.6GHz * 8,内存16GB,HDD 200GB。
注3:组件B的指标比组件D少,但平均耗时长,因为组件B的指标格式解析更耗时。
六、优化
结合设计和性能测算的观察,自研消费端组件的性能有以下优化方向:
一是日志库的优化。测试发现同步日志模式,在高吞吐量消息时会阻塞正常的执行流程,日志库需采用异步模式。该优化已完成,日志性能为10个线程每个线程写20万条记录,共耗时0.7秒。
二是支持指标多线程并行处理。
三是内存库锁机制优化,目前内存库的锁是进程级别的,多线程的优势被稀释,实现好内存库锁机制能极大提高并发处理能力。
四是要设计好的监控业务模型降低业务复杂度。比如每个系统节点的相同组件指标告警规则可能不同,在没有设置规则时采用兜底设置,兜底还分好几个业务优先级。再比如,有些指标在告警事件处理后,后续的告警就算是从头开始了,而有些则不能一笔勾销。随着业务场景的需求增加,需要合理设计数据结构和查找算法,来提高监控处理性能。
五是librdkafka参数调优,配置项多达100+。
七、总结
应该说,基于Kafka设计监控系统在业界并不是新的思想,但不同于使用Java技术栈的Storm,Kafka Stream等架构,我们首先对被监控对象做了数据模型分析,把“大”数据控制在有用的“小”数据来消费,而这些“小”数据通过轻量级的消费者消费更合适。选择C++技术栈的内存库,开源的librdkafka,使得多节点交易系统的监控仅需部署若干个自研消费端组件就可以做到。
在本次实践中,我们使用了librdkafka,Kafka等开源代码和软件。在了解原理后,也给了我们很多新的灵感,比如日志采集程序的实现原理是否可以用在证券静态行情导入,Kafka+librdkafka+数据验证的组合是否能够用来解决系统间数据交互的痛点。同时我们也深刻意识到,用好开源技术关键是不断学习实践,拥有与之匹配的设计实现能力。
最后回到监控的初心,分布式交易系统监控的目的是能够第一时间发现异常,而这些异常也促使我们思考如何设计出能够自动从异常恢复的分布式交易系统。
参考资料
[1] Neha Narkhede,Gwen Shapira,Todd Palino. Kafka The Definitive Guide. OReilly. 2017
[2] William P.Bejeck Jr.Kafka Stream In Action. Manning. 2018
[3] 邓俊辉. 数据结构(C++语言版). 清华大学出版社. 2013








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721