
本篇针对消息积压的解决过程进行了极其详尽的记录,从思路、代码、优化一条龙服务,手把手教学,让你看到网上找不到的实操细节,更有多个真实问题解决的案例。
作者介绍
云雨雪,一台无情的编码机器,一个写博客的乐子人,梦想是让这痛苦压抑的世界绽放幸福快乐之花,向美好的世界献上祝福。个人公众号《神独自在的技术生活》。
前言
之前就遇到的一个问题吧,发生过一两次了,每次都是重启等着慢慢消费,但这样肯定是不行的啦,还是得上点魔法。
按照既往惯例,我都会在文章选题开始时,看看网上大家都是怎么写的,看了不少文章吧,感觉大家写的还是比较抽象。(⊙﹏⊙),不过可能也是因为消息积压这一块吧,这个解决方案属实是太过简单,确实也没啥好说的,导致大家这个不怎么贴代码,老是讲思路,我也能够理解。但是作为好家伙棒小伙,我肯定得给大家端上一碗热腾腾的鸡汤,直接开始吧,鸡汤来咯!
事件背景
之前我不是自己维护了一套日志收集系统嘛,是Filebeat+Kafka+数据处理服务+Elasticsearch+Kibana+Skywalking这样的架构,其中数据处理服务是一个spring boot项目部署在公司的DevOps平台上。因为是我自己弄的,我就自己建了一个项目空间,专门放我写的组件的源码以及这个数据处理服务,平时我也是在上面自己部署的,因为稳定运行一年多,平时也不关注。
几周前,不知道咋回事生产的那个节点挂了。周四晚上挂的,发的邮件通知我没看到(邮件太多就不看了),周五没人看日志,就这么到了周一下午,有同事过来问我为啥没有这几天的日志。我先登录Kibana看了下,确实少了这几天的日志,然后我就登录DevOps发现节点没了,上CMAK(Kafka监控)发现积压了八百多万数据,嚯嚯,小一千万,大的要来了。
宕机后的处理
首先告诉发现的小伙伴都别慌,小BUG小场面,先用DevOps上面自带的K8S日志输出看实时日志或者写命令看日志文件。
点击容器日志可查看实时输出的日志,如下图。我个人觉得这个其实也蛮方便的,但是要定位历史问题,或者要进行搜索、链路追踪啥的,就不如一套日志收集系统了。
因为我这个自己做的日志收集系统不是公司级的项目(架构组也在做,但是有技术问题,技术问题场景太多了,所以还没有完全推广),大概就我们大组几十个开发在使用,应用到了二十多个子系统上,目前日志量已经增长到了月度亿级。

因为我会在代码规范中明令禁止测试或者正式环境打印SQL,所以日志量总体还算是可控。再加上我之前在数据处理服务中写了定时,定期删除半年以上日志,因此磁盘表示它状态良好。万幸的是,暂时没有遇到太大问题,但是后续可能要考虑压缩历史日志归档的问题。
扯远了,回到正题,我马上重启了数据处理服务进行消费,由于原Topic只有3个分区,所以并发度是3。可能有的人会说为啥消费的时候不开多线程呢,开多线程批量插入ES就不受分区并发度限制了?对的,这是一个手段,但是我开启了手动提交offset,为了确保日志不丢失,所以这并发度没法提升了。
正式的环境不能乱动,但是测试的可以随便玩,那么这个消息积压的问题场景就由我收下了!解决思路如下,非常简单,但问题就在于细节非常多,网上的实践内容也相对偏少,所以我就想着通过文章的方式来复盘下我全部的操作。
修复现有consumer的问题,并将其停掉,再不停就真G了。
重新创建一个容量更大的Topic,比如patition是原来的N倍,大大大。
编写一个临时consumer程序,消费原来积压的队列(注意该consumer不做任何耗时的操作,仅作为中转将消息快速写入新创建的Topic里)。
将修复好的consumer部署到原来N倍的机器上消费新Topic。
消息积压解决后,恢复原有架构。
真实的操作场景复盘
这里无论是通过命令还是在可视化工具上创建,都可以啦,不管黑猫白猫,抓到耗子就是好猫。因为原来的Topic分区是3,这里可以选择提升10倍,改成30。但是我是选择了相对保守的12作为分区数,因为我这资源有限。
这里我们就在原数据处理服务直接写一个监听加中转就OK了。
("performanceKafkaTemplate")private KafkaTemplate<String, String> kafkaTemplate;(topics = {"log-zero-#{systemProperties['env']}"}, containerFactory = "testFactory")public void forwardTopic(List<ConsumerRecord<String, String>> records, Acknowledgment ack) {List<LogMsgDTO> logMsgList = new ArrayList<>(1024);records.forEach(record -> {ListenableFuture<SendResult<String, String>> sendListener =kafkaTemplate.send("log-zero-test", record.value());sendListener.addCallback(success -> {}, err -> {log.error("消息发送失败", err);});});ack.acknowledge();}
这里针对Kafka做了一个封装,用的是自己封装的高性能版生产者和测试版消费者。
首先改写一下原有的消费逻辑,因为之前是按月动态索引,所以消费消息时会先从redis中获取是否存在当月索引,现在我可以直接写死这个索引,新增即可,消费的代码如下。
(topics = {"log-zero-test"}, containerFactory = "testFactory")public void testLogListen(List<ConsumerRecord<String, String>> records, Acknowledgment ack) {List<LogMsgDTO> logMsgList = new ArrayList<>(1024);records.forEach(record -> {String value = record.value();String[] split = value.split("\\|");String system = split[2];if (split.length > 13) {String env = split[3];LogInfoDTO info = new LogInfoDTO();info.setCreateTime(split[0]);info.setLogType(split[1]);info.setSystem(system);info.setEnv(env);info.setLocalIp(split[4]);info.setRequestIp(split[5]);info.setTriceId(split[6]);info.setRequestUrl(split[7]);info.setRequestType(split[8]);info.setRequestMethod(split[9]);info.setUserId("null".equalsIgnoreCase(split[10]) ? "" : split[10]);info.setUserName(split[11]);info.setThreadName(split[12]);info.setMsg(split[13]);logMsgList.add(new LogMsgDTO("test-log-zero-uat-re", JSON.toJSONString(info)));}});if (!CollectionUtils.isEmpty(logMsgList)) {esService.bulkAddRequest(logMsgList);}ack.acknowledge();}/*** 批量新增日志*/public void bulkAddRequest(List<LogMsgDTO> msgList) {BulkRequest request = new BulkRequest();//等待批量请求作为执行的超时设置为2分钟request.timeout(TimeValue.timeValueMinutes(3));msgList.forEach(msg -> {request.add(new IndexRequest(msg.getTopic()).source(msg.getMsg(), XContentType.JSON));});zeroClient.bulkAsync(request, RequestOptions.DEFAULT, new ActionListener<BulkResponse>() {public void onResponse(BulkResponse bulkResponse) {for (BulkItemResponse bulkItemResponse : bulkResponse) {boolean failed = bulkItemResponse.isFailed();if (failed) {log.error("批量插入消息失败,详细信息={}", bulkItemResponse.getFailureMessage());}DocWriteResponse itemResponse = bulkItemResponse.getResponse();switch (bulkItemResponse.getOpType()) {case INDEX:case CREATE:IndexResponse indexResponse = (IndexResponse) itemResponse;handleAddDocSuccess(indexResponse);break;case UPDATE:UpdateResponse updateResponse = (UpdateResponse) itemResponse;break;case DELETE:DeleteResponse deleteResponse = (DeleteResponse) itemResponse;break;default:break;}}}public void onFailure(Exception e) {log.error("批量插入失败", e);}});}
消费消息这个场景做得很简单啊,就是转换日志信息,然后拼接ES批量插入的请求体,几乎没什么费事的动作。这里要注意一下,如果消息早已发送到Topic,并且选择了一个全新的消费者组,那么将auto.offset.reset改成earliest从头读起。
因为我这里使用了DevOps平台,所以切换很简单,选之前的容器变更部署即可。
年轻人,听说你也懂优化
众所周知,Kafka不懂优化也没有太大关系,因为通用版已经够好用了,但是作为卷王怎么能够接受通用,必然是狠狠地定制,定在墙上那种。这里简单说一下高性能版生产者参数的调整,顺道解释下调整意义。
batch.size从16384(16KB)提升到163840(160KB),简单粗暴地提升10倍批量大小,攒够这个大小才允许发送消息,从而减少请求次数。
linger.ms默认是0ms,也就是无延迟推送消息,因为batch.size调大了所以这里同步增加到20ms,注意这里需要根据实际情况进行调整。
batch.size和linger.ms是决定吞吐量和延时的重要参数,两个条件任一满足即可发送消息。batch.size过大会导致发送消息难以攒够batch.size大小导致消息发不出去,因此需要linger.ms保底,linger.ms时间一到也能发送消息。
buffer.memory默认是32MB,这个缓冲大小要随着batch.size提升而提升到67108864(64MB)。避免过小导致消息无法写入,从而阻塞后续的生产消息。
acks使用默认值1,保证分区leader副本写入即可。
max.request.size默认1048576B(1MB),因为日志消息,比如异常堆栈信息会超过1MB,所以这里调整到5MB,注意Topic的message.max.bytes也要同步调整大小。
request.timeout.ms默认3000ms,增大了max.request.size也要适当提升下请求超时参数,比如60000ms,暴力加参是这样的。
compression.type默认无,因为日志场景会有较大量的输入,所以最好开一下压缩。我这里综合考虑压缩比和压缩吞吐量选择了lz4,注意这里broker的compression.type默认是跟随producer的,如果自己有修改,一定要改回去,避免压缩算法不一致导致的额外开销。
以上便是高性能通用版生产者的重要参数调整,接下来针对生产速度做一个对比。在本地笔记本8核16G环境下(远低于服务器性能,仅作对比参考),并发消费3分区向12分区(副本数为1)新Topic生产消息,另一对比者reliableHighKafkaTemplate(仅开启ACK为-1,调大请求消息体),结果峰值如下。高性能版的生产者是要比普通的版本要高出不少的,如果放在服务器上这个速度还会暴增,因此生产消息的速度我们并不需要太在意,肯定是比消费更快的。
|
高性能版 |
高可靠版 |
|
6045.41 条/s |
3925.80 条/s |
既然使用了Spring-Kafka就要老老实实接受人家的设定(这里是妄图通过Kafka-client写出消费者,但是被生命周期管理代码劝退,从而老老实实用Spring真香桶的败犬菜恐龙),根据Spring官方给的两条路,选择并发消费。相比写配置文件调参,我更喜欢通过bean加载,除了可以更自由的选择之外,还可以塞到组件里即插即用。接下来重点介绍下高性能模式下,如何调整消费者参数,以及如何定制Spring-Kafka的消费者工厂。
/*** @author WangZY* @date 2023/3/6 18:52* @description 测试用手动*/public ConcurrentKafkaListenerContainerFactory<String, String> testFactory() {ConcurrentKafkaListenerContainerFactory<String, String> container =new ConcurrentKafkaListenerContainerFactory<>();Map<String, Object> props = new HashMap<>(16);props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.GROUP_ID_CONFIG, StringUtils.isEmpty(prop.getConsumerGroupId()) ?"testConsumerGroup" : prop.getConsumerGroupId());props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 1048576);props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 60000);props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");container.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));container.setConcurrency(3);container.setBatchListener(true);container.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);return container;}
fetch.min.bytes该参数用来配置 Consumer 在一次拉取请求(调用 poll() 方法)中能从 Kafka 中拉取的最小数据量,默认值为1B。为了减少网络IO,也是配合前面生产者的高性能配置,这里果断上调到1048576(1MB),对应fetch.max.bytes为50MB,这个不用调。
max.poll.records用来配置 Consumer 在一次拉取请求中拉取的最大消息数,默认值为500(条),略小略小,配合生产者调整至1000。这里是预测值,要根据实际情况调整,下文有提,看到最后哟。
max.poll.interval.ms这个参数定义了两次poll()之间的最大间隔,默认值为3000(5分钟)。如果超过这个间隔同样会触发rebalance。在多数情况下这个参数是导致rebalance消息重复的关键,即业务处理消息耗时太长。这里一般来说不用调整,如果出现,也是优先调整代码,而不是修改该参数。
这里Spring-Kafka的消费者工厂定义,除了调参之外,重要还有开启并发监听setBatchListener(true)。只有开启了这个参数,才能以public void testLogListen(List<ConsumerRecord<String, String>> records)这种入参为List的方式监听消费。同理这里getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL)则是为了让入参中的Acknowledgment ack生效,改为手动提交offset后,虽然降低了消费速度,但是避免了因消费报错导致的消息丢失问题。
配置副本数可以先设置为0,刷新间隔禁用,刷盘设置为异步即可。别的一些歪门邪道经测试没大用,除了前面三项最好的提升就是加内存,这个堆硬件最好使。插一个官方推荐的优化插入速度的链接Tune for indexing speed | Elasticsearch Guide [8.6] | Elastic(elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html),顺道总结下ES官方推荐的提高插入速度的方法:
使用Bulk批量插入
多线程请求插入ES
取消或者增加索引刷新间隔
插入时禁用索引初始副本
服务器禁用swap
索引文档使用自动生成的ID
使用更快的硬件,比如SSD
加内存(这一点是我加的,因为ES很多配置是内存百分比的,提高内存一般是性能提升的最优解。)
目前测试节点是三节点集群,都是mixed节点,服务器都是8核16G+1T机械磁盘(用SSD会更快)。ES除了一个节点因机器上服务过多(Kibana,SkywalkingUI,redis-cluster等),设置为4G(-Xms4G -Xmx4G),另两台设置为6G。接下来我会以表格的方式记录不同配置下,在Kibana上观测到的极限插入速度。

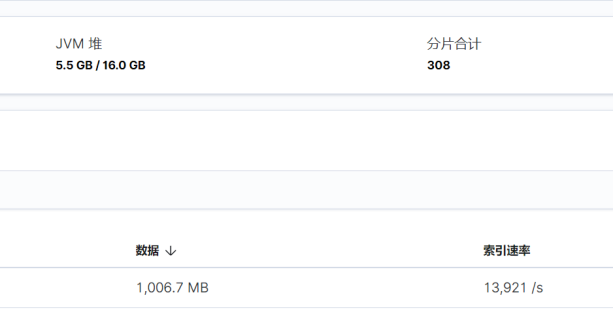
贴一张Kibana的图,其他就不截图了,不然成灌水了。这个实测结果其实是符合我的预期的,不过让我意外的是1master(4G)+2data(6+6)的速度高于3mixed(4+6+6)。不知道是不是我的机器配置原因导致了这一点,但是我手里也没有空闲的服务器供我测试了,就留待读者们自己实验了,有测试过的大佬可以在评论区留言。简单来说,是符合上述ES官方推荐的优化配置的说法的,多线程的提升是巨量的,禁用副本和刷新间隔也会产生不小的提升。

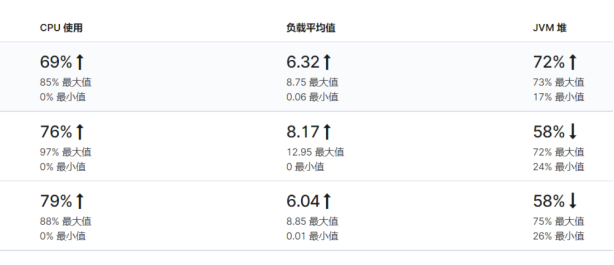
消费的单次拉取值是需要根据实际情况调整的,我第一次调整是单次3000,后来调成2000,都发生了同一个问题,速度没上去,服务器负载倒是飙升,如下图。
刺激的BUG战场
新建了Topic后,写好中转生产者后,刚调用就G了,快如闪电。原因很简单,消息体超过message.max.bytes默认值1MB了,调大即可。
java.util.concurrent.TimeoutException: Connection lease request time outat org.apache.http.nio.pool.AbstractNIOConnPool.processPendingRequest(AbstractNIOConnPool.java:411) ~[httpcore-nio-4.4.13.jar:4.4.13]at org.apache.http.nio.pool.AbstractNIOConnPool.processNextPendingRequest(AbstractNIOConnPool.java:391) ~[httpcore-nio-4.4.13.jar:4.4.13]at org.apache.http.nio.pool.AbstractNIOConnPool.release(AbstractNIOConnPool.java:355) ~[httpcore-nio-4.4.13.jar:4.4.13]at org.apache.http.impl.nio.conn.PoolingNHttpClientConnectionManager.releaseConnection(PoolingNHttpClientConnectionManager.java:391) ~[httpasyncclient-4.1.4.jar:4.1.4]
我是在spring boot数据处理服务中使用了elasticsearch-rest-high-level-client客户端,其中封装了HttpClient来向ES发送请求。这里的问题来源于使用了bulkAsync(后根据场景换成了同步请求bulk),这是个异步请求,底层是AbstractNIOConnPool提供了请求连接池。发生这个报错的原因是新的异步请求在获取连接时超过了获取连接超时时间,解决方案最直接的就是调大连接池大小和请求连接超时时间。
httpClientBuilder.setMaxConnTotal(zeroProperties.getMaxConnectTotal());httpClientBuilder.setMaxConnPerRoute(zeroProperties.getMaxConnectPerRoute());
RestClientBuilder builder = RestClient.builder(httpHostZeroList.toArray(new HttpHost[0]));builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setMaxConnTotal(zeroProperties.getMaxConnectTotal());httpClientBuilder.setMaxConnPerRoute(zeroProperties.getMaxConnectPerRoute());return httpClientBuilder;});if (!StringUtils.isEmpty(username) && !StringUtils.isEmpty(password)) {CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);return httpClientBuilder;});}
在解决上面问题时Debug发现一个很神奇的现象,就是这里的配置超时时间的setMaxConnTotal和setMaxConnPerRoute,如果后面有相同的setHttpClientConfigCallback方法时,就会走最后一个set方法,前面的不会生效。在没有debug之前,我设置的参数一直不能生效,始终是默认值,我百思不得其解,最后通过debug,发现了这个神奇的现象。最后解决方法如下,就是放在一起进行配置,希望有大佬能解答我这个问题。
RestClientBuilder builder = RestClient.builder(httpHostZeroList.toArray(new HttpHost[0]));if (!StringUtils.isEmpty(username) && !StringUtils.isEmpty(password)) {CredentialsProvider credentialsProvider = new BasicCredentialsProvider();credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider);httpClientBuilder.setMaxConnTotal(zeroProperties.getMaxConnectTotal());httpClientBuilder.setMaxConnPerRoute(zeroProperties.getMaxConnectPerRoute());return httpClientBuilder;});}else {builder.setHttpClientConfigCallback(httpClientBuilder -> {httpClientBuilder.setMaxConnTotal(zeroProperties.getMaxConnectTotal());httpClientBuilder.setMaxConnPerRoute(zeroProperties.getMaxConnectPerRoute());return httpClientBuilder;});}
org.elasticsearch.client.ResponseException: method [POST], host [http://192.168.158.115:9200], URI [/_bulk?timeout=3m], status line [HTTP/1.1 429 Too Many Requests]{"error":{"root_cause":[{"type":"circuit_breaking_exception","reason":"[parent] Data too large, data for [<http_request>] would be [2077061194/1.9gb], which is larger than the limit of [2040109465/1.8gb], real usage: [2074284352/1.9gb], new bytes reserved: [2776842/2.6mb], usages [request=0/0b, fielddata=37121/36.2kb, in_flight_requests=10749974/10.2mb, model_inference=0/0b, accounting=8100600/7.7mb]","bytes_wanted":2077061194,"bytes_limit":2040109465,"durability":"TRANSIENT"}],"type":"circuit_breaking_exception","reason":"[parent] Data too large, data for [<http_request>] would be [2077061194/1.9gb], which is larger than the limit of [2040109465/1.8gb], real usage: [2074284352/1.9gb], new bytes reserved: [2776842/2.6mb], usages [request=0/0b, fielddata=37121/36.2kb, in_flight_requests=10749974/10.2mb, model_inference=0/0b, accounting=8100600/7.7mb]","bytes_wanted":2077061194,"bytes_limit":2040109465,"durability":"TRANSIENT"},"status":429}
ES默认是1G,我这里调整到2G,上面这段话的意思就是说,ES的堆内存满了,放不下新的数据,也就是标准OOM了。重点观察报错日志的几个参数:
which is larger than the limit of [2040109465/1.8gb],这里提示的是内存上限,默认是ES内存最大值的95%
real usage: [2074284352/1.9gb],这里是当前已使用内存大小
new bytes reserved: [2776842/2.6mb],这里是本次请求需求的内存空间大小
data for [<http_request>] would be [2077061194/1.9gb],这里指的是已使用内存大小+本次请求大小,这个值大于内存上限,因此报错
此时ES此节点挂掉,查看日志可以得到下面这段。
[2023-03-09T17:45:22,338][INFO ][o.e.i.b.HierarchyCircuitBreakerService] [node-2] attempting to trigger G1GC due to high heap usage [2049729624][2023-03-09T17:45:22,343][INFO ][o.e.i.b.HierarchyCircuitBreakerService] [node-2] GC did bring memory usage down, before [2049729624], after [2029398072], allocations [1], duration [5][2023-03-09T17:45:22,332][WARN ][o.e.h.AbstractHttpServerTransport] [node-2] caught exception while handling client http traffic, closing connection Netty4HttpChannel{localAddress=/192.168.158.114:9200, remoteAddress=/172.27.136.31:6096}java.lang.Exception: java.lang.OutOfMemoryError: Java heap space
这个解决办法其实很简单,因为调任何参数都不治本了,所以唯一能做的就是加内存,我在测试阶段是加到4G就没有问题了。
微醺码头
登上微醺码头,为大家带来一些散碎的知识点,坐稳了,开船啦!
一般分为四种节点类型,分别是主节点、数据节点、客户端节点和混合节点。通过elasticsearch.yml中的node.master: true和node.data: true(默认值)来配置,默认节点是混合节点。
主节点(master),配置node.master: true、node.data: false。主要功能是维护元数据,管理集群节点状态,不负责数据写入和查询。此机器相对内存配置要求低一些,但是必须稳定,因为是master,挂了就都没得玩了。
数据节点(data),配置node.master: false、node.data: true。主要功能是负责数据写入和查询,因此要求内存必须够大。
客户端节点(client),配置node.master: false、node.data: false。主要功能是负责任务分发和结果汇聚,分担数据节点压力,计算用的,内存也得大大大。
混合节点(mixed),配置node.master: true、node.data: true。全能冠军,(⊙﹏⊙),就和全栈工程师一样,啥都会但也不会特别厉害,压力一大就容易G了。
当集群达到一定规模之后,不建议使用mixed,而是应该对各节点进行角色划分,可以按照mixed--->master+data--->master+data+client逐步划分。
接下来介绍下如何从mixed进行转换,当然我的建议是一开始就要划分出来明确的角色,别到一半再转。以下是从mixed转换到master的步骤,其他同理了。
修改elasticsearch.yml中的node.master: true和node.data:false
下线该节点,在es安装目录下的bin文件夹下执行./elasticsearch-node repurpose清除分区数据
最后重启该节点就成功
注意这里有几个问题,首先是在当前节点拥有分片数据的时候是不允许直接设置node.data:false的,会提示以下异常。

我是使用的ES7.9版本,因此官方在报错信息后贴心的提示了可以使用工具https://www.elastic.co/guide/en/elasticsearch/reference/current/node-tool.html进行分片信息的删除。

这里bin目录下执行命令后,会有个确认环节,再次让你判断是否要清除分片数据。这里我的建议是三个,一是手动通过ES的API迁移分片(一次只能迁移一个索引,折磨),二是一开始就弄好节点角色定位避免二次变更,三是所有索引都加上副本。
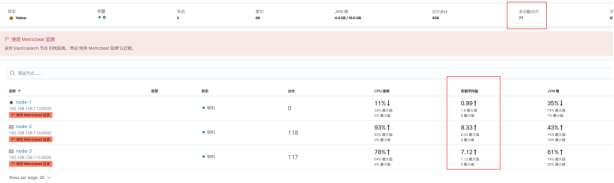
从上面这个图中可以看到,当选择清除主节点分片数据后,有副本的索引的数据不会丢,而是将副本升级为分片,体现在未分配分片中。因为我的索引大部分设置为3分片,所以这时候索引大部分状态都是Yellow,小部分没有副本的则是变成了Red(上面这个图截的不好,应该截索引那个界面的)。
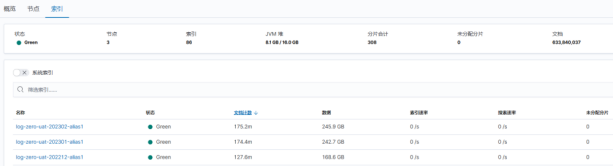
当我重新将master节点变成mixed节点后,未分配的分片会慢慢填充到该节点,节点和集群状态也会转Green,不要害怕,让子弹飞一会儿。
按照功能区分为三种特化型生产者和一种普适生产者。三种特化型分别是高性能(吞吐量)、高可靠性、顺序性。高性能上面说过了,就不复述了。
高可靠性提升重试次数和重试时间以及ack设置为all来保障消息发送的可靠性
顺序性则使用max.in.flight.requests.per.connection设置为1保证消息不会因为重试而顺序混乱,同时topic设置分区为1或者生产者发送指定分区来协同保证顺序性
import com.xxx.transfer.properties.TransferProperties;import org.apache.kafka.clients.producer.ProducerConfig;import org.apache.kafka.common.serialization.StringSerializer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.context.properties.EnableConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Primary;import org.springframework.kafka.core.DefaultKafkaProducerFactory;import org.springframework.kafka.core.KafkaTemplate;import java.util.HashMap;import java.util.Map;/*** @Author WangZY* @Date 2022/3/15 14:51* @Description 多种生产者配置**/(value = {TransferProperties.class})public class KafkaProducerConfig {private TransferProperties prop;/*** @author WangZY* @date 2022/7/14 11:38* @description 高性能*/public KafkaTemplate<String, String> performanceKafkaTemplate() {Map<String, Object> props = new HashMap<>(16);props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.BATCH_SIZE_CONFIG, 163840);props.put(ProducerConfig.LINGER_MS_CONFIG, 20);props.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 67108864);props.put(ProducerConfig.ACKS_CONFIG, "1");props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);props.put(ProducerConfig.COMPRESSION_TYPE_CONFIG, "lz4");//config.getInt,自动强转这里不用在意是字符串还是数字props.put(ProducerConfig.RETRIES_CONFIG, 1);props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, 1000);return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));}/*** @author WangZY* @date 2022/7/14 11:40* @description 高可靠性*/public KafkaTemplate<String, String> reliableHighKafkaTemplate() {Map<String, Object> props = new HashMap<>(16);props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);props.put(ProducerConfig.RETRIES_CONFIG, "3");props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, "1000");props.put(ProducerConfig.ACKS_CONFIG, "-1");return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));}/*** @author WangZY* @date 2022/7/14 11:40* @description 顺序性*/public KafkaTemplate<String, String> timeKafkaTemplate() {Map<String, Object> props = new HashMap<>(16);props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);props.put(ProducerConfig.RETRIES_CONFIG, "1");props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, "1000");props.put(ProducerConfig.MAX_IN_FLIGHT_REQUESTS_PER_CONNECTION, 1);return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));}/*** @author WangZY* @date 2022/7/14 11:41* @description 普通*/public KafkaTemplate<String, String> normalKafkaTemplate() {Map<String, Object> props = new HashMap<>(16);props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);props.put(ProducerConfig.MAX_REQUEST_SIZE_CONFIG, 10485760);props.put(ProducerConfig.REQUEST_TIMEOUT_MS_CONFIG, 60000);props.put(ProducerConfig.RETRIES_CONFIG, "1");props.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG, "1000");props.put(ProducerConfig.BATCH_SIZE_CONFIG, "16384");props.put(ProducerConfig.LINGER_MS_CONFIG, 5);return new KafkaTemplate<>(new DefaultKafkaProducerFactory<>(props));}}
这个就相对朴实了,区分比较少,主要是是否自动提交offset的对比,高性能部分也在前面提到过,直接贴代码吧。
import com.xxx.transfer.properties.TransferProperties;import org.apache.kafka.clients.consumer.ConsumerConfig;import org.apache.kafka.common.serialization.StringDeserializer;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.boot.context.properties.EnableConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import org.springframework.context.annotation.Primary;import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import org.springframework.kafka.listener.ContainerProperties;import org.springframework.util.StringUtils;import java.util.HashMap;import java.util.Map;/*** @Author WangZY* @Date 2022/3/15 14:51* @Description 多种消费者配置**/(value = {TransferProperties.class})public class KafkaConsumerConfig {private TransferProperties prop;/*** @author WangZY* @date 2022/7/14 11:35* @description 高性能*/public ConcurrentKafkaListenerContainerFactory<String, String> performanceFactory() {ConcurrentKafkaListenerContainerFactory<String, String> container =new ConcurrentKafkaListenerContainerFactory<>();Map<String, Object> props = new HashMap<>(16);props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.GROUP_ID_CONFIG, StringUtils.isEmpty(prop.getConsumerGroupId()) ?"performanceConsumerGroup" : prop.getConsumerGroupId());props.put(ConsumerConfig.FETCH_MIN_BYTES_CONFIG, 1048576);props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 1000);props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 60000);container.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));container.setConcurrency(3);container.setBatchListener(true);return container;}/*** @author WangZY* @date 2022/7/14 11:36* @description 高可靠*/public ConcurrentKafkaListenerContainerFactory<String, String> reliableHighFactory() {ConcurrentKafkaListenerContainerFactory<String, String> container =new ConcurrentKafkaListenerContainerFactory<>();Map<String, Object> props = new HashMap<>(16);props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.GROUP_ID_CONFIG, StringUtils.isEmpty(prop.getConsumerGroupId()) ?"reliableHighConsumerGroup" : prop.getConsumerGroupId());props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 60000);container.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));container.setConcurrency(3);container.setBatchListener(true);container.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL);return container;}/*** @author WangZY* @date 2022/7/14 11:38* @description 普通*/public ConcurrentKafkaListenerContainerFactory<String, String> normalFactory() {ConcurrentKafkaListenerContainerFactory<String, String> container =new ConcurrentKafkaListenerContainerFactory<>();Map<String, Object> props = new HashMap<>(16);props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, prop.getKafkaServers());props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.GROUP_ID_CONFIG, StringUtils.isEmpty(prop.getConsumerGroupId()) ?"normalConsumerGroup" : prop.getConsumerGroupId());props.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG, 60000);container.setConsumerFactory(new DefaultKafkaConsumerFactory<>(props));container.setConcurrency(3);container.setBatchListener(true);return container;}}
写在最后
在我看来消息积压这个问题场景的解决思路是很简单的,但同时细节又十分丰富,因此我补充了一些优化知识和实际遇到的问题,解决问题的过程还是很有意思的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721