
一、监控降噪背景
五六月以来,蚂蚁开启监控治理主题,推进监控进一步完善,做到既能即时响应告警——五分钟响应三十分钟处理完毕,又能过滤降噪,避免处理疲劳。除了响应公司治理主题之外,小组内部告警的噪音也是一直积累的问题,这是由于随着项目和小组的发展,不可避免使得配置的监控越来越多,累积的不健康监控增加,导致人均处理告警持续增加。因此,于六月份启动组内监控治理,同时记录治理心得。
二、为什么降噪治理很有必要?
避免告警疲劳,提高效率:监控报警在一个小组或项目成立的初期,往往会使人十分紧张,随着其中夹杂噪音增多,处理人员便会逐渐告警疲劳,对监控告警越来越不重视,从而导致对线上告警敬畏减少,真正有效的告警被淹没在了噪声中。同时增加了大量不必要的工作量,疲于应付报警,降低效率。
节省资源,同时保持系统稳定:线上监控系统通常会持续地对系统进行监控,如果监控报警太频繁,会占用大量的系统资源,导致系统性能下降,也会影响系统的稳定性。因此,降噪可以节省系统资源,提高系统的性能。
三、告警治理
利用集团的极光报警数据看板可以非常简单的看到噪音数和故障数等数据,以及五分钟发现率和三十分钟完结率(衡量应急效率的重要指标),从而获取针对性的改进信息。同时可以对打标类型选择噪音进行筛选,并定位到对应事件,以及其对应事件id匹配的监控进行针对行监控降噪治理。
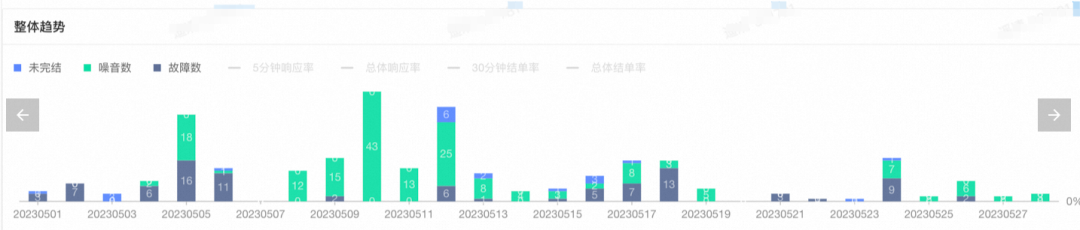 图 1. 噪音数和故障数等趋势
图 1. 噪音数和故障数等趋势
利用应急事件详情可快速定位对应监控,其中红框是监控id,对应于antmonter(集团监控系统)所配置报警监控。
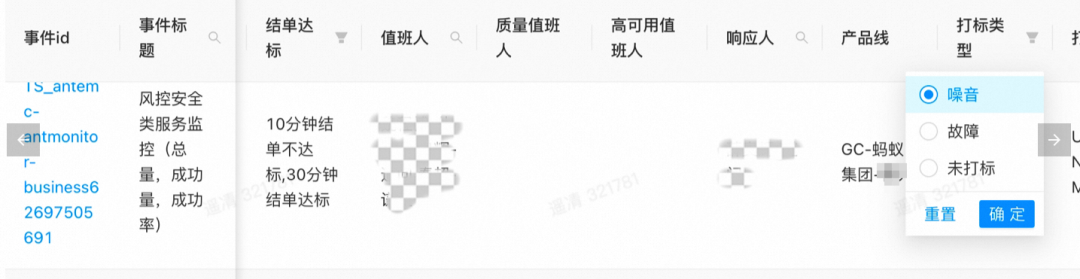
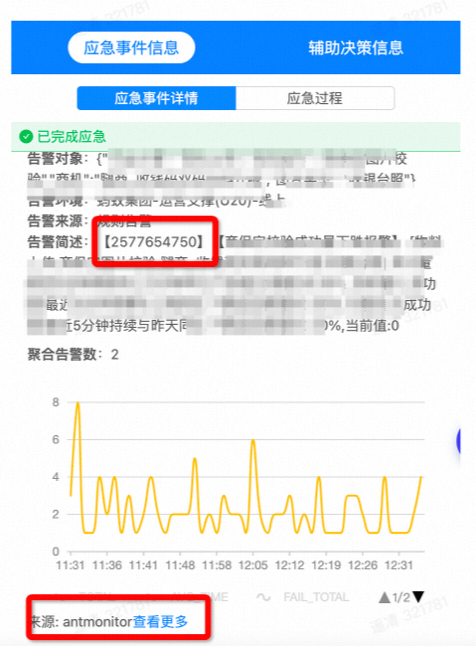
图 2. 噪音及对应事件和监控
1)如何衡量监控效果
对于监控报警而言,衡量效果最有效的指标为召回率——即衡量能够正确识别出正样本的百分比。召回率的计算公式为:召回率 = 正确识别的正样本数 / 所有正样本数。对于监控能够保证召回率接近 100%,同时尽量提升准确率。在保证召回率,识别线上问题的同时,提升准确率降低噪音,便是监控治理要做的事。
2)监控规则
有了衡量效果的指标,我们就需要对监控进行降噪。目前监控主要使用的是规则降噪,分为普通规则和智能规则。普通规则更加个性化、更加方便实用,也有主要缺点:需要开发者同时对监控系统和组内业务非常了解,能够预估报错量,随着业务的发展要经常更正,同时容易由于数据波动出现告警遗漏、告警频繁。那么针对普通规则,如何进行降噪?
①避免维度单一
单一维度的监控配置,往往难以到达较好的监控效果,同时极易产生噪音。例如,单一设置业务成功量或失败量,当n个单位采集时间低于或高于某阈值时报警。这种方法往往会在某些时刻频繁报警,例如半夜,早晚高峰等等。必须根据业务场景增加多维度触发条件,解决该问题方案如下:
成功量级 + 成功率 / 失败量级 + 成功率 适用降噪场景:成功量上升,是因为总量上升导致;失败量下降,是因为总量下降导致。
成功量级 + 成功率 + 总量 适用降噪场景:避免极少业务量场景下极端失败情况,例如两笔业务量,一笔失败或两笔都失败 导致的报警。
成功率 + 失败数量 适用降噪场景:同样适用极少业务量场景下极端失败情况。
设置采集周期 适用降噪场景:避免冲高回落导致的针状突出噪音,如网络抖动导致问题。其中周期的范围则需要开发运维人员更具业务量级和组内业务自行确定,通过召回率和准确率进行确定。
②利用黑白名单
对于一部分监控,总会存在部分业务或接口极易超出设置报警阈值的情况,此时利用黑白名单进行单独配置即可。
应用调用下游接口成功率监控,如果存在部分接口因业务问题造成失败,或部分外部调用接口经常失败且无影响,我们就需要将其进行单独配置监控。首先通过噪音打标场景查出经常报警且标记为噪音的接口,在监控处通过黑白名单,黑名单过滤掉噪音接口,并对其配置一项敏感度较高的阈值,再配置一个监控,将这些接口加白,白名单部分减少监控敏感度。
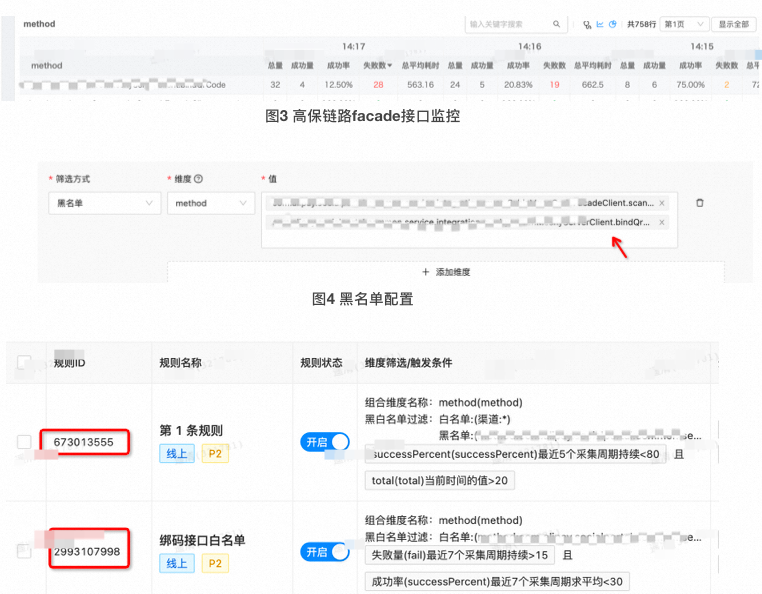
图5 敏感度配置
业务错误码报警。监控平台能够自定义配置所需监控错误码,其来源于日志当中有一些信息,可以用来帮助我们判断是否需要关心这种日志。在进行数据采集时,可以自定义所需要关注的日志数据,并配置白名单值,如图6所示,之后可以选中其在产出日志所在位置,利用监控自动进行数据获取,如图7所示。

图6. 自定义日志数据采集白名单
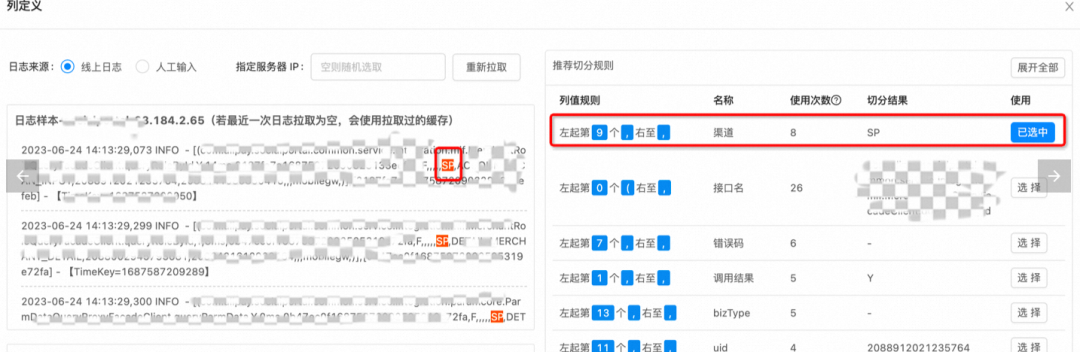 图7. 日志数据采集范围
图7. 日志数据采集范围
③利用环比和同比
业务的总量,成功量,接口的调用成功率,单机应用error总数等等,总会存在一个数据惯性,如果最近一小时总量总是维持在每分钟100,几乎不可能会突变至每分钟总量1000且持续存在。这样我们就认为惯性失效,可能存在异常从而告警。这就衍生出环比和同比的作用。环比和同比是什么?
环比,是指相邻两个时间段之间值的比较,即纵向的对比。以时刻为例,环比就是指此刻一小时与上一小时同一指标的变化率,计算公式为:(当前一小时指标-上一小时指标)/上一小时指标。
同比,是指同一时间段相邻值之间的比较,即横向的对比。以天为例,同比就是指今日此刻与昨日此刻同一指标的变化率,计算公式为:(今日此刻数值-昨日此刻数值)/昨日此刻数值。
由此可见,利用环比可监控惯性的变化,而利用同比可排除惯性的错误情况。对于监控而言,我们通常可以选择 采集周期为当前五分钟与上一个五分钟作为环比,监控其下降或者上升的程度,从而监控惯性的变化。选择同一时期与昨日或者上周作为同比,监控其下降或者上升的程度,从而判断惯性变化是否所为异常。

图8. 同比与环比监控
3)利用智能降噪
智能降噪作为antmonter给出的智能工具,可以有效进行降噪。
告警抑制:告警抑制可以帮助在大量报警风暴的情况下进行降噪,设置抑制采集周期数(如周期为一分钟,则设置周期数为5则抑制五分钟报警)。
短周期抖动:短周期抖动是一种网络抖动等原因导致瞬间凸状报错周期,会导致采集周期内整体数据求和、求平均值等偏高超过阈值而产生告警。输入短周期比例,则可以在产生该比率的报警周期时抑制,例如,采集周期为N,短周期比率A,则产生的报警在N * A内,则会被抑制。
冲高回落:冲高回落通常是指指标在一段时间内呈现出明显的上升趋势,突破了某个阈值或警戒线,但随后迅速回落到原来的水平,相当于是一次短暂的异常波动。冲高回落是指监控指标在一段时间内上涨后又下跌。当勾选该模式后,若出现监控指标在设置时间段内的持续冲高后又下跌回平稳状态,将不会触发告警通知。
4)CDO报警降噪
CDO(Complex Event Detection and Optimization)报警是一种复杂事件的监测,用于对系统的异常事件和性能问题进行监测和排查。对于CDO报警的降噪,除了打印error,warn日志规范外,还有对异常抛出的规范。对于一个应用来说,通常需要定义一个专有业务异常来服务于业务系统,并在出现可控业务问题时进行抛出,而出现未在可控范围内异常时再使用通用异常。下面举个例子来进行异常与日志的搭配代码
首先定义业务异常 BizException:
public class BizException extends RuntimeException {/** serialVersionUID */private static final long serialVersionUID = 5840651686530819567L;/** 异常错误代码 */private ResultCodeEnum code = ResultCodeEnum.UN_KNOWN_EXCEPTION;/*** 创建一个<code>BizException</code>** @param code 错误码*/public BizException(ResultCodeEnum code) {super(code.getMsg());this.code = code;}/*** 创建一个<code>BizException</code>** @param code 错误码* @param message 自定义错误信息*/public BizException(ResultCodeEnum code, String message) {super(message);this.code = code;}}
其次,定义业务处理模板,当抛出业务异常时,在生产环境会进行warn日志打印,而对于其余不在可控之中的异常,则使用error日志打印。在抛出可控,不会导致系统崩溃或无法使用异常时,应抛出业务异常,如此进行规范化。
public class HandleTemplate {public void execute(final Response response, final HandleCallback action) {Profiler.enter("开始进入操作模板");try {action.doPreAction();action.doAction();action.doPostAction();} catch (BizException be) {if (EnvEnum.DEV.getType().equals(EnvUtil.getExactEnv())) {LogUtil.error(LOGGER, be, "业务异常:");} else {LogUtil.warn(LOGGER, be, "业务异常:");}ResultUtil.generateResult(response, be);} catch (IntegrationException ie) {LogUtil.error(LOGGER, ie, "查询业务异常:" + ie.getMessage());ResultUtil.generateResult(response, ie);} catch (Throwable e) {LogUtil.error(LOGGER, e, "操作系统异常:" + e.getMessage());ResultUtil.generateResult(response, ResultCodeEnum.SYSTEM_ERROR, e.getMessage());} finally {}}}
此外,对于warn日志和error日志的使用也需要进行规范化,WARN日志应该用于记录系统发生了一些异常事件,但
这些事件不会导致系统崩溃或无法使用。例如输入参数异常或不规范,输入的参数为空、非法、越界等。ERROR日志通常用于输出一些严重错误信息,表示系统发生了一些致命的错误,例如空指针异常导致系统崩溃、无法使用,未授权访问、入侵等。如此进行规范化,则可以正确治理CDO报警。
5)其余方式
此外,还有一些比较有必要的降噪方法,以适合不同场景下的降噪情况。
去除预发环境。去除预发环境的监控报警,只订阅生产环境,避免无谓的资源消耗和时间消耗。
设置生效时间段。根据业务时间调整生效时间段,对于有高低峰期业务特性,配置生效时间段,从而减少低峰期报警噪音。同时设置生效时间段 + 连续N分钟内只报警一次,可以避免大量报警风暴。
报警抑制,避免报警风暴。
去除不必要和重复报警,正确订阅报警,如一些自动配置化的报警,以及做好报警监控日志分析,避免大量重复覆盖流量的监控报警。
发送渠道优化。根据业务重要程度设置不同报警渠道,避免大量短信邮件轰炸。
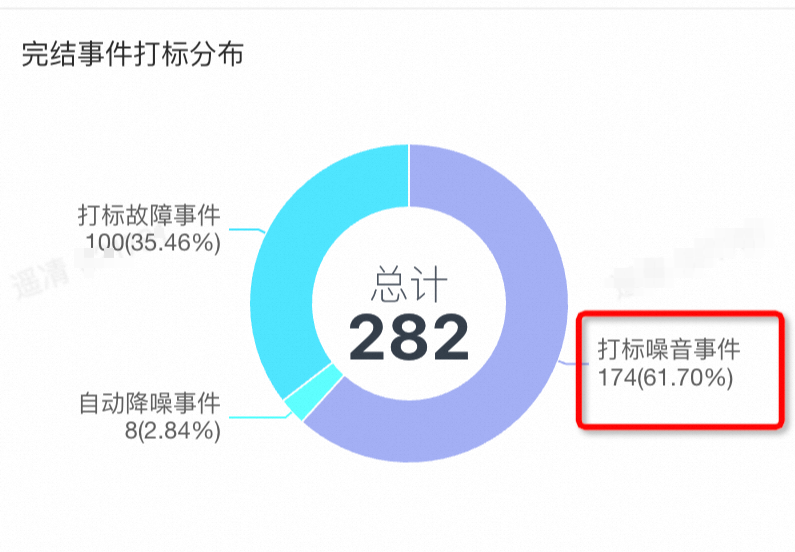
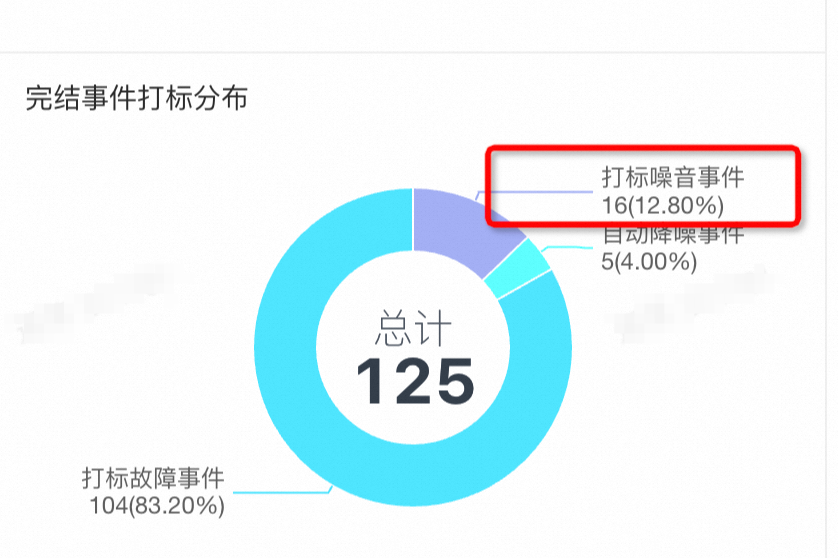
自六月治理报警以来,噪音数已经大大减少,从占整体事件的61.70%下降到12.80%,同时打标为故障数的报警数量维持变化不大,可以说明监控保持召回率不变的同时,准确率大大提升。

五月噪音率:
六月噪音率:
最后一定要注意,降噪的治理一定要结合业务实际,并在降噪后的一定时间内以指标进行衡量,如召回率,准确率等,否则以个人感觉进行调整,就会有可能出现线上问题被屏蔽的情况!降噪的目的,是保证召回率的同时,尽量提高准确率。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721