
关于标题
首先说一下标题,《如何搭建运维/SRE能力》,这里我没有写搭建团队,而是搭建能力,因为有些目标的达成未必一定需要自建团队,从成本、结果可预见性、长期投入维护的角度来看,需要慎重决策,决策错了,未来将是一地鸡毛,这个后文再展开。
关于运维/SRE团队
另外一点也要提前澄清,文中提到的运维/SRE团队都是为业务服务的,业务的成功是第一要务。有些运维团队做了一些产品在对外商业化输出,本身成了一条业务,这个另当别论,而且,以我在老东家的经验来看,运维/SRE团队这样的做法(对外商业化输出)不可取,尤其是在一个没有ToB基因、没有相应的ToB组织建设的公司。
从哪里获取运维/SRE能力
既然一切都是为了业务成功(不考虑业务,只考虑自己能否晋升能否忽悠老板的另当别论),我们就重点来看业务需要哪些运维能力(后文详细讲解),需要从哪里获取这些运维能力,典型的获取方式有以下几种。
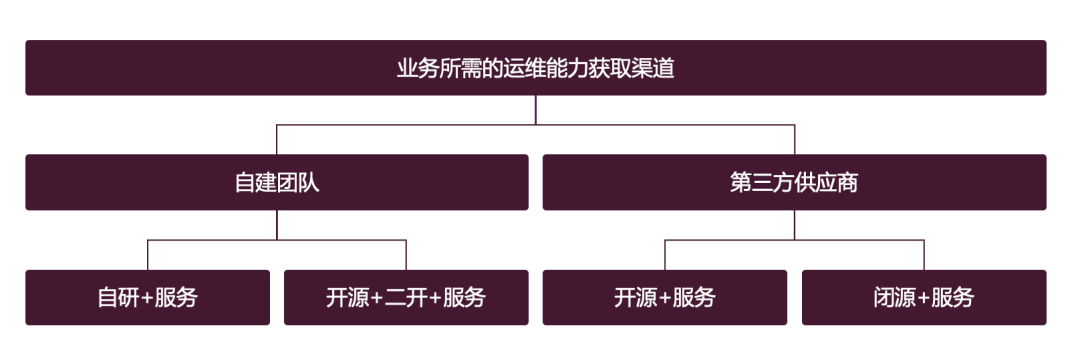
首先是通过自建团队提供相关能力,这个方式大家最为熟悉,自建的团队对业务的交付物通常包括两部分:产品+服务。先说产品:
如果产品需求是通用需求,产品大概率是直接使用的开源项目。需要考虑开源项目的持久性(开源项目研发人员是否有商业公司做收入上的支持,个人开源项目大都会死在没有收入上)、活跃性(项目是否已经多年未更新?提的issue、pr是否及时处理?通常一周内处理就可以看做是活跃的)、生态繁荣性(是否有很多人参与做贡献?很多公司投入使用?)
开源项目是否要二次开发?如果二次开发的代码可以merge回主干,通常意味着二次开发的代码具有通用性,得到了开源项目团队的认可。如果无法merge回主干,后面的维护就是麻烦事了,尤其是人才变动之后,一地鸡毛。基于开源项目的API做一些胶水代码,和内部系统做整合,通常是可以的,毕竟没有改造开源代码,后面开源项目升级还是可以跟得上的。
当然也有不用开源完全自研的(只是使用一些开源的lib库,核心产品逻辑自研),这种要慎重,如果开源社区没有相关的产品,那只能自研,但是自研之后就要考虑长期维护的问题,研发人员通常喜欢做从0到1的事情,后面收益小了,无法晋升涨薪,就容易变动。而运维这个赛道,开源社区的产品琳琅满目,需要自研的产品可能屈指可数,三思。
其次就是服务,这里所谓的服务,说的是向业务侧输出的专家经验。比如自建团队做了一款监控产品,这个团队需要给公司内部的“客户”输出监控的最佳实践、监控产品出问题的时候需要这个团队快速解决。其实,公司内部的中后台团队需要有很强的服务意识,同时还得了解行业最佳实践,否则,就容易被业务牵着鼻子走,走出了和行业最佳实践背道而驰的路子,后面,就都是问题了。
服务的核心,是靠人(当然,能把最佳实践固化到产品里,那自然是极好的),作为管理者,要想让这个团队输出好的服务,就需要考虑很多人的问题,比如:能否招到相关的人才、能否留住相关的人才(发展空间、薪资等)、自建团队每个方向至少两个人互备,成本是否可以接得住。
通过第三方供应商来获取运维能力,是另一个路子,供应商的交付物显然也包括两部分:产品+服务。产品分为开源、闭源两种类型,有哪些考量点呢?
开源的产品通常会有更多的用户、更多的场景来打磨,但是一些长尾需求,通常不开源,至于原因么,要么是开源团队把这些长尾需求作为收费项,要么就是开源团队觉得这些长尾需求不够通用,不值得放到产品里。
闭源的产品,通常受众小,没有太多的开源用户帮助打磨产品,就需要经过较长时间的商业化客户打磨,或者,闭源产品的供应商有很强大的质量管理体系,对产品有完备的测试,这就需要找那些家大业大的供应商了,而且,测试人员和终端用户毕竟是两类人群,商业客户的打磨是不可或缺的,只是,如果供应商有强大的质量保障团队,会让这个打磨过程变得短一些。
不管是开源还是闭源,供应商都是带着产品来的,作为甲方可以直接测试,来看产品匹配度,很快就可以得到反馈,而自建团队来做的话,可能需要几个月甚至一两年的时间来开发,业务可能等不起,开发完了之后产品是否真的符合预期,又有很多因素决定,结果具有不可预见性。
其次是服务,供应商相比自建的团队,通常会有优势。原因如下:
因为供应商见识了更多的客户场景,而ToB公司,长期的行业Know-How的积累,是这个公司的核心竞争力,供应商会不断的从优秀客户那里汲取经验,反哺给那些不那么先进的客户,良性循环,多方共赢。
也是因为供应商见识了更多的场景,可以对产品做更好的抽象,可以让产品更通用,更像一个产品,而自建团队做的产品,通常更偏工具,无意冒犯,我说的是通常。
供应商之所以在运维这个赛道创业,大概率是在这个赛道有些建树的,相比自建团队,供应商的顶层认知通常会好一些,你真的去招人的时候就会发现了,最牛逼的那群人,要么创业了,要么太贵了,要么不愿意来。
另外说一下成本问题,供应商的收费大概率是比自己招人(前提是招到合适的人)来得划算,否则的话,商业逻辑不成立。这个道理显而易见不再赘述。
从第三方供应商这里获取运维能力,看起来是碾压自建团队的,所以,后面的文章还用读么?其实也不尽然,对于某个运维能力,到底更看重的是产品能力,还是服务能力,你最需要的是产品能力还是服务能力,需要 case by case 地看,后文,我会从业务侧需要的各个方面的运维能力分别拆解。
业务需要哪些技术支撑能力
运维本质是一类技术支撑能力,跟基础架构团队很像,有些活放到运维团队是可以的,放到基础架构团队问题也不大,甚至有些公司直接把这类人放到业务研发团队,我们暂且不管分工的问题,先来梳理一下业务需要什么样的技术支撑能力。
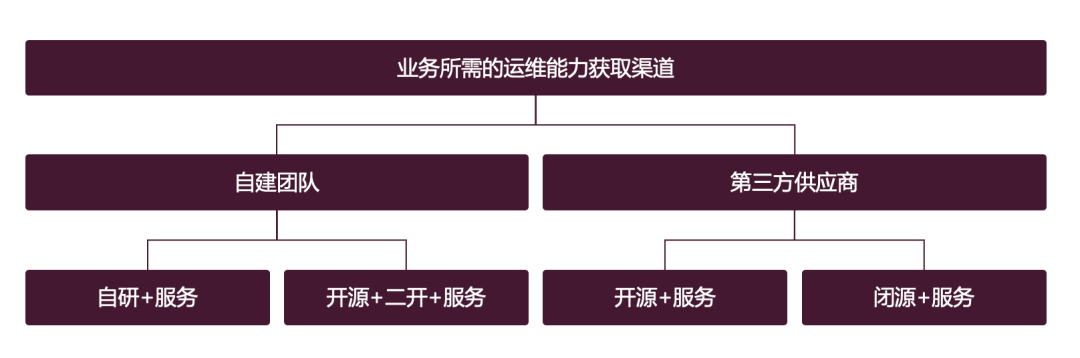
这个图其实已经很能说明问题了,我再稍微啰嗦一下:
可靠的基础环境和组件:业务程序要运行,需要基础网络、硬件、操作系统、数据库、中间件等,需要这些环境和组件稳定可靠;
快速安全变更的能力:快速变更的能力,大家很容易理解,作为研发人员,写了一个feature或者做了个bugfix,肯定很想快速交付,但是变更很容易导致故障,变更需要受控,需要尽量确保安全;
可靠性保障能力:软件部署到生产环境之后,可能会遇到各类问题,如何能够提前做好风险量化,如何能快速发现问题、定位问题、快速止损,这可能是业务侧对运维侧最重要的诉求了;
最佳实践:业务依赖很多基础支撑能力,这些能力用得如何?是不是业界最佳实践?是不是公司内其他大部分业务的最佳实践?需要基础支撑团队反哺给业务。
各个能力如何获取
上面谈及的四个能力,应该如何获取?下面我们就掰开了揉碎了讲一讲。
首先说基础硬件环境,显然有两种选择,上云 or 自建,如果是政策有要求必须自己折腾,那没有办法,以政策为准。如果可以自行选择,现在这个时代,大概率是上云更合适,除非公司体量很大,机器量很大,自建才可能有优势。注意,我这里说的是才可能,算成本的时候切记要把人力成本算上,别只算了硬件的成本。
关于择业:对于系统运维工程师、网络运维工程师,看起来并不是个好消息,云的出现确实抢占了一部分这类岗位的空间,没办法,时代的车轮滚滚向前,大家都是历史的尘埃。
再说组件,比如MySQL、Redis、MongoDB、Kafka、ElasticSearch、Nginx、Kubernetes等等,显然有3种选择,使用云上PaaS产品 or 自己折腾 or 自己出硬件+供应商出方案和服务。针对每种选择,我们分别做一下点评:
云上PaaS产品:如果规模不大,没有相关人才储备,使用云上PaaS产品,是比较合适的,可以快速把能力建设起来,选择使用云上PaaS产品的甲方,通常已经使用了云上的虚拟机、Kubernetes类的Runtime环境,顺带采买PaaS类的产品,也比较丝滑,不需要再跟新的供应商做对接。
自己折腾:如果某个组件规模很大,或许是有自建的必要性的,比如Kafka,自己折腾,招2个人一主一备,水平还可以,出了问题能兜底,在北京的话每年大概100万的成本,得多大的规模才能从硬件和组件上省出这些钱呢?当然,也可以招聘一些低成本的运维工程师(划重点,这里可能需要运维工程师,但是职级不高),能解决日常问题,高阶问题解不了,高阶问题可以求助外部供应商的专家服务。
自己出硬件+供应商出方案和服务:第三方供应商相比云厂商的PaaS产品,通常性价比更高,响应更快,但是组件如此之多,每个供应商大概率只能搞定有限的几款,作为甲方,可能要同时跟多个供应商打交道,略微麻烦。对于需要跨云协同的产品,比如统一监控、故障定位、FinOps相关的产品,如果公司用了多家云或是混合云架构,大概率是第三方供应商更为合适。
关于择业:各组件的资深老炮,第一选择是去云厂商工作或创业输出经验,第二选择去自建组件的大厂,普通中小厂,很难有高薪资,毕竟第三方的专家服务性价比不低。
业务研发最常做的变更是二进制、配置的变更,当然,还有对基础环境以及组件的变更需求。
我们先说二进制、配置的变更,怎么做才能又快又安全地迭代呢?可以分阶段,公司还比较小的时候,不用太关注工具的建设,只需要定好规范和流程即可。规范方面比如:部署在哪个账号下,哪个目录下,日志怎么放,进程怎么托管,任何变更必须能够可回滚等等,流程方面比如:变更通报机制、多模块协同上线机制、无法回滚的需要有审批机制等等。
然后,需要有历史变更的量化数据,比如某个团队最近一个季度有多少次变更,回滚率如何,故障率如何,各个团队有个对比,做得不好的团队就会在下个季度好好改善的。
当公司继续变大,就可以投入人力做变更类的平台,把规范制度落实到平台上,产出量化数据,因为不同的公司情况各异,在传统的物理机虚拟机时代,很少看到有商业化的变更系统。当然,Kubernetes起来之后,屏蔽掉了底层的很多差异,基于Kubernetes做变更平台通用性强了很多,开始有相关的产品出来。
生产环境的变更,和测试环境、联调环境的变更还不太一样,生产环境对稳定性要求比较苛刻,测试环境、联调环境则相对没有太高的要求。所谓的CI/CD的系统,大都是针对测试环境、联调环境的,能够对生产环境做到CD的公司,屈指可数。
划重点:测试、联调环境的CI/CD系统,更多的是为研发效率提速;生产环境的变更系统,更多的是确保稳定性、落地规范制度的。公司前期体量小,靠规章制度就够了,后面就需要规章制度+变更平台协同发力了。
这个规范制度谁来定?变更平台谁来开发?
规范的制定其实偏前期,可能运维团队都还没有的时候规范就已经有了,所以,大概率是CTO以及下辖的Core团队来制定就好了。如果之前没有制定过,运维总监(运维总监上场了)可以牵头制定,CTO下辖的Core团队来评审(大家有参与度),最终CTO拍板(自顶向下)发布,大家执行。
变更平台的开发,由运维团队来开发相对比较合适,后文还会介绍一些其他的平台,成立一个专门的运维团队(这里我说的运维和SRE没有区别,你也可以管这个团队叫SRE团队)是合适的。变更平台因为要落地公司的规范,外采的情况比较少,公司大到一定规模之后,基于开源的东西自研、攒,是个大概率的选择。
关于择业:变更管理是企业中的重要一环,同时服务于稳定性体系。这是一个典型的DevOps岗位,天花板大概在P7+的水平(纯属个人看法,仅供参考)。
另外就是基础组件和环境的变更,典型的比如MySQL表结构、Nginx配置、DNS、VIP等等,这类变更可以内化到组件管控平台里,让组件能力提供方提供变更入口和管控能力。
这个能力非常重要,SRE就是Site Reliability Engineering的缩写,即站点可靠性工程。从CTO的角度,软件部署到生产环境,后续可能会有各种问题发生,希望能有一套工程体系来保障可靠性。这是一个巨大的话题,本文不会事无巨细,只是理清楚哪些事哪些人来负责即可。
所谓的可靠性,就是与故障做斗争的过程,所以,我们还是来看故障的生命周期,从生命周期的各个环节着手,把故障打趴下,甚至直接把它扼杀在摇篮之中。
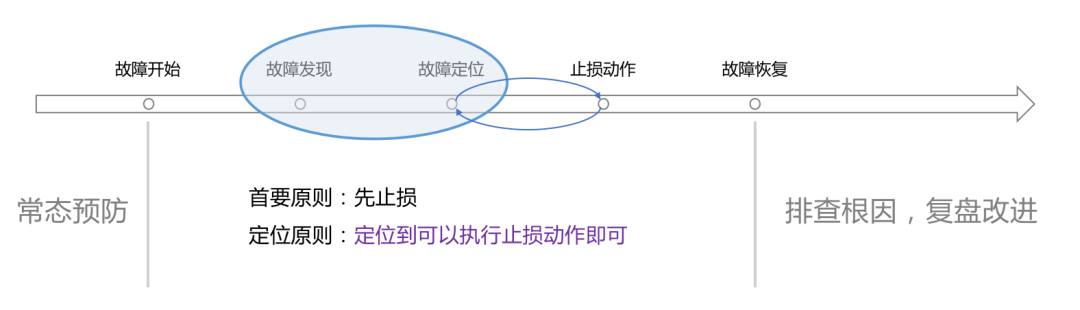
1)故障开始之前降发生
事前的预防和风控,有很多的工作。比如:制定告警完备性标准并对各个业务线做量化评估;制定定位原则和流程以及故障定级定责的标准;提前梳理各个业务的核心功能和服务模块的对应关系,建立全局稳定性视图或者作战室,便于快速揪出故障模块或接口;对架构做优化;梳理故障预案并定期演练保鲜,也就是混沌工程那摊事;等等等等。
这里有些事情是需要业务研发来搞定的,比如架构优化,剩下的事情,我的建议是:让运维团队来牵头,研发配合。比如CTO下辖的Core团队大概率既有运维一号位也有各个业务的技术一号位,名义上要CTO拍板,授权运维一号位来牵头,各个业务的研发一号位来配合,当然了,实际操刀的时候,运维一号位可能是找了一个得力干将来实操,各个业务线可能也是有技术一号位依仗的人来做接口人配合。
除了架构优化之外,其他这些事情都是横向的事情,是可以有一些方法论和最佳实践的,把大家拉通,有利于共享这些方法论和最佳实践。当然,有些人会有疑问:我们能否直接在研发团队找个人来组成这么一个稳定性的虚拟组织,共同推进这个事情呢?其实也可以尝试。不过会有这么几点问题:
每个业务线通常只有这么一两个接口人,人少活多,这个人大概率很难兼顾业务代码开发和稳定性工作,如果这个人全职做稳定性了,其实就相当于SRE了。
如果是SRE,和业务研发人员的考核体系其实是不同的,KPI怎么定?而且这个人可能也没有很好的归属感。
如果这个人同时兼顾两个事情:稳定性、业务研发,可能会引发人的惰性,稳定性工作遇到问题的时候,天然的就会想去干点业务研发的活,业务研发遇到问题的时候,又想偷懒去干稳定性的活。
划重点:事前的预防和风控,请各位CXO找运维总监要结果,但是必须给予极大的配合,从上往下推。对于搞定这摊事的SRE工程师角色,看起来是需要非常专业的高级别人士,工作5年以内大概率认知跟不上,或许,从资深研发团队招SRE是一个不错的选择,各位CXO可以尝试下。
2)故障开始之后降影响
一旦故障发生,我们的首要目标就变成降影响了。相关团队立马协作起来,快速定位直接原因、快速止损,事后再慢慢排查根因即可。这里会涉及如下一些工作内容:
定义故障:通常,业务的指标出现问题就代表故障开始了,比如订单量下跌、叫车呼叫量下跌、支付量下跌,老板会尤为关注这类指标;而某个机器的CPU飙高或者磁盘用满,可能只是团队内部消化的问题,甚至K8s类的系统自动漂移解决,通常对客户主流程没有影响,老板是不关注的。为了不至于草木皆兵,我们就需要区分故障和问题的定义,不同的业务线指标不同,但是总体方法论是一样的。
响应故障:故障告警接收人是给业务研发?还是SRE?还是OnCall中心?不同的公司做法差异巨大,我个人的想法是:直接发给有能力处理的人!没有非黑即白,不同的告警不同的处理机制,比如基础网络有问题,显然是要发给网工,某个业务有问题,发给对应的运维和研发,尽量不要在中间再转一次,发给张三,张三处理不了去联系李四,就浪费时间了,故障处理应该争分夺秒。
快速定位:一套行之有效的故障定位系统,是大杀器。故障定位系统通常是基于可观测性数据构建的,可以看作是驾驶舱级别的产品。可观测性数据是海量的,如果不经过梳理利用,这些海量的数据无法变成有价值的信息。从定位的角度来看,通常需要的是:可观测性体系+故障定位+持续运营。
快速止损:止损要快,就要有完备的预案,每次故障复盘的时候,建议CTO、运维总监关注预案有效率,就是说,这个故障是否是利用一个既有的预案来止损的,还是现攒的解决方案。如果是现攒的,说明你们的预案不够完备啊。
OK,上面洋洋洒洒一片,回归问题,针对这块工作内容,CTO找谁要结果?我的建议是:SRE团队(文中多次出现运维、SRE字眼,在本文中基本都代表一个意思,这里的运维不止是Operations)。显然SRE无法搞定所有的故障,应该说大部分故障都得借助其他团队的人,但是CTO总不能一会找A团队一会找B团队吧。
所以,SRE要携CTO的尚方宝剑,牵头整体的稳定性建设,各个业务需要出接口人极力配合,所谓的稳定性建设,包括事前的预防风控、事中的统筹协同、事后的复盘推进,这也是SRE对公司的最大价值。
这个内容很多,比如用什么机型套餐比较合适,用什么组网方式比较合适,用哪些组件公司具有更好的掌控力、可以得到更好的支持(不管是内部团队还是借助第三方供应商),公司推荐甚至要求的编程语言、框架是什么,业界推荐的接入层方案是什么?变更方案是什么?可观测性怎么做?等等等等。
不可否认,牛逼的业务研发团队,这些实践方式是门清的,但是同样不可否认,业务线多了之后,水平是良莠不齐的,水平差的团队势必需要教练角色的人,总不能啥事都去找CTO吧,SRE团队作为一个横向的技术团队,特别适合负责这摊事。但是显然,这是一个高端职位,新瓜蛋子干不来,招聘高阶人士做业务BP是推进技术栈趋于统一的有效手段,如果CTO用不好这个抓手,技术体系会百花齐放,后面则是各种治理困局。
上面的四个支撑能力,业务侧应该如何获取,CTO应该如何统筹,各团队应该如何配合,大致就说这么多。下面我们再做两个小结。
小结1:CTO如何帮助业务线获取这些支撑能力?
显然,CTO不需要亲力亲为,但CTO要做好把关,CTO要颁发政策,是全军统帅。横向的工作落给SRE团队,各团队出接口人极力配合,大概率是个最佳实践。如果把横向的工作目标完全打散到业务团队自闭环,就无法享受到横向团队带来的经验传播能力。而且,屁股决定脑袋,不在其位不谋其政,各个业务自己容易有小九九,中心的横向组织也是一个削藩机制,抱歉这个词用的重了,本意是好的,你要自己体会啦。
另外补充一点FinOps的话题,FinOps也是一个横向能力,是否也要交由SRE来做呢?这个倒是未必。就让业务自闭环我觉得也挺好的,业务自己要负责盈亏,IT支出是支出大头,业务的GM理应是很上心的,CEO把营收净利相关的KPI压给业务GM,业务GM可以自闭环做好折中的。
小结2:运维/SRE择业建议
如果没有太高的职级和薪资期望,做一些相对基础的Operations工作也是可以的,10年内这个岗位大概率不会消亡。如果对职级和薪资有更高期望,先深扎某个细分领域,做到行业专家,是一条行之有效的路径。再之后,则讲究多个技术方向的融会贯通了,又要往广度发展。再之后,创业或者高管。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721