
一、制定SLIs、SLOs、SLAs
SRE最好从整个软件研发周期的最开始去联合相关的干系人去制定相关的SLI,在未来软件进入生产之后,更好的提供一份比较科学严谨的SLO以及SLA,以及避免在可能在欠缺SLI的情况下导致我们不得不为相关的指标增加开放工作,而且SRE应该为研发团队宣导相关SLI的历练,让研发在实现功能的同时考虑功能相关的SLI数据的埋点上报。这需要我们跟研发团队保持良好的沟通和宣导。
SLIs,服务水平指标,表示对服务能够稳定运行而定义的一些指标。
SLOs,服务协议目标,基于SLI达到的能够稳定运行的目标或者范围。
SLAs,服务水平协议,是跟用户或者客户承诺的服务的可靠情况 是一种协议 当达不到承诺的情况下应该做的事情。


二、可靠性、性能和弹性、饱和度、可观测性
服务时间:
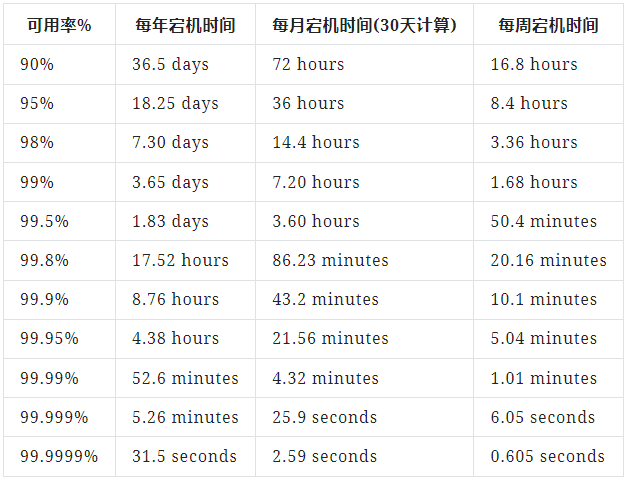
MTTR 是设备从任何故障中恢复所需的平均时间。
MTBF 是在正常系统运行期间,机械或电子系统固有故障之间的预计经过时间。MTBF 可以计算为系统故障之间的算术平均(平均)时间。该术语用于可修复系统,而平均故障时间 (MTTF) 表示不可修复系统的预期故障时间。
MTTF 表示不可修复系统的预期故障时间。
性能和弹性是两个冲突的点。如果我们一味的追求性能,必然导致我们的应用不是太弹性。如果太弹性也就意味着我们的应用性能不是那么强。
这两者的取舍应该取绝于,我们的单体QPS以及用户的对于延迟的容忍度。
这个定义一般是定义我们的SLO,他可以是当前服务承载的容量,也可以是CPU使用率。饱和度最大值应该是我们服务不可用的时候的所表现的测量点。
我们系统的可观测性信号由以下几点:
指标
跟踪
日志
proile
crash
这几个信号会帮助我们显著了解我们系统的稳定性,并能很好的帮助我们在故障的情况下,快速发现并且快速排障。
而且这几个信号我们也应该进行数据标准的统一让几者可以关联起来,更好的帮助观察和故障排查。这也是现代可观测性建设的核心目标之一。
我们应该建设一个具备相关信号的可观测性平台以及推动研发进行相关的可观测性信号能力的接入以及开发。
最好联合相关团队进行宣导,以及最好有在迭代中有10%的人力投入能够做到相关的支持。
1)指标
指标是一个很重要的概念,我们常常忽视他的存在。指标的定义,与监控系统所支持的数据模型结构,有着非常密切的关系。监控数据的来源,从数据的类型可以分为:数值,短文本字符串,日志(长文本字符串)。通常所讲的指标,都是对当前系统环境具有度量价值的统计数据,使我们能够明确知道当前系统环境的运行状态。
指标的定义应该遵循SMART原则:
S代表具体(Specific) 指标是明确的,有具体的含义,能反映具体的属性,有针对性的。
M代表可衡量(Measurable) 可测量指标的活动,包括百分比、数值等。
A代表可实现(Assignable) 能够将指标的值获取到,有技术手段或工具采集到。
R代表相关性(Realistic) 与其他指标在逻辑上存在一定关联性。
T代表有时限(Time-bound) 在一定的时间范围内取值跟踪。
指标数据模型(OpenMetric):
metric_name{<label name>=<label value>, ...} value timestampnode_disk_read_bytes_total{device="sr0"} 4.3454464e+07node_vmstat_pswpout 0http_request_total{status="404", method="POST", route="/user"} 94334
指标类型:
Counter,计数器是一种累计型的metric度量指标,它是一个只能递增的数值。计数器主要用于统计类似于服务请求数、任务完成数和错误出现次数这样的数据。
Gauge,计量器表示一个既可以增加, 又可以减少的度量指标值。计量器主要用于测量类似于温度、内存使用量这样的瞬时数据。
Histogram,直方图对观察结果(通常是请求持续时间或者响应大小这样的数据)进行采样,并在可配置的桶中对其进行统计。
Summary,类似于直方图,汇总也对观察结果进行采样。除了可以统计采样值总和和总数,它还能够按分位数统计。
2)跟踪(Trace)
跟踪对于当下复杂的分布式应用来说是非常必要的。它们可能分布在上千个服务器、不同的数据中心和可用区中,如何监控服务之间的依赖关系和调用链,以判断应用在哪个服务环节出了问题,哪些地方可以优化?
当前最佳的分布式Trace协议选择应该是Opentelemetry。
Causal relationships between Spans in a single Trace[] ←←←(the root span)|+------+------+| |[] [Span C] ←←←(Span C is a `child` of Span A)| |[] +---+-------+| |[] [Span F]
Temporal relationships between Spans in a single Trace––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time[][][][][] [Span F··]
3)日志(Log)
日志也是我们观察系统的一个重要信号,担心当今软件形势的发展,让我们的日志收集和存储受到了巨大的挑战。当我们的应用越来越多的从主机往k8s这种架构转型的时候,我们的日志采集受到了比较大的挑战,而且服务产生的日志也越来越多的,对于海量的日志的检索,我们需要探寻更多的方案。
4)Profile
对于当下云原生的技术的发展,如何对云原生架构下的应用进行profile,也是我们的一个重要挑战,所幸的是由于bpf技术的相关发展,我们可以更好的利用底层技术,去快速的利用bfp相关的技术进行应用的profile从而帮助应用更好的调优。
5)Crash
crash是我们线上环境出现问题之后的重要现场,我们理应建设好相关的crash分析流程,来更好的跟相关信号进行打通关联,从而跟好的做到自动化的问题发现,报告生成。
三、错误预算
我们可以简单的用 SLO目标 + 错误预算 = 100% 来简单的计算出我们的错误预算。我们的一些日常工作例如版本迭代、变更、故障处理都算在错误预算里面,也就是只要会影响SLO的操作,都应该属于我们错误预算的一部分。如果我们超出了错误预算,也就意味着我们的SLA会收到用户质疑,也就意味着我们应该开始排查为啥错误预算的消耗过高,也就是我们应该给错误预算一个阈值范围,在一定范围的功能发布,变更操作都属于正常的,一旦超过某个值,也就意味着我们的系统可能出现了不稳定的情况,这个时候我们应该马上进行总结,寻找问题的原因,快速解决它。我们应该同真个团队寻找到一个合理的平衡点。
四、事务工作预算
作为SRE,我们应该对工作有个要求:
不需要人的地方由机器完成
需要的人的地方由机器辅助完成
所以需要人操作的地方一般属于我们的事务工作,但是我们也不需要将全部的时间投入到事务工作上,比如变更需要手工执行命令,手动的通知开放。这个时候我们应该理一理我们的时间投入情况,如果事务性的工作太多,是不是我们没有梳理好整个发布流程,变更流程。我们没有沉淀出相关的自动化流程。所以一旦发现我们的事务性工作占据太多的时间,一定要停下来梳理,哪些可以自动化的,哪些可以半自动化的。争取将人工参与的部分降到一个合理的地步。
五、风险识别和管理
风险识别与管理,我在大学的时候学的是安全工程,这是一门专门学习如何进行风险识别与管理的学科,但是那都是对于现实层面的风险识别识别与管理,例如机械、工业、化学、交通等领域的,但都有着类似的方法论。
说到风险,我们就要认识一下海恩法则:
海恩法则是德国飞机涡轮机的发明者德国人帕布斯·海恩提出一个在航空界关于飞行安全的法则,海恩法则指出:每一起严重事故的背后,必然有29次轻微事故和300起未遂先兆以及1000起事故隐患。法则强调两点:一是事故的发生是量的积累的结果;二是再好的技术,再完美的规章,在实际操作层面,也无法取代人自身的素质和责任心。
通过海恩法则,我们要认识到事前的风险识别与管理能极大的帮助我们避免相关问题的出现。所以需要我们对于应用架构有着极为深度的了解。并从可用性的角度,去判别应用风险的可能点。
比如当容量过载的时候,系统可能出现什么问题
机房断电,会出现什么问题
域名解析异常,会导致什么问题
我们列出一份详尽的系统风险评估文档。从不同的角度列举不同风险的可能点以及事故预言。在现代云原生的发展下,我们更加可以利用混沌工程等故障去模拟相关风险的产生。
六、事故管理
事故是不可避免的,其实事故不可怕,可怕的是我们没有对事故进行总结学习。只有出现了事故,我们才能对于现有体系的问题进行修复总结,避免同一个事故再发生,所以我们需要对于事故有着细致的报告和总结复盘。
七、事故报告&事故复盘
事故报告是我们了解事故全景的重要手段,我们需要通过事故报告了解到:
事故原因,国内的朋友可以了解一下事故致因2-4模型
事故背景
事故半径
事故时间线
事故干系人
事故处理过程
有了以上的信息,我们才可以详细的知道一个事故的全部面貌,最好我们有一个统一的知识库去存档这些,帮助以后我们了解相关的改进背景以及处理方案有着极好的作用。
研究故障或者失败的逻辑非常重要,复制成功者所做所为,不一定回让你成功,而避免失败者的做事套路,将一定会增加你的成功概率。
底层逻辑:
故障是常态,无法完全避免
故障时表象,背后的技术和管理上的问题才是根因
可以包容失败,但是不允许犯错
个体的失误反而是一件好事
良好的事故复盘能够有效的帮助团队,回顾整个事故的点线面,这样学习式的复盘,能更好的给每个人以比较深刻的印象,最好的是学习之后,能够整理出相关合理的流程帮助未来的事故不在发生以及推动相关工具建设,告警设置以及故障经验。
八、项目研发工作
SRE还有重要的工作是相关系统的研发,因为很多重要平台都是通过SRE孵化出来的,例如可观测系统、海量分布式作业平台,CMDB系统等。因为这些平台的使用才能更好的帮助整个团队提高研发效能水平。
SRE也需要有着相当不错的架构设计能力,因为SRE需要评估研发团队的架构以及SRE团队研发平台的架构。
而且SRE也需要从架构层面去衡量整个系统的可靠性,可观测性等能力,并给出相关的指导意见。
软件工程更是SRE需要深入了解到,因为我们需要参与到研发流程的建设,不管是瀑布式的研发模式,还是现在DevOps敏捷迭代的开发模式,我们都应该完整的了解软件工程。
从我的经历来看,一般SRE团队内部没有专职的项目管理的成员,所以一般需要某一个成员兼职项目管理的角色,这名成员一般要根据项目周期、时间风险、人力投入、技术分析、周边团队协作方面去规范项目进度。一般需要需要经验丰富的人担任。
SRE自身的软件交付质量,也需要有相关的测试流程去把握,但是对于SRE团队来说,最好是做到核心路径的单元测试覆盖,这样在重构或者功能迁移的时候,能快速回归测试迭代,最后通过完整的集成测试帮助上线前的交付验证,避免出现问题。
因为SRE团队一般成员较少,所以自身的研发DevOps流水线一定要建设得比较好,才能高效的产出交付功能,不然就会陷入研发怪圈。
作者丨诸天域
相关推荐:

dbaplus图谱丨SRE体系建设及职能转型指南(附高清电子版)








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721