
岗位要求是对运维已经有了初步的入门,对SRE和运维工程师有了自己的理解和思考。对于运维工程师除了扎实的基础技能之外,对于监控、变更、容量、预案等有一定的认知和思考。
一、监控篇
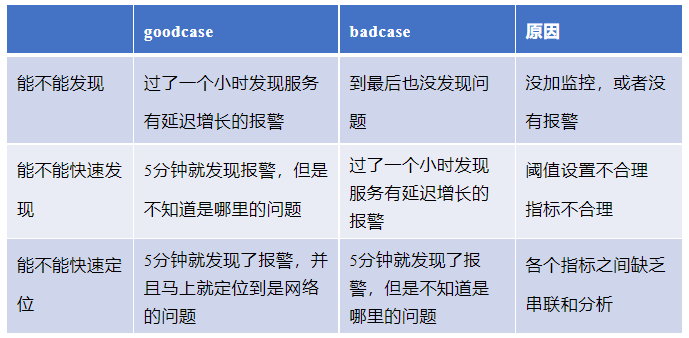
能不能发现?能不能快速发现?能不能快速定位问题?
监控添加的四个方向:
统一入口和门户
紧紧把握核心指标的准/召回率
深入业务链路加监控,比如你的上下游
完善基础监控和指标
第一个问题为什么一定要有核心指标,核心指标的目的是发现问题,是对全局稳定性的把控,核心指标管理越好对业务的掌控会越好。比如当有故障的时候如果去评估影响,那么核心指标的波动就是需要在第一时间去观察和判断的。
说一下我的理解和看法,一切核心指标一定要从业务需要去出发和选取。举个例子,比如是搜索系统,那么搜索的时间就是一个非常核心指标。如果是推荐系统,比如抖音和快手,那么时长就是一个非常核心的指标。如果是存储系统,比如网盘,那么上传文件数和存储文件数就是核心指标,比如电商的成交量,成交金额等。
链路监控:
什么是链路?链路就是一个功能,一个请求的完整流程,比如:cdn→Lvs→nginx→server→db。
如果一个人不了解这个业务如何快速判断问题呢,那么就必须有完整的链路监控,让每个人看到链路就可以对全局的链路有个完整的理解,快速屏蔽业务理解消耗的时间。
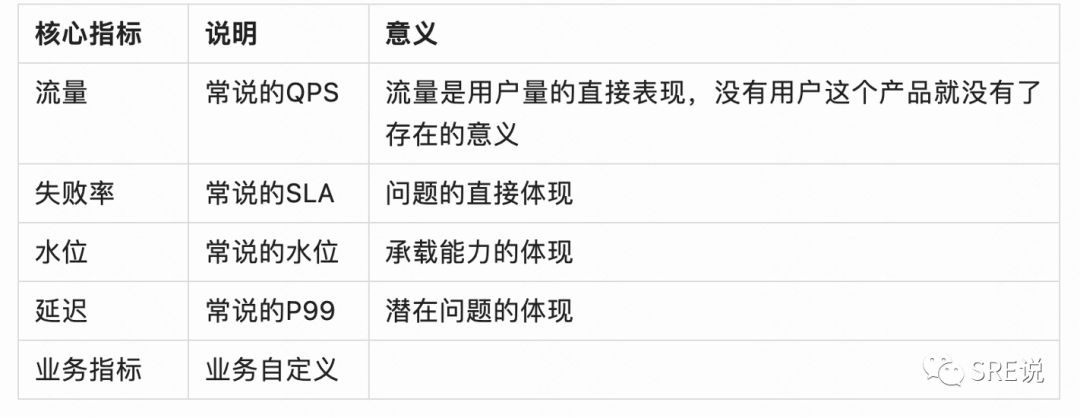
链路监控应该如何做,第一步是梳理其中的关键链路,第二步是关键指标。关键指标其实就是上面的黄金指标,这里有个指标是没有的,想想是哪个指标,为什么?
基础监控:
基础指标很多时候为的不是发现问题,而是定位问题。当有故障或者异常的时候基础指标的完善可以快速定位问题所在。比如单机有故障,如果这台机器的各种基础指标很完善就可以快速定位到是这台机器的什么地方出了问题,并快速解决。
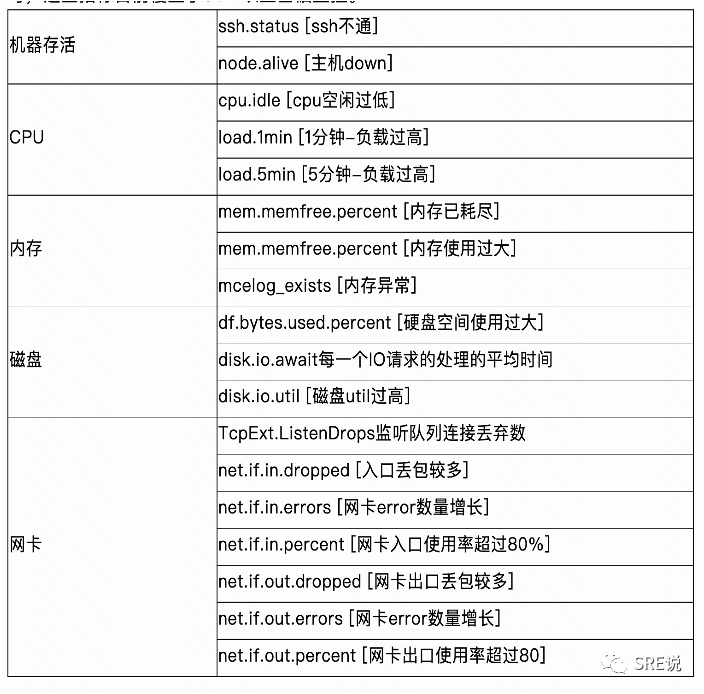
事件监控:
变更事件
运营事件
网络事件
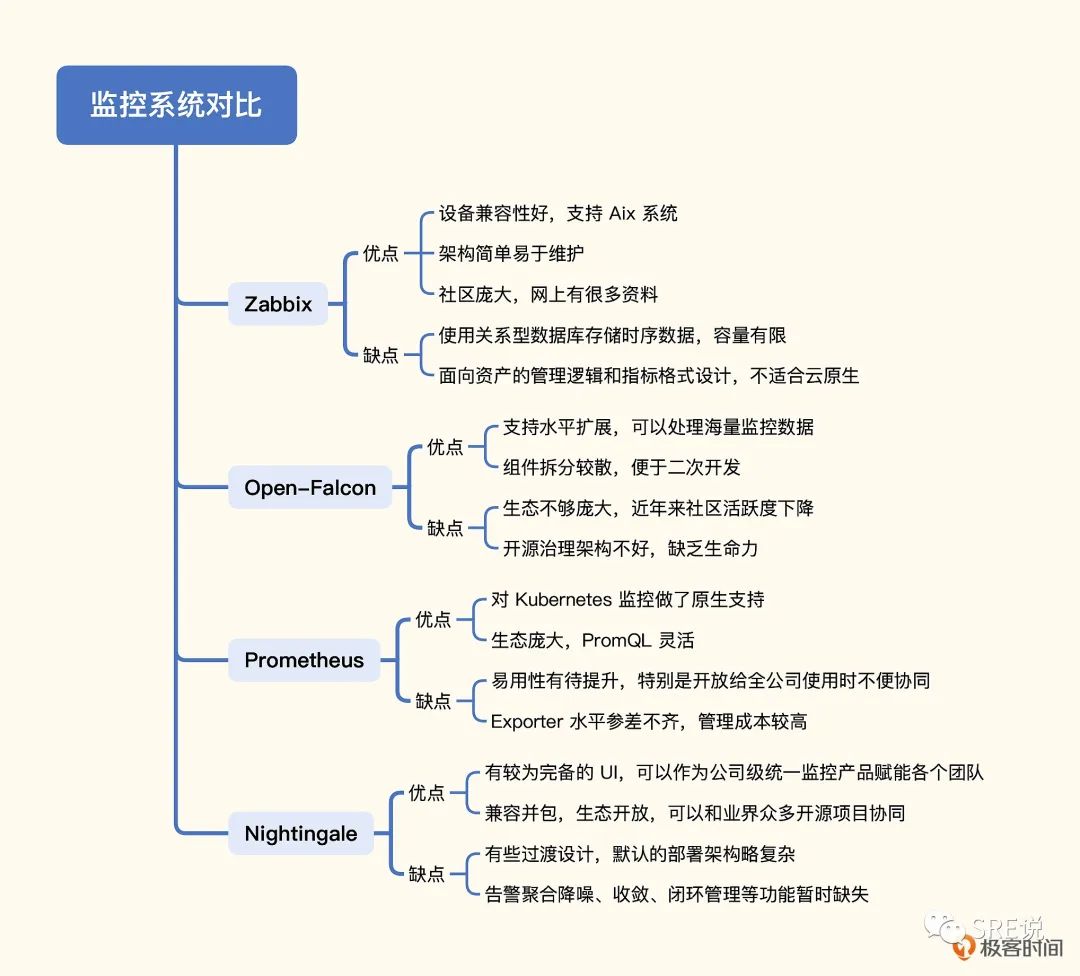
图片来自极客时间
报警合并:把一些一样性质的指标合并掉,或者只保留一个。
报警升级:可以逐级报警。
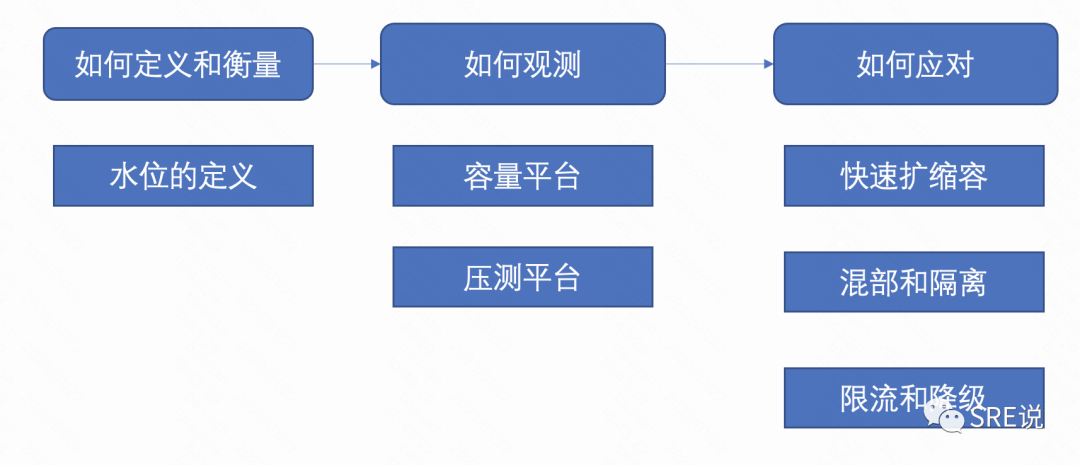
二、容量篇
容量的目标就是资源、稳定性、业务发展三者之间取得平衡,利用有限的支撑尽可能多的流量。
首先是容量如何定义,如果是入口则按照QPS来进行。如果是内部服务,则按照CPU来进行(绝大部分都是CPU,除了少量的)。
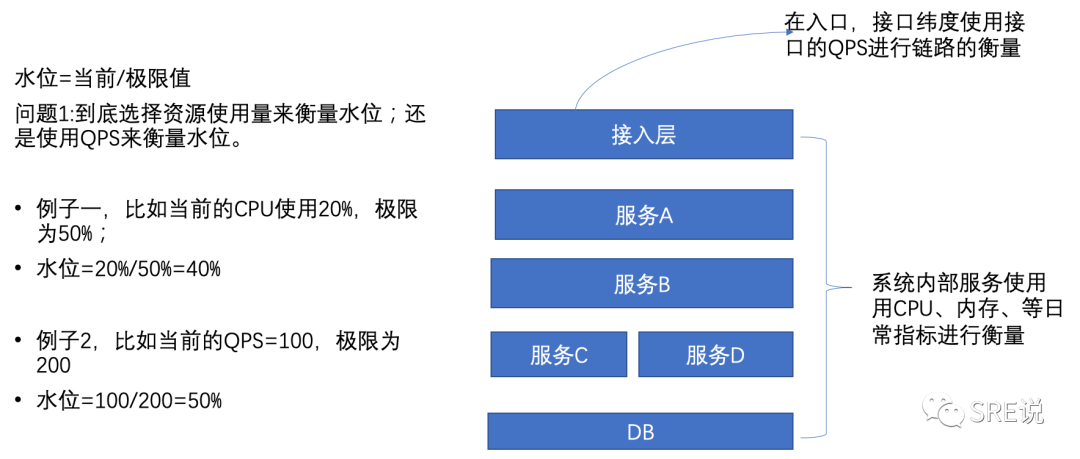
这个是为什么呢?如果在后端服务因为受制于机型、容器配额等等,不可能每一个都压测出一个比较准确的极限值,而且压测成本很高,所以只需要关注CPU就行。
容量数据从哪里来呢?压测、日常监控、经验等,都需要有一个平台来记录。
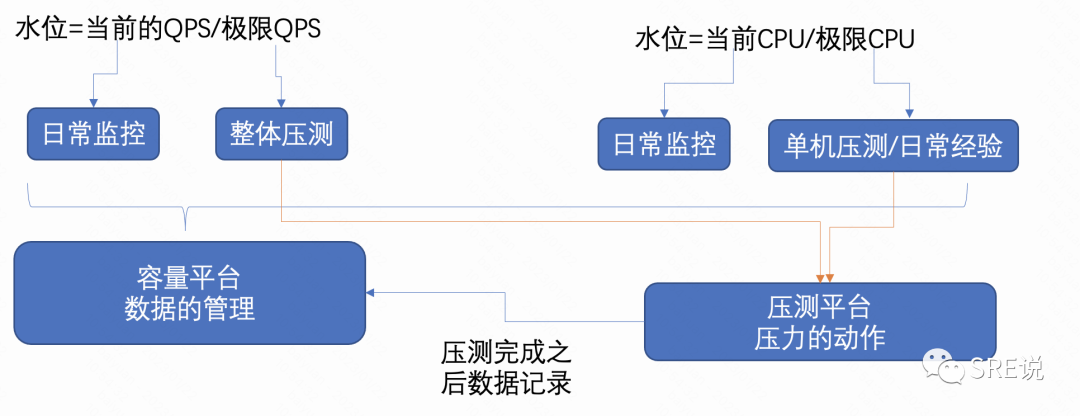
常见的方式有快速扩缩容、限流、降级、错峰、缓存等。
故障1:2021年12月由于西安疫情的加重,在2021年12月20日,西安市“一码通”因访问量过大导致系统崩溃。无法扫码导致许多西安市民难以进行核酸检测。
故障原因:流量突然变大,负载过重,短时间由于各种条件限制无法及时扩容和分流导致。这个跟当年火车站抢票一样。
针对西安健康码的案例,我们应该做什么:
首先是限流,一定要确保自己的服务不挂;
第二是快速扩容,如果服务在云上,利用云上的资源快速扩容自己的服务;
第三是降级,看看有哪些接口没用的,赶紧降级调,把用户最关心的红码、黄、绿 这一个信息保留就行,其他图片加载都可以去掉;
第四是缓存,如果是15分钟查过的就缓存一下,不要让用户无限重试。
(这个问题一般是百度T5,阿里P6以上会问到的问题。)
三、变更篇
变更的目标:在效率和稳定性上取得一个均衡。
目前60%以上的故障都来自变更,这个想想为什么,因为变化才更容易导致问题,不能因为没有故障,就不变更。
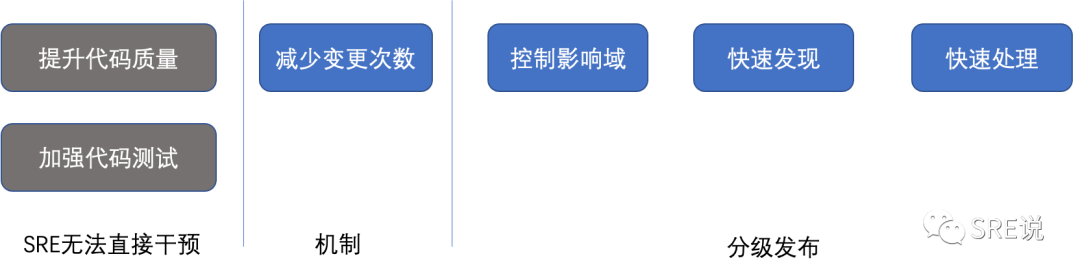
规范、考试、奖惩:分级规范、时间窗口规范、审批制度等。
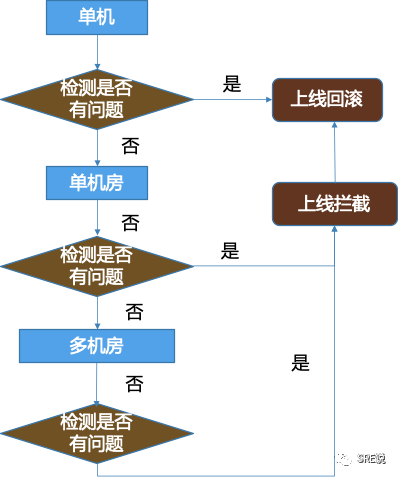
班车机制:核心服务尽量一天之上1-2次;
审批机制:早上10-晚上7点;周一到周五;
强制暂停:单实例-30%-100%(按照业务自己调整);
人工检查:上线单子里面附带相关监控;
一旦发现问题之后,快速回滚,快速切流,快速摘除;
自动检查:上线单子之后指标进行批量检查和自动检查;
自动处理故障:如果单实例,自动摘除,如果是单机房,自动切流。
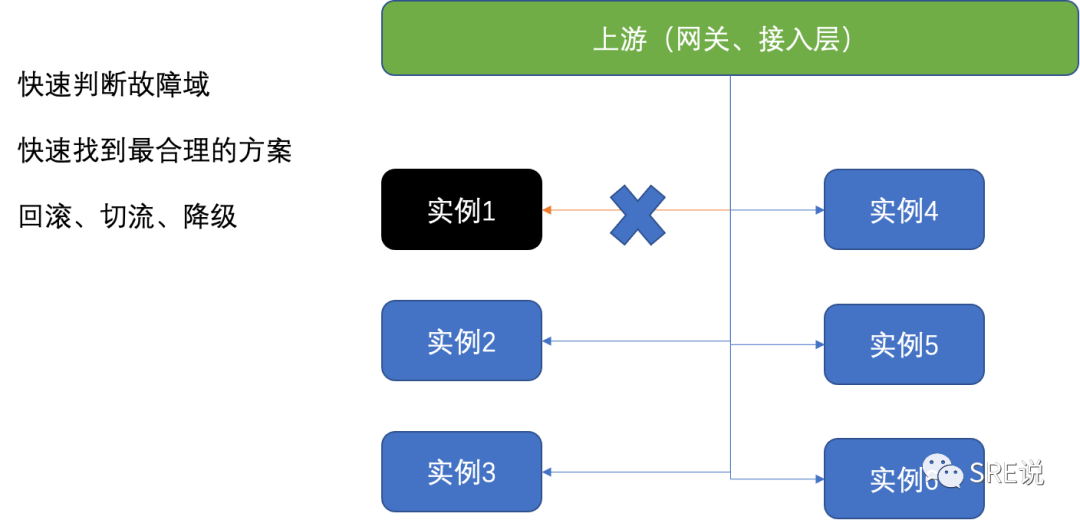
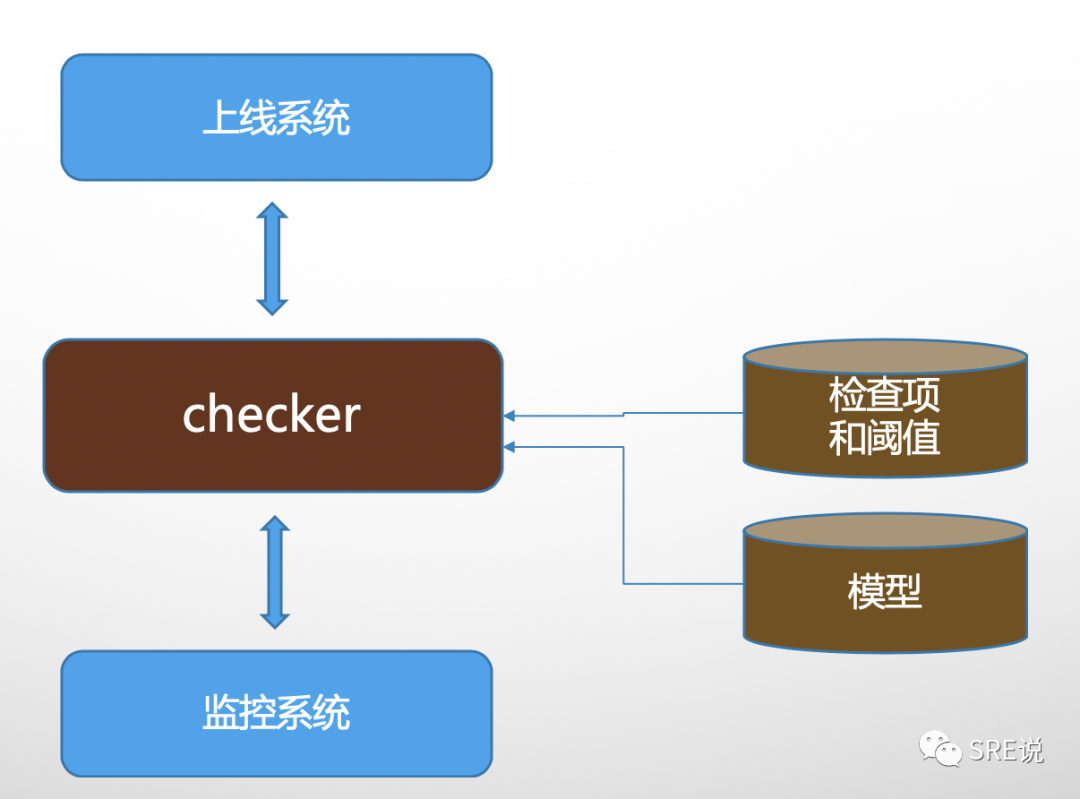
智能检查:
分级发布的一个核心点是,必须要做大量的检查,这样就会给上线效率造成很大的影响,因为可能是多人ci,一个人上线,那么这个上线的同学可以不清楚别人业务的指标是否正常,是否检查完整性会有大打折扣,另外,检查必然会有大量的时间浪费,那么是否可以有一个工具来实现所有指标的自动化和智能化检查呢?智能检查应运而生。
智能在哪里呢,异常指标的判断,一个上线可能有几百上千的指标,不可能去定义每个指标的检查算法,那么这个智能检查就会集成一些默认算法指标,以及上下游的服务。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721