
作者介绍
王鹏,先后在电商、生活服务等行业从事基础架构工作,对于大规模分布式中间件有丰富的实践经验,2017年加入去哪儿网,先后负责机票报销凭证、核心订单数据服务重构等工作,后转到基础架构负责AIOPS体系建设,包括Trace收集处理分析工作,AI智能报警、链路分析以及日志相关工作,为业务运维提供快速、准确、高效的服务。
一、背景
随着分布式系统架构的普及,系统越来越复杂,常常被切分为多个独立子系统并以集群方式部署在数十甚至成百上千的机器上。为掌握系统运行状态,确保系统健康,我们需要一些手段去监控系统,以了解系统行为,分析系统的性能,或在系统出现故障时,能发现问题、记录问题并发出告警,从而达到先于运营人员发现问题、定位问题。也可以根据监控数据发现系统瓶颈,提前感知故障,预判系统负载能力等。
在去哪儿内部,拥有 Watcher 监控体系(Watcher 包括业务线自定义监控指标,通用中间件指标 Knell 体系 )、报警体系(Watcher 自带报警)、雷达(根据智能预测算法进行报警)以及日志体系(基于 ELK 的实时业务日志体系以及离线日志,和错误日志分析系统 Heimdall),但是缺乏一个串联整体的分布式链路追踪系统。在众多开源的 APM 系统里面我们选择了自主研发,主要基于去哪儿网历史技术框架以及 JavaAgent 技术的实现,在整个实施过程中解决了系统大数据量高并发的性能问题以及 Trace 中断,和整个调用拓扑连通性的问题。
二、技术选型
在云原生的可观测性定义中包含了 Monitoring、Logging 以及 Tracing,如下图1所示,这三部分构成了云原生可观测的三大基石。
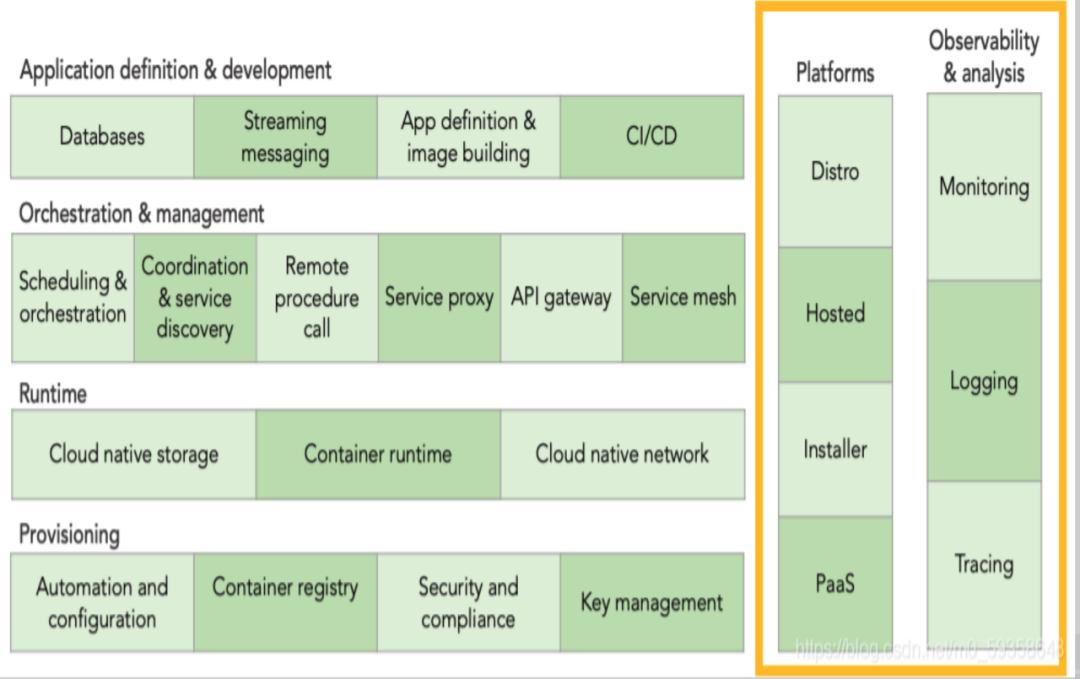
图1 云原生可观测性的三大基石
从图1中可以看出,APM 体系是贯穿于整个云原生开发运行过程中的,是对系统最直观的感受,那么我们要建设一套 APM 系统应该如何选型呢?
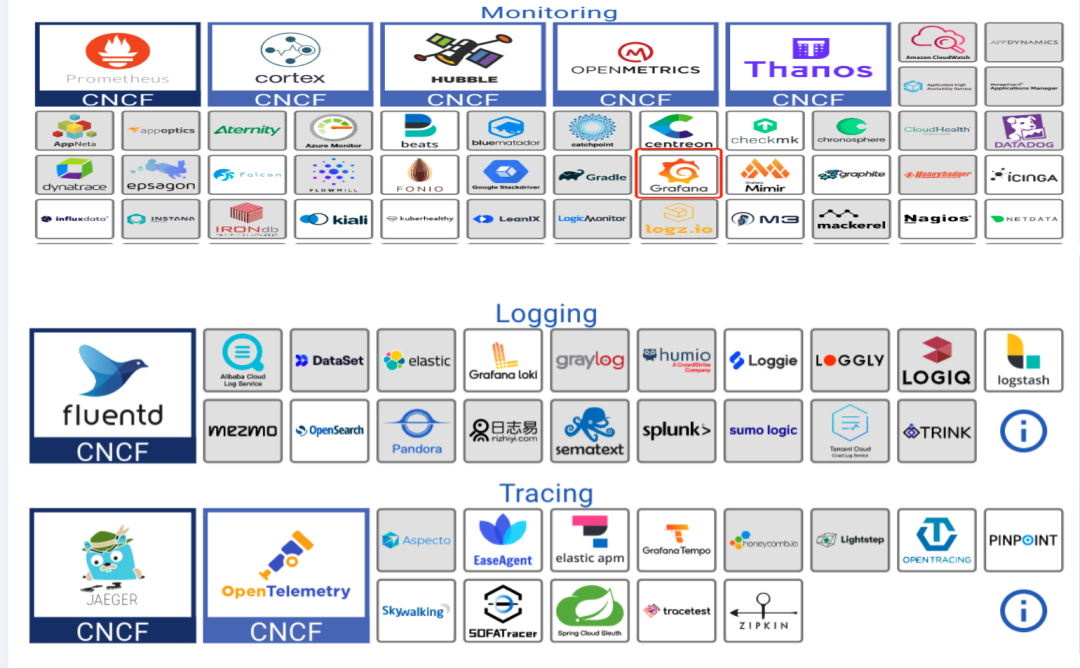
图2 目前技术栈
监控选择 Prometheus 和 Grafana 的组合,这个组合已经在业界非常流行,只需要做一些内部的适配,比如和内部的系统关联,指标关联等等。
在日志这部分也是有很多选择的,从 ELK 体系到 Loki 有很多可以选择的组件,这里更多的问题可能是数据量的问题,因为每天海量日志的传输存储需要耗费大量的资源,包括存储、传输以及处理分析资源。这块的技术选型需要根据公司产生日志大小以及重要性进行分级处理,比如实时日志可以存储到 ES 或者 Clickhouse ,一些非重要的日志可以压缩存储到 HDFS 。
国内比较火的框架有 SkyWalking,是华为开源的一款 APM 工具,架构简单界面优雅,采用 Agent 插装的模式可以不改动现有框架代码自动增加 Trace 相关功能,非常适合一些体量中小的公司,因为这部分公司大量的采用了开源框架,而且数据量不是特别大,存储也可以有很多选择,SkyWalking 适配了非常多的第三方存储。
Jaeger 是国外比较火的一款 Tracing 工具,可以展示相关的调用链路,有一些简单分析,也是采用了 Agent 插桩的模式,不需要改动代码就可以实现 Tracing 的功能,整体来说各大 APM 工具的基本功能都是很全面的,更多的需要结合公司的一些技术栈来选择,在去哪儿这边, Java 是使用最多的语言,其他还有 Python 和 Go,另外在历史的某个时段,也做过很多中间件的人工插桩,自研的分布式 RPC 调用框架,以及 QMQ,分布式配置系统 Qconfig 以及分布式任务调度系统 Qschedule 都是进行过改造。基于这种情况,我们需要做的是覆盖一些常用的开源插件,就可以完成整个插桩工作。
三、架构设计
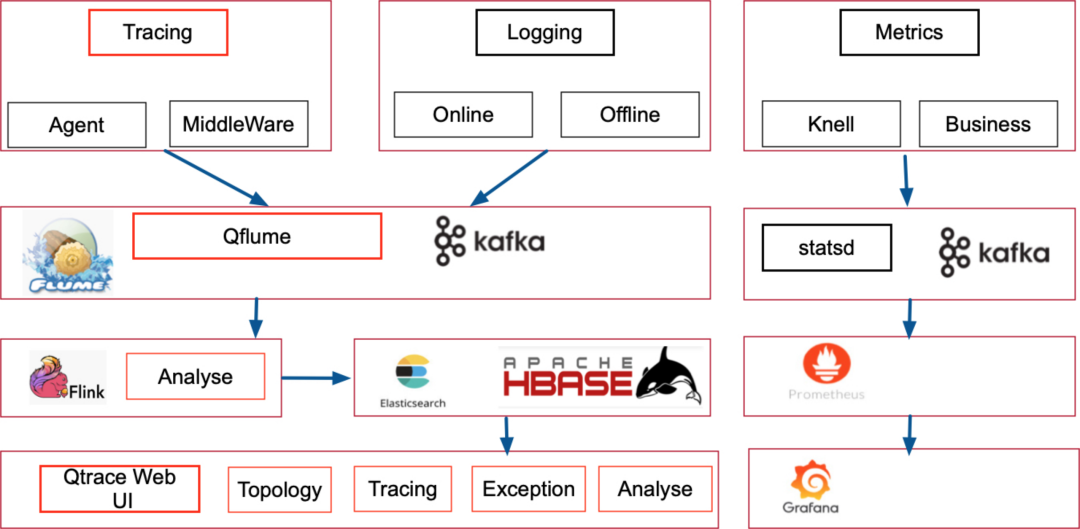
图3 架构设计
基于技术选型阶段的分析,Trace这部分采用自研中间件人工手写代码插桩,其他开源中间件使用Java Agent 插桩模式,这样可以快速构建 Trace 的记录能力,数据传输层采用了 Apache Flume 日志收集组件以及 Kafka 作为我们的数据传输中介,使用 Flink 作为整体接受以及处理分析的框架,最终将数据存储到 HBase 中。展示界面采用了自研的WEB UI,前端采用了 React 框架,展示调用拓扑结构,调用链路,异常日志和分析结果。
四、数据流图
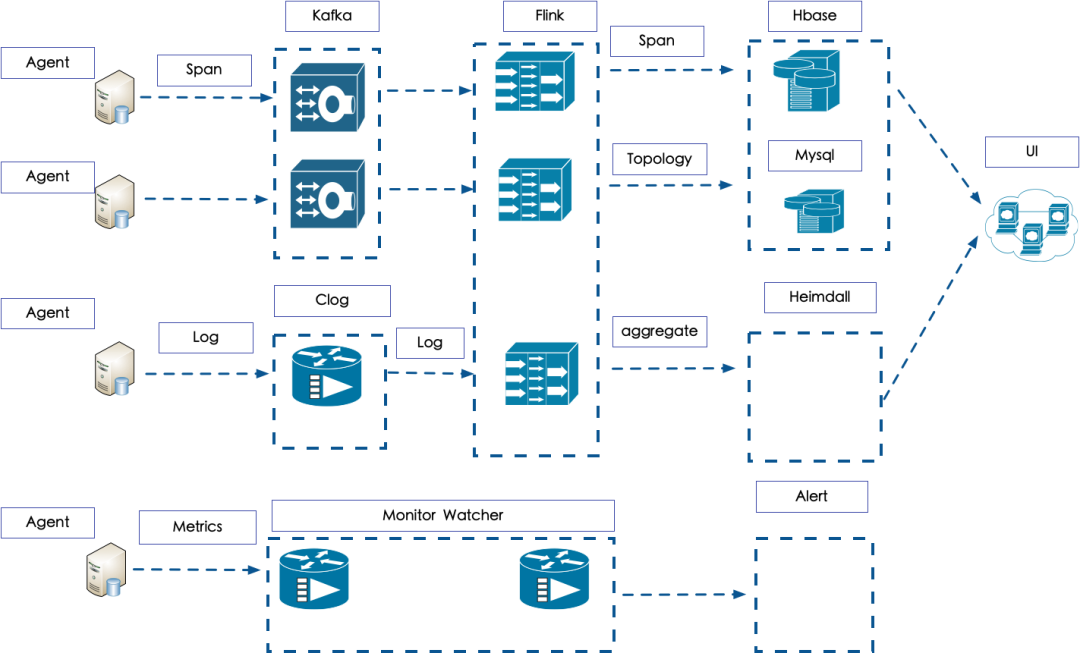
图4 数据流程图
Agent 部分主要负责日志的打印和收集上报,这部分分为两个中间件,一个是用于产生 Trace 的中间件,另外一个是上报的中间件,目前产生 Trace 的中间件是包装现有的开源组件以及部分采用 Agent 的动态插桩实现。上报的 Agent 采用了 Apache 的 Flume ,对于 Flume 进行部分改造,支持日志轮转不丢日志,针对行级别收集,以及在应用中心下发配置,配置收集不同的日志,不仅可以上报 Trace 的日志,还可以实时收集其他日志。
日志上传主要通过 Kafka 中间件,目前公司的所有的机器上报日志都是通过公共的 kafka 中间件上传,最终存储方式会有所不同,Trace 日志经过 Flink 进行聚合,得到拓扑、和聚合的结果。聚合的结果主要包括失败的 Trace,超时的 Trace 等等,拓扑的数据主要是整个调用拓扑结构。
监控部分的上报主要是通过 Watcher 的Agent进行,Metrics 会在 Trace 经过的地方进行采样和埋点,这样在 Metrics 在上报之后,可以通过这种关联关系,查询某个时间点的 Metrics,以获取相对应的 Trace 信息,监控数据会推送到 Watcher 系统进行展示,同时报警配置也在 Watcher 中。
可以通过存储到 HBase 和 Mysql 的数据查询出来具体的 Trace 信息以及相关的拓扑结构,通过聚合结果可以查询到具体的错误量失败率,耗时最大的 Span 等等信息。
这部分数据主要存储Clog中,目前已经转移到数据组统一的 ELK 平台进行存储和查询关联,日志数据格式通过 Logback 配置后,输出指定的格式,头部有 Trace 信息,通过这种关联可以将有问题的 Trace 快速关联到日志,进行排查。
五、落地的问题以及解决方案
技术选型和架构确定后,面对两大问题:trace 中断问题以及 trace 联通性问题。
Trace 中断问题:在一个 Trace 产生的过程中,这条链路会经历很多节点,虽然整个Trace的上下文传递下去,但是出现了中间节点的丢失情况。例如:Traceid : t_123 SpanId:1 (初始值) 如果调用深度增长,会变为 1.1 1.1.1 等,但是在这个过程中出现了丢失现象。由此可以构建出来一个Trace的中断率的公式:
intterrupt_rate = interrupt_span_ount / total_span_cout ,其中 interrupt_span_count 是通过其上下文中span 的 parent 和 child 是通过计算得到的,因为有 child 必然存在 parent。
1)现象以及问题分析
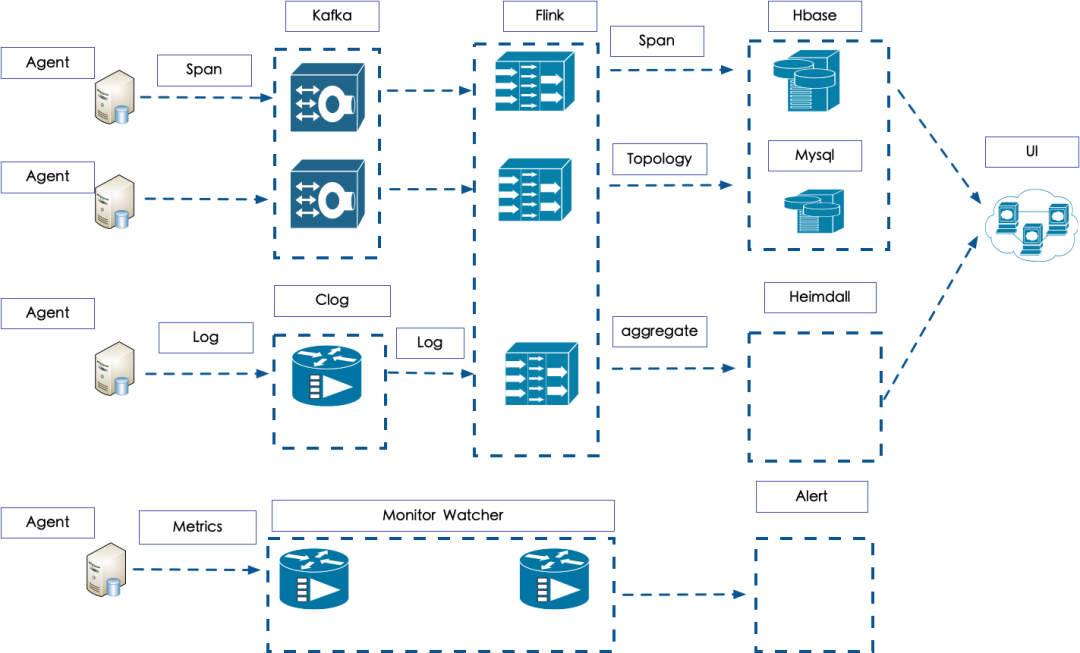
图5 日志
从构建的中断失败率率指标可以看出,采样的 Trace 的丢失率非常高可以达到80%,那么是什么原因导致的呢?整理了一下高失败率的原因,并进行了统计,结果如下表:
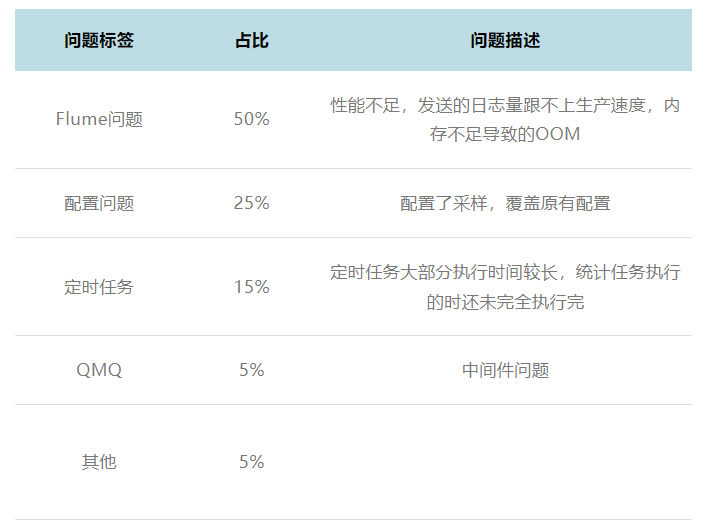
图表 6 统计终端产生原因
这个组件的问题占了50%以上,继续分析每个 case 后发现核心问题是 Flume 性能跟不上日志的写入速度。
通过分析发现丢数据的问题主要发生在异步写数据的过程中,因为后续 Sink 过程中发送的速率跟不上写入的数据量,导致了内存队列日志的堆积,堆积到一定程度就需要丢弃数据,这样导致了数据无故消失,造成了最开始的现象,只要我们对内存队列的大小做扩容,以及将 Sink 改为异步发送,并扩展 TailRead 的并发,就可以提升性能。但是这样做虽然性能提升上来了,这给Flume 带来了巨大的压力,大量的日志需要从 Flume 组件上传,但是不能无限制增加其内存,日志收集组件的内存限制是配置 JVM 参数实现的,在内存受限的情况下,大量的日志传输会造成频繁的 OOM错误,可以从图7中的 OOM 监控显示中看到,整个 OOM 是非常严重的,这也导致了大量的数据传输丢失。
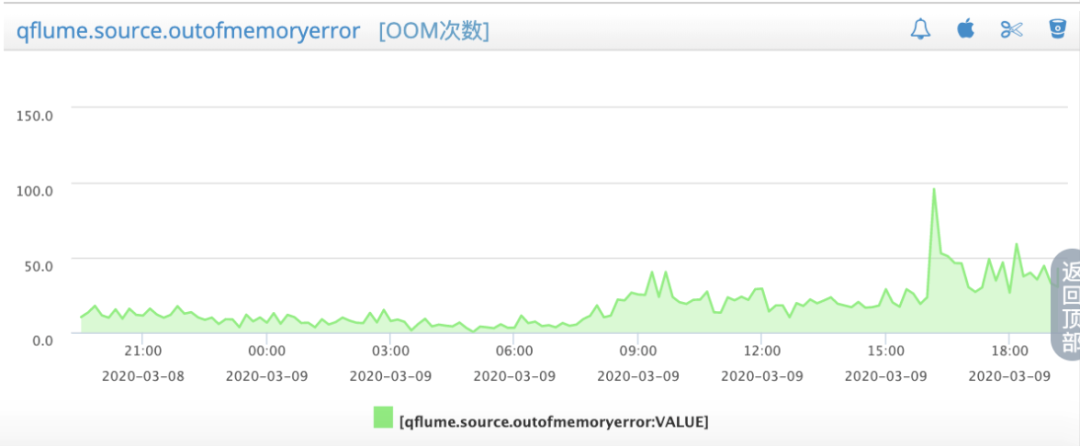
图7 写入速度超过生产速度导致的 OOM 监控
2)OOM的问题解决--滑动窗口限流
如何解决内存不够用的情况呢?增加内存显然不现实,不能占用过多系统内存,保证业务进程的使用。还要让日志稳定的上传上来——滑动窗口限流。
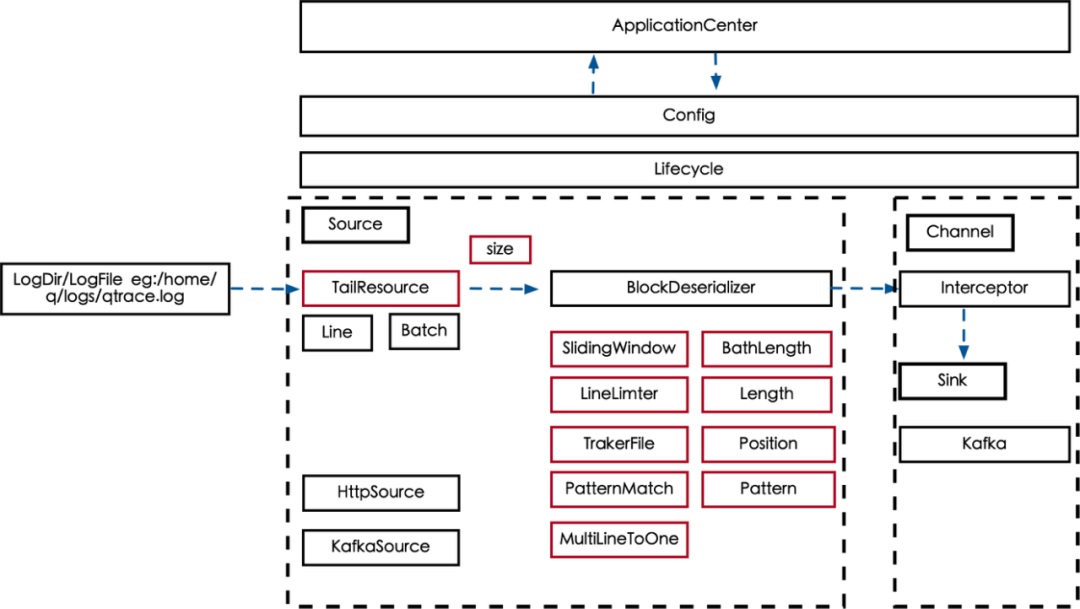
图8 限流
通过对整个传输过程做动态限流,将数据占用的内存容量控制在合理的范围内即可,图8中通过 SlidingWindow 限制一个批次的大小,以及条数大小,以及单条日志的大小,这里为啥要限制单条大小,已经有全部的大小限制了。因为有些日志就一条就可以耗尽你的内存,必须将这些日志进行截断,要不然会频繁的 OOM。通过这些限制,我们就能够精确控制传输组件的流量,以确保不出现 OOM 的情况。
3)堆外内存溢出如何解决?
但是事情往往不是想的那么简单,突发情况!
图 9 出现问题
在部署整个日志收集组件的过程中,发生了一次故障,业务系统的进程突然被Kill,这种情况迅速波及了其他服务,导致了一次“雪崩”事件,为什么我们部署了这个服务会影响到业务应用呢?而且我们明明做了内存限制?在触发问题的系统中,我们发现了奇特的现象。
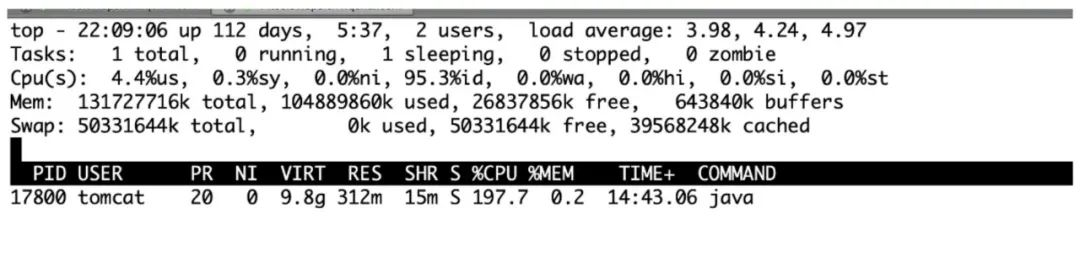
图10 CPU 占比过高
可以看到进程号为17800的日志收集进程竟然占用了197%的 CPU 资源,这台机器已经是业务应用下线的机器,CPU 使用率本身不高,经过查看其他机器的 Flume 资源使用情况,发现占用了大量的堆外内存资源,原因是需要发送大量 kafka 消息,这些消息会缓存在堆外内存中去,大量的堆积会导致整个的系统内存不足,最终 Linux 系统会 Kill 掉占用内存最大的进程,毫无例外都是业务的应用进程,至此算是了解其中原因,如何解决呢?
就是要对 Flume 进程做资源控制,CGroup 技术就是为此而生,通过为 Flume 进程设定 CGroup 资源组,可以控制日志收集进程的资源使用情况,限制其过度使用内存和 CPU 资源。最终整体失败率从80%降低到20%左右达到了预想的效果。
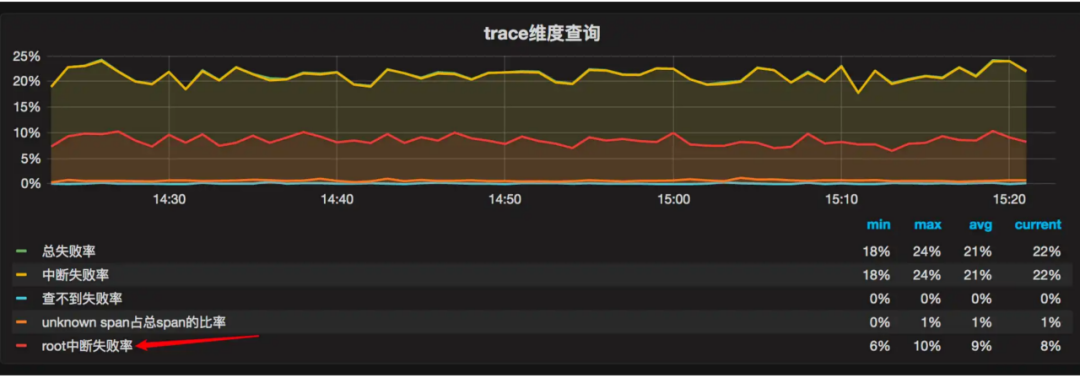
图11 失败率降低
在解决完日志上传的各种类型问题后,数据传输和处理的性能瓶颈逐步展现出来,首先是 Kafka 的性能瓶颈。出现的现象是在日常运行过程中, kafka 集群会出现剧烈的抖动,如图12所示。
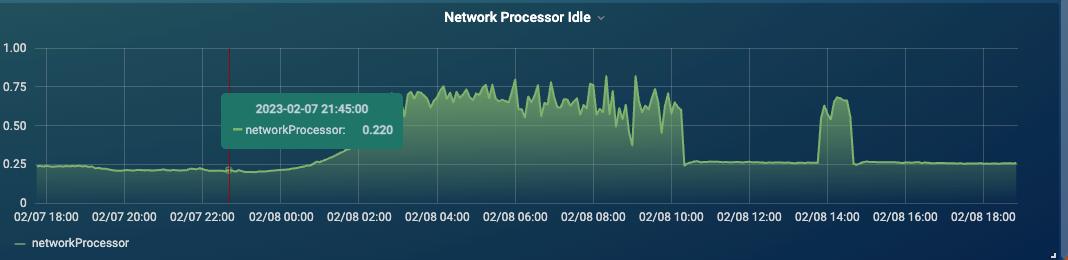
图12 kafka空闲线程数急剧下降
通过监控发现整个集群的网络空闲链接急剧下降,客户端连接数也急剧下降,导致大量的客户端连接超时。通过分析整个 Kafka 的处理流程,我们发现当网络空闲连接急剧下降的同时,Kafka 的写入进程耗时严重上涨。
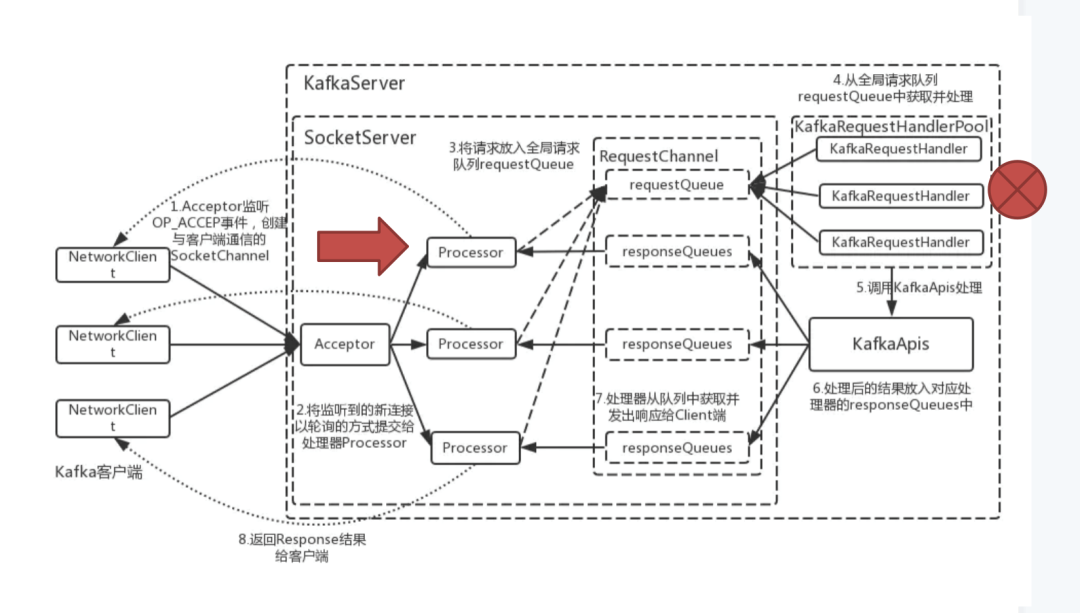
图13 kafka 工作原理图
从图13中可以看到红色标记的部分是 Processor 的数量大量降低,原因是在 RequestChannel 中处理任务的 KafkaRequestHandler 性能下降导致,这个 Handler 主要负责写入数据和索引,当磁盘 IO 达到机器性能瓶颈时,就会导致这种情况。因此,我们就需要优化写入性能,分散更多的 Partition 以及写入慢的机械硬盘升级为SSD。
通过这些调整从以前的数据处理不稳定状态转为平稳状态。
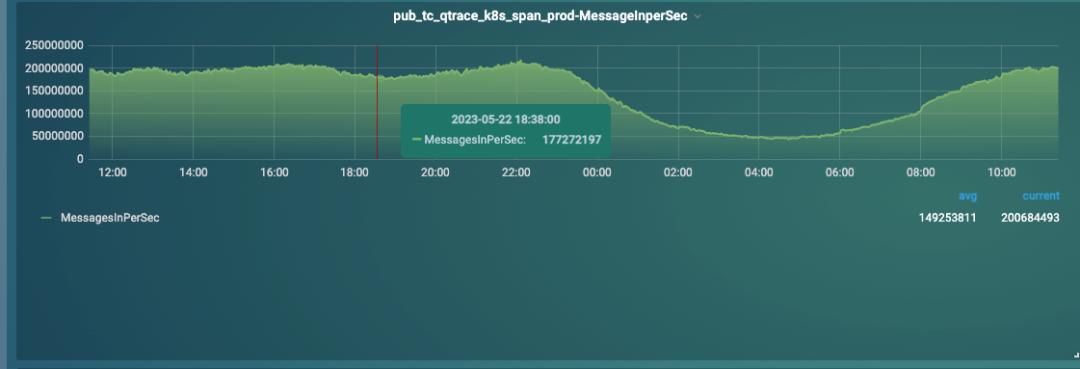
图14
Flink 处理模块主要是处理所有的数据,包括解析,分析、根据各种维度的聚合,需要聚合相关的拓扑以及各种维度的索引。
由于 Trace 的数据量非常大、平均 QPS 可以到300w,在数据处理模块中,最常见的问题就是背压。何为背压?顾名思义就是在数据流从上游生产者向下游消费者传输的过程中,上游生产速度大于下游消费速度,导致下游的 Buffer 溢出,这种现象就叫做背压。
背压出现的原因是下游任务处理能力不足,如何优化背压?
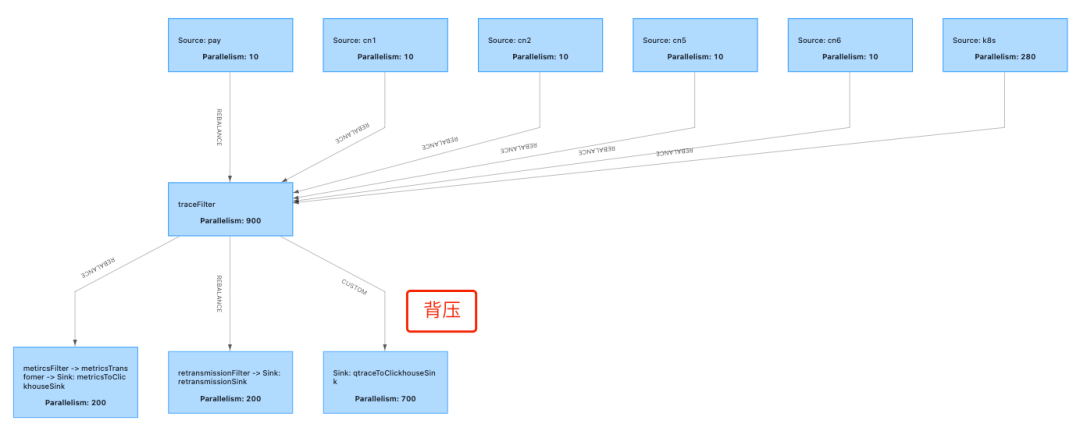
图15 背压
SubTask 是否消费均匀,Yarn 集群分配资源是静态分配,这会导致运行期资源不足。为什么需要看子任务是否处理数据均匀?
如果在分配任务的过程中数据存在倾斜,数据不均匀,会导致整体任务处理缓慢,部分算子背压严重,严重影响整个集群的处理速度。例如在这图中的 Trace Filter 到 Sink 的过程中,会出现背压,原因可能是数据不均匀,或者本身存储数据的缓慢导致处理速度跟不上,上游的生产速度所以产生背压。遇到这种情况,需要调整内存大小以及观察Sink性能,除此之外还需要关注算子的计算是否均衡。如果不均衡需要看本身的 Hash 算法是否能够保证Trace数据均匀分配,以及不同的 Task 的资源抢占情况,综合调配。
算子的 Input 和 Output 是否一致,内存是否充足。
发布 Flink 任务时,需要设置JVM内存大小,JVM参数需要根据上下游的算子数量以及传输数据量大小进行配置,配置过小就会导致堆积和背压。算子的内存大小是也需要根据当前存储的BathSize去预估,需要留有一定的Buffer,防止 OOM 发生。
使用内存 Map 替代聚合 Window 。
很多情况下,只需要缓存部分数据,则可以采用内存 map ,性能会大大超过 聚合window 的性能。但是存在丢失数据的风险,需要根据情况确定。
Filter 一定小心下游算子的拥堵导致全面的拥堵,压缩算子传递数据,使用 ShargeGroup 共享 JVM。上下游的算子如果配置 ShareGroup 则可以共享 JVM,这样避免多余的网络传输,提升整体的执行效率。
何为 Trace 联通性?一个调用拓扑其实是一种图,这种图可能是有向无环图 ,也有可能是有向有环图(存在 QMQ 的回调导致的环装调用),如果是有向无环图的情况,即无法从某个顶点出发经过若干条边回到该点,对于真实的 Trace 来讲,有一种情况可能会打断这种图结构变为,多个图结构。
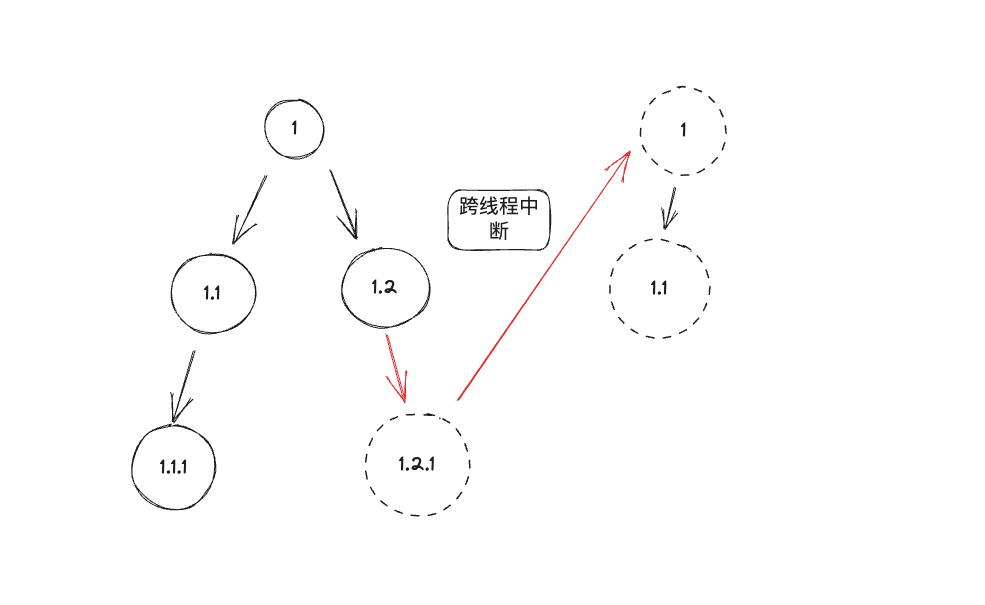
图16 跨线程中断
图中展示的调用在1.2 → 1.2.1 的过程中出现了跨线程或者跨进程,导致上下文丢失,最终一个新的调用拓扑产生,但是本身他们应该隶属于同一个拓扑结构,或者图结构。解决联通性的问题核心思路就是:保证跨进程或者跨线程保证 Trace 上下文信息传递。
1)跨进程解决方案-中间件自编码
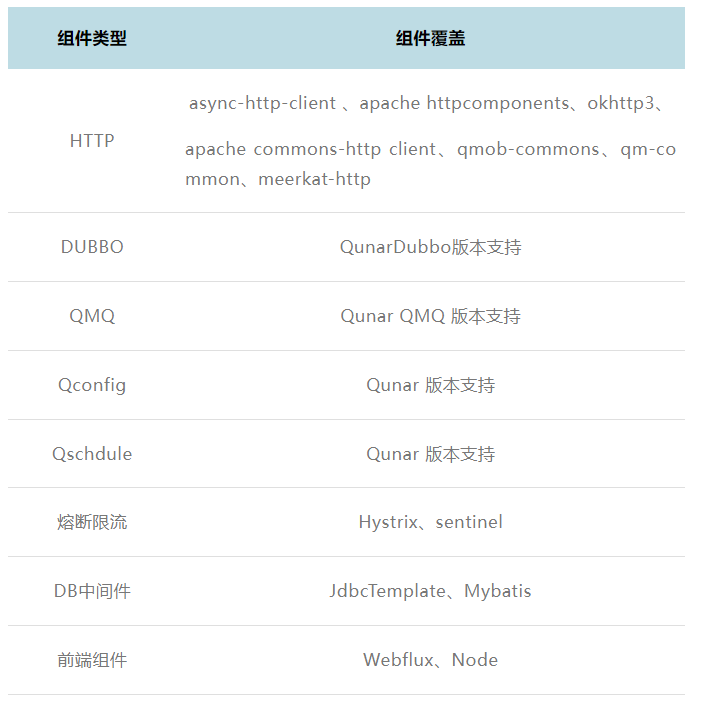
跨进程的解决方案主要依赖于对于内部中间件的硬编码实现。支持内部中间件体系(Dubbo QMQ QunarAsyncHttpClient QunarHttpClient Qschedule Qconfig )、常见的开源通信中间件(Apache http client 3 &4 版本 okhttpclient ),业务常用组件基本都已经支持列表如下:
2)跨线程解决方案--JavaAgent自动插桩
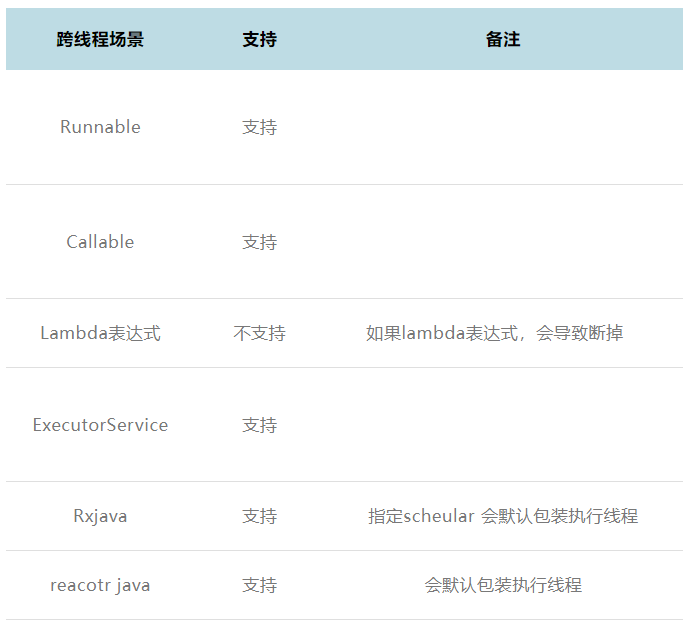
对于业务中经常使用的异步编程,采用 Java Agent 探针的模式来支持,内部跨线程问题是导致中断的主要原因,在 Qtrace Agent 里面已经全面解决,包括 Jdk 提供的Runnable Callable ExecuteService Future Rxjava Reactor java 等跨线程问题,通过 Agent 插桩的方式来弥补丢失的上下文信息。
如果没有 Qtracer.wrap 的话,及时有 QtraceAgent 都会中断
CompletableFuture<Integer> future = CompletableFuture.supplyAsync(new QTraceSupplier<>(()->{LOG.info("supplyAsync------"+QTraceClientGetter.getClient().getCurrentTraceId());return 1;}));Integer i = future.get();LOG.info(String.valueOf(i));CompletableFuture<Void> future1= CompletableFuture.runAsync(QTracer.wrap(()->{LOG.info("runAsync------"+QTraceClientGetter.getClient().getCurrentTraceId());}));future1.get();executor.submit(QTracer.wrap(() -> {LOG.info("in lambda------"+QTraceClientGetter.getClient().getCurrentTraceId());}));executor.submit(new Runnable() {@Overridepublic void run() {LOG.info("in lambda------"+"in runnable"+QTraceClientGetter.getClient().getCurrentTraceId());}});
3)JavaAgent性能
如果想将 JavaAgent 插桩模式应用在所有的系统上,则性能评测数据,是一个重要的指标,性能问题主要体现在使用Agent后,请求耗时、吞吐量是否收到影响。首先明确几个概念:
裸请求:未使用 agent,未使用 Qtracer 组件包装,直接发送请求;
Agent:使用 agent 字节码修改拦截的方式去支持 Qtrace。
①对于HTTP请求的影响
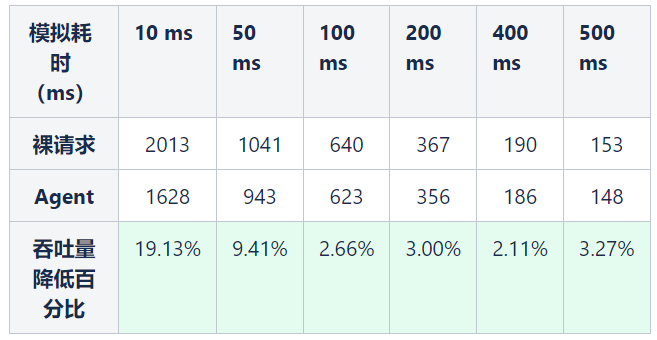
总结:对于 HTTP 请求通过 JavaAgent 插桩后,超过 50ms 的请求,整体吞吐量最多降低4%,耗时增加最多4%。
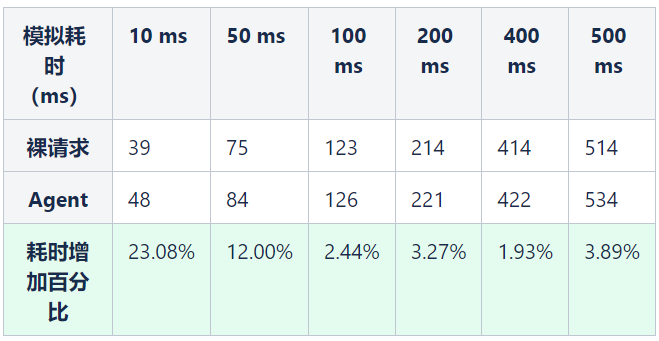
②对于跨线程的请求影响
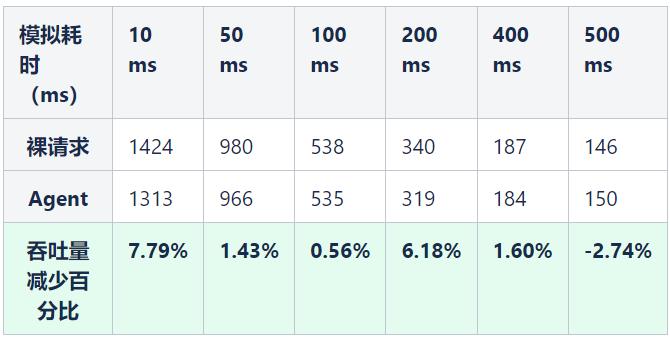
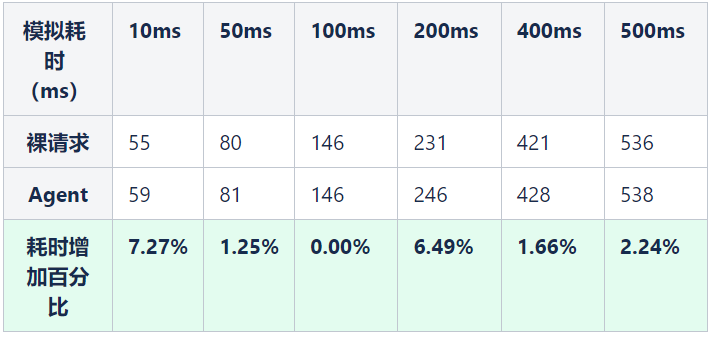
结论:对于跨线程的场景,耗时在 50ms 以上的平均吞储量降低3%左右,平均耗时增加3%左右。
对于业务线来说,正常的请求一般都是超过 50ms 左右,所以 Agent 对于整体性能的影响不是特别大,针对于某些对于性能要求严苛的场景,则采用了编码的方式来解决,比如访问 redis,访问 db 操作等。从功能和性能两方面验证了 Agent 的可行性,随着全面的部署 Agent,整个 Trace 的连通性得到了极大提高,从以前的 20% 左右的联通度,到现在 80% 以上的联通度。基本解决了跨线程和跨进程断掉的问题。为整个业务拓扑完整性构建打下坚实基础,也为后续的全链路压测以及混沌工程提供坚实的基础。
六、总结
整个分布式链路追踪系统,从技术选型、架构设计以及落地的过程中,遇到了很多结构性问题和性能问题,从问题分析到定义指标最终解决问题,积累了很多经验,不同类型的问题都是可以通过定义指标、数字化指标、分析问题、逐步拆解、最终分治解决,希望对大家在建设 APM 系统的过程中有所帮助。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721