
本文根据高鹏老师在〖2023 中国数据智能管理峰会-上海站〗现场演讲内容整理而成。(关注【dbaplus社群】公众号,回复“230331”可获取完整PPT)

讲师介绍
高鹏,新浪部门主管。在高可用架构设计、业务逻辑设计和优化方面,有较为丰富的经验。目前负责新浪智能数据分析平台建设,致力于运维大数据价值挖掘,提升运维服务质量和产品用户体验度。ClickHouse中国社区发起人之一,国内最早大规模使用ClickHouse的用户之一,对ClickHouse的架构、使用、优化,有较好的理解和实践经验。
分享概要
一、基础设施研发
二、监控产品演进
三、AIOps应用
四、数据科学应用
五、未来展望
一、基础设施研发
我们属于新浪微博的基础研发团队,如图所示,我们需要负责三层架构:运维基础设施、服务端和客户端业务运维。
运维基础设施层(运维平台底座):内部混合云平台、CICD系统、K8s私有云容器平台、4层/7层负载均衡等;
服务端:SLA、服务拓扑、成本优化、服务日志;
客户端:APP、PC、H5、小程序等的运维保障。

依据不同业务场景,我们建设了垂类监控、智能报警、链路追踪,同时也基于一些经典算法,实现了智能监控告警。
在技术选型上,主要做了哪些考虑呢?
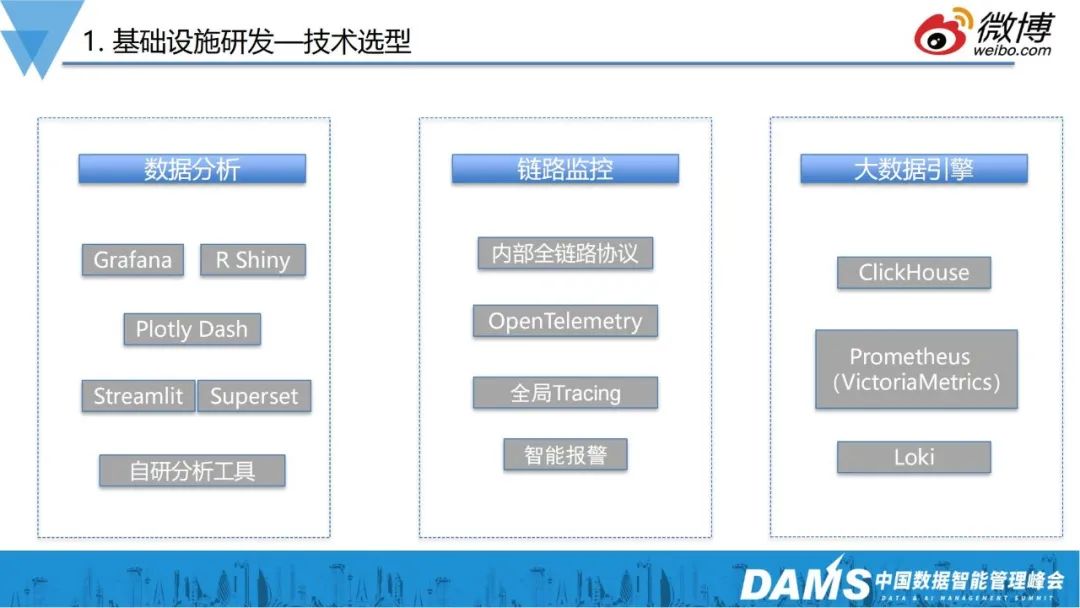
1、数据分析
可观测本质上是以大数据为底座的,所以数据分析非常重要。所以我们引入了数据分析领域比较专精的Grafana、R语言、plotly、Shiny等,来搭建数据可视化场景和框架;
2、链路追踪
存量业务很难实现标准化。在两三年前,我们就在内部推广了一个全链路监控协议,虽然不如OpenTelemetry,但基本上实现后端资源监控的目标,现在我们新的业务则逐渐以OpenTelemetry作为标准;
3、大数据引擎
三四年前还没有可观测性的概念,当时还叫监控平台,当时还面临着比较大的数据分析问题,用传统的Hadoop框架,抽取各种数据层次,再把数据从Hive提取到MySQL,这样一通操作,只能实现T+1的分析报表功能。
之后流行的ES方案,也有很多问题,如复杂查询性能差、资源占用高等;Spark、Flink等流式计算,也存在上手难度大等问题。
监控应该是一个7*24小时的服务,不是离线服务,所以亟需一个非常高效的工具来解决慢速查询的问题。

对比了业界比较常用的一些方案后,我们最终选择了ClickHouse作为查询引擎。

左图是新浪微博线上的一些数据表,基本上都是百亿、千亿级的规模,由于ClickHouse速度快、性能好、资源占用率低的特点,一些复杂SQL都可以在极短时间内返回我们想的结果。目前为止,ClickHouse每天承载的数据量大概在3,000亿条,每秒的数据量大概在500万左右。
在一次热点事件中,峰值达到近千万QPS,我们仅用了30台服务器,就承载了这么大数据量的数据分析工作。所以,不管是运维,还是传统数据分析,ClickHouse都是一个利器。

基于这些考虑,我们把ClickHouse作为整个数据分析平台的基础设施。
原来的架构中,数据流是非常复杂的,导致整个数据生命周期难以维护,有了ClickHouse作为超高性能的数据底座以后,我们的数据就变得非常简单。
上层对接各种业务层数据,这些数据通过Kafka数据总线,最终通过ETL流程写到ClickHouse数据仓库里,运维和数据分析师则可以直接在ClickHouse上面做查询。而对于需要长期保留的数据,我们开发了一些工具把这些数据打捞到MySQL等持久化存储。
二、监控产品演进

有了数据平台后,要由上往下去建设产品层面的监控,做好产品侧的“最后一公里”。
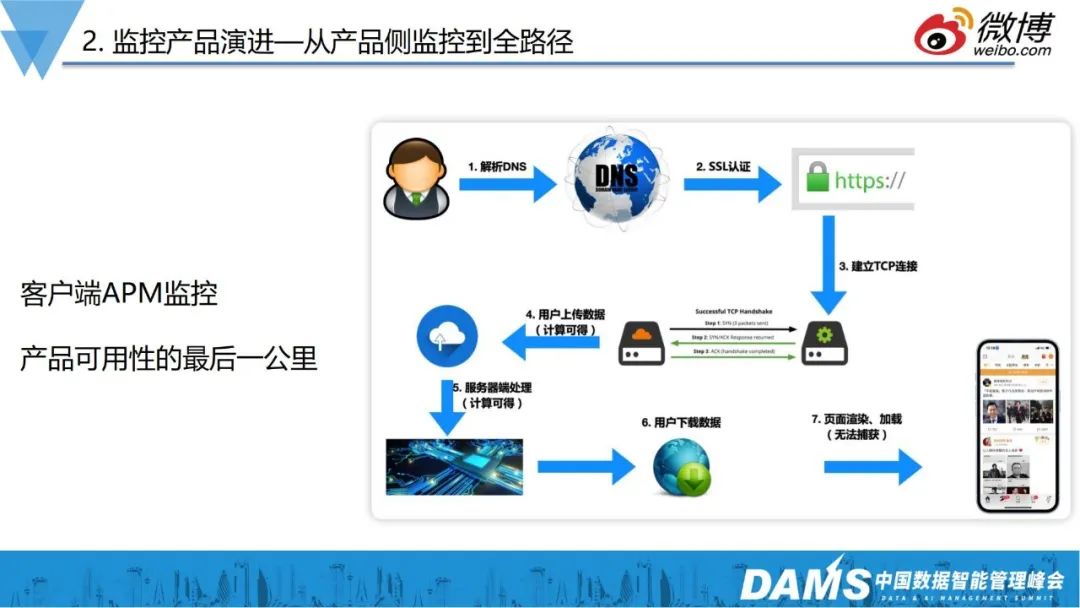
上图是一个典型的移动端访问的链路路径,大部分场景下,大家使用的是移动互联网产品,90%的用户喜欢用手机进入微博,而移动网络本身存在很多不确定性,如网络问题、3G/4G/5G/Wifi切换的问题、IPv6的问题、DNS问题等。
比如早年接到用户投诉,反映安卓客户端提示APP要升级,点进去之后变成了其它APP,端上请求下载的是新浪apk,但是却变成了别人的apk,发生了DNS劫持问题。但HTTPS全量铺开后,这类问题基本上也不存在了。
再举一个跟DNS相关的例子,之前接到一个用户投诉,客户端访问非常慢,我们打开了他端上的日志,发现用户本人在北京,但访问到的服务到了广州,就导致了客户端访问慢的问题。大家都知道现在大部分本地化调度,基本上都是基于DNS来做的,DNS根据你的Local DNS IP来源, 返回给你一个离你最近的一个IP。由于运营商的Local DNS大部分都不是eDNS,所以无法通过用户真实IP判断。后来看了用户的APM日志和DNS,发现其可能通过某些“优化软件”,把手机系统DNS的IP篡改了。
再如疫情期间推出了疫情地图这样的产品,这些页面基本上都是一个接口去后端取数据,再交给前端JS渲染,逻辑非常简单。有一天早上某同事发现疫情地图白页挂掉了,但查看后端数据一切正常。后来发现,后端返回的数据里,有一个int型的数据,不知道什么原因,成了字符串,导致端上的JS在渲染的异常。
上述种种问题都表明,如果想做好用户产品体验的话,首先要保证的其实就是产品距离用户的最后一公里,也就是产品侧APM监控。
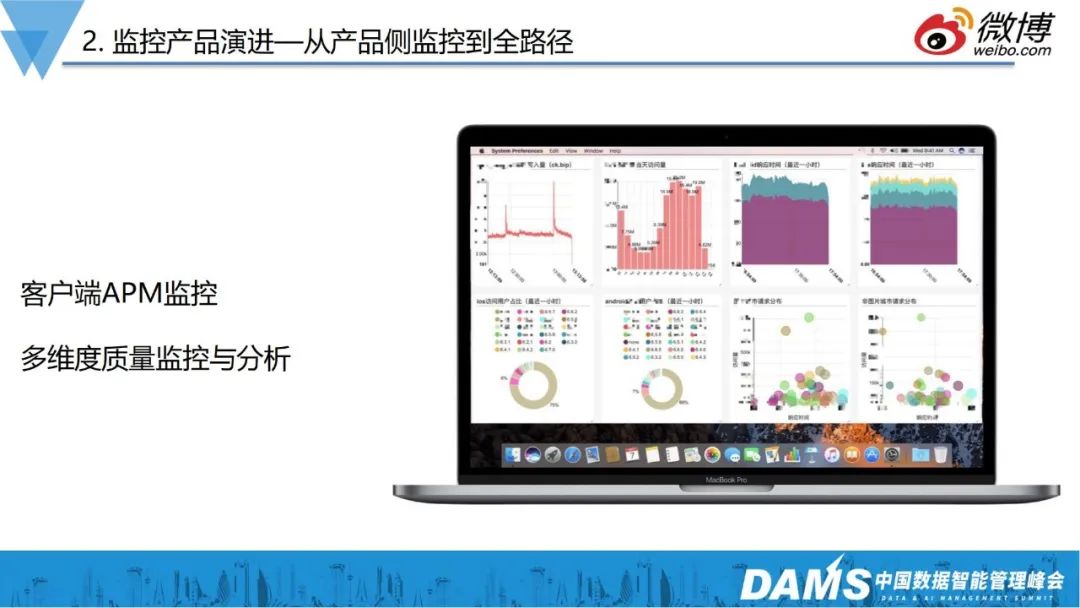
有了产品侧的APM监控后,就能够很明确知道服务在用户层面到底是怎样的体验:访问CDN的质量怎么样?CDN作为IT成本较高的服务,不同厂商的质量到底怎么样?钱是不是花得值?
我们现在都是用混合CDN,有了APM数据后,就可以判断各家厂商的覆盖程度有没有达到承诺,这是产品保障非常重要的指标。
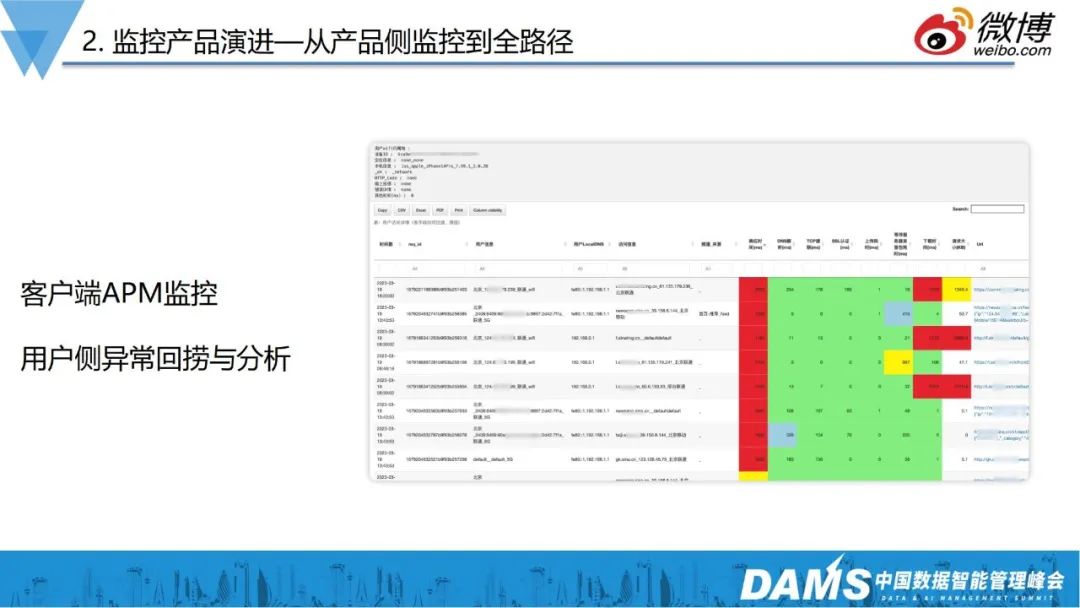
除了基线层面的数据,还有Trace监控产品,如果有用户投诉,我们则能够复现其访问路径,检查网络和访问质量,以此解决问题。
那么有了APM是不是就够了呢?答案是否定的,当用户问题发生并进入公司内部服务后,接下来要做的就要搞清楚为什么访问慢?慢在哪里?是DB慢,还是前端慢?
所以有了产品侧监控后,紧接着就是做后端全链路监控。
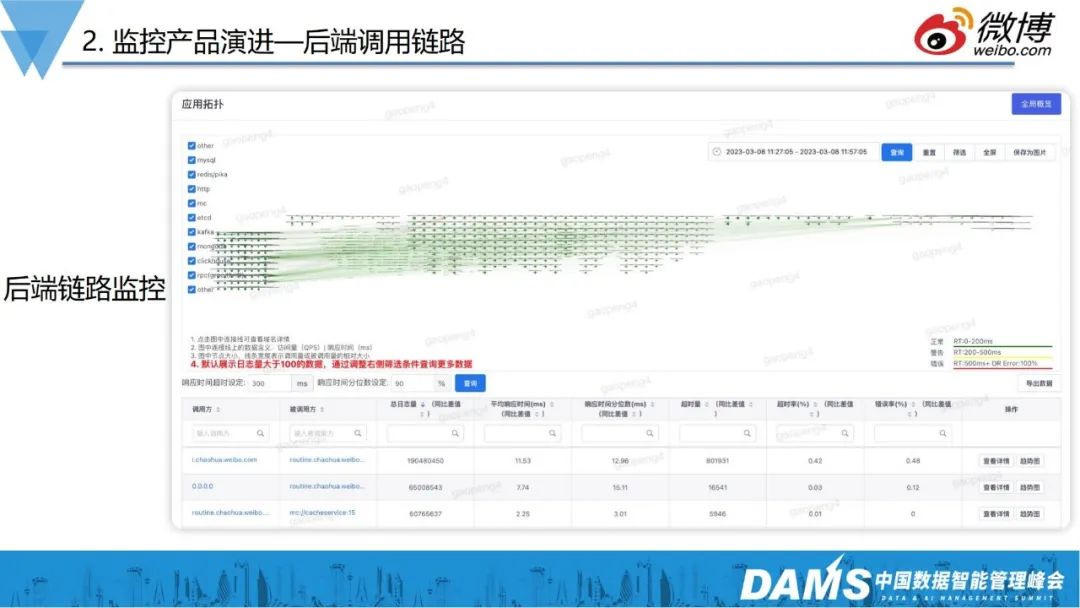
上图是内部产品的调用拓扑图,本身已经非常复杂。前面提到我们内部使用的是自定义协议来做打点的拓扑架构绘制,虽然并没有用到OpenTelemetry,但它所串联的ID和APM其实都是一一对应的,本质上和OpenTelemetry没有太大的区别。
有了上面这些点线关系后,我们也能知道它在后端进入内部服务后,具体是怎样的访问路径,可以很清楚看见某个服务从不同机房到后端,以及不用接口、不同pod IP到对端的服务可用性。同时,我们定义了很多SLI,如平均响应时间、P90、P95、P99响应时间、错误率等,结合ClickHouse的函数,可以实现快速的统计需求,最后形成了内部服务的metric和trace可观测。

我们现在也在积极拥抱OpenTelemetry,上右图是一个使用Jaeger展示存在ClickHouse里的一个调用瀑布图。
三、AIOps应用
前面提到,有了端上、链路等日志后,数据量会非常庞大,远不是人肉去配置报警规则就能搞定的。
所有的可观测指标,不可能让工程师盯着大屏发现异常,最终一定都要落地到监控报警,以下是传统监控面临的一些困境:

业务多样性:同一场景不同业务,差异巨大,导致添加报警繁琐无比;
比如同一个DB,有两个业务或接口,背后的SQL、业务逻辑都是不一样的,这一块的报警就要引入算法去做。
周期差异性:不同时间范围,波动巨大,导致无法固定阈值“一刀切”;
新浪的业务是偏媒体类的,早上9点、晚上23点会存在访问高峰,中间时间段的流量则不是很规律,对于这种场景,也需要算法去实现。
数据多维度:维度众多,出现问题不知道是什么导致的,导致报警只能是“吹哨”。
传统的报警,只会告诉你出了什么事,运维人员需要登录机器,一顿shell操作排查原因,我们则希望是收到报警后,能及时告诉我们是什么原因,具体是哪个组件出了问题等。
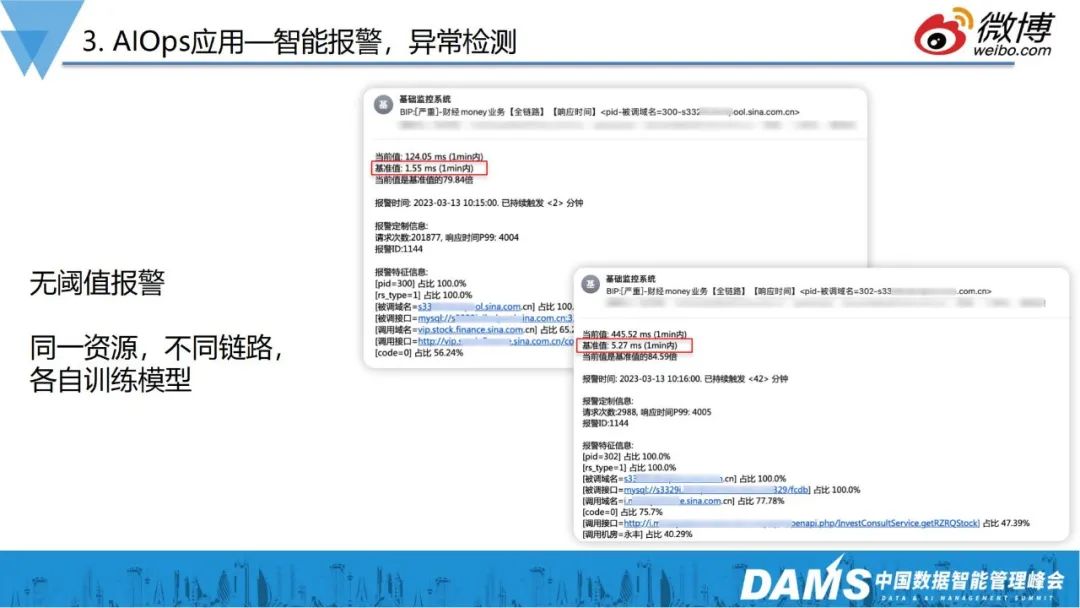
基于以上思考,我们做了无阈值的异常检测。
如上右图,是同一MySQL的两个不同业务,我们看到基准值相差非常大,一个1ms,一个5ms,靠人工加报警阈值,已然不现实。
因此,我们的监控系统在不同的业务调用链上,有各自不同的阈值,报警系统会根据各自的模型判断报警。

当触发报警条件时,能不能告诉用户一些信息,以此提升信息的有效荷载呢?
举个例子,上图是一个web服务5xx的报警,传统运维可能会配置500、502、504多个报警,无疑会增加工作量。现在我们支持配置一个5xx的报警,让报警告诉你现在是谁占得多?哪个运营商的用户受影响最大?具体是哪个接口?有了这些信息,就可以帮助运维减少大量的排查工作。
目前报警特征这部分的功能,我们用了较经典的算法——关联规则算法,该算法不是简单每个维度group by,一份日志会有个几十上百个字段,特征组合是Cn1的复杂度,它能够有效减少计算的时间复杂度。

在AIOps应用上,我们还做了多级服务日志关联,定位问题产品位置。如图是端上发生的一次链路,我们展示了它在后端整个调用链路,在这个过程中,它对哪些资源依赖、对各个链路上是否有问题,我们都可以很直观看到。
以上就是我们在算法层面的一些应用。
四、数据科学应用
数据科学应用是我们近两年重点发力的方向,这块更偏向于运维垂直领域下的数据分析,和我们传统业务的数据分析不大一样。
近两年,大家都在讲降本增效,在整个运维体系中,也避免不了降本增效的需求。
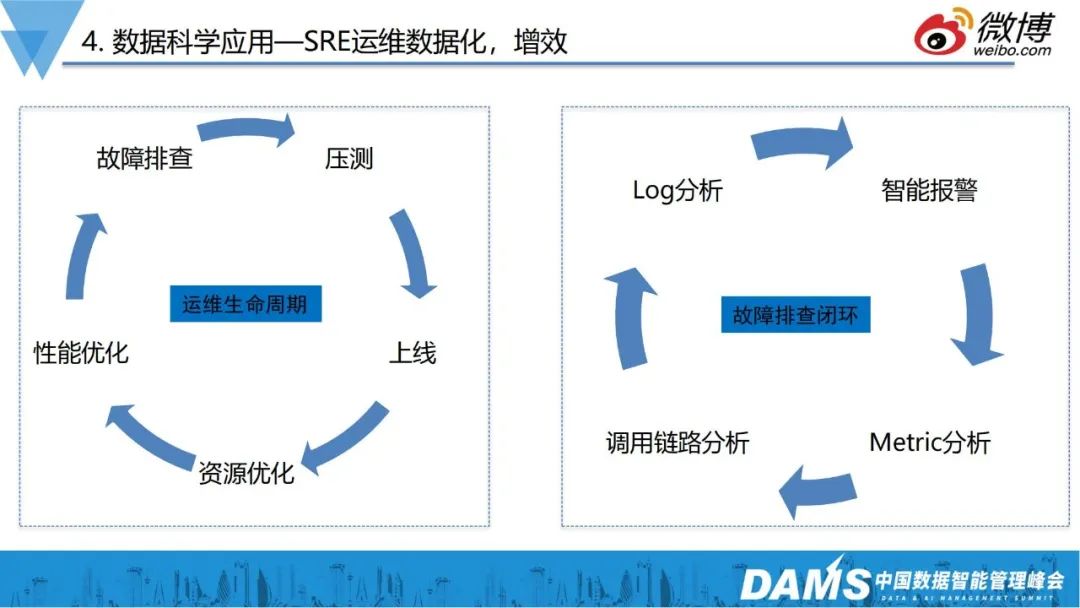
在增效方面,我们的运维生命周期,以及运维生命周期中的故障排查、处理流程,也完全用数据走成了闭环。
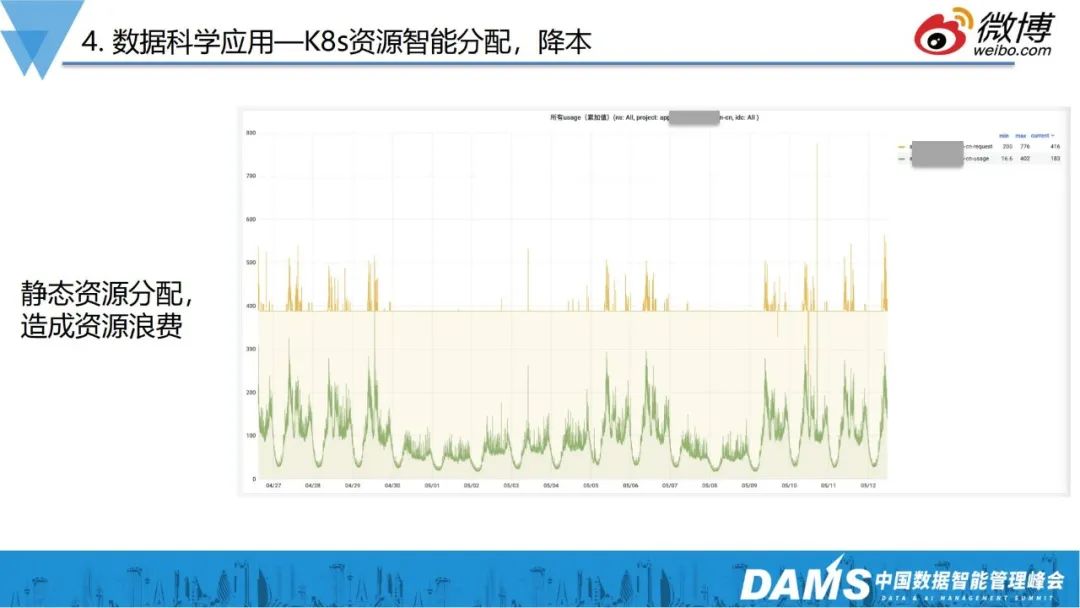
在降本方面,我们进行了K8s资源智能分配。
如图是K8s资源分配的模板,K8s组员分配是按照request和limit来预分配的,但因为实际使用是动态、不确定的,这就可能会造成资源浪费,如果用HPA覆盖的话,又存在滞后性,业务会抖动一下,才能把资源拉高。那么这个问题怎么解决呢?

我们用一些简单的数据分析,就把问题解决了。如上图所示是财经类的业务,周六日不开盘,量非常少,工作日9-11点、14-16点开盘,黄色曲线是K8s request给某个项目两周时间全部CPU,绿色是实际CPU的使用情况,可以看到有明显的大周期和小周期,如果把黄线拉得过高,大部分业务空闲的时候,资源就会白白浪费。
目前,我们是贴着实际使用量去分配资源的,首先通过长期实际使用的数据进行观测,再根据实际使用的CPU情况,判断出下一时刻资源的预期,把下一时刻的资源改成预期数值,最终实现降本的目标。
接下来分享我们在数据可视化方面的一些案例。
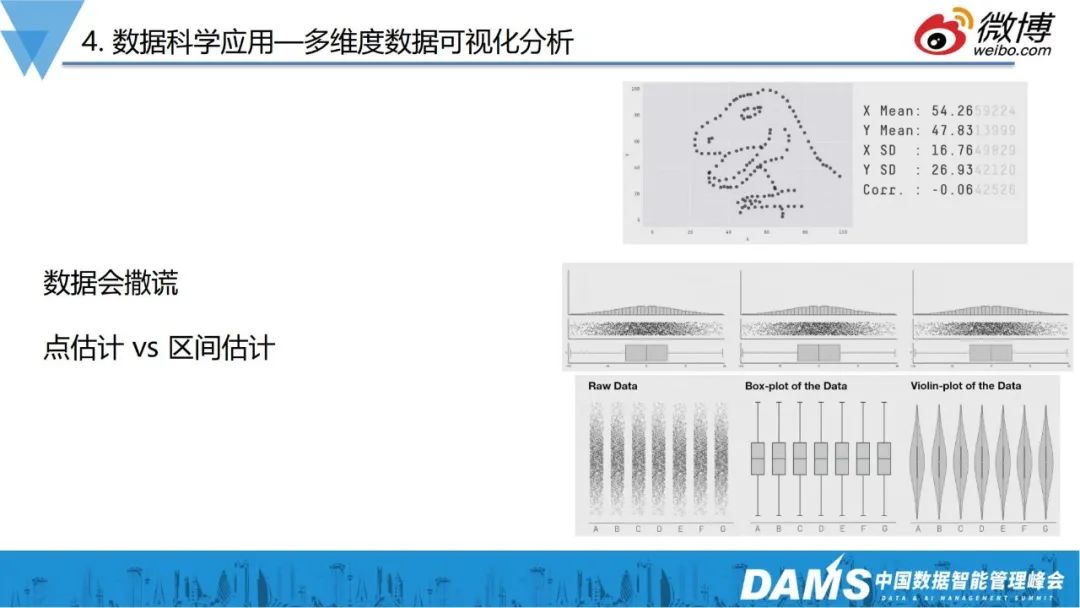
大家在做数据分析的时候,往往会使用一些平均值、P99、中位数等,但有时候这类数据会造成极大的信息偏差,如上右图,散点形状一直在变化,均值、方差基本上在小数点后3位才有差异。
这提醒我们,在做数据可观测、数据分析的时候,提取的指标本身可能没有意义,无法反馈处问题的真实情况。
那么我们是如何利用数据可视化解决实际问题的呢?

前面提到的降本增效,除了要减少资源的不合理分配,还有一个目标就是要通过数据分析,找到不合理的服务器利用率。
上右图是内部针对服务器的利用率做的散点图分析,由图可见,有的业务利用率都集中在上部,这种一般是离线计算业务,CPU越高越好;有的业务CPU分布呈现枣核型,分布比较平均,一般常见于在线业务,因为要保障响应时间,所以不能把CPU堆的特别高,有的又全是很低,这种就不太合理。
有时候运维总说服务器不够用,通过实际的利用率分析观察,发现服务器不够用只是个假象。就如K8s问题,预期和实际使用的GAP其实是非常大的,把GAP消除掉之后,就发现有大把的资源闲置。
在提高服务器利用率上,我们往前延伸了一步,把散点图增加了时间序列,变成了时间序列热力图。

如图是某个业务线某天所有服务器CPU使用率的热力图,右上角X轴是CPU利用率,越靠右越高,Y轴是对应的服务器数量。
上右图服务器利用率一部分较高、一部分较低,但是这个图它只能体现出一天的情况,为增加时间维度,我们把这个图做成了下面的时间序列热力图,X轴又变成了日期,颜色的深浅来代表多少服务器的多少,然后 Y轴变成了CPU利用率。
明显看到,随着时间的变化,集中在上半部的颜色越来越深,说明这个部门CPU的利用率高的机器是越来越多的,这样的话,就避免了我们只用某一时刻的数据来简单描述数据,让数据变得更加客观真实。
这个案例属于宏观层面的分析,业界有做eBPF分析的,比如IO的latency分布,也会使用这种时间序列热力图进行展示。
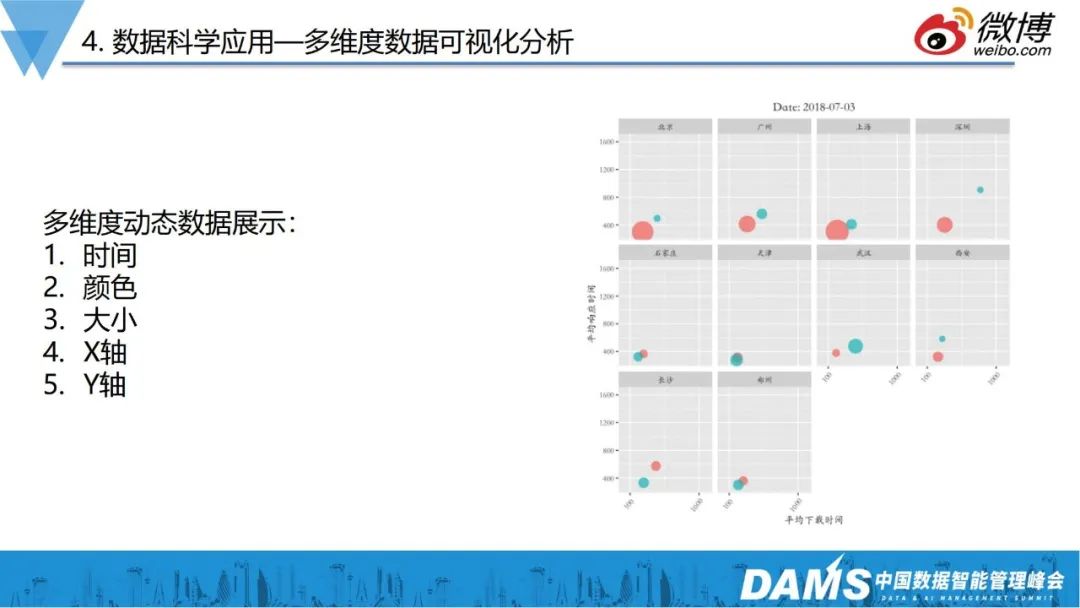
如上图所示,我们在数据分析上,也对CDN服务做了多维度的数据展示。图中是一个多家CDN性能的综合对比,展示了五个维度的动态数据,其中包括日期数据,颜色代表厂家,圆圈大小代表体量,X轴和Y轴分别代表了CDN的响应时间和下载时间。
通过这个图,我们可以非常直观判断厂商产品质量,实现多维度的数据可观测。

除此之外,我们还做了能够给运维直接赋能数据能力的工具——交互式BI分析工具。
数据分析的最后一公里,是让需要用的人,以一个很低的成本用起来,如我们内部的APM日志回捞的工具,CDN的同事就会经常用来分析问题。作为基础服务,需要快速排查用户的投诉问题,比如用户反馈视频的首帧慢了、图片加载异常了,使用这些工具,就能够快速的看到到底是DNS的原因,还是TCP建联的问题,还是后端服务的确是慢了。
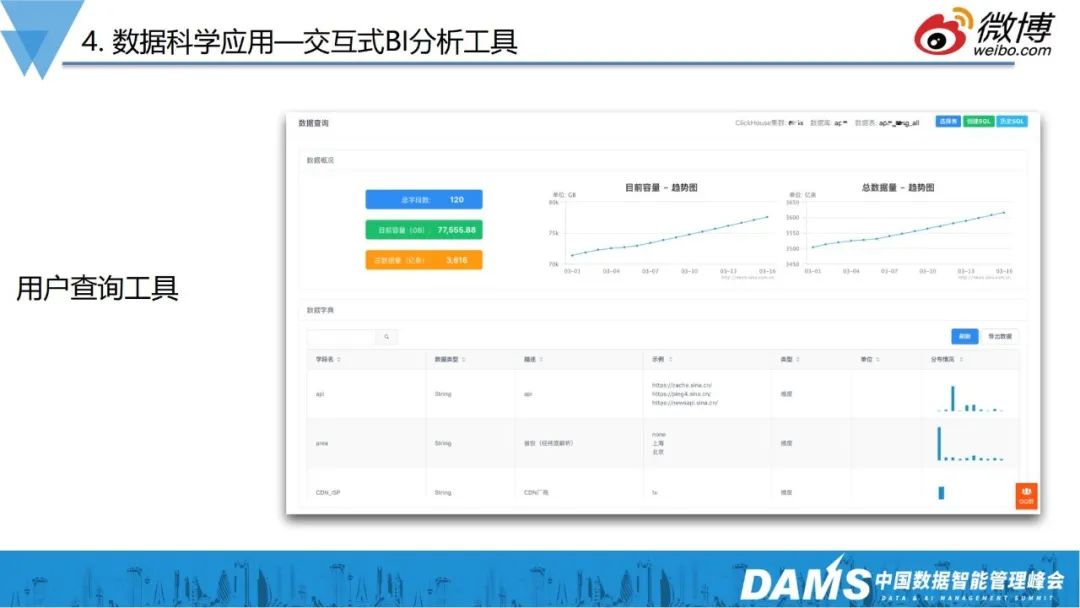
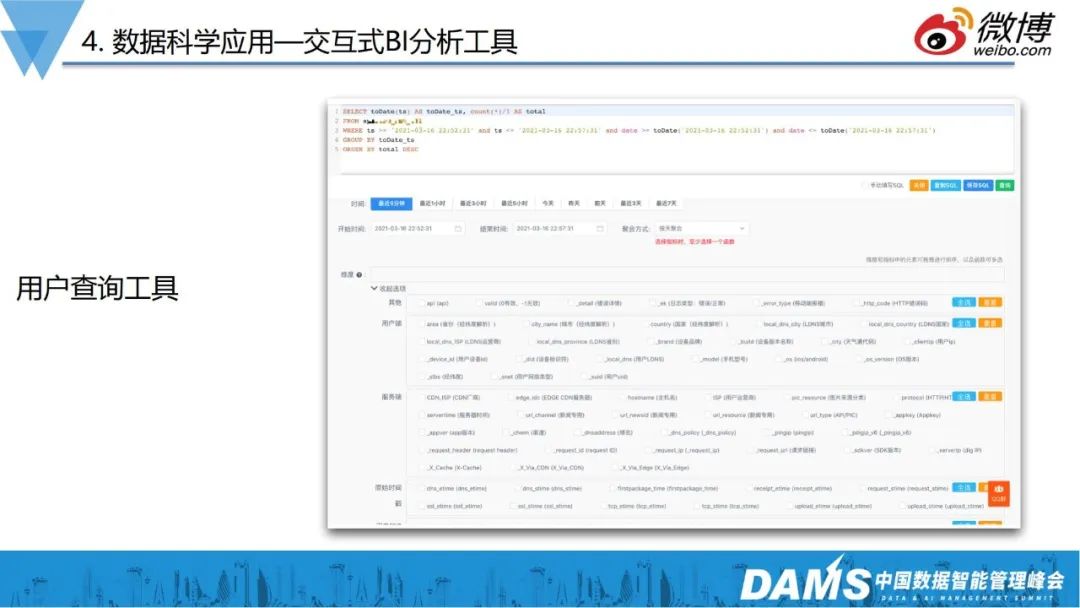
前面提到,ClickHouse解决了从数据存储、查询的问题,但实际上让数据用起来,还是有一定难度的。很多运维人员不太会写SQL,因此我们内容做了类似数据打捞的工具,使用者可以简单通过勾选,完成数据提取和数据聚合等查询工作。

最近ChatGPT特别火,我们也在尝试与其建立连接。
前面提到使用勾选工具,解决写SQL难的问题,那么能否通过自然语言描述的形式,让ChatGPT生成我们想要的SQL呢?
通过测试,90%的情况下,ChatGPT都能“听懂”描述,给出正确的SQL,未来相信也能不断帮助我们降低数据获取的难度。
五、未来展望
1、数仓的可拓展
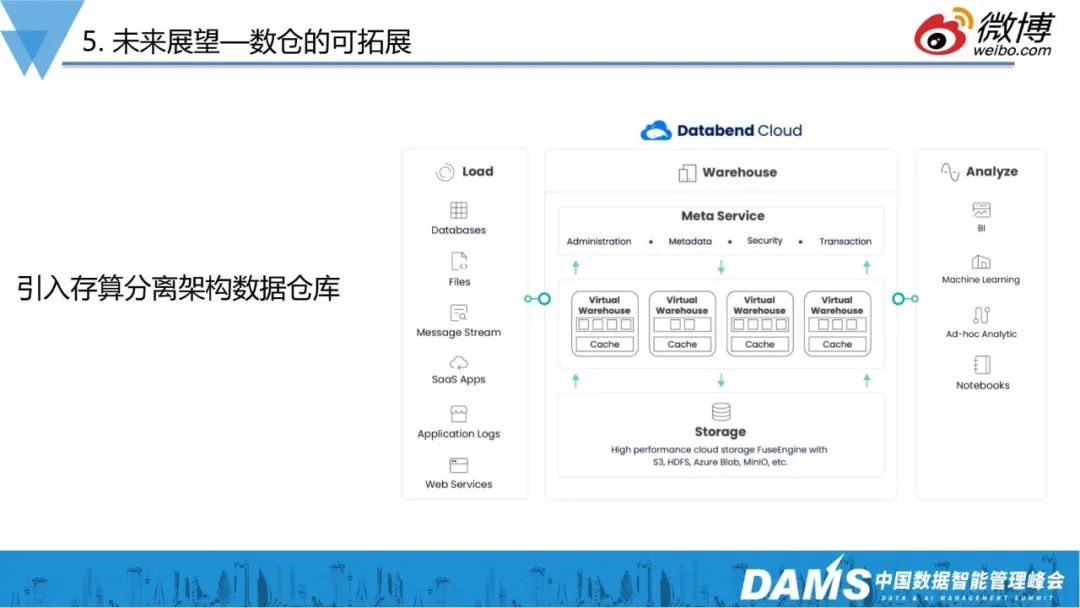
近几年OLAP领域发展火爆,国产产品也非常优秀,比如databend这种定位于存算分离架构的数据仓库。
ClickHouse虽已经一款高性能的数仓产品,但在运维层还有一定的复杂度,未来我们会引入存算分离的数据仓库,进一步地减少在数据存储、运维方面的压力。
2、数据分析的未来

前面讨论了很多用工具降低数据分析难度的时间,那么ChatGPT是否也能让数据分析变得简单?能否直接把数据给ChatGPT,让AI直接给我们结论呢?
如图是直接从Nginx7层服务里导出来的一些日志,直接给到ChatGPT后,发现它可以直接做好初步的数据分析结论,判断异常、响应时间分布等情况,结果让我们感到兴奋,AI的思考能力实在强大。
3、全路径可观测

有了全链路、端上监控后,发现端上报的指标都是非常宏观的,不能马上定位到根本问题,这些工作非常依赖于资深SRE,通过抓包、系统工具,排查系统层、内核层的指标才能找到根因所在,整体非常耗时。
再如,客户端、后端、DB层、TCP层等都需要更微观的监控,线上有很多异常,可能是TCP重传、RTT恶化导致的,这些根因数据我们在应用宏观层面是没办法拿到的。
因此,我们未来要做更微观的可观测。目前我们做的是基于eBPF,去拿一些内核层面的微观数据做解释,逐步让可观测“深入骨髓”。
最后和大家分享业界常说的一句名言:“If You Can't Measure lt, You Can't lmprove lt.”
做数据可观测,本质上是通过各种手段降低数据衡量的难度、数据使用的复杂度,让数据成为武器,让开发提效,让运维“安稳长满优”。
Q&A
Q1:底层用ClickHouse作为OLAP的数据库,如何支撑实时的并发查询呢?
A1:OLAP产品谈并发本身是个伪命题,这个场景大部分是热数据,真正需要并发需求的,可能就是近几分钟的数据,这类热数据,本身就有较高的并发性能。
其次,ClickHouse本身也会有各种各样的机制去提升并发性能,比如物化视图等,通过构建视图,把原始数据做提取并物理存储,提取后的数据再查询,基本上也能达到千级别QPS。
Q2:AIOps的链路图是通过聚合出来的吗?通过自定义协议怎么采集这些节点?
首先,拓扑图本身没有太大的技术含量,主要就是依赖端上日志的记录,包括我们看到从APP到后端,链路管理本质上有记录全局ID,有了ID就能知道先后,OpenTelemetry也是一样的逻辑,只不过OpenTelemetry增加了Span ID的概念,可以看到调用的上下游关系,本身没有什么特殊的地方。
Q3:AIOps链路的采样率是怎样的?会不会影响性能?
端上的采样率是严格控制的,比如采用率低于1%,数据量也非常大的。如果采样率不合理,对数据的观测肯定会有影响,所以可以通过针对VIP用户全量采集的方式,去规避问题排查缺少数据支撑的情况。
采样规则的开关是可以随时去调的,比如某段时间需要增加采集量,就可以随时把开关调大。其次在采访的时候,错误日志是全量上报的,这样也能保障数据的客观性。后端链路监控也是类似的规则,业务量较小是,基本上是全量采集。
所以目前来看,对性能的影响是微乎其微的。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721