
前言:
关于什么是SRE,以及在业务上有哪些具体的输出,网上资料众多但都只是对基本概念做描述。那容器SRE究竟要怎么结合业务,得物容器SRE又有哪些最佳实践,本文就得物容器SRE的一些事情向大家做介绍。
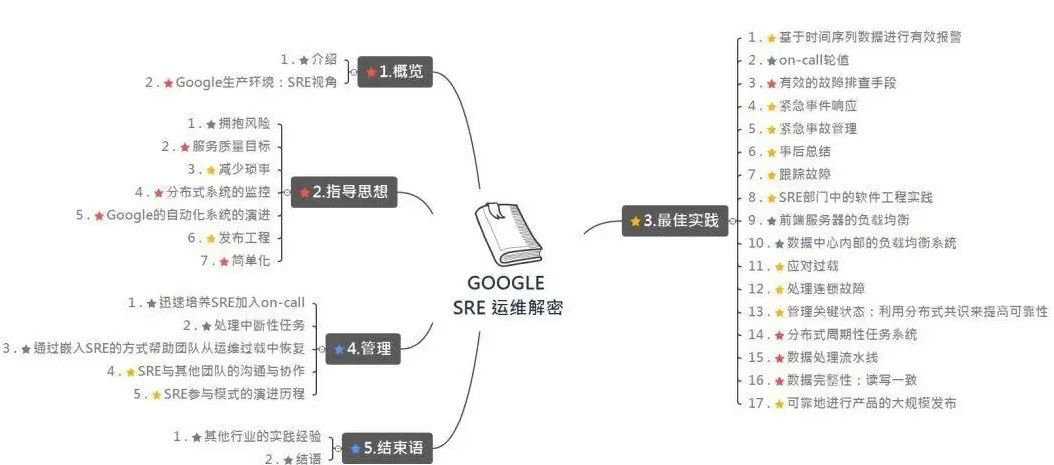
一、SRE定义
稳定性工程师,用软件工程解决复杂的运维问题,50%的时间用于运维琐事,50%的时间用于软件工程保障业务的稳定性和可扩展性,包括开发监控,日志,告警系统,业务性能调优等
二、对于SRE的理解
(1)一个团队 Oncall 至多需要两个人 (另外一个是新手 shadow),oncall人员需要具备以下能力:
①清晰的问题升级路线
②清晰定义的应急事件处理步骤
③监控巡检,如下:
查看监控,分析服务可用性下降或者耗时增加等影响服务质量的问题的根部原因。
整理以上事件的数据
分析根本原因,优化并且解决(运维手段,代码,或者脚本 / 代码自动化运维手段)
(2)遇到重大故障时的各种重要角色
IC(Incident Commander):故障指挥官,这个角色是整个指挥体系的核心,最重要的职责是组织和协调,而非执行,下面所有角色都要接受他的指令并严格执行。
CL(Communication Lead):沟通引导,负责对内和对外的信息收集及通报,这个角色一般相对固定,由技术支持、QA或者是某个SRE来承担,要求沟通表达能力要比较好。
OL(Operations Lead):运维指挥,负责指挥或指导各种故障预案的执行和业务恢复。
IR(Incident Responders):即所有需要参与到故障处理中的各类人员,真正的故障定位和业务恢复都是他们来完成的,如具体执行的SRE、运维、业务开发、平台开发、DBA,甚至是QA
100%稳定的系统是不存在的
服务质量指标 SLI(indicator):量化指标,包括延迟、吞吐量、错误率、可用性、持久性等
指标不宜过多,应关注用户的真实需求
常用的指标度量应该尽量标准化(如时间间隔、频率等)
服务质量目标 SLO(Objective):对特定 SLI 的目标值
服务质量协议 SLA(Aggrement):与用户间的明确协议,一般伴随着代价
维护服务可用性的成本不是线性增长的,到一定程度,增加一个9可能需要10倍100倍的成本,通过SLO让成本和收益取得很好的平衡,假设一个业务增加SLO等级,可以计算一下需要的成本和带来的收益,如果得不偿失就可以不用增加SLO等级
SRE的经验大概 70% 的生产事故由某种部署的变更而触发
变更管理的最佳实践:
(1)采用渐进式发布机制
(2)迅速而准确地检测到问题的发生
(3)当出现问题时,安全迅速地回退改动
容量规划必需步骤:
必须有一个准确的自然增长需求预测模型,需求预测的时间应该超过资源获取的时间。
规划中必须有准确的非自然增长的需求来源的统计。
必须有周期性压力测试,以便准确地将系统原始资源信息与业务容量对应起来。
SRE的四个黄金指标是构建成功的监控和告警系统的一些基本原则和最佳实践
延迟:延迟是信息发送方和接收方之间的时间延迟,以毫秒(ms)为单位。而原因往往是由于数据包丢失网络拥塞和网络抖动造成的,称为“数据包延迟差异”延迟对客户体验有直接影响,转化为成功请求的延迟和失败请求的延迟。
流量:流量是系统工作量带来的压力。它通过每秒查询数(QPS)或每秒事务数(TPS)来衡量。企业通过数量来衡量这一点:关键绩效指标(KPI)是在给定时间来到站点的人数。这与商业价值有直接关系。
错误:错误是根据整个系统中发生的错误来衡量的。被认为是服务错误率的重要指标!有两类错误:显式错误,如失败的HTTP请求(500个错误代码,例如);隐含错误是成功的响应,但内容错误或响应时间长。
饱和度:饱和度定义了服务的过载程度。它衡量系统利用率,强调服务的资源和整体容量。这通常适用于CPU利用率、内存使用、磁盘容量和每秒操作数等资源。仪表板和监控警报是帮助你密切关注这些资源并帮助你在容量饱和之前主动调整容量的理想工具
可靠性是MTTF(平均失败时间)和MTTR(平均恢复时间)的函数。评价一个团队将系统恢复到正常情况的最有效指标,就是MTTR。
任何需要人工操作的事情都只会延长恢复时间。一个可以自动恢复的系统即使有更多的故障发生,也要比事事都需要人工干预的系统可用性更高
三、得物容器SRE的实践
Oncall是直接体现SRE价值所在,能够直接影响MTTR时间的主要核心系数,一个好的Oncall甚至可以帮助公司挽回很多资损甚至是公司的形象,所以Oncall是每个SRE最重要的工作。
我们有自己的Oncall机制、适用范围、人员构成、复盘跟进、不同场景会邀请不同队员参与排障。有基本的故障处理原则,事故处理后的闭环。下图为整个Oncall流程的进行方式:

当然每次都只是处理故障,恢复后不做总结归纳是不会有任何沉淀的,容器SRE会记录每次有意义的故障进行文案撰写并在故障中总结现有系统存在的工具类、平台类、代码类隐患点,分等级高中低进行推进push帮助业务,基架不断完善系统健壮性;
(1)延迟问题背景:
某天下午SRE侧开始陆续接到业务研发反馈redisRT 增长导致超时,其中某服务有多个pod存在redis RT突增导致部分请求超时(截图如下)

经过了一系列的驱逐与资源规整等止血操作后,该故障在30分钟后恢复。在这种场景下排查根因通常是一个很棘手的问题,因为第一现场很难在短时间内再进行模拟、恢复,第二在生产环境下不易做太多的测试工作。这种背景下就要发挥SRE的价值了。下面是叙述我们整个问题的排查思路与过程,希望能给大家一些借鉴。
(2)问题排查思路:
排障过程描述只是说了一个思路,部分时间点可能和故障产生的时间重合
先排查是否是网络问题引起的,当问题发现解决后后我们梳理了对应的宿主机的信息,想发现一些规律来确认故障的根因;

图上可见,这三台并不是一个网段的,唯一相同的也就是同一个区域,这个范围较大,不像是一个局部事件。所以我优先想到了云商故障;
为了进一步确认问题,我将对故障的 ecs ID 给到了阿里并进行了一个授权,随后还拉群做了语音讨论
接下来是整个根因排查分析:
①排除链路问题
翻阅故障时的监控发现,网络耗时在故障时间点附近比较平稳、经过和阿里内部监控的核对,当时问题宿主机网络延迟在故障时间点延迟仅从 2ms 增加到 4ms 所以可以排除是由于网络问题导致的
②发现异常现象
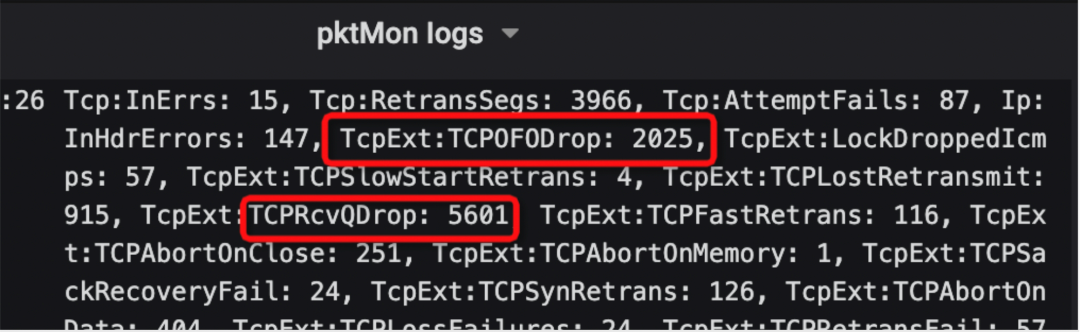
node监控有大量的异常包,drop 计数异常,常规情况下应该为0(上图),我们对这些drop 包做了分析(下图)发现Drop 的统计数非常高,同时tcpofo,tcprcvq这两个指标指向了TCP内存限制,需要扩充内存空间。

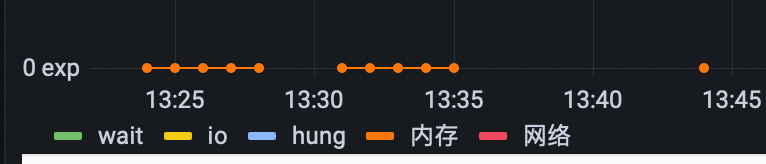
为了更进一步知道根因所在,我们又去观察了对应的 io夯、调度(任务等待)、 夯住(应用进程锁)、用户态内存等待、网络 (系统 5状态分类左图) (这里第一步已经排除了“网络”故障所以这里做了删除线处理),可以看到排查到io等待时间过长(下图)
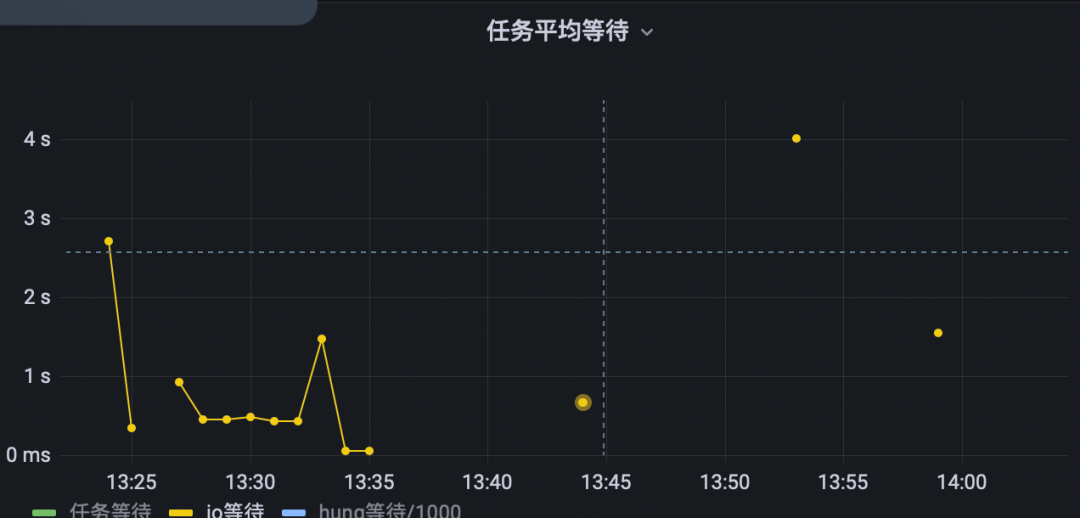
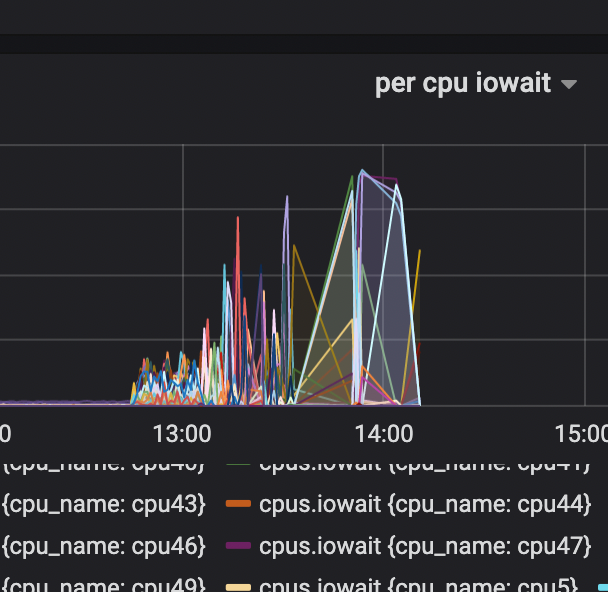
③深挖排查到IO平均等待时间上存在问题
IO平均等待时间在秒级以上,远超了正常范围,故开始排查percpu iowait 状况。经过一系列的操作最终我们使用sls 导入tidb 的方法数据做了一个可视化;
select * from cpus where time > now() - 4h and host = 'i-bp11f8g5h7oofu5pqgr8' and iowait > 50.0
我们对那些 CPU iowait 比较高的筛选出来,看看能不能找到对应的业务(当时就怀疑是不是由于混部原因导致的)但是找了一圈没有发现什么问题。
(3)最终根因定位:
绕了一圈发现线索又断了,还是回到那个TCP 内存限制的问题,为什么会判断tcpofodrop 指标会与tcp_mem 有关呢?可以直接看代码逻辑
内核源码网站推荐
https://lxr.missinglinkelectronics.com/linux+v4.19/net/ipv4/tcp_input.c#L4459
(一个展示源代码存储库的软件工具集)


上面的逻辑简单叙述:TCP的核心预分配缓存额度函数为tcp_try_rmem_schedule,如果无法分配缓存额度,将首先调用tcp_prune_queue函数尝试合并sk_receive_queue中的数据包skb以减少空间占用,如果空间仍然不足,最后调用tcp_prune_ofo_queue函数清理乱序数据包队列 (out_of_order_queue)。简单说:如果内存分配失败,对应drop计数就会递增
另外当时我们也发现了dmesg日志里tcp oom的日志,如下图所示
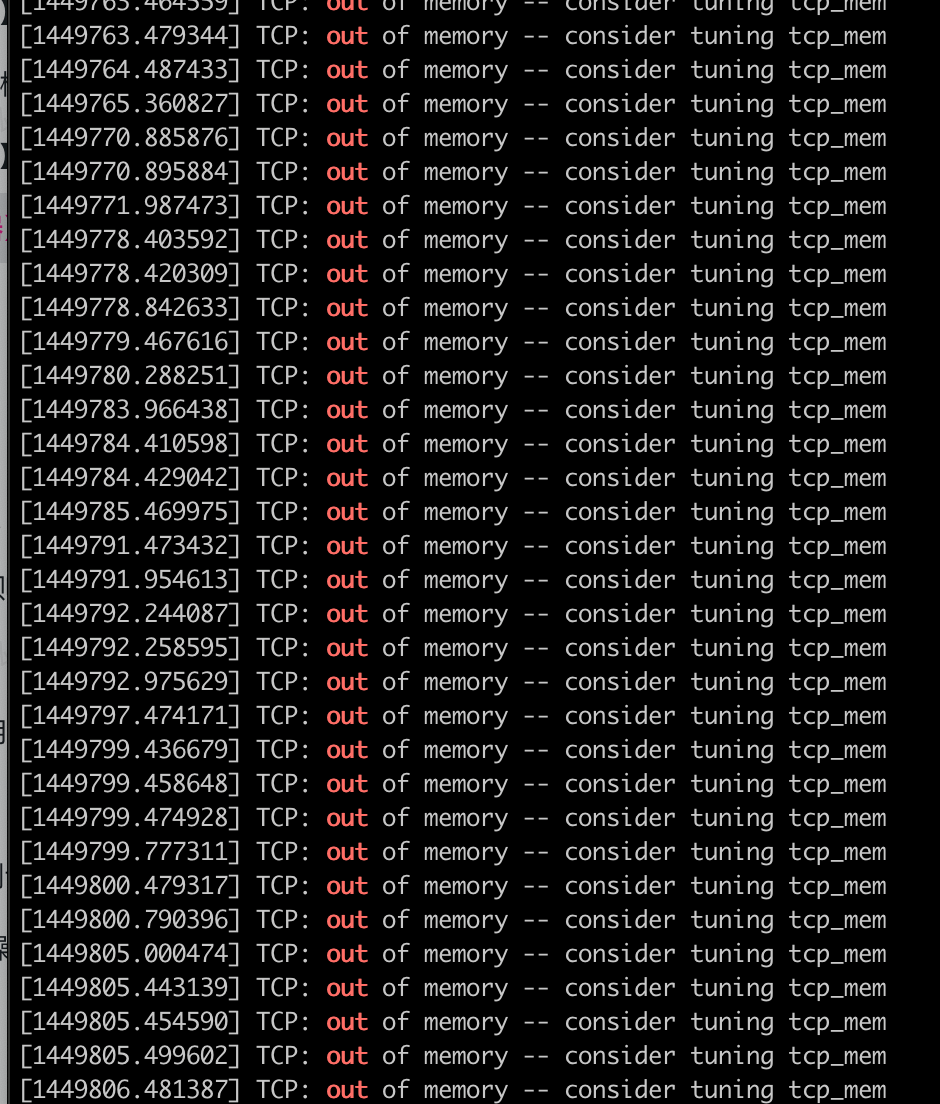
于是就搜了一些实践准备将线上连接数比较高的那几台机器做一个替换处理试试
#命令查看方法sysctl -a|grep -i tcp_mem|tcp_rmem|tcp_wmem
当时想准备替换的配置(当时这个调整低于线上目前的值)
# 扩大TCP 总内存大小# 扩大到 32G 最小值不动 中间数为max 的 70%echo "net.ipv4.tcp_mem = 1104864 5872026 8388608"/etc/sysctl.conf#单个 socket 读分配最大内存#原先16MB 扩大到 32MB (中间数为最佳实践推荐)echo "net.ipv4.tcp_rmem = 4096 25165824 33554432"/etc/sysctl.conf#单个 socket 写分配最大内存#原先16MB 扩大到 32MB (中间数为最佳实践推荐)echo "net.ipv4.tcp_wmem = 4096 25165824 33554()432"/etc/sysctl.conf
当时线上内存
cat /proc/sys/net/ipv4/tcp_mem6169920 8226561 12339840,这里是最小值24G 压力值32G 最大值48G
在check这些参数的过程中突然就发现了一个问题,我们线上的参数换算成内存值是48G左右,已经算大了,可以想象一下 tcp 链接总的内存已经用了48G!这部分还不光是网络开销只是一个 TCP 链接,我们就有 ss 看了下当时的链接情况:

通常出现这种情况的原因有以下两种:1、应用没有正确close他的socket进程 2、没有处理异常情况下的socket








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721