
许龙,哔哩哔哩资深开发工程师,2020年加入B站,负责k8s云平台相关研发工作,包括容器和k8s引擎、混部、弹性伸缩等。
一、背景
中大型互联网公司的服务器数量可达万级别,在降本增效的大背景下,机器资源利用率的重要性日益凸显。如何在确保服务SLO影响最小的情况下提高机器资源利用率,从而降低服务器的采购成本,是一项非常值得研究的课题。
对于k8s云平台来说,造成机器平均资源利用率低的原因可以概括为以下几点:
1)业务申请的资源配额超过实际使用量。即用户在申请资源时可能会对服务的真实资源使用情况估计不足,一般倾向于申请过量的资源。这就导致机器配额被占满,无法继续调度容器,而实际资源利用率却很低。
2)服务的资源使用量存在波峰波谷。大部分服务的负载都会存在高低峰,当服务处于波谷的时候就会存在很大的资源浪费。
针对上述问题1),我们可以通过服务画像给业务推荐一个合理的资源配置值,并结合弹性伸缩的手段来解决。
针对上述问题2),关键点在于如何将业务波谷时空闲出来的那部分资源利用起来,比如凌晨在线业务处于波谷的时候,往在线集群调度适量的离线任务。
目前B站私有云平台已经达到较大的机器规模,我们从上述两个思路出发来给整体云平台降本:一方面提供了hpa和vpa的弹性伸缩能力,使得业务资源配额使用更为合理;另一方面,我们实施了较大规模的业务混部来解决算力的闲置问题。本文将主要分享B站云平台的混部实践,而弹性伸缩方面的实践我们会择机在后续文章中介绍。
二、混部的概念
我们把业务划分为在线业务和离线业务。在线业务一般是各类微服务,特点是延时敏感、有很高的可用性要求,如推荐、广告、搜索等服务;离线业务一般是批处理任务,特点是延时不敏感、允许出错重跑,如大数据场景中的MapReduce任务、视频处理中的转码任务等。所谓混部技术,就是通过调度、资源隔离等手段,将不同类型、不同优先级的在离线业务部署在相同的物理机器上,并且保证业务的SLO,最终达到提高资源利用率、降低成本的目的。需要注意的是,混部不是简单地将容器部署到同一台宿主机上,而是需要通过调度算法将混部任务调度到具有空闲资源的机器,同时需要有隔离机制来保证高优任务不会受到混部任务的干扰。
三、B站混部的场景
B站是一个视频类网站,存在大量的点播视频转码任务,这类任务属于计算密集型,具有运行时间短、允许失败重试等特点。另外,在凌晨时段会触发大量的转码定时任务,刚好和在线业务形成错峰。我们通过在离线混部技术将转码任务调度到在线集群,既提高了在线集群的资源使用率,又补充了转码任务高峰期时的算力缺口,极大地降低了服务器成本。这类混部场景的难点在于:
1)调度层
混部任务不能影响在线任务的整体配额容量,例如机器一共64核,如果混部任务直接申请32核的cpu request资源,那就会造成该机器只能调度32c的在线业务容器。
调度器需要动态感知到各个节点可混部资源量的变化,资源空闲越多的节点调度越多的混部任务。
2)节点层
混部任务一旦调度到某个k8s节点后,在cpu、内存、磁盘、网络等各个资源层面都有可能对在线任务产生“竞争”,因此需要随时感知在线任务的负载情况并做相应的隔离管控,尽量做到对在线任务零干扰。
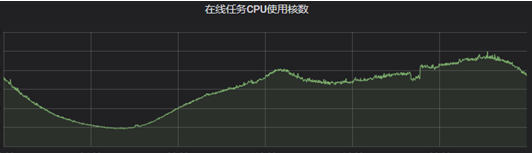
离线集群整体的cpu使用率较高,但部分时段也存在一定的资源闲置,例如训练平台在训练任务较少时整体利用率会偏低。由于都是离线任务,延时敏感性没有在线那么高,因此这类场景除了混部转码任务外,还可以混部一些更“重”的大数据任务。但是大数据任务通常用yarn调度,如何将k8s调度和yarn调度进行协调是我们需要解决的关键问题。实现了大数据混部后,我们就可以做到各个离线业务互相出让资源。例如将hdfs datanode机器接入k8s用于混部转码任务;反过来,转码的机器上也可以运行hadoop/spark等大数据任务。
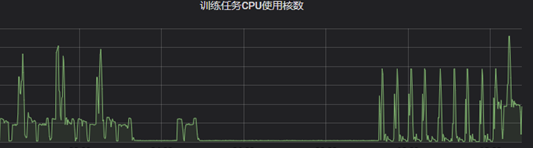
IDC通常会存在一定量的备机,用于各业务应急场景使用,但是日常是闲置的。这部分机器我们也会自动化接入k8s跑混部任务,当业务需要借调备机时再自动下线混部。
下面,我们结合在离线混部和离线间混部这两个场景,具体介绍一下混部的关键技术点。
四、在离线混部
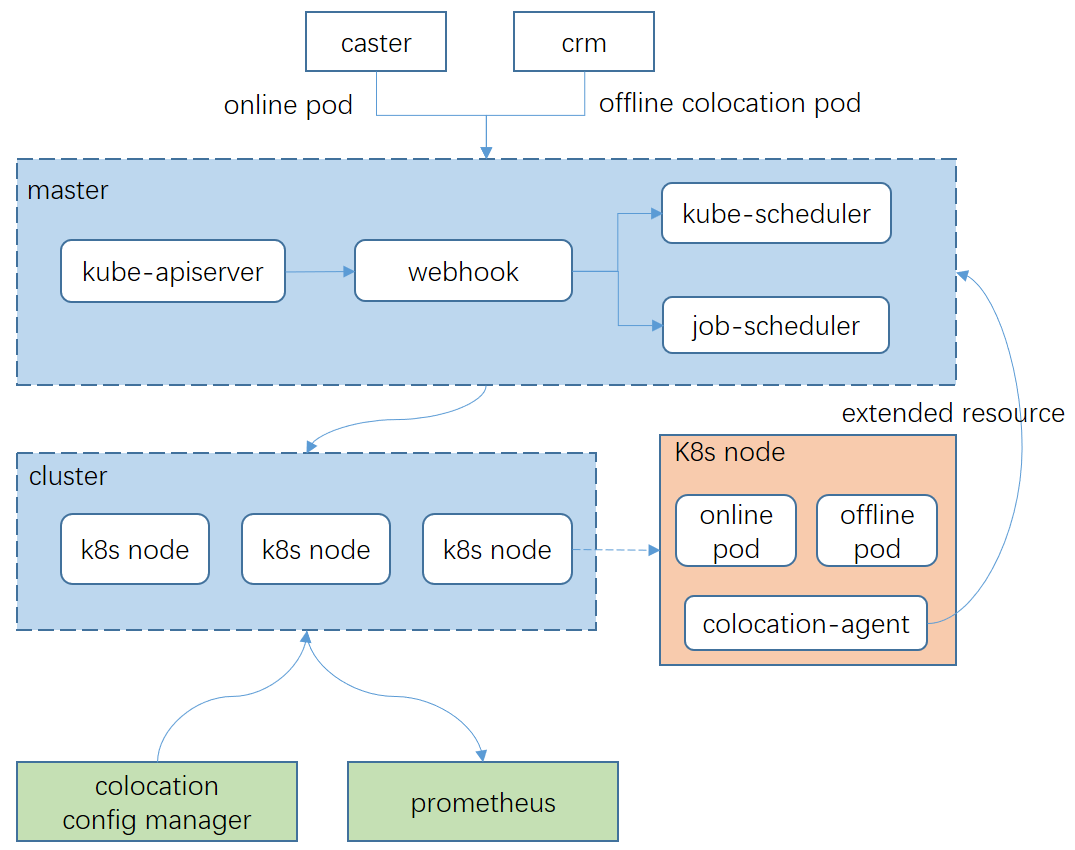
任务提交模块
caster是我们的在线业务发布平台,crm则是离线批处理任务提交平台。crm可以支持多集群调度、混部资源余量统计、混部资源quota管控等。
k8s调度模块
kube-scheduler为原生的在线任务调度器,而job-scheduler是我们自研的离线任务调度器,能支持转码任务的高并发调度。另外webhook负责对离线任务的资源配额进行动态转换,转换为自定义的k8s扩展资源。
colocation-agent
每个k8s节点上都会部署混部agent,负责混部算力动态计算和上报、资源隔离、监控数据上报等。
colocation config manager
在大规模k8s集群中,各类节点的混部配置存在一定的差异性,同时也存在动态更新的需求。该模块负责对混部配置进行集中管控,支持策略下发、开关混部等功能。
混部的可观测性
每个节点的agent负责采集节点中的一些混部指标,例如:可混部资源量、实际的混部资源用量等,最终上报给prometheus进行看板展示。可观测性对于排查单机的混部问题非常有用,我们可以很方便地通过监控曲线来查看某个时刻的混部资源使用情况。同时,我们也可以随时查看整体集群的混部算力使用趋势。
下面,我们从混部任务调度、在线QoS保障两方面来介绍在离线混部的关键技术点。
1)k8s原生调度器的基本原理和问题
k8s的每个节点都会上报节点资源总量(例如allocatable cpu)。对于一个待调度的pod,k8s调度器会查看pod的资源请求配额(例如cpu reqeust)以及相关调度约束,然后经过预选和优选阶段,最终挑选出一个最佳的node用于部署该pod。如果混部任务直接使用这套原生的调度机制会存在几个问题:
混部pod会占用原生的资源配额(例如cpu request),这会导致在线任务发布的时候没有可用资源;
原生调度本质是静态调度,没有考虑机器实际负载,因此没法有效地将混部任务调度到实际负载有空闲的机器上。
2)基于扩展资源的混部调度
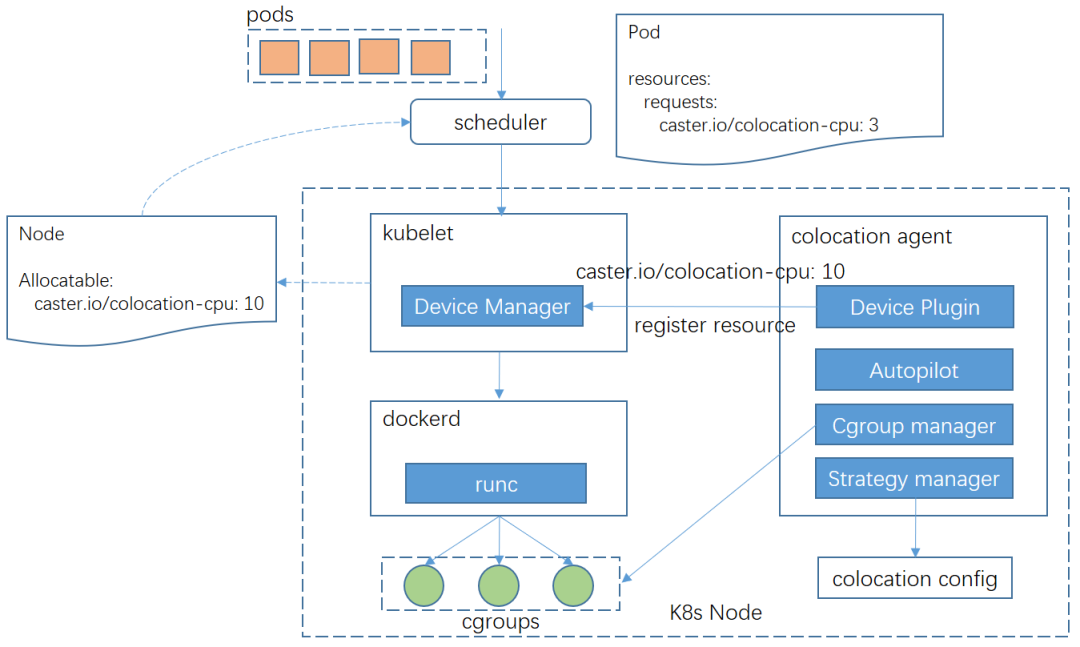
为了解决上述问题,我们基于k8s的扩展资源进行混部任务调度,整体分为3个步骤:
①colocation agent模块中,策略组件会实时加载当前接收到的混部配置,并调用autopilot组件进行混部算力的计算,然后通过device-plugin组件上报混部扩展资源,例如caster.io/colocation-cpu
②混部任务在申请资源配额时,仍然申请原生cpu资源,但是会增加pod标签“caster.io/resource-type: colocation”。k8s webhook模块根据标签识别到混部pod,然后将pod申请的资源修改为混部扩展资源。这种方式对业务层屏蔽了底层扩展资源,通过标注pod标签即可指定是否使用混部资源。
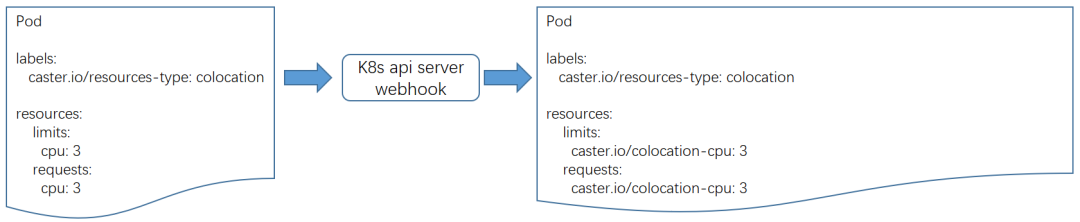
③混部调度器job-scheduler根据pod申请的扩展资源量以及各个节点上报的混部扩展资源量进行调度。我们利用转码pod存在同质化(资源规格和调度约束相同)的特点对调度器进行了优化,基本思路是:
将pod与调度相关的字段进行hash值计算,并在调度队列中按hash值排序pod
pod预选的结果同样也满足其他同质化pod的要求,因此将预选node进行缓存
当前处理的pod若是同质化pod,则从缓存中直接选取一个节点进行调度
3)混部资源量计算
k8s node是怎么确定当前节点应该上报多少混部扩展资源量的呢?我们针对不同的应用场景设计了不同的混部策略算法:
动态计算
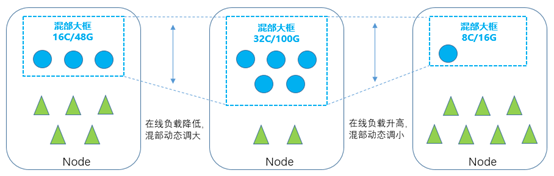
针对各类物理资源,例如cpu、memory等,我们会分别设置机器的安全水位值n%。agent会实时探测在线进程的资源使用量online_usage,然后根据安全水位和在线负载动态计算出可混部资源量。在线使用量和可混部资源量是此消彼长的,随着在线使用量上升,我们上报的可混部量就会下降,反之,当在线使用量下降,可混部量就会上升。
静态计算
例如备机池闲置机器没有在线业务,不需要动态资源计算,因此我们可以配置静态上报策略,上报固定的可混部资源量即可。
分时计算
如果部分在线业务在某些时间段不希望部署混部任务,我们就需要用到分时策略,即在某些时间段关闭混部或者减少上报混部资源量。另外,我们还支持设置grace period,在分时混部结束前,会提前停止调度混部任务到该k8s node,并等待存量任务结束,做到优雅退出。
资源隔离是混部架构的关键难点。我们希望在提高单机混部资源量的同时,尽可能地降低混部任务对在线业务的性能影响。主要从三个层次来保障在线业务的QoS:
任务调度
根据前文所述的混部任务调度机制,混部调度器可以实时感知各节点的可混部资源量,因此可以从全局视角将混部任务调度到资源充足的节点上。
资源隔离
节点混部agent可以秒级检测在线负载变化,根据安全水位值计算当前可混部资源量,然后通过cgroup及时进行资源限制。
任务驱逐
离线的混部任务一般都是可重试的,因此驱逐可以作为一种兜底手段。
下面我们详细介绍一下资源隔离层的几种策略。
1)混部大框
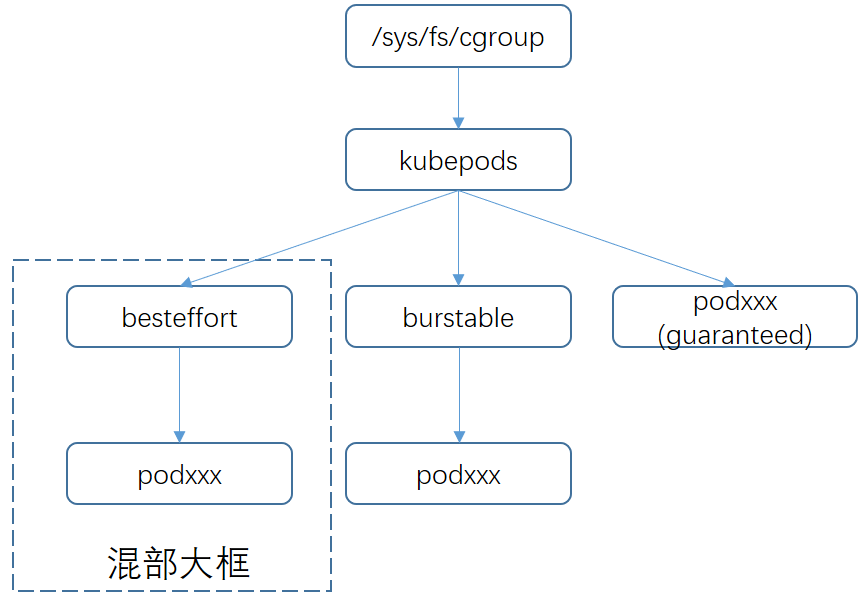
在前面的介绍中我们提到webhook会对混部任务申请的资源类型进行修改,去除原生的资源类型request.cpu和request.memory,改成caster.io/colocation-cpu和caster.io/colocation-memory。由于没有申请原生资源类型,那么k8s会自动将这类pod归类为best effort类型,并且最终通过runc将该类pod的cgroup设置到/sys/fs/cgroup/cpu/kubepods/besteffort目录,我们称为“混部大框”。
2)cpu动态隔离
在cgroup层面,我们给大框设置了最小的cpu share值,保证在资源争抢时,混部任务获得cpu时间片的权重最小。
colocation agent中的cgroup manager组件负责动态地调整“混部大框”的cpu quota,从而对混部任务进行整体的资源限制。当colocation agent检测到在线负载降低时,就会调大“混部大框”的cpu quota,让混部任务充分利用空闲的算力。当在线负载升高时,则是缩小“混部大框”的cpu quota,快速让出资源给在线业务使用。
此外,我们通过cpuset cgroup对整体混部大框做了绑核处理,避免混部任务进程频繁切换干扰在线业务进程。当混部算力改变时,agent会给大框动态选取相应的cpu核心进行绑定。另外,选取cpu核心的时候也考虑了cpu HT,即尽量将同一个物理核上的逻辑核同时绑定给混部任务使用。否则,如果在线任务和混部任务分别跑在一个物理核的两个逻辑核上,在线任务还是有可能受到“noisy neighbor”干扰。
3)内存动态隔离
与cpu隔离方式类似,colocation agent会根据当前在线业务内存使用情况,动态扩缩混部大框的memory quota。另外,通过调节oom_score_adj,混部任务的oom_sore被设为最大值,保证oom时混部任务尽量优先被驱逐。
4)网络带宽限制
我们使用了cni-adaptor组件,使得k8s node可以支持多种网络模式,对于转码混部任务,通常不需要被外部访问,因此通过annotation可以指定bridge网络模式,分配host-local的ip,避免占用全局网段中的ip资源。同时也利用了linux tc进行混部pod的网络带宽限制。
5)驱逐机制
混部agent层支持内存、磁盘、cpu load等维度的驱逐机制。当任意资源负载达到设置的驱逐水位时,agent会立即驱逐机器上的混部任务。为了防止任务在同一台机器上被频繁驱逐,需要在驱逐后设置一定的冷却时间,冷却期内禁止调度混部任务。
五、离线间混部
针对训练、转码等离线集群跑大数据混部任务的场景,我们基于在离线混部框架做了功能增强,其关键点在于yarn nodemanager on k8s。具体的调度步骤为:
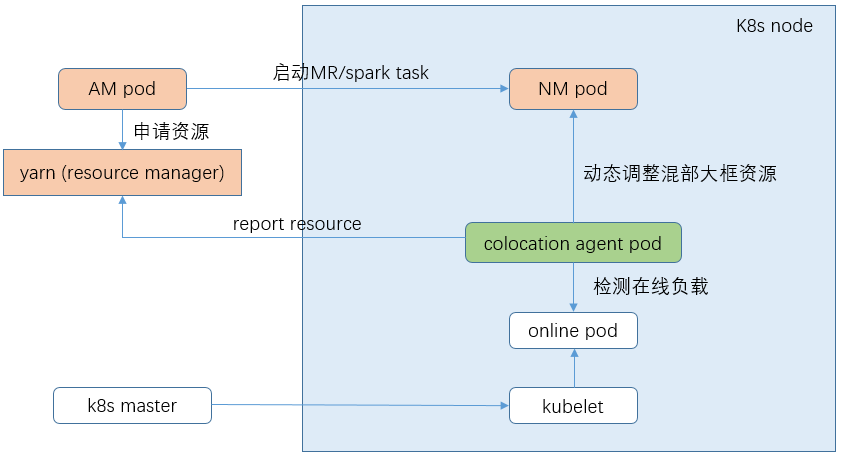
1)yarn node manager以daemonset的形式部署在相应的混部节点上
2)节点上的混部agent会动态检测在线容器负载变化,并根据设置的混部策略计算可混部值。这个值一方面会通过接口上报给yarn rm,另外一方面会设置到混部大框的cgroup中进行动态的资源限制
3)用户把大数据任务提交到混部集群时,rm会找到集群中有充足资源的混部节点,并最终在nm中拉起task
为了降低大数据任务对非混部业务的影响,大数据团队也做了相关技术改造,例如支持remote shuffle、基于应用画像识别小规格任务进行调度等。
六、混部管理平台
我们开发了界面化的混部管理平台来支撑日常的运维需求。主要功能包括:
策略管理
支持批量查看和设置节点的混部策略,例如安全水位、硬限值等。同时也支持设置节点组,只要节点打上对应的组标签,管控层可以秒级感知并立即下发相应混部策略。
开关混部
如果临时需要对特定机器关闭混部,可以在平台进行一键关闭,此时会立即驱逐机器上的混部任务并且停止上报混部资源。
监控查看
单机粒度监控主要满足日常排障需求,可以精确查看某一时刻机器上的混部上报量、混部任务数、混部实际资源消耗等。节点组粒度的监控则可以评估这批机器整体贡献的混部量以及对应的使用情况。
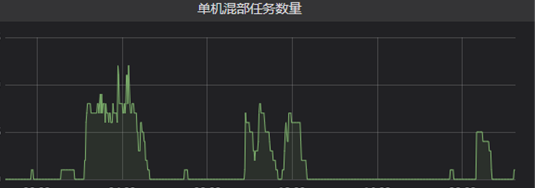
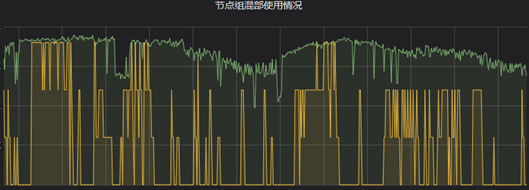
七、混部效果
目前B站云平台大部分机器都参与了混部,混部机器的平均cpu使用率可以达到35%,峰值使用率则可以达到55%左右。这些混部算力支撑了B站大规模的视频转码任务,以及ai机审、大数据MR等任务,节省了数千台机器的采购成本。
八、总结
本文介绍了B站基于k8s云平台进行的混部实践,主要分为在离线混部、离线间混部等业务场景。我们采用了一套对k8s无侵入的混部框架,并且通过调度、资源隔离等手段来确保非混部业务的SLO,另外也开发了相关的监控、策略管理平台等来提高整体混部系统的可运维性。后续我们会在内核层隔离与可观测、统一调度等方面优化混部技术框架,持续助力云平台降本。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721