

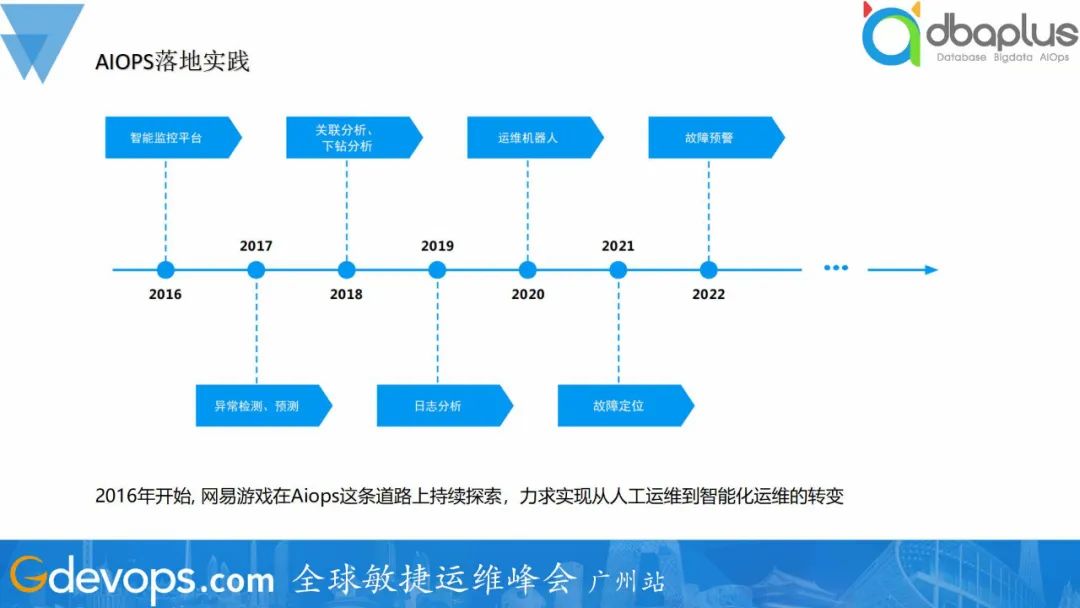
一、网易游戏AIOPS落地线路图
2016年开始, 网易游戏在AIOps这条道路上持续探索,力求实现从人工运维到智能化运维的转变。从2016年开始组建智能监控团队,构建智能运维平台,一直到现在,落地了异常检测、预测、关联分析、下钻分析、日志分析、运维机器人、故障定位、故障预警等。除此之外,还有很多其他功能,如火焰图分析、硬件预测、CDN文件发布等,都取得不错的实践效果。
二、异常检测
异常检测是研究AIOps的必经之路,后续很多场景功能都以异常检测为基础,属于不得不解决的问题。异常检测指通过 AI 算法,自动、实时、准确地从监控数据中发现异常,为后续的诊断、“自愈”提供基础。相比传统阈值配置成本高、误报多、场景覆盖少的问题,异常检测有易配置、准确率高、场景覆盖面广、自动更新等优点。
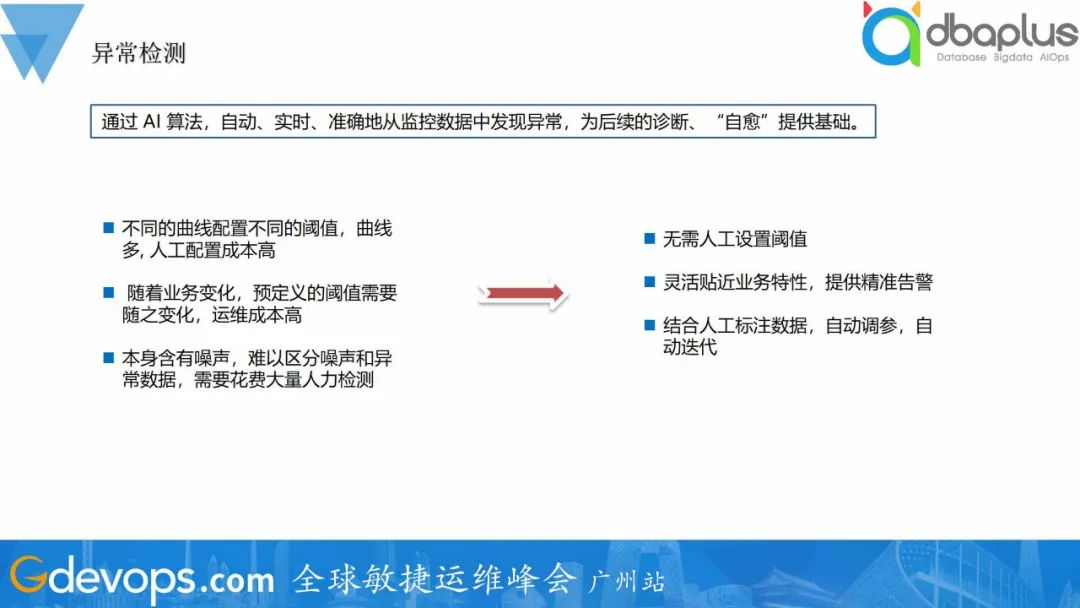
对于异常检测,其实网上很多文档或者书籍都给出了一些算法或者工具,但在实际运用的过程中,会发现效果往往不是很好,究其原因是这些算法只能有效地针对一些特定的场景、以及需要做很多的优化来适配实际的场景。为了更好地在实际场景中落地,我们对算法做了一些调整优化,并结合业务需求对指标进行划分,达到更好的检测效果。我们将异常检测根据指标类型划分成了三种场景----业务黄金指标(如游戏在线人数)、性能指标(如cpu使用率)、文本数据(如日志),采用不同的检测算法。

1、业务黄金指标
业务黄金指标的特性是周期性强、曲线波动小、指标量级小、准确率和召回率要求高。我们知道有监督模型具有高准召率、高扩展性的优点,因此我们考虑采用有监督模型对业务黄金指标进行异常检测。然而有监督模型需要大量的标注数据,但对异常检测项目很难收集到足够的异常数据。那应该如何去解决和平衡这两者之间的关系呢?我们从样本构建到报警可视化,构建了一整套的检测框架。
1)样本构建
考虑到样本收集困难问题,我们的样本主要来自两个方面——历史KPI数据集和线上用户标注数据。首先,抽样部分KPI数据集,采用简单无监督检测模型如Iforest检测得到异常score,通过不等比例分层抽样筛选出疑似异常样本和正常样本,进行人工标注,并划分成训练集和测试集用户模型训练和测试。功能上线后,收集用户标注数据,用于模型优化。用户标注的数据仅会作用于本项目,避免不同用户异常认知差异导致的错误报警问题。还有一点需要注意,当历史异常数据不足时候,可以通过异常生成的方式生成样本,如加噪声、设计抖动模式等方式。
2)预处理
预处理模块包含曲线分类、缺失标准化处理以及特征计算三个部分。曲线分类采用LSTM+CNN的方式实现,将待检测KPI分成3类(稳定、不稳定、不检测),分类准确率可达到93%+。线性和前值填充的方式进行缺失值处理,并max-min归一化。特征包含统计特征、拟合特征、分类特征、滤波特征、自定义特征等,构建近500维特征。考虑到无效特征问题,需要进行特征选择,再进行建模。
3)算法模型
模型主要采用常见模型,如RF\XGB\GBDT等,再用LR进行集成,进行检测。
4)可视化
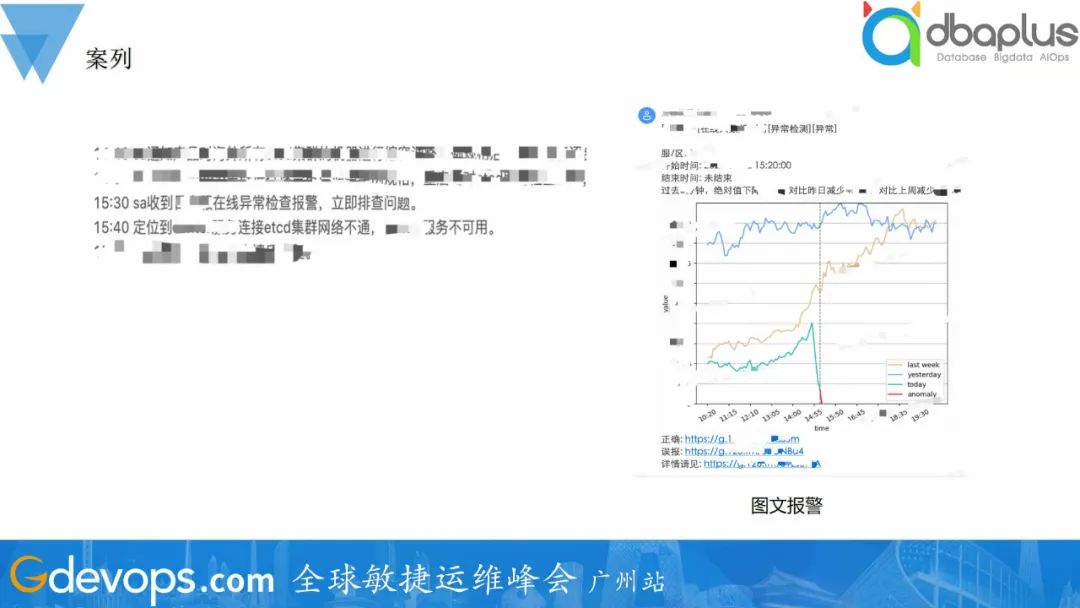
可视化部分包含图文告警、快速标注、异常视图三个模块。通过图文形式进行报警,在报警消息中加上快速标注链接,用户在收到报警后可以快速确认是否有异常发生并标注。

通过有监督模型的方式可达到高准召率的检测效果,线上检测效果可达到90%+,可满足用户的需求。
2、性能指标
有监督检测模型可以很好地对业务黄金指标进行检测,但并不适合性能指标场景。如上面所说,性能指标量级大、指标类型复杂、周期不定等。若依旧考虑采用有监督模型,需要花费巨大的标注成本和训练成本,对于大规模部署的业务很不友好。因此,我们采用无监督模型来检测性能类型指标。
我们按异常类型进行划分,划分成毛刺、漂移、高频、线型趋势四种类型,分别采用不同的检测模型进行检测,用户可以根据自己的需求进行选择报警类型。
毛刺类型:毛刺异常是最常见的一种类型,可以采用差分和SR算法进行检测,都有不错的效果。
漂移类型:漂移问题,首先需要进行STL周期分解,分解出周期、趋势和残差项。然后采用均值漂移和鲁棒回归算法进行检测。
高频类型:高频是毛刺的一种变种,有时不关心顺时的抖动,但是持续抖动时候就需要关注了。因此,采用的检测算法也会比较类型,可以采用多步差分进行检测。
线性趋势类型:线性趋势主要是为了监控内存泄漏类型问题,可以先进行STL分解,在LR回归和MK检测进行趋势检测。
最后,均需要进行周期抑制的步骤,避免周期性的误报问题。
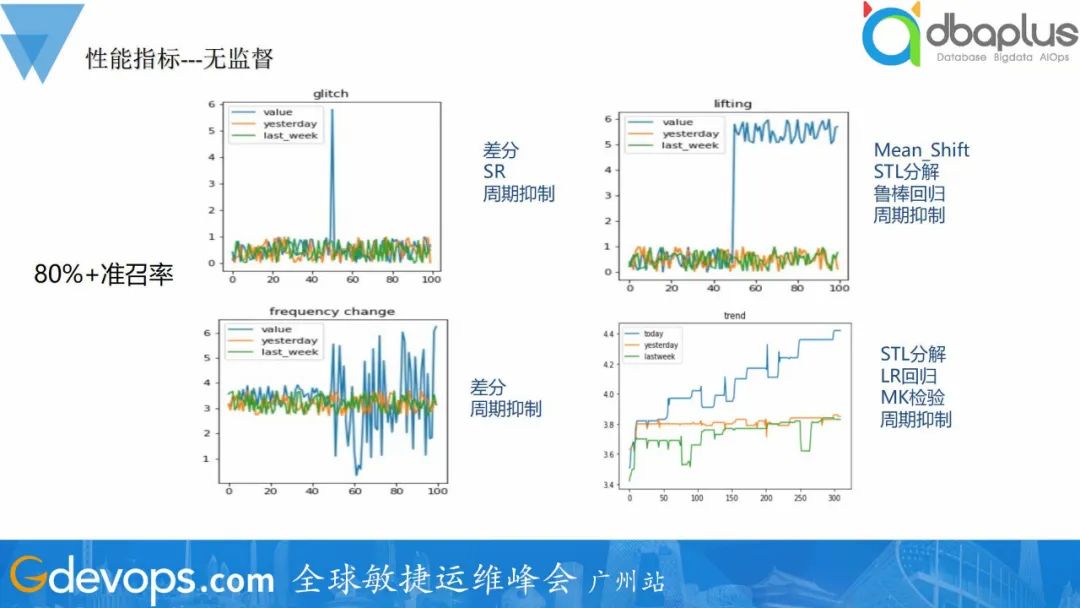
无监督的检测模型,准召率可达到80%+,基本可达到用户预期。通过图文告警的方式告警,帮助用户快速确认报警的正确性。
3、文本数据
业务的高速发展,对系统稳定性提出了更高的要求,各个系统每天产生大量的日志:
系统有潜在异常,但被淹没在海量日志中,有的项目警量最多可达每日1w+,如何合并告警。
故障出现后,日志报警量级太大,难以定位。
新版本上线,系统行为有变化,却无法感知。
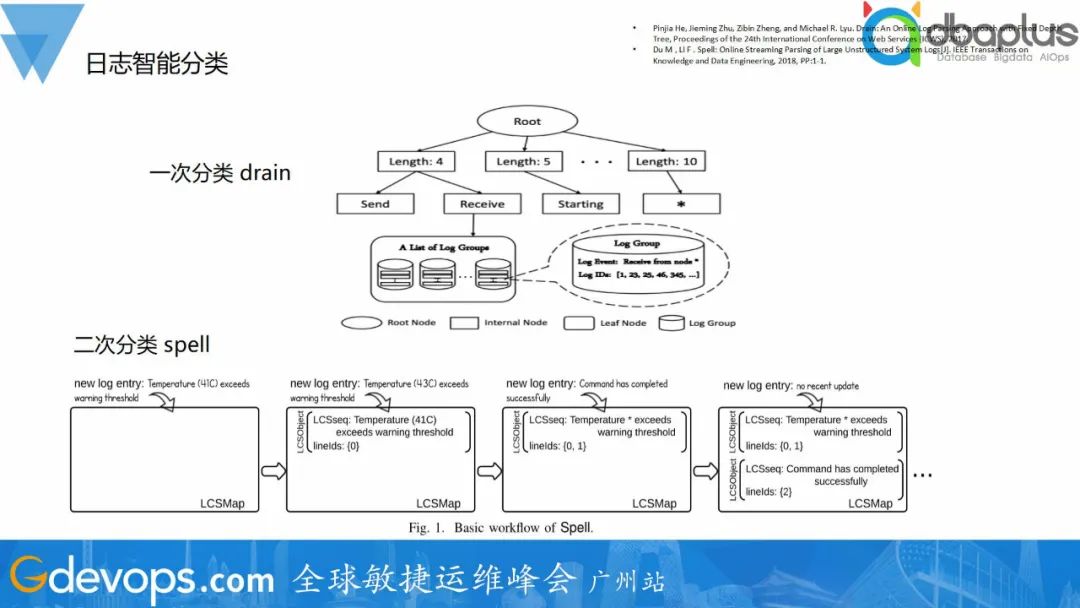
这些问题,归根到底,是日志信息太多、格式多样,不能很好归类。日志智能分析基于大数据和AI算法,提供实时日志智能分类,以及日志指标异常检测等功能。利用模型根据日志文本的相似性进行归类,自动提取对应的日志模版。如下图,可以从两条日志中提取出模板。

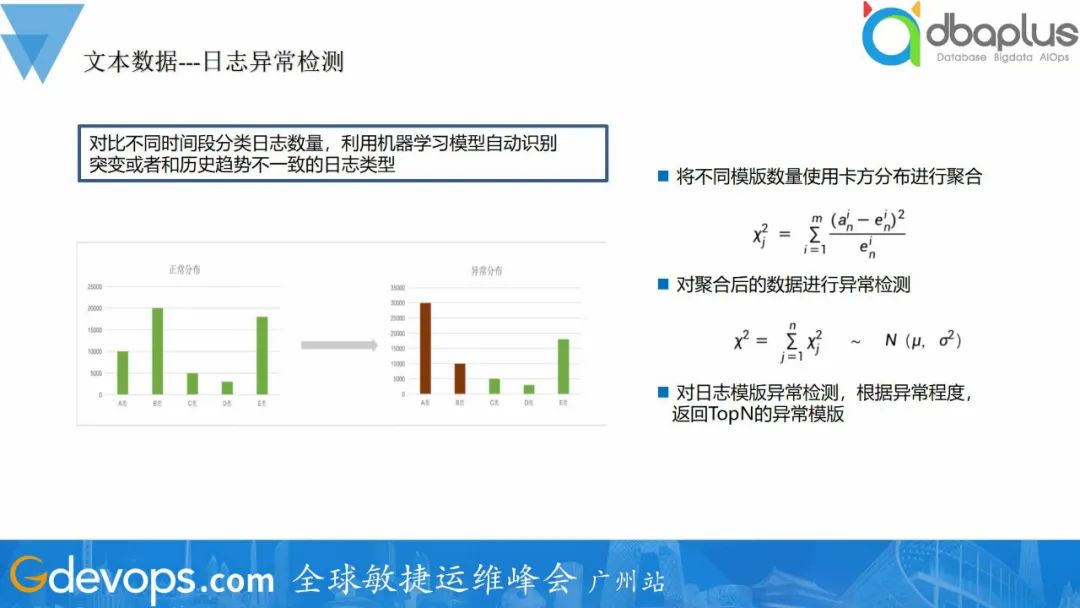
得到日志模板后,可以基于日志模板数量进行异常检测。智能异常检测会对比不同时间段的分类日志数量,利用机器学习模型自动识别突变或者和历史趋势不一致的日志类型,并发出告警信息:
根据历史两天日志分布情况训练模型,学习正常日志波动周期。
从日志整体分布分析,减少单类日志小抖动造成的误报。
自动选取影响分布最大的topN类日志。
与指标异常检测不同,日志异常检测可以检测到代码类型异常,对程序排障有重大帮助。此外,日志分类可以对日志治理也要很大的帮助,新项目/服务上线时候通过审查日志模板,可以根据需求整理、删除无效日志。
三、故障定位
在标准的故障处理流程中,故障定位一般可分为两个阶段:
故障止损前:可以快速获得可用于止损决策的信息,做出相应的止损操作使得服务恢复。
故障止损后:进一步找到导致故障的深层次原因,确定故障根因,将线上环境恢复到正常状态。
在游戏场景中,随着游戏及系统架构的日渐复杂,运维人员收到的报警信息也变得多种多样,在面对故障时,纷杂的报警信息令运维人员一时难以理清逻辑,甚至顾此失彼,无法在第一时间解决最核心的问题:
游戏架构日渐复杂,出现故障后排查链路比较长。
故障产生后,往往会引发多个报警,但是这些报警比较零散,没有按照一定的规则去分类和可视化。导致排查过程中需要人工先去梳理,和过滤报警。
目前故障定位依赖人工经验,这些经验难以被复用。

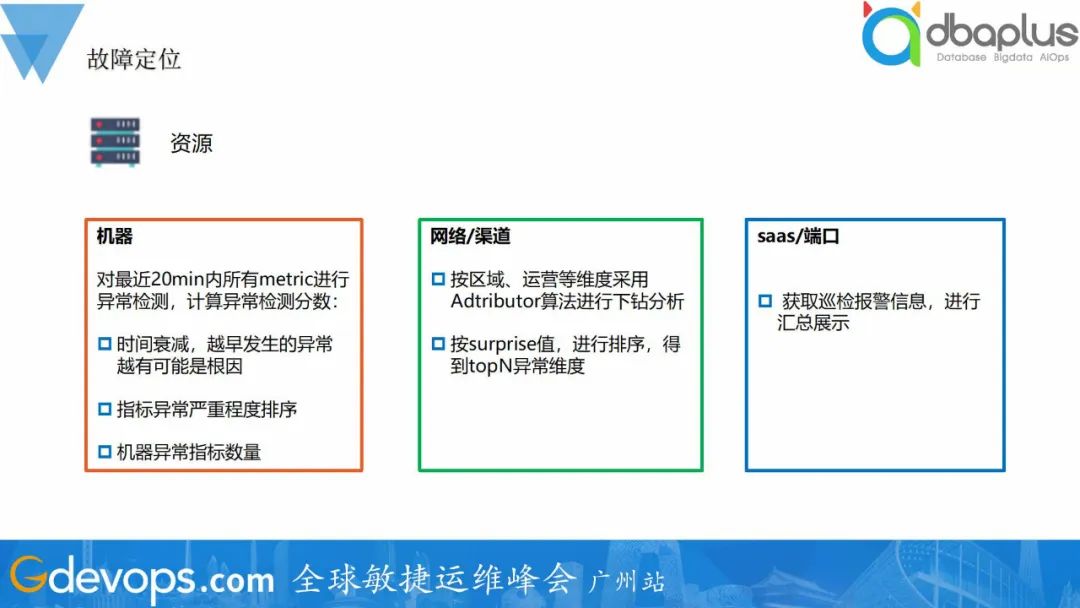
1、资源
资源维度可区分机器、网络渠道、SaaS进行分析给出异常信息。
1)机器
对最近20min内所有metric进行异常检测,计算异常检测分数。再基于越早发生的异常越有可能是根因、指标异常越严重越可能是根因、机器故障越严重越可能是根因几个准则进行排序,给出topN异常机器。
2)网络/渠道
采用Adtributor算法,按区域、运营商等维度进行下钻分析,给出topN异常维度。
3)saas
目前我们SaaS有比较完善的报警,直接可获取异常结果进行汇总。
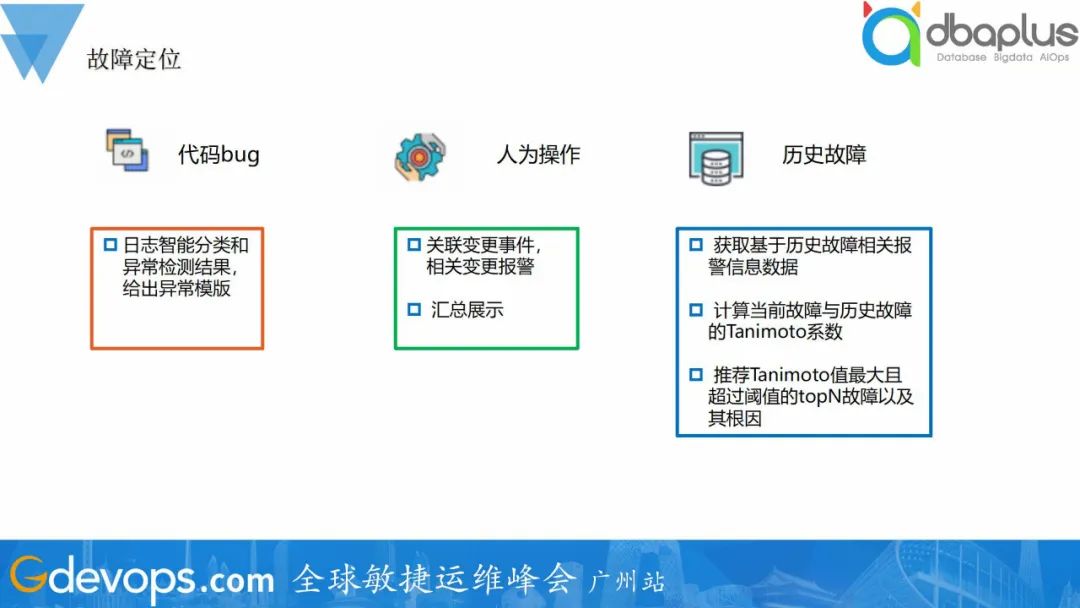
2、代码
代码问题直接可通过日志分类和异常检测发现,给出topN异常模板。
3、人为操作
人为部分主要是变更事件,与变更系统联动,关联到故障发生前的变更事件,并异常提醒。
4、历史故障
除了分析机器、代码等问题,还有一个比较有效定位故障根因的方式就是关联历史故障。如果本次故障与历史故障异常表现相似,那么大概率是相同的原因导致,故可以历史故障原因作为本次故障根因的推荐。计算当前故障与历史故障的Tanimoto系数,推荐Tanimoto值最大且超过阈值的topN故障以及其根因。
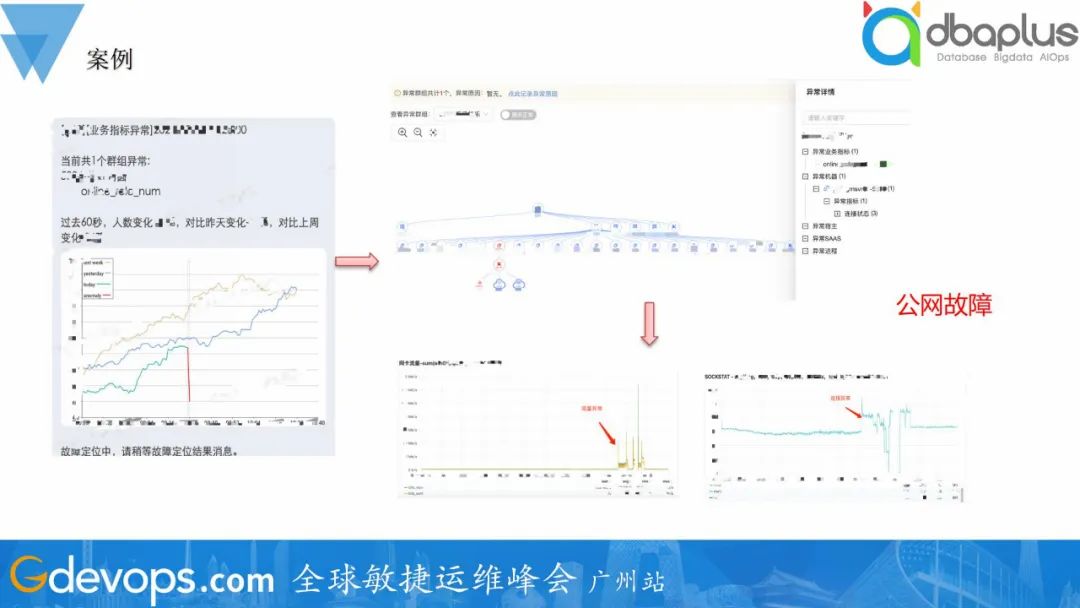
整体的故障定位流程,检测到故障的发生,基于拓扑资源、代码、人为因素、历史故障这几个角度出发,采用不同的方式进行根因分析。如检测到游戏在线人数下降,出发故障定位流程,检测到机器A 网络连接异常,告警出网络问题,人工进行排查出公网故障导致。









如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721