
王伟强,前抖音电商 C 端营销&大促方向 POC,阿里巴巴 2020 年货节&后年货节大促集团技术总执行 PM,广告和电商领域六年后端开发经验,久经大数据量、高并发、巨额资金场景下的技术考验。
内容来源丨公众号:字节跳动技术团队(ID:BytedanceTechBlog)
2015 年 5 月,杭州市萧山区某地光缆被挖断,某公司支付软件受到影响,用户反复登录却无法使用,一时间#XXX炸了#成为微博热词;2021 年 7 月 ,某视频网站深夜宕机,各系产品所有功能似乎全崩,直至次日凌晨才恢复服务。这两个故事,导致吃瓜群众对企业技术实力产生了质疑和误解,影响颇深……
从两个故事可以看出,对于失败场景考虑不充分对于企业声誉的打击有多大。站在程序员个体角度,面向失败设计对于个人的影响也同样巨大,企业的事故责任终究要落到程序员个人头上,而事故也往往会消耗组织对于个人的信任,直接或者间接地影响个人的发展。在字节跳动,事故对个人的影响不算太大,但在其他一些公司,一次事故往往意味着程序员“一年白干”。
不同年限的程序员差异到底在哪里?这个问题,我的理解是,除了架构设计能力、项目管理能力、技术规划能力、技术领导力之外,面向失败设计能力也是极其重要的一环。
业务开发的新同学有时候可能会有迷之自信,觉得自己写的代码与老鸟们没有什么不同。实际上,编写正常流程的业务代码大家的差异不会太大,但是针对异常、边界、不确定性的处理才真正体现一个程序员的功力。老鸟们往往在长期的训练下已经形成多种肌肉记忆,遇到具体问题就会举一反三脑海里冒出诸多面向失败的设计点,从而写出高可用的业务代码。如何去学习面向失败设计的方法论,并慢慢形成自己独有的肌肉记忆,才是新手向老鸟蜕变的康庄大道。
基于这样的考量,我写了这篇文章,对自己这些年来的一些经验和教训做了一些总结,希望能够抛砖引玉,让更多的老鸟们把自己的经验 share 出来,相互学习共同进步。
一、道
道的层面,我想讲讲面向失败设计的世界观。
1、失败无处不在
理想中,机器硬件永不老化、系统软件永不过期、流量总在预期范围内、自己写的代码没有 bug、产品经理永不改需求,但现实往往给你饱以老拳,给你社会的毒打:硬件一定会在某个时间点故障、软件总在一个时间节点跟不上时代潮流、流量总在你意想不到的时候突增——即使你在婚礼上、没有程序员不写 bug、产品经理不但天天改需求,甚至还给你提自相矛盾或者存在逻辑漏洞的需求。
无论是在传统软件时代还是在互联网、云时代,系统终究会在某个时间点失败。面向失败设计不是消除失败,而是减少乃至消除失败造成的影响,守着企业和个人的钱袋子。
2、唯一不变的是变化
不但失败无处不在,变化也无处不在。
1)不要写死——你的 PM 为改需求而生
“不要写死,你的 PM 为改需求而生”,这句话是我对口的一个产品经理的飞书个性签名,它深得我心。永远对代码写死保持不安,根据墨菲定律,你越是认为不会改变的字段或功能,就越会发生改变。所以,多配置、少写死,让你在产品改需求时快速响应从而令别人刮目相看,也能让你在发生故障时有更多的手段做快速恢复。
2)隔离可变性——程序员应软件变化而生
如果系统软件永不变化,我们还需要设计模式么?还需要面向对象么?面向过程一把梭不是又快又好么?但是,永不变化的系统软件,要程序员何用?抖音已经如此强大,什么都不改也能给字节挣很多钱,那抖音的程序员都可以下岗了么?好像并非如此。
设计模式,是前辈们总结的应对变化的利器。23 种设计模式,一言以蔽之,曰:隔离可变性。无论是创建型模式,还是结构性模型,又或者是行为型模式,设计的目的都是为了把变化关进设计模式的笼子里。
3)定期回归——功能在演化中变质
定期回归,也是应对失败的重要原则。互联网的迭代实在是太快了,传统软件往往以年月为维度迭代,而互联网往往以周乃至日迭代。每一天,系统的功能都可能在演化中变质,快速的迭代不但让业务代码迅速腐化变成屎山,也让内部逻辑日益臃肿,乃至相互冲突。终有一天,原本运行良好无 bug 的代码,会变成事故的导火索。
3、对代码的世界保持警惕
对代码的世界保持警惕吧,不然总有一天你会经历血泪教训。
1)不要相信合作方的“鬼话”
对合作方给你的所有接口、方案保持怀疑,也不要相信合作方任何一个未经你亲身验证的论断。实践才是检验真理的唯一标准,对世界始终保持怀疑是工程师的核心素质。不要在出现故障之后跟合作方相互甩锅时才追悔莫及,前期多做些验证,保护了你也保护了他,更是保护了你们之间的塑料友情。
2)不要相信代码注释
一行错误的代码注释,把我从阿里带到了字节,亲身经历的血泪教训。错误的代码注释不如没有注释,不要再用错误的注释给后来人埋坑了,救救孩子吧。
3)不要相信函数输入
NPE(NullPointerException 空指针异常)也许是程序员职业生涯中遇到过的最多的错误,这一点颇令人困惑,因为程序员从刷 LeetCode 第一道题开始,就知道需要对函数参数做检查。
之所以出现这样的结果,是因为线上生产环境所能遭遇的场景远比一道代码题复杂,这其实也是工业界与学术界的区别,学术界的问题是确定的,工业界的问题是不确定的。即使上游传递参数的是一个你认为极为可靠的系统,即使你遍览程序上下文确定不会出现空参数,也最好去做一些防御性的设计,因为可靠的系统也会给你返回不合规范的参数,当前不存在空参数的代码在未来的某一天也会被改得面目全非。
4)不要相信基础设施
即使是支付宝也会崩溃,即使是可用性 6 个 9 的系统,全年也有 31 秒中断。不要相信基础设施,做好灾备,搞好混沌工程,才能让你每个晚上睡得安稳,避免被报警电话打醒。
4、设计原则
1)简洁的方案最优雅
如果你设计的技术方案没有太多的花里胡哨,整体透露着一种大道至简的美感,也许你就离成功很近了。简洁的方案代表着更小的理解成本、更小的维护成本、更好的扩展性。
如果你的方案里面到处都是花里胡哨的炫技,看起来复杂而严谨,那么也许你离让自己头疼也让别人头疼不远了,一顿操作猛如虎,一看月薪两千五。
当然,并不是最简洁的方案就是最合适的方案,举个例子,核心交易链路的服务必然会比数据展示的服务稳定性要求更高,因而做了较多高可用设计之后方案会更加复杂,因而在满足稳定性的前提下选用尽可能简洁的方案才是推荐的做法。
2)开闭原则是设计模式的总纲
开闭原则是设计模式的总纲,大部分设计模式里面都有开闭原则的影子,软件实体应当对扩展开放,对修改关闭,可以通过“抽象约束、封装变化”来实现开闭原则。开闭原则可以使软件实体拥有一定的适应性和灵活性的同时具备稳定性和延续性。
基于开闭原则,很多常见的设计问题都有了答案:
① 大量 if-else 的屎山代码问题
大量的 if-else 肯定是不符合开闭原则的,每一个 if-else 的代码支路都是对原有代码结构的破坏,这里就可以应用工厂+策略设计模式对 if-else 进行剥离,把逻辑的新增和修改限制在工厂模式子类的内部。
② 冗长的业务工作流处理问题
业务流程代码往往非常冗长,封装得不好的话阅读和维护代码都非常困难,可以考虑用命令+职责链设计模式对工作流做封装。封装的好处在于,整体的工作流读起来将非常清晰,主流程代码往往能从数百行精简到十行以内,并且,对流程的修改仅仅是简单的断链或者增加链节点的操作,从而把修改的影响减到最低。
③ 历史字段类型修改问题
互联网开发过程中经常需要修改历史字段的类型,根据开闭原则,我们不该去修改原有字段的类型,而应该新增一个字段,这样才能保证对上下游链路的影响最小。
④ 对象属性中途篡改问题
举个实际的业务场景,在某些业务请求中,抖音极速版需要做与抖音相同的处理,把抖音极速版的 APPID 改成抖音的 APPID 是最简单的方法,但是这种做法是不符合开闭原则的,对对象属性中途的篡改,会改变对象在程序中的语义,总有一天它会有不符合预期的表现,很多事故因此而起。正确的做法是,在上下文中传递一个新的字段,下游的每一步处理都可以选择正确的字段做正确的处理,而不会被中途篡改的字段蒙蔽。
3)懒惰是程序员最大的美德
懒惰是程序员最大的美德,好的程序员往往是默默无闻的,越是在团队里面滋哇乱叫到处救火刷存在感的程序员越可能是团队的慢性毒药。
为了让自己懒惰,安安稳稳躺平就把业务做好,程序员必须掌握平台化、工具化、自动化三板斧。平台化,把程序员从无穷尽的重复劳动中解救出来;工具化,把程序员从水深火热的人肉运维和 oncall 中解救出来;自动化,让程序如流水线般顺滑,从而提升程序员的人效。能将这三板斧挥舞到什么层次,也体现了程序员能力到达了什么层次。有了平台化、工具化、自动化,就可以做标准化、规模化,助力公司和业务持续往上走。
二、术
术的层面,我想讲讲在组织和流程角度如何面向失败设计。
1、组织
1)面向失败设计的工种
测试工程师、测试开发工程师、风控&安全合规工程师都是开发工程师最可靠的合作伙伴,也是企业为了面向失败设计而设置的工种。
测试工程师是软件质量的把关者,他们是线上质量的卫士,对开发工程师代码的质量和性能负责。测试开发工程师是一个技术型的软件测试工种,除了做常规的测试工作之外,还会写一些测试工具和自动化脚本,用自动化的手段来提高测试的质量和效率。风控和反作弊工程师对业务的生态负责,监测业务的异常问题,提高业务风控的效果。安全合规工程师则是对信息安全负责,能够对于项目提供合规咨询、信息安全风险评估。
2)面向失败设计的组织形式
安全生产小组是一种面向失败设计的组织形式。安全生产小组往往是横向的技术团队,对多个业务团队提供规范制定和推行、生产过程管控、事故复盘组织等技术支持,为线上质量负责,通常还会在每个业务团队设置系统稳定性负责人,作为接口人来有效推行他们制定的制度。
结对编程,也是一种面向失败设计的组织形式。严格意义的结对编程,要求两个程序员在一个计算机上共同工作。一个人输入代码,而另一个人审查他输入的每一行代码。结对编程可以让程序员写出更短的程序,更好的设计,以及更少的缺陷,同时,结对编程也可以促进知识的传播,让新人快速进步,也让老人在带新的过程中总结自己的知识和经验,还可以规避在相应开发人员请假或者离职带来的工作交接的问题。
严格意义的结对编程,在互联网行业极为罕见,很少有团队会真正这样实操,也许是因为在管理者看来,两个人干同一件事情大大增加了人力的成本。但是,结对编程的一些思想和理念,也值得我们借鉴,比如我们可以让两个程序员结对做业务 owner,互为 backup,相互 code review,从而在一定程度上获得结对编程的好处。
2、流程
假设不做面向失败设计,那么软件开发流程也许可以简化为编码+发布两步。但是成熟企业的开发流程大致如下:
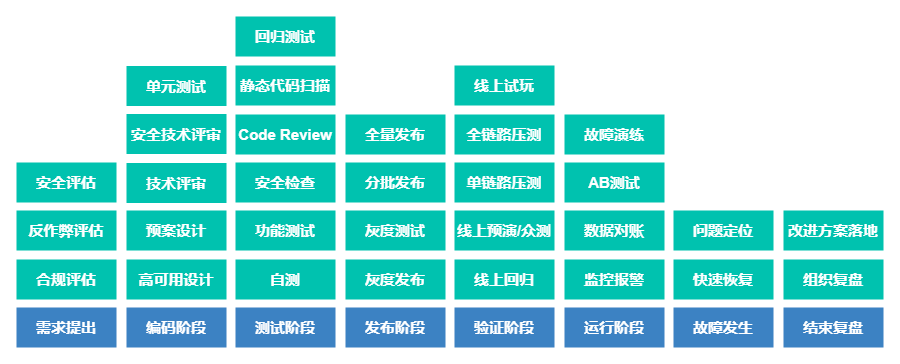
需求提出阶段
需要先期做一些合规评估、反作弊评估、安全评估,在前期就把一些潜在的安全合规风险排除。
编码阶段
在设计技术方案时需要考虑止血/降级/回滚措施,并组织技术评审和安全技术评审,针对技术方案中的安全风险做一些评估。除此之外,最好做一些单元测试,可以大大提高代码的质量。
测试阶段
需要开发人员先做自测,再让测试工程师参与功能测试、安全工程师做安全检查,针对代码改动可能造成的额外影响,做好做一次更大范围的回归测试,以排除一些预期外的影响。
发布阶段
需要采用灰度发布的机制,先发布小部分机器,或者仅针对部分地区用户灰度,在灰度发布之后做灰度测试验证功能正常,再继续分批发布、全量发布。
验证阶段
可以让测试同学在发布完成之后做一次线上回归,保证功能在线上环境稳定可用。对于大型活动,往往还需要组织内部用户线上预演或众测。针对非预期内流量可能把系统打挂的风险,可以做单链路压测和全链路压测。在大型活动开始前,如果条件允许,或者在小范围做一次线上试玩,提前暴露一些风险。
运行阶段
需要开发人员做好监控报警和离在线数据对账。对于项目的效果,可以用 AB 测试来量化收益。
故障发生时
第一时间必须做好故障快速恢复,尽可能减少线上损失,之后再考虑定位故障原因。
在项目结束或者故障处理结束之后,需要组织一次有效的复盘,并对过程中的问题做一些总结,形成有效的改进方案,并持续跟进改进方案的落地
3、一些观点
1)测试同学的重要性,怎么吹都不为过
测试工程师是线上质量最重要的卫士,他们的重要性,怎么吹都不为过。一个优秀的测试同学,可以做到以下事情:
非黑盒测试,具备读懂开发代码的能力,根据代码针对性地设计测试用例;
设计完备的测试用例,覆盖所有测试场景;
编写数据对账脚本,能够做离线数据对账和实时数据对账;
编写自动化测试工具;
编写数据一致性监控脚本、资损防控工具。
2)单元测试最省时间
编写单元测试用例,看似费时间,实则是最省时间的做法。单元测试保证了代码的行为与我们期望一致,从而省下了大量的发布、自测、联调、修改代码的返工时间,另外,可以做单元测试的代码往往职责更加清晰、分层分块更加合理、稳定性更好。
3)复盘是对齐做事高标准的一个必要方式
复盘是不断优化组织,对齐做事高标准的一个必要方式。通过 PDCA(Plan-Do-Check-Action,戴明环)这样的一个循环,工作在不断的改善后,最终形成知识沉淀,作用于下一次计划执行,团队于是变得越来越有执行力,个人则成为 Better Me。
4)研发红线是程序员的保护伞
研发红线是企业面向失败设计行之有效的暴力机器,它由无数零件(规范和条目)组成、冰冷、机械、运行起来无法阻挡,不以个人意志为转移。研发红线强制要求程序员遵守企业的流程和规范,警告程序员不犯低级错误,看似冰冷无情,实则是程序员的保护伞。
三、技
在技的层面,我想谈谈面向失败设计的具体技术细节。但是技术细节实在太多,限于篇幅,此处只列举一些经典技术问题的解法。
1、将面向失败当做系统设计的一部分
针对非预期流量,可以做系统限流、系统过载保护、自适应扩缩容;
针对依赖服务超时或错误,需要对依赖系统设置超时时间,并对所有依赖做强弱依赖梳理,关键时刻降级非核心依赖;
针对预期外的情况,可以提前准备好紧急预案,并做好预案演练;
针对瞬时高流量,需要敏锐地判断系统的极限,做好流量打散,并避免 DB 和缓存热 key;
针对可能出现的机房问题,做好同城双(多)活和异地多活;
针对人为失误,可以使用平台化、工具化、自动化的方法减少人肉操作;
避免出现单点问题,做冗余设计来降低局部失败对系统的影响;
失败重试时需谨慎,避免踩踏雪崩;
故障只能减少,不能消除,做好监控报警、故障演练、攻防演练,锤炼风险应急能力。
2、分布式锁的六个层次
你只看到了第二层,你把我想成了第一层。实际上,我在第五层。
——芜湖大司马
Redis 实现分布式锁有六个层次,看看大家平常用的分布式锁处在第几个层次。
分布式锁设计原则:
互斥性
在任意时刻,只有一个客户端持有锁。
不死锁
分布式锁本质上是一个基于租约(Lease)的租借锁,如果客户端获得锁后自身出现异常,锁能够在一段时间后自动释放,资源不会被锁死。
一致性
硬件故障或网络异常等外部问题,以及慢查询、自身缺陷等内部因素都可能导致 Redis 发生高可用切换,replica 提升为新的 master。此时,如果业务对互斥性的要求非常高,锁需要在切换到新的 master 后保持原状态。
1)层次一
redis.SetNX(ctx, key, "1")defer redis.del(ctx, key)
使用 SetNx 命令,可以解决互斥性的问题,但不能做到不死锁。
2)层次二
redis.SetNX(ctx, key, "1", expiration)defer redis.del(ctx, key)
使用 lua 脚本保证 SetNX 与 Expire 的原子性,做到了不死锁,但是做不到一致性。
3)层次三
redis.SetNX(ctx, key, randomValue, expiration)defer redis.del(ctx, key, randomValue)// 以下为del的lua脚本if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end
分布式锁的值设定一个随机数,删除时只删除当前线程/协程抢到的锁,避免在程序运行过慢锁过期时删除别的线程/协程的锁,能做到一定程度的一致性。
4)层次四
func myFunc() (errCode *constant.ErrorCode) {errCode := DistributedLock(ctx, key, randomValue, LockTime)defer DelDistributedLock(ctx, key, randomValue)if errCode != nil {return errCode}// doSomeThing}func DistributedLock(ctx context.Context, key, value string, expiration time.Duration) (errCode *constant.ErrorCode) {ok, err := redis.SetNX(ctx, key, value, expiration)if err == nil {if !ok {return constant.ERR_MISSION_GOT_LOCK}return nil}// 应对超时且成功场景,先get一下看看情况time.Sleep(DistributedRetryTime)v, err := redis.Get(ctx, key)if err != nil {return constant.ERR_CACHE}if v == value {// 说明超时且成功return nil} else if v != "" {// 说明被别人抢了return constant.ERR_MISSION_GOT_LOCK}// 说明锁还没被别人抢,那就再抢一次ok, err = redis.SetNX(ctx, key, value, expiration)if err != nil {return constant.ERR_CACHE}if !ok {return constant.ERR_MISSION_GOT_LOCK}return nil}// 以下为del的lua脚本if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("del",KEYS[1])elsereturn 0end// 如果你的Redis版本已经支持CAD命令,那么以上lua脚本可以改为以下代码func DelDistributedLock(ctx context.Context, key, value string) (errCode *constant.ErrorCode) {v, err := redis.Cad(ctx, key, value)if err != nil {return constant.ERR_CACHE}return nil}
解决超时且成功的问题,写入超时且成功是偶现的、灾难性的经典问题。
还存在的问题是:
单点问题,单 master 有问题,如果有主从,那主从复制过程有问题时,也存在问题;
锁过期然后没完成流程怎么办。
5)层次五
启动定时器,在锁过期却没完成流程时续租,只能续租当前线程/协程抢占的锁。
// 以下为续租的lua脚本,实现CAS(compare and set)if redis.call("get",KEYS[1]) == ARGV[1] thenreturn redis.call("expire",KEYS[1], ARGV[2])elsereturn 0end// 如果你的Redis版本已经支持CAS命令,那么以上lua脚本可以改为以下代码redis.Cas(ctx, key, value, value)
能保障锁过期的一致性,但是解决不了单点问题。
同时,可以发散思考一下,如果续租的方法失败怎么办?我们如何解决“为了保证高可用而使用的高可用方法的高可用问题”这种套娃问题?开源类库 Redisson 使用了看门狗的方式一定程度上解决了锁续租的问题,但是这里,个人建议不要做锁续租,更简洁优雅的方式是延长过期时间,由于我们分布式锁锁住代码块的最大执行时长是可控的(依赖于 RPC、DB、中间件等调用都设定超时时间),因而我们可以把超时时间设得大于最大执行时长即可简洁优雅地保障锁过期的一致性。
6)层次六
Redis 的主从同步(replication)是异步进行的,如果向 master 发送请求修改了数据后 master 突然出现异常,发生高可用切换,缓冲区的数据可能无法同步到新的 master(原 replica)上,导致数据不一致。如果丢失的数据跟分布式锁有关,则会导致锁的机制出现问题,从而引起业务异常。针对这个问题介绍两种解法:
① 使用红锁(RedLock)
红锁是 Redis 作者提出的一致性解决方案。红锁的本质是一个概率问题:如果一个主从架构的 Redis 在高可用切换期间丢失锁的概率是 k%,那么相互独立的 N 个 Redis 同时丢失锁的概率是多少?如果用红锁来实现分布式锁,那么丢锁的概率是(k%)^N。鉴于 Redis 极高的稳定性,此时的概率已经完全能满足产品的需求。
红锁的问题在于:
加锁和解锁的延迟较大。
难以在集群版或者标准版(主从架构)的 Redis 实例中实现。
占用的资源过多,为了实现红锁,需要创建多个互不相关的云 Redis 实例或者自建 Redis。
② 使用 WAIT 命令
Redis 的 WAIT 命令会阻塞当前客户端,直到这条命令之前的所有写入命令都成功从 master 同步到指定数量的 replica,命令中可以设置单位为毫秒的等待超时时间。客户端在加锁后会等待数据成功同步到 replica 才继续进行其它操作。执行 WAIT 命令后如果返回结果是 1 则表示同步成功,无需担心数据不一致。相比红锁,这种实现方法极大地降低了成本。
3、热点库存扣减
秒杀是非常常见的面试题,很多面试官上来就让面试者设计一个秒杀系统,面试者当然也是“身经百战”,很快可以给出熟背的“标准答案”。
但是,秒杀还是相对简单的热点库存扣减问题,因为扣减的库存量不大。更加典型的热点库存扣减问题是春节红包雨,同一个资金池数亿人抢红包。对于春节红包雨介绍两种方案:
1)方案一
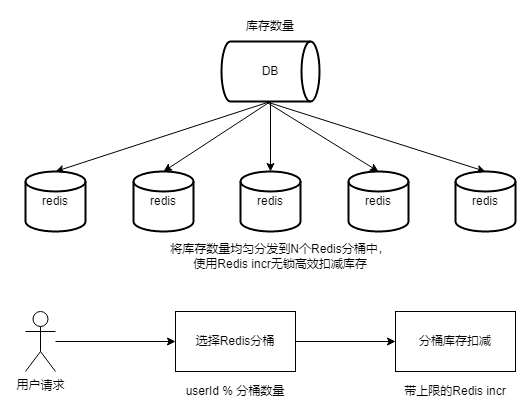
存在问题:
不同分桶之间,库存消耗不均,可能导致部分用户无法扣减库存,但其他用户可扣减库存,从而引发用户投诉。
2)方案二
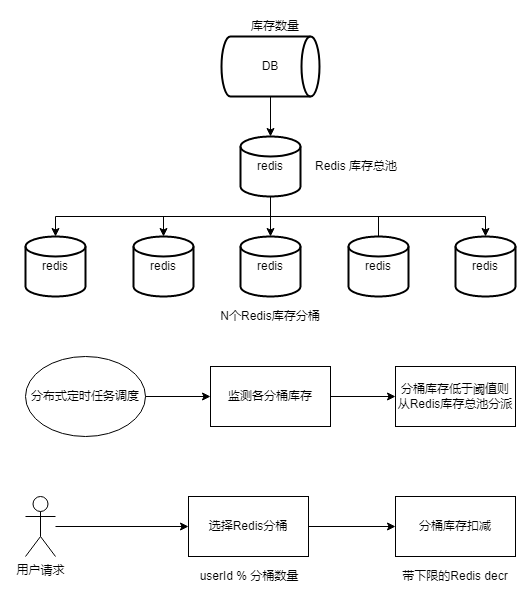
小量多次地分派库存,从而缓解分桶库存消耗不均问题。
2021 年抖音春节红包,将用户进入的时间打散,减少瞬时请求峰值,也是一个很好的技术思路。
3)如何体现面向失败设计
① 为何用定时任务调度主动分配库存,而不是在分桶库存不足时被动拉库存?
答:因为主动分配库存 QPS 比被动拉库存低几个量级。
② 如何应对超大流量?
答:流量不触达 DB、分桶、打散。
③ Redis 库存总池为何不用某个 master 机器维护,而用定时任务调度随机挑选机器?
答:防单点。
编程之美,蔚为大观。好的代码,往往结构清晰,表意明确,设计精巧,无论是读代码还是写代码都可以给程序员一种直击心灵的美感,甚至让读者爱不释手,让作者引以为傲,引之为自己的代表作。但是,为了留住这种美,我们还需要去做面向失败的设计,充分考虑失败场景,才能减少失败的概率,向死而得生。
本文对面向失败设计做了一些浅显的思考,欢迎探讨、补充和指正。
参考资料








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721