
本文根据王赟老师在〖deeplus直播:云原生运维转型的多维度探索〗线上分享演讲内容整理而成。(文末有回放的方式,不要错过)

本次分享主要介绍如下几点:
分布式追踪的基本原理
分布式追踪在中信银行的落地实践
未来展望
一、分布式追踪基本原理
1、什么是分布式追踪?

如opentracing所述,分布式追踪又称为分布式请求追踪,对应用进行监控,用于定位问题故障和性能问题分析。
2、dapper模型
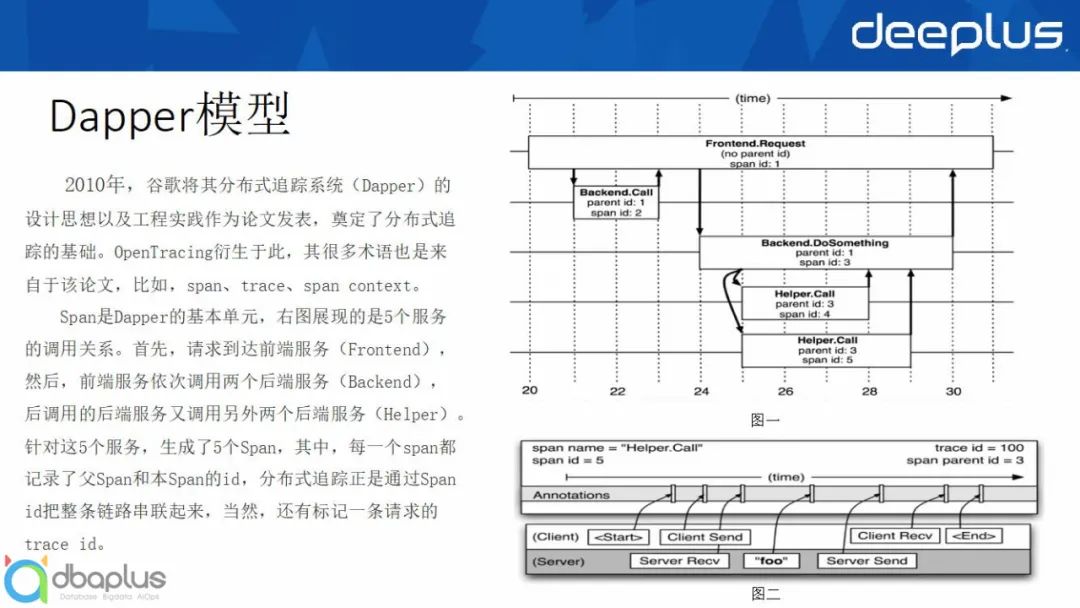
2010年,谷歌将其分布式追踪系统(Dapper)的设计思想以及工程实践作为论文发表,奠定了分布式追踪的基础。
3、opentracing模型

OpenTracing衍生于dapper论文,其很多术语也是来自于该论文,比如,span、trace、span context。
4、skywalking如何获取span信息?

Skywalking采用代码“埋点”的方式进行链路信息的采集,然后,使用grpc进行链路信息的上报。为实现跨进程和跨线程的链路串联,在进行跨线程和跨进程时,需要分别传递当前线程和当前进程的链路信息(SpanContext)到下一个线程和下一个进程,为此,设计了跨进程(sw8)和跨线程信息传输协议,并实现相应的api进行信息的生成和解析。
针对java应用,为实现无侵入埋点,使用了字节码增强技术,设计了一套字节码框架。通过spi技术来支持埋点的多样性,即用户可以通过字节码插件针对特定代码进行个性化的拦截器实现。
二、分布式追踪的落地实践
1、引入价值
微服务场景下,区别于传统的单体系统架构,具有服务多、链路长的特点,从而,形成错综复杂的请求链路。尤其地,在service mesh体系下,尽管sidecar能够把服务治理从服务代码中解耦,但比起传统的微服务链路,增加了一跳,势必会带来开发运维成本。解决这一系列的链路痛点问题,正是分布式追踪带来的价值。
1)故障定位
分布式追踪可理解为请求追踪,正如其名,其可以对请求链路进行追踪,记录请求过程中的各种事件,能够根据异常或响应码,判断服务处理请求的状态,进一步确定链路状态。从而,达到故障定位的能力。实际运用过程中,故障定位时间可以达到秒级。
2)依赖梳理
分布式追踪过程中,会记录请求链路所经过的服务或所经过服务的被调用接口信息,从而,形成服务调用关系或者接口依赖关系。为梳理组织调用视图和识别接口变更情况提供了数据来源。
3)性能分析
Dapper模型的核心概念是span,span会记录埋点位置发生请求和响应的时间,从而,衍生出服务响应时间、分段耗时统计、服务实例响应时间排序、服务慢接口排序等指标。开发测试的同学正可以借助该指标进行链路性能问题分析,同时,也可以借助该指标进行生产性能瓶颈分析,甚至能够为智能运维提供数据来源。
2、部署架构
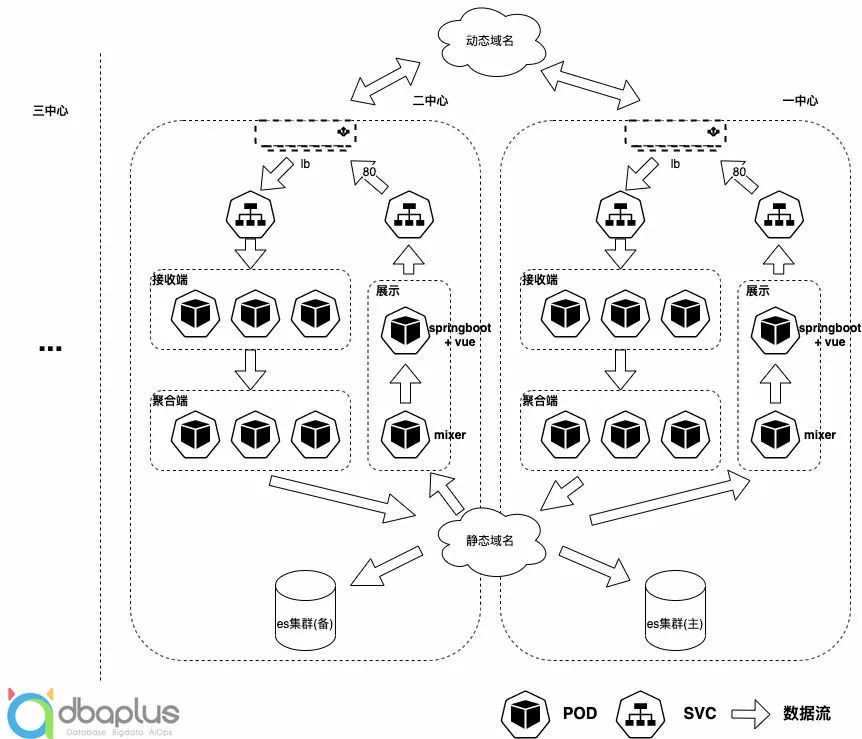
目前,使用skywalking的版本是8.5.0。其部署架构如图所示,依托kubernetes的编排能力,应用采用容器化部署,存储采用elasticsearch。应用部署组件及其功能如下所示:
接收端:度量数据的一次聚合、链路数据的持久化。
聚合端:度量数据的二次聚合及其持久化。
查询后端:graphql方式提供数据查询的接口,供页面查询用。
3、系统接入
针对Java应用,在接入过程中主要遇到三个问题,jdk版本、通讯协议、便利接入。
针对jdk版本,全面升级jdk版本到1.8.0。
针对通讯协议,中信银行自研了rpc框架(crpc),终态是所有系统均采用crpc协议,如场景一所示。但是,在过渡态,提供场景二的解决方案。当然,项目组也可以编写字节码插件的方式进行接入。
对于sidecar,则采用skywalking提供的go sdk进行手工埋点实现,如场景三所示。
1)场景一
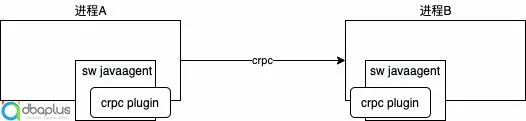
采用crpc进行通讯的应用系统,通过crpc插件进行无侵入埋点。
2)场景二
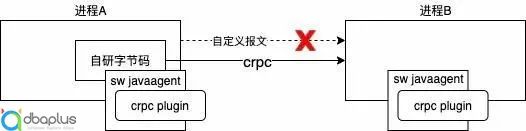
采用socket自定义报文通讯方式进行通讯的系统,可以服务端进行改造,客户端采用自研字节码的方式,转换原有的通讯协议为crpc通讯协议,最后,采用crpc插件进行埋点。
3)场景三

sidecar使用skywalking go sdk进行埋点。
4、容器环境接入
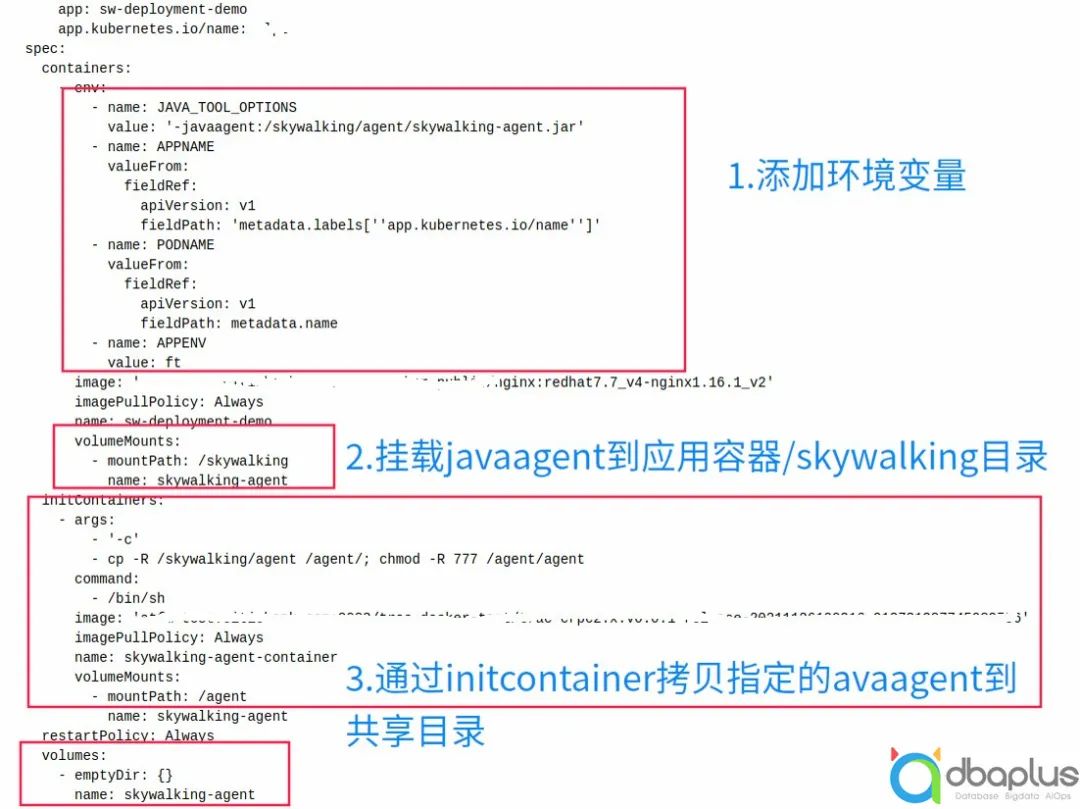
容器环境接入,采用kubernetes sidecar的特性,把javaagent以镜像的方式进行发布,项目组以initcontainer的方式引入镜像,然后,通过共享目录的方式,挂载javaagent到应用进程可访问的目录中。应用yaml文件如下所示:
三、未来展望
1、satellite介绍

2、定制化工作
冷热存储分离,目的在于优化elasticsearch的性能。
管理控制台,例如,增加采样率配置、接入应用的状态展示、应用上报控制等等。
服务上下游endpoint依赖关系的展示,例如,本服务依赖上游服务的哪些接口。
......
Q&A
Q1:tranceid如何与日志结合的呢,能讲解下使用场景吗?
A1:Traceid和日志关联可参考链接:https://github.com/apache/skywalking-java/blob/main/docs/en/setup/service-agent/java-agent/Application-toolkit-log4j-2.x.md。可用于链路追踪与日志的关联查询,日志也可以根据traceid进行日志聚合。
Q2:go-sdk可以把信息log到es和splunk两个吗?
A2:请参考链接:https://github.com/SkyAPM/go2sky。
Q3:针对日志全链路追踪,是否有必要将公司现有日志体系对接到行业标准?
A3:Skywalking进行分布式追踪尽管自定义了segment等概念,其也是衍生于dapper,对上报的埋点信息进行链路生成,即上报的信息中已包含链路串联的信息,并不需要从日志中获取链路信息相关。
Q4:这个只能查询单笔交易链路,有没有聚合的统计分析?
A4:Skywalking定位是apm,其包含了度量信息统计和展示的能力,可访问该链接进行体验:http://demo.skywalking.apache.org/,账号密码皆为skywalking。
Q5:为什么有部分考虑使用go语言开发sdk?
A5:中信银行的sidecar采用go语言开发,所以,会用到go sdk。
Q6:InfluxDB 做后端行吗?为什么选es?
A6:请参考该文章:https://skywalking.apache.org/docs/main/latest/en/setup/backend/backend-storage/#backend-storage。
Q7:请问你们有对探针做过新插件的开发吗?
A7:自研rpc框架采用新开发的插件进行链路信息的采集,插件开发可参考如下链接:https://github.com/apache/skywalking-java/blob/main/docs/en/setup/service-agent/java-agent/Java-Plugin-Development-Guide.md。
2022 Gdevops全球敏捷运维峰会·广州站将于6月17日举办,精选运维热门议题,共同探索云原生时代下的运维转型蜕变之路,部分议题抢先剧透:
【腾讯游戏】腾讯游戏SRE工具链建设实践
【平安银行】数据库智能化运维实践之故障自愈
【浙江移动】“AN”浪潮下数据库智能运维的实践与思考
【光大银行】光大银行智能运维探索与实践
【网易游戏】网易游戏AIOps探索与实践
【vivo】万级实例规模下的数据库可用性保障实践
【微众银行】亿级金融系统智能运维的深度实践
【去哪儿网】大规模混沌工程自动演练实践
【货拉拉】货拉拉智能监控平台的设计与实践
(持续更新……)
点击此处回看本期直播








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721