
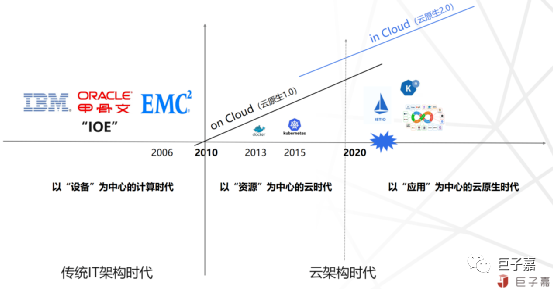
云计算的拐点已至进入成熟期,云原生成为驱动业务发展的动力引擎,作为新型基础设施,不仅是企业数字化转型的最佳技术路径,同时也成为新领域人工智能、大数据、边缘计算、5G 等底层平台基础设施。随着云原生技术的成熟和市场需求的升级,云计算的发展已步入新的阶段。
云原生2.0,将充分地释放了云计算的红利,未来将有更多的业务应用生于云,长于云;为了最大程度发挥云原生的优势,支持好各种复杂个性化场景,云原生技术在不断完善演进,从中心到边缘;理念也在不断总结升华,从微服务到Mesh,再到无服务,业驱云长,云随业动。
一、云原生时代
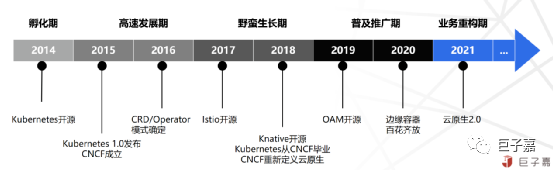
Kubernetes开启了整个云原生的时代,以两年为一个大的阶段,可以分为五个阶段,分别是孵化期、高速发展期、野蛮生长期、普及推广期、业务重构期。随着物联网、人工智能等技术的不断发展,尤其是产业互联网发展落地,云原生作为新一代基础设施,从互联网大厂走向企业,走向产业;云原生2.0,企业云化从“On Cloud”走向“In Cloud“,生于云、长于云且立而不破;企业新生能力基于云原生构建,使其生于云;应用、数据和AI的全生命周期云上完成,使其长于云;企业原来的业务核心系统开始基于云原生的技术理念解构及重构,实现借助技术的敏捷实现业务敏捷的数字化转型。
未来云原生必将更全面的服务于产业与实业,分布式云 + 云原生,将成为云基础设施新范式,赋能新云原生企业敏捷创新,推动云原生生态有序繁荣,让云无处不在,让智能无所不及。
二、Kubernetes架构及扩展性
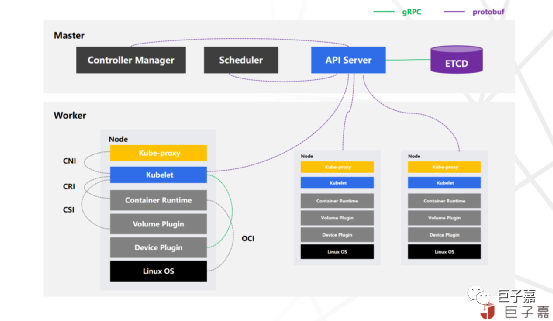
Kubernetes主要由以下几个核心组件组成:
etcd保存整个集群的状态;
apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
kubelet负责维护容器的生命周期,负责Volume(CSI)和网络(CNI)的管理;同时也负责管控Device Plugins,主要是GPU,FPGA及网络设备。
container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
早期在Kubernetes在高速发展期,为了快速适配各个各样的场景,将Kubernetes打造成一个可扩展的平台,大致可以分为基础设施(Infrastructure)及应用管理(Application Management)扩展两个方面:
基础设施(Infrastructure)扩展:
通过OCI与CRI标准容器镜像(image spec)及容器运行时(runtime spec)。
通过CNI与CSI标准化网络及存储,开放网络及存储扩展能力。
通过Device Plugins插件框架,将系统硬件资源引入到Kubernetes体系。
应用管理(Application Management)扩展:
通过CRD扩展Kubernetes用户自定义资源。
通过Operators实现Kubernetes应用生命周期管理。
Kubernetes可扩展性架构及CNCF开放式生态发展方向,在高速发展期,野蛮生长期乃至普及推广期,开放式平台及生态都是非常正确明智的选择;但是进入业务重构期,面向业务需要提供整体性一体化的平台,而不是一个碎片化的功能部件,不是所有公司都具备组装及调优能力,这时候平台的价值就会被重复的组装及调优将价值拉低;平台需要从散装转化成一体化,开箱即用的品牌机,要么就直接选择企业级容器平台或公有云容器产品,比如Openshift及阿里云ACK;要么通过生态治理,逐步收紧平台扩展能力,增加组件的成熟度监管,分久必合合久必分,在分与合中保障平台及生态的良性发展。
三、Kubernetes走向碎片化
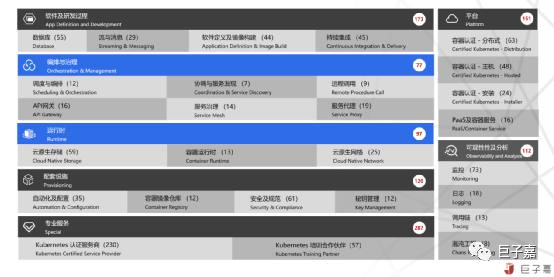
CNCF开放式生态,是导致整个生态体系碎片化的根源;从2015年CNCF只有Kubernetes一个项目,到如今高达80多个官方项目,其中毕业项目15个,孵化项目21个,沙盒46个项目;包含底层众多的容器运行时、容器存储、容器网络以及硬件加速器项目,还有以应用为中心的北向数据库、中间件等项目。
通过CNCF官方认证的Kubernetes的云服务或者发行版也多达130款,通过CNCF官方认证服务商和培训合作伙伴超过250家。在中国CNCF的会员数量超过60家成员单位。
如此庞大的软件生态体系,集结了开源,云厂商,软件服务商及设备厂商等多个利益方;整个生态大跃进式发展,无论是公有云厂家还是企业,都是忙于通过积木式能力组装容器平台,乐此不疲。还有公有云厂商,疲于跟进与整合容器技术,但只能提供毫无壁垒,毫无优势的工具平台,无法形成真正产品及竞争力;还有从容器,微服务到无服务技术,平台能力几乎应有尽有,貌似全部就绪,好像就只差最理想的应用迁入即可;但是在实际的使用及推广过程,与喧嚣的社区相比,云原生的价值被疲于应对平台各种诡异问题,兼容新老业务的痛苦过程中消耗殆尽,一片哀嚎。
容器运行时(Container Runtime Interface,简称 CRI)是Kubernetes v1.5引入的容器运行时接口,它将Kubelet与容器运行时解耦,将原来完全面向Pod级别的内部接口拆分成面向Sandbox和Container的gRPC接口,并将镜像管理和容器管理分离到不同的服务。在v1.6时已经有了很多外部容器运行时,如frakti和cri-o等。v1.7中又新增了cri-containerd支持用containerd来管理容器。
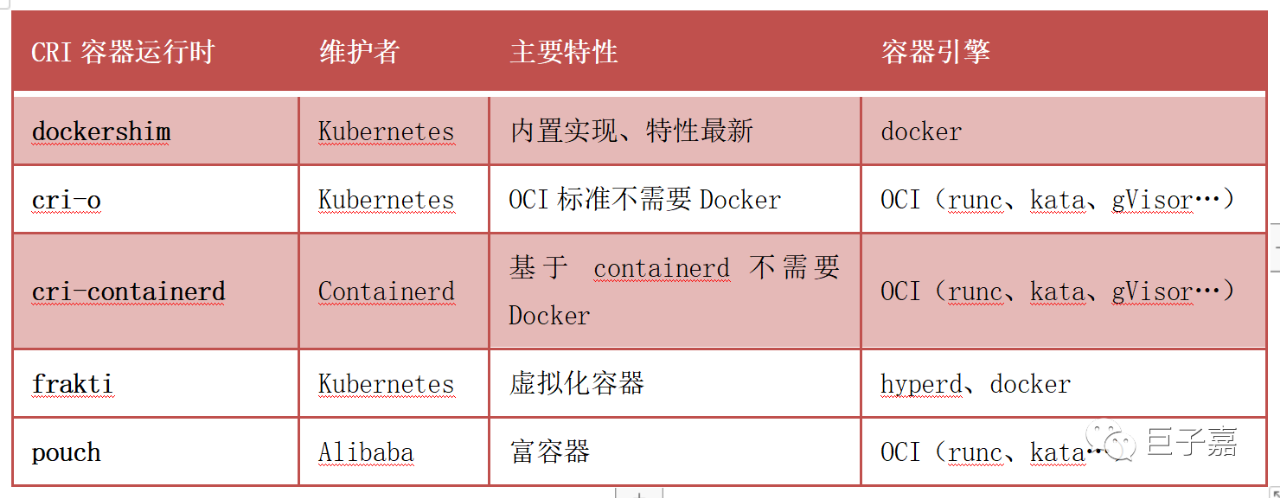
Kubelet衔接运行时的方式及调用链路如下:
docker :dockershim => dockerd => containerd => runc
containerd:containerd => shim v2 => runc
cri-o:cri-o => runc
frakti:frakti => runv
pouch:pouchContainer => containerd => runc
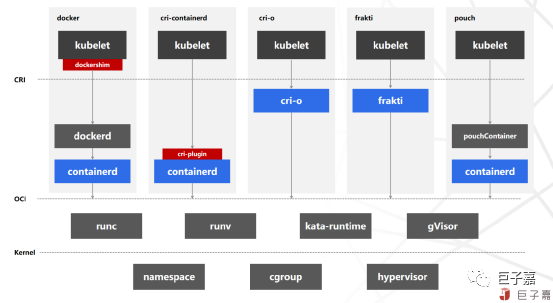
containerd与cri-o:两者都是调用runc,containerd是内置runc代码,通过函数直接调用;cri-o是通过linux命令方式调用runc二进制文件,在性能上containerd更具优势,但是cri-o集成方式更为合理优雅,比较推荐cri-o。
runc与runv:runc创建的容器进程,直接运行在宿主机内核上,而runv是运行在由Hypervisor虚拟出来的虚拟机上,占用的资源更多启动速度慢,而且runv容器在调用底层硬件时,中间多了一层虚拟硬件层,计算效率上不如runc容器。
总的来说,生产环境的运行时选择主要取决于运行效率,端到端的全流程运行效率,因此建议结合自身业务需求,使用场景以及团队技术储备等选择合适的容器运行时。对性能要求大于安全隔离要求时,推荐使用cri-o + runc;对安全隔离要求大于性能要求时,在隔离性要求较高的业务场景下,推荐使用frakti + runv。
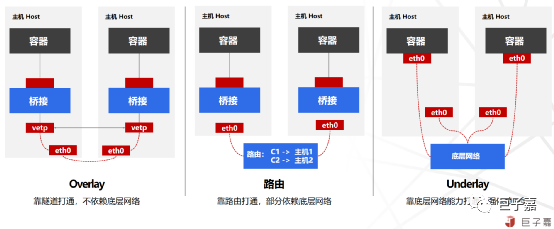
容器网络属于Kubernetes容器平台核心组件,技术复杂度高,对业务影响大。Kubernetes网络依赖底层的技术大致可以分为三大类:
Overlay模式是在二层或三层网络之上再构建起来一个独立的网络,这个网络通常会有自己独立的IP地址空间、交换或者路由的实现。VXLAN协议是目前最流行的Overlay网络隧道协议之一,显著优势就是灵活,对底层网络没有侵入性。
路由模式放弃了跨主机容器在L2的连通性,而专注于通过路由协议提供容器在L3的通信方案;路由模式更易于集成到现在的数据中心的基础设施之上,便捷地连接容器和主机,并在报文过滤和隔离方面有着更好的扩展能力及更精细的控制模型。
Underlay模式是借助驱动程序将宿主机的底层网络接口直接暴露给容器使用的一种网络构建技术,较为常见的解决方案有MAC VLAN、IP VLAN和直接路由等。

同时容器网络技术也在持续演进发展,社区开源的网络组件众多,每个组件都有各自的优点及适应的场景,难以形成统一的标准组件,以下是比较常用Flannel、Calico、Cilium、OVN网络插件简单介绍:
Flannel:Flannel是最流行的Kubernetes容器网络插件,提供多种网络模式实现,覆盖多种场景,支持3种网络模式:
UDP模式使用设备flannel.0进行封包解包,不是内核原生支持,上下文切换较大,性能非常差;
VXLAN模式使用flannel.1进行封包解包,内核原生支持,性能较强,性能损失可以控制在20%~30%左右;
HOST-GW模式直接将宿主机当作子网的下一跳地址,性能最强,性能损失大约在10%左右。
Calico:Calico 是一套开源的网络和网络安全方案,用于容器、虚拟机、宿主机之前的网络连接,支持3种网络模式:
全互联模式(node-to-node mesh)基于BGP协议,每一个BGP Speaker都需要和其他BGP Speaker建立BGP连接,这样BGP连接总数就是N^2,如果数量过大会消耗大量连接。
路由反射模式Router Reflection(RR)基于BGP协议,指定一个或多个BGP Speaker为RouterReflection,它与网络中其他Speaker建立连接,每个Speaker只要与Router Reflection建立BGP就可以获得全网的路由信息。
IPIP模式把IP层封装到IP层的一个tunnel,常规的网桥是mac层的,而ipip 则是通过两端的路由做一个tunnel,从而将两个本来不通的网络通过点对点连接起来。
Cilium:Cilium是一个基于eBPF和XDP的高性能容器网络方案,是Kubernetes第一个基于BPF的CNI,支持L3/L4/L7安全策略,支持三层平面网络(如Overlay,VXLAN和Geneve等),提供基于BPF的负载均衡,提供便利的监控和排错能力,为大规模集群环境而设计。Cilium的卖点并不是eBPF,相对于固化的iptables或ipvs而言,Cillium真正的卖点是eBPF提供的无限可编程能力。
OVN : ovn-kubernetes提供了一个OVS/OVN网络插件,支持underlay和 overlay两种模式。underlay是容器运行在虚拟机中,而ovs则运行在虚拟机所在的物理机上,OVN将容器网络和虚拟机网络连接在一起;overlay是OVN通过logical overlay network连接所有节点的容器,此时ovs可以直接运行在物理机或虚拟机上。
总的来说,Overlay模式对底层网络要求低、落地容易、IP地址占用少等特点,但是对性能损失比较大。路由模式更易于集成到现在的数据中心的基础设施之上,便捷地连接容器和主机,并在报文过滤和隔离方面有着更好的扩展能力及更精细的控制模型;Underlay模式对底层网络要求较高,但是如果底层已经有一个完整的虚拟化IaaS层,尤其是公有云场景,将云原生能力直接融入到现有的云体系,通过Underlay模式实现高性能,灵活可定义的容器网络才是最佳选择。
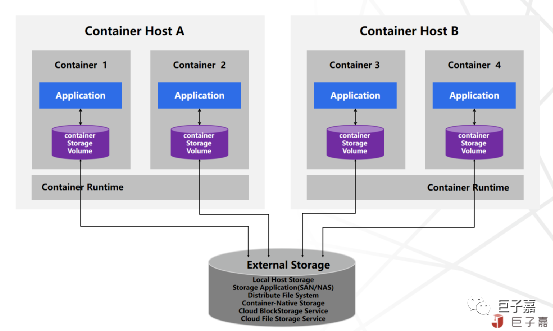
市面上的存储产品种类繁多,主要分为四大类,分别是分布式文件存储,分布式块存储,Local-Disk和传统NAS。
分布式块存储:包括开源社区的Ceph,Sheepdog,商业产品中EMC的Scale IO,Vmware的vSAN等,分布式块存储不适合容器场景,关键问题是缺失RWX的特性。
分布式文件存储:包括开源社区的Glusterfs,Cephfs,Lustre,Moosefs,Lizardfs,商业产品中EMC的isilon,IBM的GPFS等。分布式文件存储适合容器场景,但是性能问题比较突出。
Local-Disk:有明显的缺点,尤其是针对数据库,大数据类的应用。节点故障后,数据的恢复时间长,对业务影响范围广。
传统NAS:也是一种文件存储,但是协议网关(机头)是性能瓶颈,传统NAS已经跟不上时代发展的潮流。
Kubernetes v1.9 引入的容器存储接口CSI,并于v1.13版本正式GA。CSI的引入极大的增强了容器存储生态体系,标准化容器平台与外部存储系统的集成。有状态应用不需要了解底层存储系统的任何信息,只需将数据写入文件系统或块设备的容器存储卷,由容器平台透明地处理存储相关的编排与调度工作。
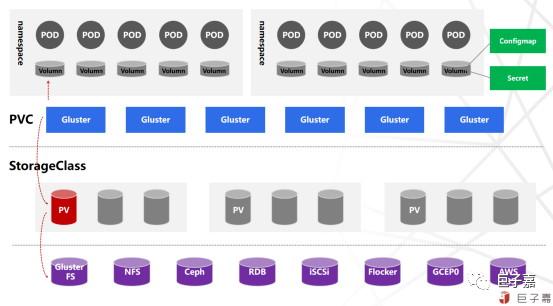
基于CSI实现的持久化Volume的创建和挂载流程如下:
用户提交PVC,Kubernetes平台自动创建出PV
Kubernetes平台将PV和PVC进行绑定
部署Pod并使用已创建的PVC,Kubernetes将Pod调度到某宿主机
Kubernetes将PVC对应的Volume进行Attach到对应宿主机
宿主机上的kubelet完成Volume的Mount操作
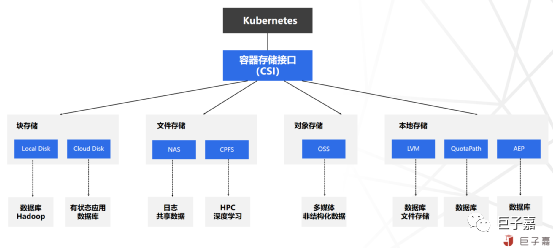
总的来说,容器存储方案的选择,需要基于实际的业务需求出发,深刻理解容器平台未来承载的业务类型,如果基于云平台构建云原生平台,尽量与IaaS底层保持一致,同时需要考虑团队的技术实力,开源产品对技术能力要求比较高,选择开源产品,最好有相应的技术人员储备。如果技术储备不足,最好是选择商用产品,虽然成本高点但经过了众多企业的技术验证。
1)资源对象及CRD,Kubernetes平台开放基础
Kubernetes标准的资源对象超过一百多个,自下而上可以分为四层:资源层,实现网络、存储及基础平台等资源对象;调度层,实现各种调度控制器及调度等资源对象;隔离与服务访问层,实现资源限制与隔离、配置、身份、路由规则等资源对象;应用层,实现应用逻辑、服务定义、生命周期控制等资源对象;云原生平台类产品主要是在调度层扩展,通过自定义CRD及控制器,实现Kubernetes的能力扩展,比如边缘容器,istio等。

CRD功能是在Kubernetes v1.7版本引入的,通过 CRD 可以快速自定义 Kubernetes资源对象。CRD可以是命名空间的,也可以是集群范围的,由CRD的作用域(scpoe)字段中所指定的,与Kubernetes内置对象一样,删除名称空间将删除该名称空间中的所有自定义对象。基于Kubernetes内置对象与CRD就可以创建出千变万化的组合;另外同一个资源对象又有多种实现方式,比如 Ingress就有10多种实现,PV就更不用说,部分互不相干扩展能力存在相互冲突及版本不兼容,一个生产运行的Kubernetes容器集群,尤其是启动了Istio,Knative能力,CRD的数量是远远超过Kubernetes内置对象,对于开发者与平台管理挑战巨大。
2)从Helm到Operator,实现应用全生命周期管理
云原生应用日趋复杂,仅仅通过Kubernetes对象及Yaml很难清晰的描述一个复杂的应用程序,所以诞生Helm与Operator。Helm 主要实现是云原生应用打包和版本管理等。Operator本质是一种调节器模式(Reconciler Pattern)的应用,主要实现云原生应用管理,尤其是有状态应用管理,协调应用的实际状态达到预期状态。

Helm :开发非常容易,可以使用git仓库管理,运维效率相对不高,用户使用简单,开源生态丰富。
Operator:开发入门较难,OperatorHub搭建困难,运维效率更高,用户使用简单,开源生态丰富
建议当前考虑使用Operator作为容器应用首选,社区有大量基于operator开源实现支持各种中间件和应用。同时也存在比较严重的碎片化问题,在Helm hub上Kafka的chart多大十几个,如果包含Kafka配置管理就更多很难选择。Operator Hub稍微好点,Kafka有三个Operator供选择。
3)OAM与KubeVela,走向标准与治理
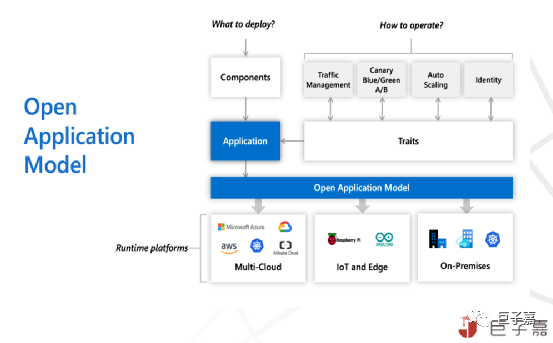
OAM:Kubernetes的核心API资源比如Service、Deployment等,只是云原生应用部分描述,所以衍生出Helm及Operator以应用为中心,描述一个可部署的应用,但是缺乏标准及规范,复用性差冲突难以排查处理,需要一个专注于应用管理的、标准的、高度一致的模型标准与规范,所以就有衍生出了开放应用模型 Open Application Model (OAM),基于OAM实现应用描述与基础设施部署,管理应用解耦,通过应用组件(Components),应用部署配置文件(Application Configuration),应用运维特征(Traits)实现平台无关、高可扩展的应用描述能力。
KubeVela:是基于OAM标准实现的,面向平台构建者的、简单易用,高度可扩展的开源云原生平台构建引擎。目标是让任何平台团队都能够以Kubernetes原生的方式,快速、高效的打造出适合不同业务场景的、能够直面用户的云原生平台出来。比如构建应用 PaaS、数据库 PaaS、AI PaaS 或者持续交付系统等。KubeVela开发入门简单,环境搭建困难,混合云场景优势明显,运维效率高,但是处于生态发展初期。
总的来说,Kubernetes原生的应用原生比较标准,但是一些偏平台的产品及应用就相当杂乱,大部分都只是借助Kubernetes 屏蔽了底层技术设施差异,对于上层的应用来说没有什么变化。这些应用大部分是传统云时代PaaS平台范畴的产品及应用,还有少部分基于云原生技术及理念的新产品,企业及研发团队需要根据自己的需求,通过这些产品及应用拼装成一个面向应用全生命周期的平台,依然有大量的重复建设工作。
四、总结
对Kubernetes平台及CNCF社区来说,Kubernetes作为云原生的核心平台,CNCF作为一个生态运营管理组织,要足够开放,满足上下游个性化集成的需求,确保整个生态繁荣及良性竞争,实现技术与平台快速演进,持续保持行业领先;同时也要去拥抱企业及开发者的真正需求,解决当前企业及研发团队平台杂乱,投入成本过大,无流程难以管控的难题,真正助力企业实现业务价值。
对企业及用户说,“境”优先,“器”其次,在云原生时代,面对复杂的平台、繁荣且碎片化的生态,不要过度追求“神兵利器”,至少先掌握一种工具,能搞定问题的就是好工具。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721