
自打去年以来,可观测性Observability这个概念又非常火,按照我的感受,在运维领域,这个概念是近两年继AIOps之后,热度最高的一个了。
无论是国内还是海外的运维相关的公司,都给了自己一个新的定位,就是可观测性平台,或者叫做可观测云,相对应的产品也是层出不穷。
对于我来讲,我看一个趋势,往往会从落地的角度,从实际情况来分析,反向去看,而不是单纯地看技术多么酷炫。
所以,我观测了很久Observability之后,打算还是从实际情况入手来聊聊这个概念,看看可观测这个东西到底包含哪些内容?它们之间是什么关系?
如果要落地,里面真正核心的、决定成败的又到底是哪些东西?
一、可观测性Observability的概述
Observability是来自控制论的一个概念:
In control theory, observability is a measure for how well internal states of a system can be inferred by knowledge of its external outputs. The observability and controllability of a system are mathematical duals. The concept ofobservability was introduced by American-Hungarian scientist Rudolf E. Kalmanfor linear dynamic systems.
这里我们不做详细描述,大家感兴趣可以自行查询一下。
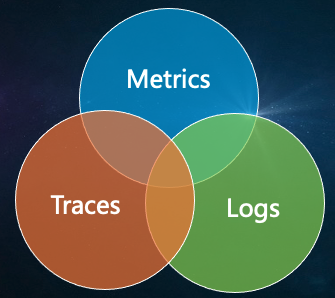
通常我们在IT领域看到的关于可观测性概念的介绍,都会提到它是Metrics, Traces以及Logs的结合,通常会以下图来呈现。
这里我找了一个Splunk的Demo,我们可以直观的感受一下,可观测性的实际效果是怎样的。
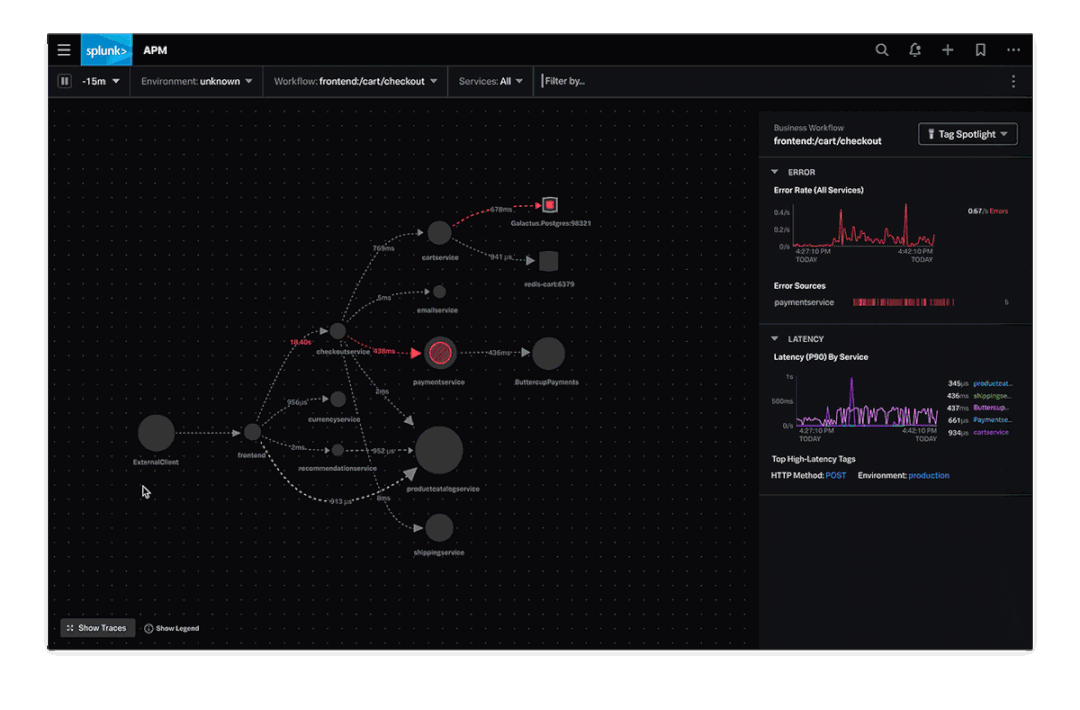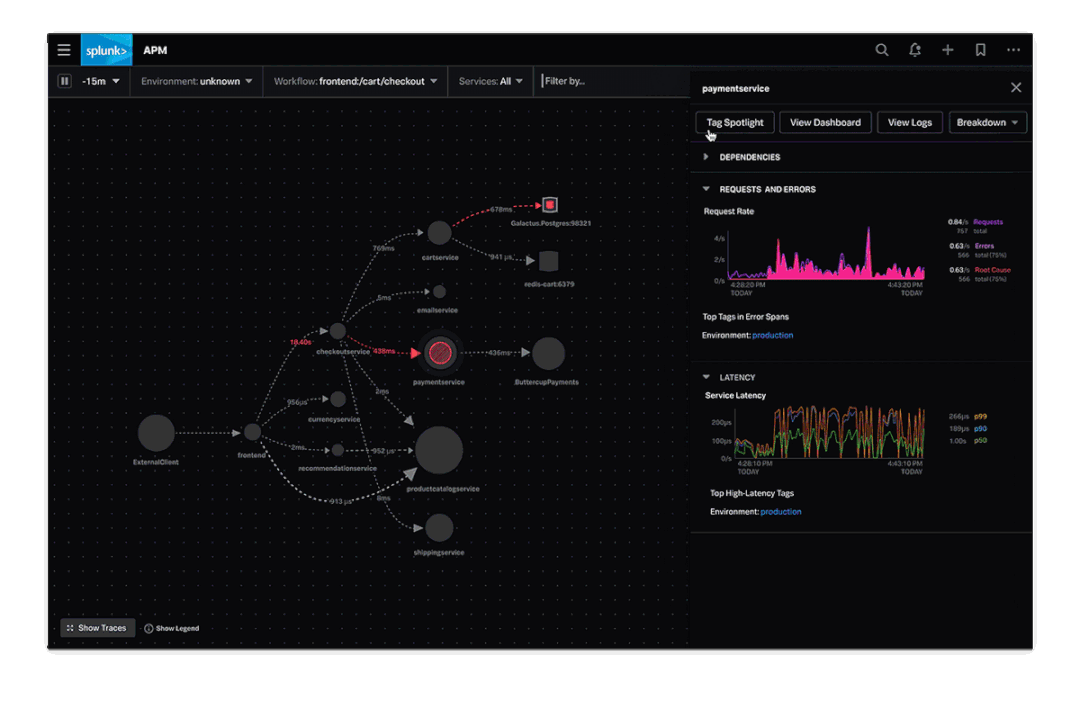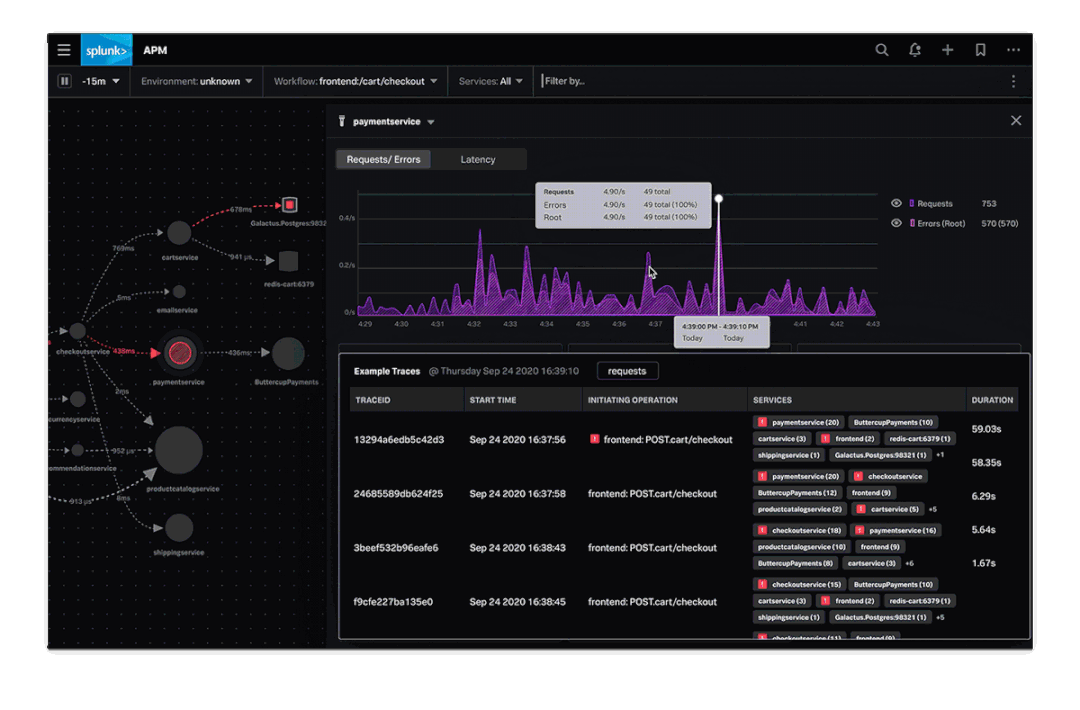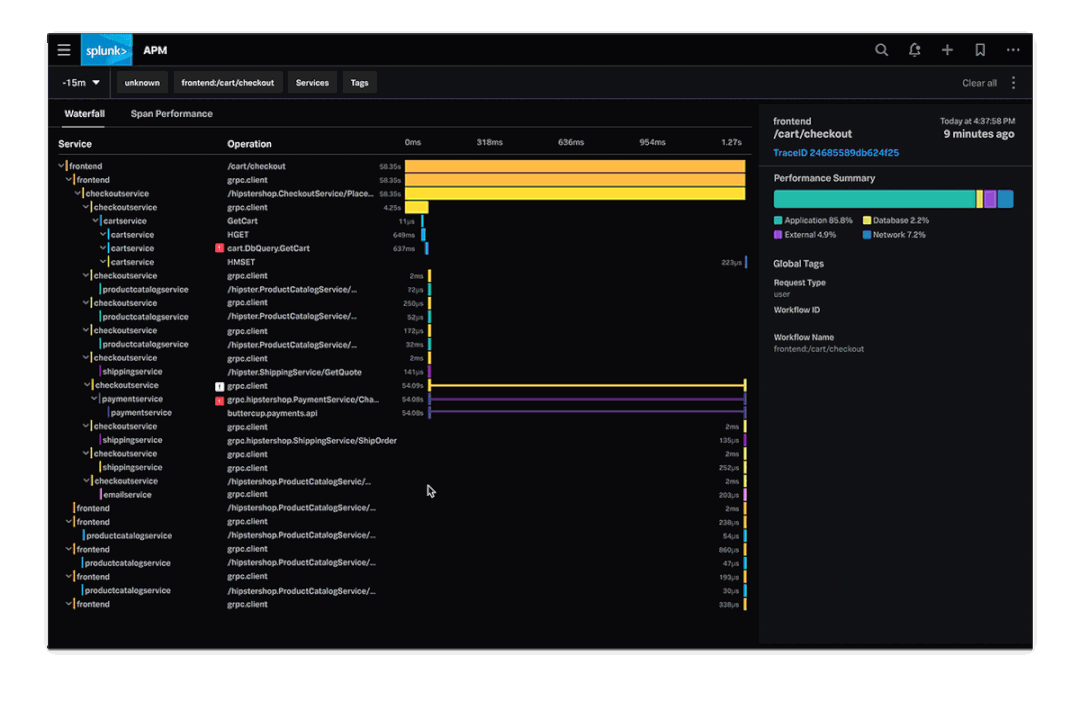
大家看完这个示意,对可观测性就有更直观的理解了,不做赘述。
但是这个Demo就只能作为Demo看一下,现实情况远比这个要复杂的多,原因我们后面会讲到。
不过,这里就有问题了,监控做了这么多年,Metric都是全的,日志系统也上了,Log一条都没拉下,调用链工具也引入了,Trace拓扑也能画出来,那上面这个效果是不是将三者结合一下就有了呢?
答案显而易见,是否定的。相反,现实情况下上述的效果并不容易达成,这里不仅仅是Metric、Trace和Log三者的技术结合在一起就OK,这只是外在的形,要想达成这个效果,其实更关键的是背后的神。
那这个神到底是什么,接下来我就换一个方式描述一下这个过程,把背后更为核心的内容呈现出来。
二、可观测性Observability的剖析
一图胜千言,我直接用一张图来描述,如下所示:

其实有了这张图,对Observability有一定理解的同学,应该就看的差不多了。
如果说Observability的内在的神是什么,总结下来就是3部分内容:
SRE方法论;
AIOps算法能力;
业务架构的理解,这里暗含着对领域知识的掌握。
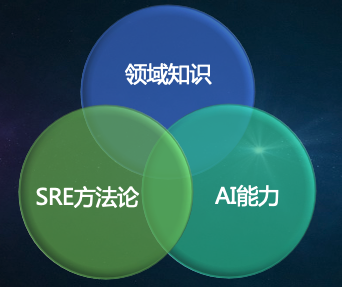
我们可以看到,这三部分的核心能力的掌握就不单纯是技术能力的体现了,这里要有非常深厚经验积累和时间,以及长时间对业务架构摸索和理解。
也只有在这三部分核心能力的指导下,像Metric、Trace和Log这样的技术手段才能发挥最大价值。
接下来我们再谈谈为什么这三个核心能力非常重要。
三、可观测性Observability的核心能力
这里面要用到SLO的方法,帮助我们识别关键Metrics,快速感知问题发生,主要是在Detect阶段。
我们知道复杂系统下,会包含网络、应用、分布式中间件、容器、主机、存储、数据库等等多层设备和部件,每个部件都会有自己的各类指标。
但是指标这么多,出问题同时告警,那就告警风暴了,一个是会造成关键信息淹没,再就是信息多了,告警就变成了“狼来了”,接收告警的人就麻木了。
这个时候就要设定SLO,而且SLO得是要分层设定,业务层面,要关注业务SLO,比如GMV、订单量、支付成功率等等。
系统层面就要关注系统SLO,比如订单接口成功率、时延和TPS等等,应用就要关注应用的SLO,缓存、消息、存储、数据库,以及底层的网络、容器、虚拟机、硬件主机要也要有自己的SLO。
SLO怎么设计,我不详述了,之前讲了很多,大家自行了解SRE的SLO机制就好了。
不过,即使做分层设定,出问题告警依然很多,我可以通过选定最上层的业务SLO来感知出问题了,提升响应速度,但是问题出在哪儿依然未知,这个时候在这种复杂系统中,就必须依赖AIOps的能力了。
AIOps领域,针对Metric、Trace和Log,都有专门的算法来应对支持,对应三类,比如针对Metric,就是KPI Anomaly Detection,针对Trace就是Tracing Anomaly Detection,针对Log就是Log Anomaly Detecion。
所以,AIOps是会始终贯穿整个Observability过程的,关于AIOps推荐看一下清华裴丹教授的文章和课程,会有更详细的分享。
如果SRE方法论和AIOps是落地Observability的两个核心,那对业务架构的理解,我对它的定位就是核心中的核心。
我们在架构领域经常听到的一句话就是,“脱离业务谈架构就是耍流氓”,其实也适用于Observability,适用于SRE和AIOps,脱离业务架构谈Observability就是耍流氓。
那对业务架构的理解为什么这么重要呢?我们看两个场景:
第一个,还是回到SLO设定上,当我们设定业务SLO时,我们是要根据业务类型和特点来的,或者换种说法,用户对我们业务的感知,是通过哪些指标来体现的?
首先,我们得能定义出来,比如电商可以是可以订单和支付维度来判定,对应会有下单成功率、下单量,支付成功率,支付笔数等等。
再进一步,正常这些指标都一个平滑的驼峰式曲线,等但是在做活动时,它可能就是一个个的尖峰和突刺,在节假日它的同环比会下降,遇到热点商品,可能会出现一段时间的波动,但是这些场景并不意味着系统出问题了,这种就要在AIOps的算法里识别出来。
那类似微信的IM又是什么指标和特点?社交软件微博又有什么不同?跨行业的电信运营商,以及银行、证券、保险等金融行业又各是什么特点。
这些都取决于对业务场景的深刻理解。
如果说第一个场景只要我懂业务就可以设定SLO,那如果我往深里看,那就不仅仅是对业务场景的理解了。
第二个,我们往业务架构深里看,我们都知道复杂分布式系统里,调用关系是异常复杂的,会呈现密布的网状调用关系。

当然现在有各类Trace工具能帮我们把调用拓扑呈现出来,也可以根据TraceID或业务ID单独看某次的调用链,确实方便了很多。
但是这么复杂的调用关系全部呈现出来,我到底应该怎么看?
答案是基本没法看!
所以这个时候就必须得事先规划出一条核心的业务链路,也就是我们常说的业务关键路径Critical Path,再进一步,关键路径上就会有核心应用,只有对照着这个路径去看,Observability才会有针对性和指导意义。
所以上面的那个Splunk的Demo,我们为什么说就是个Demo,因为现实中的调用关系要比Demo复杂N多倍,但是它想呈现的效果,就是针对Critical Path关键路径路来的。
关于Critical Path,核心应用,强弱依赖关系等等,在我的课程和之前的文章中都有,可以自行查阅。
所以讲到这里,我们可以看到,Observability从业务来讲,其实是需要事先定义出如下一条业务分析链路的:
业务SLO—Critical Path—核心应用SLO—核心分布式组件SLO—容器SLO—IAAS SLO
只有这个链路清晰了,AIOps才会发挥最大的优势,Observability的效果才会呈现出来。
一开始可以冗余,不那么清晰,但是必须得有,就像杭州到深圳,大家得知道杭州打车去机场,飞机去深圳机场,到了深圳再打车或地铁去目的地,这就是一条主线,这个都没有,基本就没法出门了。
所以,要做到这个程度,你就得懂业务、懂业务架构、懂技术架构、还要有一定的经验积累和沉淀,不然没法做判断。
上面讲了那么多,我放个示例,就不多讲了。
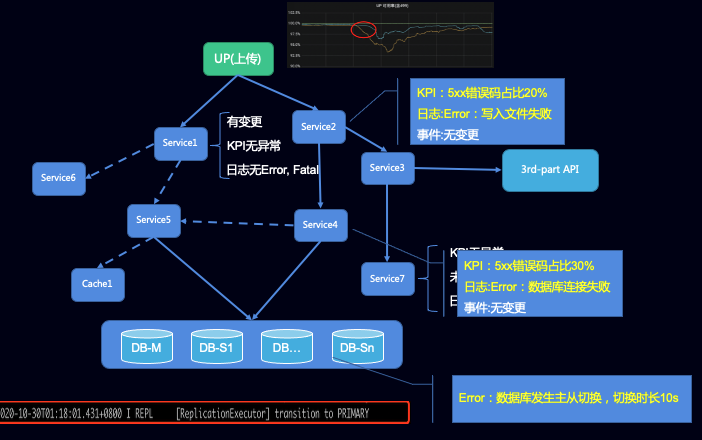
当然,可能会有人挑战我说,AIOps可以做到无监督学习,自行分析关键路径,不用这么麻烦还要人工分析。
当然,我相信未来有一天或许会做到,但是到目前为止,我觉得这还不现实,即使能分析出链路来,但是已然离不开架构师的梳理和确认。
这个状态,我觉得就跟现在的无人驾驶一样,绝大多数情况下,他可以自动巡航,但是关键时刻还是离不开人的判断和控制。而人的判断又是来自于驾驶经验、交通法规、伦理道德以及当时的精神面貌等很多因素。
从这个角度,自动巡航能力只是人的决策依据的一部分而已,只能做辅助,永远离不开也取代不了人的判断。
四、总结
当前看到的Observability的产品只有Metric、Trace和Log的技术描述,额外再加上部分AIOps的加持,但是这些只是形,没有神。
要想有神,最关键不能离开业务和场景,所以SRE方法论、领域知识(业务和架构)以及AIOps才是Observability的落地的关键所在。
而这三者之中,对业务场景及业务架构的理解程度,决定了SRE和AIOps可以发挥的效果如何,也最终决定了落地的效果。
再就是,为什么之前很少有人提Observability,这两天如此火热,我觉得还是技术应用发展到一定程度的结果,大家前几年都在分头搞监控、链路跟踪和日志系统,这两年搞差不多了,自然就会有更高的应用诉求。
所以,从技术上讲,并无新鲜的东西,关键还是得有更清晰的判断和思考。
作者丨Cheng哥
来源丨公众号:成哥的世界(ID:forrest_thinking)
dbaplus社群欢迎广大技术人员投稿,投稿邮箱:editor@dbaplus.cn








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721