
一、建设背景和问题
随着分布式云原生、容器化、微服务、大数据技术的成熟和普及,生产系统架构朝着微服务、容器化方向改造,这给监控运维带来如下问题和挑战:
出现大量分布式新技术并缺乏监控标准:如K8s里的容器、pod、deployment、微服务的API网关、熔断、服务治理等,亟待梳理这类分布式新技术的监控标准。
环境的动态性变强:分布式对象动态可变,例如容器和pod创建、销毁、迁移,传统监控工具无法处理云环境下对象的动态发现和更新,无法提前配置。
监控数据量急剧增多:监控指标数量随着容器规模增长呈爆炸式增长,海量监控对象的高频采集和处理成为一个新的挑战。
业务架构趋于复杂:云原生应用架构下,原有单体系统变成了众多微服务的协作,单个用户请求会经过多个微服务应用,形成复杂的调用链路,这给问题排查和定位带来了困难和挑战。
分布式系统的可观测性分为metrics(指标)、链路和日志。指标监控基于基础指标数据(例如CPU、内存、响应时间,调用量等)进行监控,是较为传统和应用范围最广的监控手段;链路追踪解决服务间的复杂调用和性能耗时分析问题;日志监控对系统运行过程数据:如关键统计信息,警告、错误等进行监控,这三种手段共同配合完成分布式系统的全面监控。链路监控和日志监控是分布式日志中心的建设范畴,本文主要针对分布式系统的指标监控展开,下文所提到的分布式监控仅限于分布式指标监控范畴。
当前统一监控平台使用的传统监控工具比如Zabbix、ITM、Nagios难以实现在容器云及其他分布式动态环境下进行监控,因此亟待采用一种新技术解决分布式系统监控问题。
开展分布式监控,重点需要解决如下几个问题:
分布式监控标准梳理和制定;
分布式系统监控工具选型;
分布式监控管理平台设计和开发。维护和管理分布式监控标准,对分布式监控工具进行驱动管理。
下面我们会逐一介绍。
二、分布式标准制定
在分布式监控标准梳理过程中,我们采用如下四个原则,产出如下图所示的分布式指标体系:
分层分类:监控指标进行分层、分类,由各专业团队再去有重点的丰富监控标准。
监控标准统一:无论传统平台还是容器云平台,对于同一个类对象的监控标准要统一,确保指标全覆盖。
同类对标:对于相同类型的监控对象,需对标原有相似类型的监控对象。如新引入的开源中间件需对标传统的WebLogic监控标准。
持续优化:敏捷迭代、持续补充和完善原有监控规范。

分布式指标体系层级图
具体每个层级,每个组件的监控指标,由于篇幅原因,在此不再展开。
三、平台概述
分布式监控平台是统一监控平台的子系统,负责分布式和云原生系统的监控。平台主要分为四层:监控工具层、存储层、处理层和管理平台层,如下图所示:
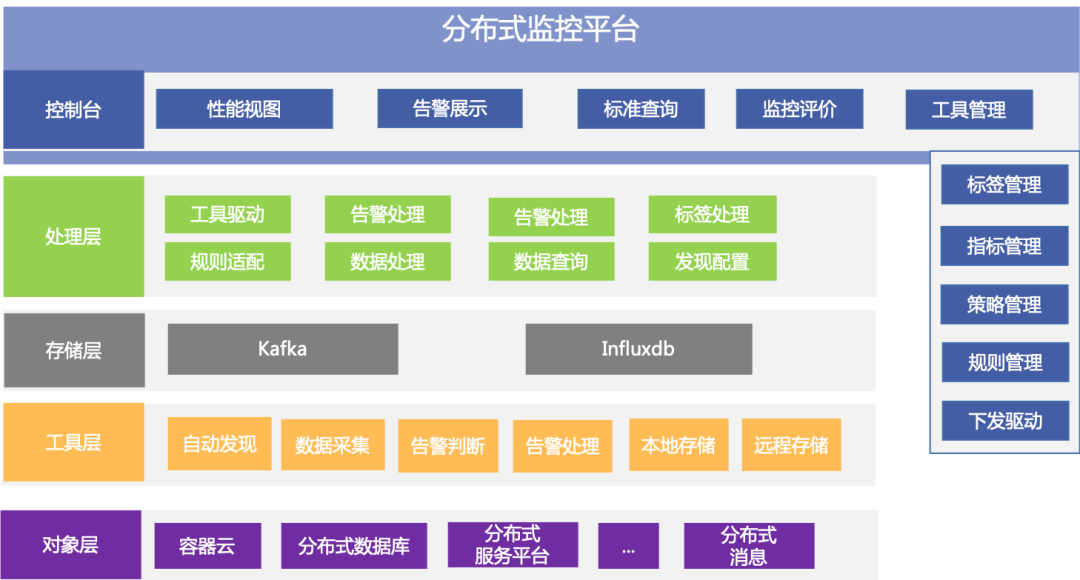
分布式监控平台逻辑架构图
监控工具层主要是由Prometheus工具组成,接收处理层的驱动指令,进行监控对象的自动发现、数据采集、告警判断、性能数据进行本地存储的同时,实时送入存储层的Kafka,为后继的数据分析提供数据源。
处理层负责连接监控管理层和工具层,主要包括工具驱动、实时数据处理、告警处理、Prometheus本地数据实时查询四大功能模块。
工具管理和驱动:将监控管理层的指令转换成Prometheus Operator接口API,进行相应Prometheus工具的驱动,如自动发现配置、采集指标配置、采集频率、告警配置(指标、阈值、告警持续时间),告警等级,性能数据存储配置等。
实时数据处理:对性能数据进行实时时间戳转换,异常清洗,数据格式化和标准化处理,InfluxDB存储格式适配等,最后送入存储层的InfluxDB进行历史存储,供后继的监控视图展示和问题定位查询使用。
告警处理:通过搭建AlertManager集群和自研的告警处理模块,二者互相配合,实现告警的统一集中处理。
Prometheus本地数据实时查询:接收管理平台请求,获取相应Prometheus本地性能数据,按需提取字段,采样点稀释,数据聚合等。
管理平台层由接口层、指标&指标实现管理、策略管理、规则管理、标签管理、工具管理、驱动管理、监控评价、监控视图展示、告警管理组成,其中接口层提供统一门户实现监控信息的全貌展示,提供便捷的管理支持与任务派发。
四、平台关键技术点
调研当前业界众多的开源监控系统例如Prometheus、OpenFalcon和夜莺等,最终选型Prometheus,原因是:
原生支持K8s监控:具有k8s对象服务和分布式系统对象的发现能力,而且k8核心组件和很多都提供了Prometheus采集接口。
强大的性能:go语言开发,v3版本支持每秒千万级的指标采集和存储,可以满足一定规模下k8s集群的监控需求。
良好的查询能力:PromQL提供大量的数据计算函数,可通过PromQL查询所需要的聚合数据。
不依赖外部存储:自带高性能本地时序数据库,实现采集数据的本地存储,同时可对接第三方存储实现历史数据存储。
当然Prometheus也有他的不足,那就是:
Prometheus不支持集群部署,单机处理能力有限,缺乏高可用和扩展能力。
Prometheus本地存储容量有限,不能满足较长时间范围的历史数据存储和查询。
缺乏平台化和自服务管理能力,不支持通过API进行监控配置(尤其是管理监控目标和管理警报规则),也没有多实例管理手段。
我们对Prometheus的不足做了一些扩展与整合:
缺乏高可用问题:在分布式监控集群中,每个Prometheus监控实例均采用主备方式部署,同一监控对象同时有两个Prometheus进行监控,任意一个Prometheus实例失效都不会影响到监控系统的整体功能。
不支持集群,单机处理能力有限问题:设计并实现基于标签的可扩展机制,支持K8s和独立部署下动态新增或者删减Prometheus工具实例,采集Target动态调整和分配,实现监控能力可扩展。支持功能分区和水平扩展两种方式,所谓功能分区就是不同的Prometheus负责监控不同的对象,比如Prometheus A负责监控K8s组件,Prometheus B负责监控容器云上部署的应用;水平扩展就是极端情况下,当个采集任务的Target数也变得非常巨大,这时通过功能分区无法有效处理,可进行水平分区,将同一任务的不同实例的采集任务划分到不同的Prometheus。
本地存储能力有限问题:把Prometheus性能数据实时写入Kafka,再通过Flink流式计算实时消费到InfluxDB,利用InfluxDB的分布式可扩展能力,解决了单Prometheus本地存储的限制问题。
缺乏平台化和自服务管理能力:引入Prometheus Operator对Prometheus、监控规则、监控对象、AlertManager等K8s监控资源进行API式管理。开发分布式监控管理平台,提供图形化的监控标准配置管理界面,进行自服务化、自动化下发,具体会在下面章节进行详细介绍。
建立标准化的分布式监控标准管理模型。基于标签在K8s和Prometheus中的重要作用(K8s基于标签分类管理资源对象;PromQL基于标签做数据聚合;Prometheus Operator基于标签匹配监控对象和监控规则),因此以标签为核心,构建了一套分布式管理模型,具体包括监控标签、监控工具、指标实现、指标、监控策略、监控规则,如下图所示。通过在分布式监控平台落地实现了同类对象的标准化监控。
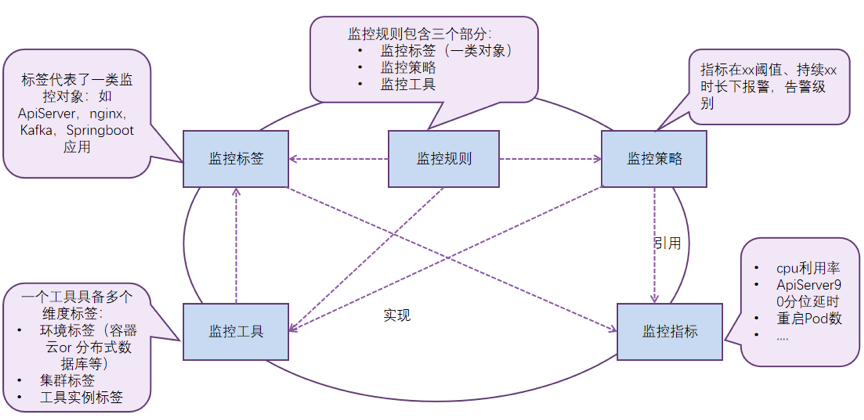
分布式监控标准模型图
打通运维和研发壁垒,实现代码即监控。监控管理员提前内置下发监控规则,研发投产时,只需要做两点就可实现监控:
自研应用提供指标采集接口,公共开源组件以sidecar模式部署相应exporter暴露采集接口;
投产Service yml配置上具体对象类型标签信息(nginx、tomcat、Kafka、Java应用、go应用、Redis等)。
驱动模块根据Service yml驱动Prometheus实现投产对象的配置和发现,并基于预置的规则进行监控,示例如下图所示:

标准化和自服务化配置下发监控规则过程示例图
集中告警处理集群搭建:搭建AlertManager告警处理集群,实现告警的集中统一管理。通过AlertManager的分组、抑制、静默实现告警的初步处理,但是AlertManager现有功能不满足如下实际生产需求:
告警持续发生2小时未恢复,再次产生一条更高级别的告警(告警升级);
告警转换成syslog对接统一监控平台;
相同告警持续发生半小时内只产生一条告警(告警压缩);
针对集群、应用系统维度的总结性告警;
基于特定场景的根因定位,如Master节点宕机导致其上K8s核心组件不可用,产生一条master节点宕机根因告警(告警根因定位)。
告警二次处理模块:基于go语言自研高性能告警处理模块,提供webhook接口供AlertManger调用。接口实现的功能有:告警字段丰富、告警压缩、告警升级、告警总结、告警根因提示、告警转syslog发送统一监控平台。
Adapter改造:基于开源Prometheus Kafka Adapter进行改造,确保海量性能数据实时写入Kafka,供后继的数据分析和数据价值利用,比如动态基线计算和异常检测等。
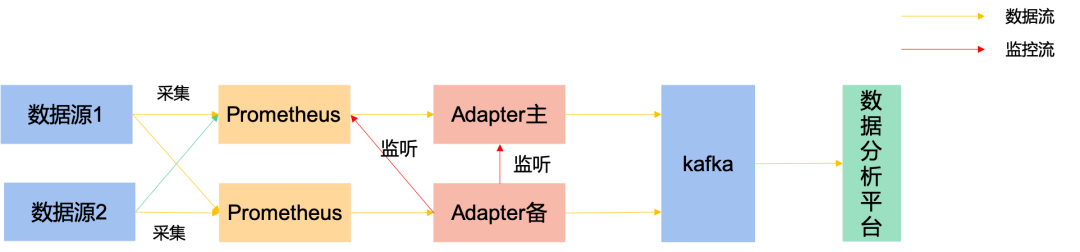
Adapter工作示意图
适配当前Kafka SASL/PLAINTEXT认证模式,对采集数据进行压缩以节约带宽,对Kafka写入性能参数调优以应对大并发数据量的实时写入。
设计Adapter主备模式,避免数据重复。如果主Adapter健康检查能通过且主Adapter对应的Prometheus正常运行,则利用主Adapter传递数据送入Kafka,备Adapter暂停工作;如果主Adapter或者主Adapter对应的Prometheus健康检查不通过,则使用备用Adapter进行传递数据,并通知管理人员Prometheus和主Adapter故障。
流处理模块:基于Flink自研流处理模块,确保海量性能数据的实时处理和入库。流处理的内容包括:时间戳处理(Prometheus默认采用UTC时间)、异常数据清洗、数据格式化和标准化处理,InfluxDB存储格式适配。

告警和性能数据集中处理架构图
五、总结
在平台建设中,借鉴同业及互联网企业容器云K8s相关建设经验,基于开源技术自主研发,构建了立体化、集中化、平台化、标准化的分布式监控平台,系统具有如下特点:
自动发现:动态环境自动发现并监控;
高性能:海量对象秒级采集处理,日均处理T级数据,并可弹性扩展;
自动化&自服务化:避免针对具体监控对象逐个手工配置,灵活性差,容易误操作和漏操作,维护成本较高的问题;
研发运维打通:监控迁移到设计开发阶段,研发暴露指标&自助配置投产yml和策略即可实现分布式监控;
自主可控:基于开源Prometheus技术自主研发。
目前分布式监控平台已于11月初在G行投产,实现G行容器云生产集群的全面监控,实现海量对象的秒级处理,日均处理T级数据,告警准确率和召回率均为100%,系统运行稳定,监控效果符合预期。
六、后继工作展望
平台一期建设实现了容器云及云上应用和服务的监控,接下来会扩大分布式监控的纳管范围,实现分布式数据库、全栈云管理平台、分布式消息等的监控纳管。
监控自服务化能力建设,封装有一些自服务监控场景:比如监控的上下线、监控规则修改、个性化监控配置等。
监控评价功能,以量化的方式展示分布式系统的监控覆盖率和标准化率,以评促改,形成闭环。
分布式监控工具自身优化,比如Prometheus负载的自动平衡,基于一些预警数据,智能扩缩Prometheus的实例个数,自动分配采集对象,达到最佳的监控能力。
与自动化运维操作平台进行联动,实现一些场景的自动化处置。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721