
伴随着G行服务上云、业务容器化,应用架构已经从原来的单体服务,步入云原生生态,多实例、微服务、分布式,对于监控系统的要求越来越复杂、越苛刻,既要兼容现有主机监控,又要融合云平台监控、业务监控等。本文重点偏重于Prometheus的操作、实战以及在G行的改进,对于一些原理性的技术知识,请以官方文档为主。
Prometheus作为一款面向云原生应用程序的开源监控工具,其监控场景包括:业务监控、性能监控、容器监控、微服务监控、应用监控、其他监控(如:URL监控)等;
Zabbix是一个老牌高度集成的网络监控解决方案,可以提供企业级的开源分布式监控解决方案,其监控场景包括:硬件监控、系统监控、网络监控、中间件监控(如:Oracle)、其他监控(如:URL监控、端口监控)等;
Open-falcon是一款相对新的互联网监控系统,有小米开源,其监控场景包括:服务器、操作系统、中间件、应用等进行全面的监控。
下面是他们主要功能点对比:

图1-1 经典监控系统指标类比
Prometheus因其在时间序列数据的记录、多维度的数据收集和数据筛选查询语言上表现优异,而且它能更容易结合其他监控系统,支持云原生。
对于监控系统而言,常见的监控维度无外乎资源监控和应用监控。资源监控是指系统的载体,比如主机、应用的资源使用统计等,在k8s场景下,就是各种资源利用率,比如节点的、集群的、Pod的等。应用监控指的是对于应用内部指标的监控,例如我们会将应用访问量、响应时间等进行实时统计,并通过端口进行暴露或者推送来实现应用业务级别的监控与告警。下面我们罗列了一些在Kubernetes下的监控对象及其实现方式:
核心组件
Kubernetes集群中内置的组件,包括apiserver、controller-manager、etcd等。
静态物理资源
主要指Node节点的资源状态、内核事件等。
动态伸缩资源
主要指Kubernetes中抽象工作负载的实体,例如Container、Deployment、Service、Pod等。
自定义应用监控
主要指需要应用内部需要定制化的监控数据以及监控指标,例如应用的JMX、响应时间、延时等。
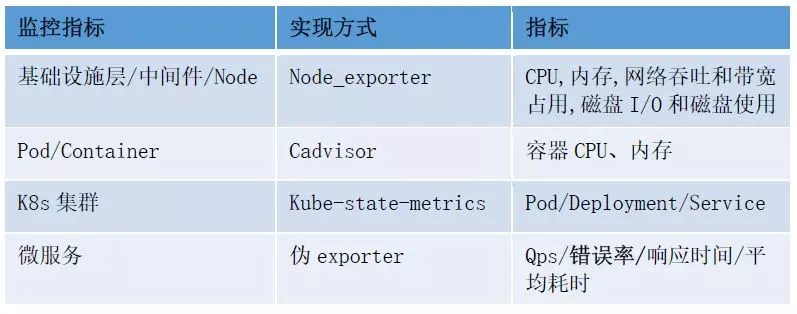
图2-1 k8s下的监控对象及实现方式
下面以G行容器云下的Prometheus Operator为例,概述一下Prometheus及其组件的部署关系。

图2-2 Prometheus Operator下的服务发现
简单地讲,Prometheus Operator的作用通过CRD的方式将需要动态监听的实体进行定义,并通过监听Apiserver中实体的变化,进一步实现Prometheus中动态资源更新配置与报警规则。用更通俗的话讲就是:通过ServiceMonitor实现对service的数据获取。
ServiceMonitor自动识别带有某些label的service,Prometheus通过Prometheus Operator实现从这些service中获取数据。同时,ServiceMonitor也是由Prometheus通过label自动发现的。
通过Prometheus Operator的CRD,可以让Prometheus的监控对象自动生成,无需额外配置监控任务,就能实现动态实体的监控。
下图展示了其中的一些要点,后面会分开描述:

图2-3 CRD下的服务发现概略图
1)Service
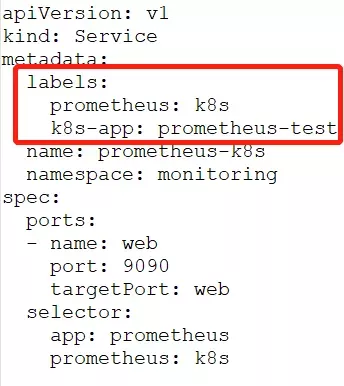
图 2-4 带有k8s-app标签的Service片段
2)ServiceMonitor
通过selector匹配service,通过标签选择endpoints,实现动态发现服务。

图2-5 带有k8s-app标签选择器的ServiceMonitor片段
3)Prometheus
通过matchLabels匹配ServiceMonitor的标签k8s-app:prometheus-test, 实现服务或者监控的添加。

图2-6 带有k8s-app ServiceMonitor选择器的Prometheus片段
通过ruleSelector(匹配标签prometheus:k8s,role:alert-rules)选择PrometheusRule里面的labels prometheus: k8s,role:alert-rules,实现规则的动态增删改。
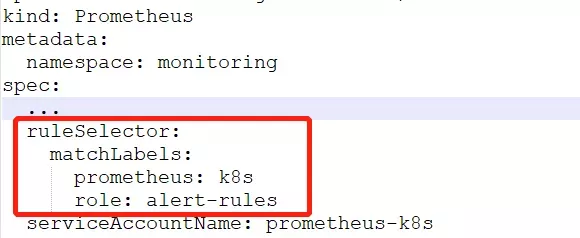
图2-7 带有Prometheus和role的规则选择器的Prometheus片段
基于上面的架构配置,前端团队能够创建新的ServiceMonitor和Service,以及规则的动态修改,从而允许对Prometheus进行动态重新配置。
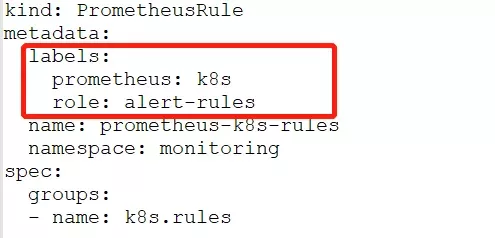
图2-8 带有prometheus和role标签的PrometheusRule片段
通过ConfigMap生成AlertManager需要的yml文件:

图2-9 配置文件生成器ConfigMap片段
基于config.yml文件,配置Alertmanager的启动yml。
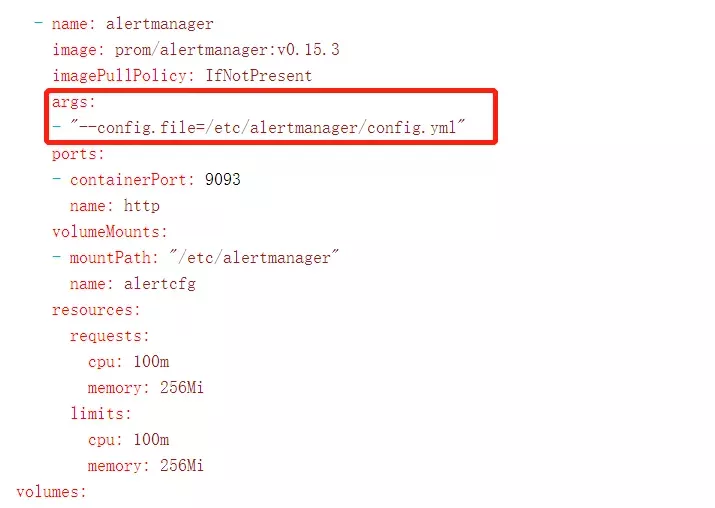
图2-10 基于配置文件的AlertManager片段
至此,Alertmanager通过yml文件建立起来,之后通过刷新PrometheusRule文件中的配置规则,Prometheus实时动态探测监控指标,在超出阈值情况下,按预设规则发出告警。
对于Prometheus而言,是一个拉取模式的采集系统,而拉取式的系统通常会有一个通病,就是数据提供方的数据量级问题。推送数据的时候,我们可以根据数据的量级分批、分次进行推送。而拉取通常是全量数据的同步,就会受限网络限制,延时大,数据堵塞、中断等。
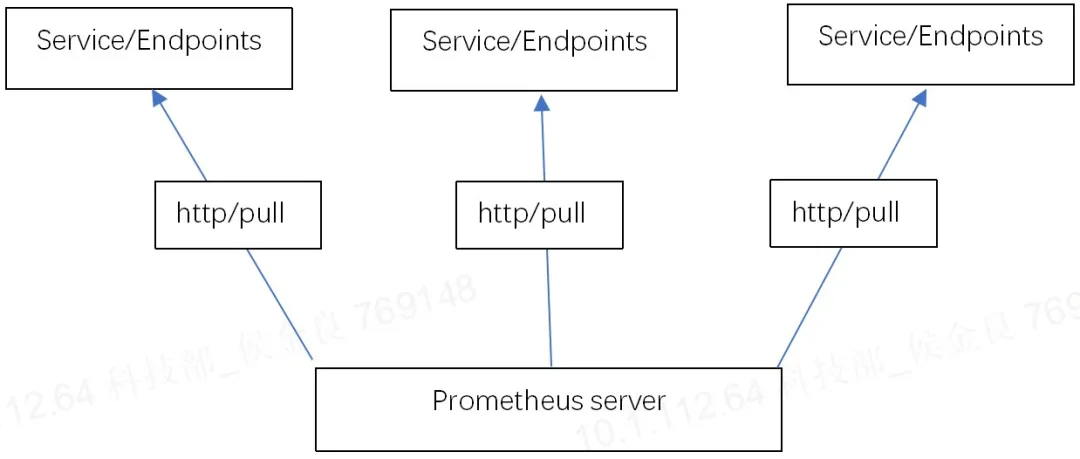
图3-1 原生Prometheus采集指标数据的模式
Prometheus自身的存储数据格式性能还是很低下的。这会导致在集群量级比较大的情况下,Prometheus的CPU、内存、磁盘、网络都存在较高的利用率。另外,Prometheus本身是单点架构,虽然社区中已经有集群模式,但是依然不够成熟。
2、监控指标不准确
由于Kubelet的数据指标不是实时的,而Prometheus的数据采集会丢失时间戳,这会导致非常异常的利用率曲线。同时,由于Prometheus有一定的延时,对于实时性要求较高的系统,是非常不利的。
容器云中,为了实现自定义配置监控,G行通过复制服务Service的yml文件,添加自定义的label标签,生成冗余Service,然后建立ServiceMonitor,同时将Selector内容指定为相应冗余Service的标签,通过ServiceMonitor的关联,将Service映射的endpoints绑定到Prometheus进而动态监控起来。动态关联,伸缩有度,通过标签管理和配置,自适应实现容器云下的分布式监控。
2、全闭环监控
随着服务快速上下线,如何做到监控自适应,助力监控系统全闭环管理,及时反馈出服务监控健康状态,给出监控评价,是监控有效性和监控水平的重要体现。G行通过监控布控率、监控可达比以及监控标准化率等,实现监控评价,实时把控服务的动态发展。
1)监控布控率
由前面章节可知,通过容器云平台查询,获取当前接入的应用Service;同时获取监控复制生成的Service,两者Service个数进行比较,可以得到接入服务的监控布控率。
2)监控可达比
通过k8s查询,基于label标签,获取被复制Service的Endpoints,进一步得到其下的Targets;由监控布控率可知,被复制Service其下有多少Targets,将两者Targets进行比较,获取监控可达比。
3)监控标准率
格式化各个监控对象及中间件的监控指标,并设定运维标准阈值,在设置监控规则时,通过更改不更改阈值、增加删减指标等,获取对象及中间件的标准化率。
基于监控覆盖度、监控可达比率以及监控标准化率等量化指标,可视化度量监控的布控质量,能够及时产生反馈信息并持续追踪,持续优化监控系统。
3、存储
1)远程转存Remote Write
在多集群或者大规模k8s下,将所有的Prometheus数据,通过remote write,远程写入Influxdb集群,从而实现数据汇总,进而实现全局视图。
2)实现Prometheus Rpc 服务器的功能
在Prometheus中,集成rpc server的功能,统一所有k8s外的Prometheus,然后将集群内部的Prometheus数据,在gateway处基于metric hash进入外部Prometheus,在查询的时候,将metric放入查询url上,然后在gateway处找到通过metric hash之后的Prometheus,进而形成“近似”全局视图。
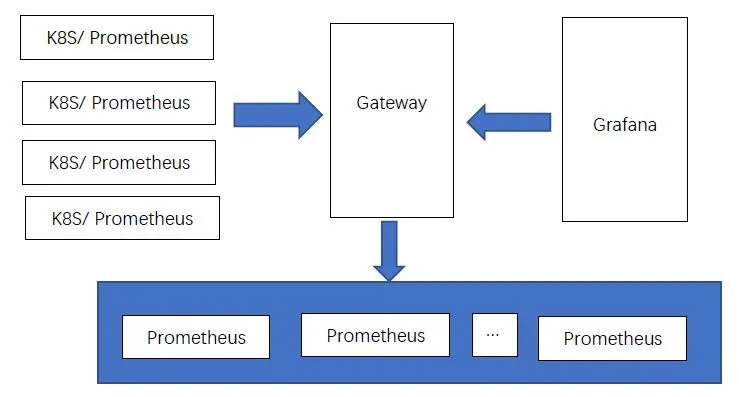
图4-1 自定义模式下的Prometheus集群
1)告警外移
在Prometheus之外,编码Service,将夹带复杂逻辑的告警规则拉入,实时查询外置Prometheus集群,形成告警数据。
由于Prometheus需要导出数据至远端存储,我们可以在中间加入Kafka,在数据到达Kafka之后,形成并列消费,通过Flink流处理,将简单match的告警规则拉入Flink端,可以实现实时告警。

图4-2 集成大数据的自定义AlertManager
2)统一Open-falcon、Zabbix等监控数据
伴随大数据以及数据中台的发展趋势,可以将其他监控系统,比如Open-falcon、Zabbix,采集的数据,通过工具集,汇总到Kafka,对其进行业务处理、格式化透传、告警等。
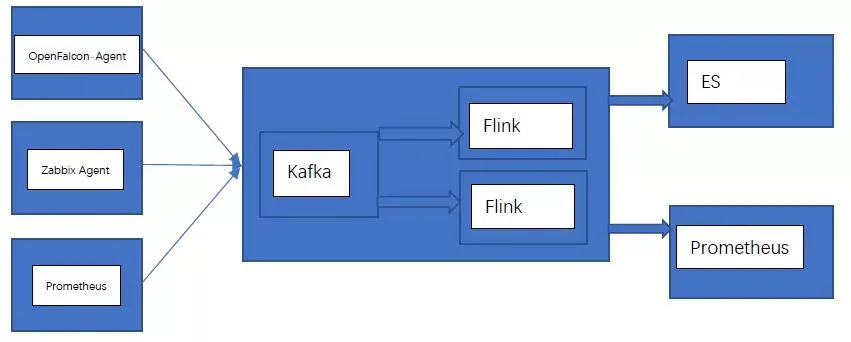
图4-3 统一监控运行数据
通过分布式监控平台的建设,G行的监控服务在故障发现、快速定位、故障自愈等方面,得到了更健康快速发展:
通过监控标准的制定、评价的闭环,使其监控的服务及资源能够健康有序运转,更进一步促进业务的规范和合规;
将open-tracing标准引入微服务的开发,将平台及业务运行日志引入分布式监控,汇总并聚合,从资源、网络等多维度实现全局的业务视图链路,准确掌握生产一线应用部署情况,并进行优化;快速定位代码性能问题,协助开发人员优化代码,缩短系统上线稳定期等。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721