
团队介绍
西风带,隶属于华夏银行信息科技部分布式系统研究与应用小组,作为华夏银行在分布式技术领域的信息科技专业团队,本着研究、引进、吸收、落地的新技术转化原则,一直致力于分布式技术的研究与落地实践,跟进主流技术演进趋势并结合银行信息系统现状,提出系统分布式架构设计及技术应用解决方案,为银行信息系统架构转型赋能。
一、问题场景
InfluxDB作为时序数据库被广泛应用于监控领域的数据持久化工作,在数据持久化的运行过程中,往往会遇到各种各样的错误,MAX-VALUE-PER-TAG是在InfluxDB写入时为避免OOM问题所引发的保护性错误。
本文通过Prometheus远程写入InfluxDB进行业务系统监控数据持久化的视角,来介绍一下max-value-per-tag错误(如下图)产生的原因及解决措施,以期能为大家在使用InfluxDB时提供一些经验和参考。

二、成因分析
在Prometheus远程写入InfluxDB的场景中,导致此问题产生的主要原因是由于通过Prometheus远程写入InfluxDB的监控指标中包含了多个具有较高离散度的标签数据所引起。举例如下:
设置Exporter暴露的监控指标,使监控指标中包含具有高离散度的标签要素,此类标签不用多,一两个即可,例如:全局系统跟踪号(每个指标自增1)、交易时间(每个指标实时抓取系统时间)等;
设置完监控指标后,我们通过Prometheus将采集的指标持续不断的写入InfluxDB。(注:Prometheus会使用snappy压缩算法将含有预先定义的如下数据结构信息流使用protobuf协议传输至InfluxDB);
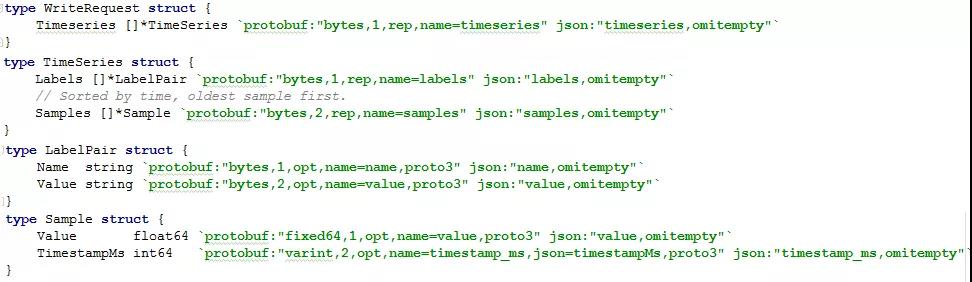
InfluxDB收到数据流后会将监控数据指标名作为表名(measurement)、所有标签作为索引字段(tags)、样本值作为常规字段(field)进行解析和存储:


在存储时,InfluxDB会将由标签组成的索引字段(tags)默认保存在内存中,目的是为了避免索引字段取值过多而导致程序申请内存过大而引起的操作系统运行异常,即OOM问题;
为了避免OOM问题的发生,InfluxDB提供了max-values-per-tag保护参数,该参数的初始阈值为100000,即当某一索引字段(tags)取值数量超过该阈值时,会引发该条时序记录写入失败:


综上所述,当Prometheus持续写入数据至InfluxDB一段时间后,由这些高离散度的标签形成的索引字段(tags)数量便会达到max-values-per-tag阈值设定限制,从而导致后续监控数据写入失败。
三、解决方案
1)方案简述
由上一章节描述可知,InfluxDB将索引数据默认保存在内存中主要是为了解决OOM问题,但如果我们的使用场景只是为了做监控数据持久化,即基本上只会做写入操作,是否可以将这些索引数据保存在磁盘中呢?
InfluxDB提供了通过配置参数(如下图所示),将索引数据由内存转移到磁盘进行保存的功能。索引保存于磁盘虽然读取速度不如存储在内存快,但理论上可以解决max-values-per-tag问题。

2)测试验证
①在InfluxDB配置文件中进行index-version=tsi1的配置,配置完成后,/var/lib/influxdb/data的数据库实例路径中将创建index路径集和索引落盘所需的相关数据文件;
②设置具有类似全局系统跟踪号、交易时间等高离散度标签的监控指标,通过Pushgateway进行监控指标推送,模拟平均100TPS交易场景下的InfluxDB数据储存情况;
③持续运行12小时后,InfluxDB运行正常,所有监控指标成功写入,但通过对/var/lib/influxdb/data的数据库实例路径容量进行观察,发现平均每小时新增磁盘使用空间约300M(index增长50M,tsm增长120M,_series增长130M)。由此测算得知,在平均100TPS的交易场景下保存监控数据所需磁盘空间如下:

3)测试结论
虽然通过修改配置参数,将索引数据由内存转到磁盘写入,解决了max-value-per-tag的警告问题,但对磁盘空间消耗过大,造成磁盘空间消耗过大的原因如下:
InfluxDB对同一监控指标的时序数据进行索引数据存储维护时,会对索引取值(集合)进行笛卡尔乘积处理;
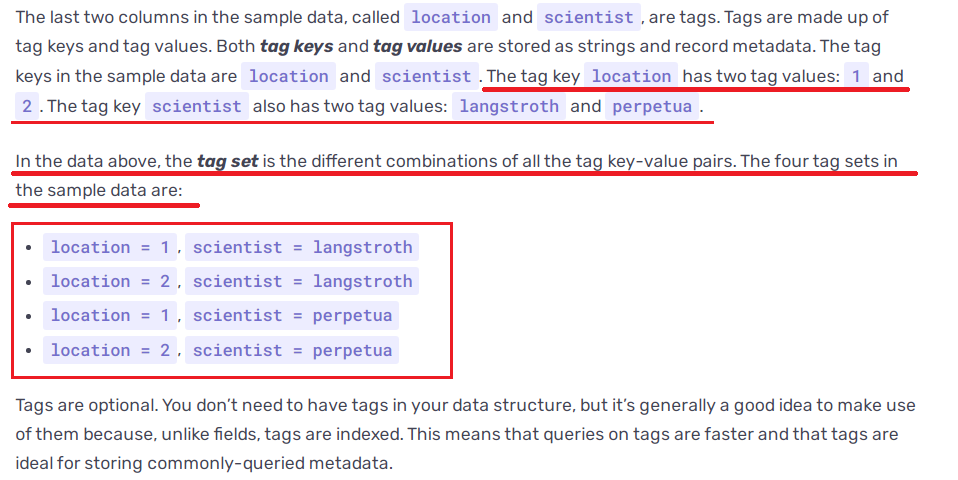
监控指标中的高离散度标签形成的索引字段使得上述笛卡尔乘积变得异常庞大。
由此可以看出,InfluxDB更偏向于高效读写大数量时序变化数据,索引字段作为其快速数据查询的基础,一般是由不随时间变化的信息要素组成,而不是具体的数据信息,所以,用于标识监控指标唯一性的高离散度标签信息不适合作为InfluxDB的索引字段。
1)方案简述
在监控系统中,高离散度的标签往往是作为监控告警的辅助信息使用,而不会作为监控维度的分析,所以将这些标签放入索引的意义不大。第二种方案就是通过对InfluxDB进行客户化,将这些高离散度的标签作为常规字段进行存储。
2)测试验证
①对InfluxDB进行客户化开发,在接收到Prometheus的远程写入请求时先对监控指标数据进行预处理,仅将指标名保留为索引字段,而将高离散度的标签去除索引属性转变为常规字段进行存储,代码修改样例如下:


②InfluxDB客户化改造后,模拟解决方案1中测试验证的第2步操作,经过12小时的测试验证,InfluxDB运行正常,未出现max-value-per-tag的警告问题,且磁盘空间只增长了几十M,满足了不超过索引上限和磁盘空间占用较小的需求。
③但是在验证数据正确性时发现:对于同一批次抓取的多条监控指标具有相同的时间戳,原本应该基于时间戳标签插入多条监控数据变成了基于同一批次时间戳的更新操作,失去了使用时间戳标签区别监控指标的意义。
3)测试结论
由于Prometheus周期性抓取指标的特性,对于同一批次抓取的多条监控指标具有相同的批次时间戳,在远程写入时被InfluxDB解析成了具有同一时间戳、同一索引(指标名)的重复时序数据,原本应该进行多次数据插入的动作变成了未被预期的针对同一条时序数据的多次更新操作,造成了远程数据集写入缺失,从而此方案虽然解决了max-value-per-tag的警告问题和磁盘存储空间的问题,但无法满足监控数据持久性要求。
1)方案简述
通过前2个方案的测试结论可知,既然InfluxDB不适合存储具有高离散度标签的时序数据,那么我们就将高离散度标签的时序数据在写入InfluxDB前进行屏蔽处理。
2)测试验证
①通过修改Prometheus的remote_write配置段,将具有高离散度标签的监控指标进行屏蔽设定,去除具有高离散度标签的监控指标向InfluxDB的写入请求。

②配置完成后,模拟解决方案1中测试验证的第2步操作,经过12小时的测试验证,InfluxDB运行正常,未出现max-value-per-tag的警告问题,磁盘和系统资源占用情况适中。
3)测试结论
本方案其实是对InfluxDB不适合存储具有高离散度标签的时序数据结论的一个论证,通过技术手段规避了max-value-per-tag问题的产生,保证了非高离散度标签的监控数据持久化及InfluxDB的稳定运行。
四、总结
通过以上3个解决方案的过程描述,造成max-value-per-tag问题的主要原因是由于监控指标中存在着高离散度的标签,由于InfluxDB不适合存储具有高离散度标签的时序数据,在实际开发过程中,遇到高离散度的标签时建议将其只作为监控指标在监控系统中进行临时性存储,而无需将其在InfluxDB中进行持久化存储(注:Prometheus可以通过配置文件的配置在本地存储一定天数的监控指标,默认15天)。
通过对max-value-per-tag问题的分析,我们可以更深入的了解到指标监控及时序存储技术在监控场景中也不是万能的,它比较适用于针对固定标签的指标,并基于时间变化对其进行监控及趋势预测的场景,对于满足不了的场景,建议大家尝试一下日志监控或链路追踪,通过不同的角度去寻找最优的解决方案。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721