
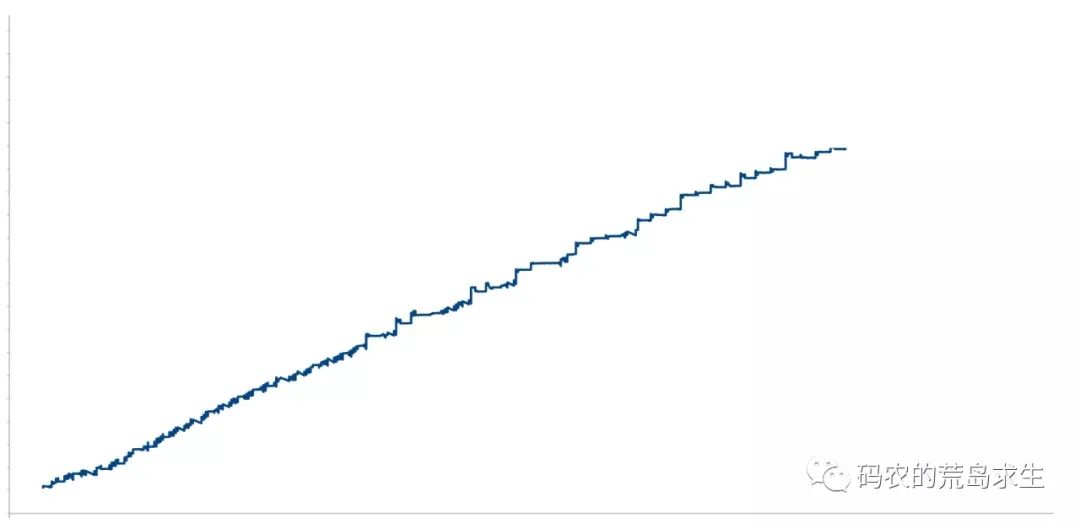
很显然该服务存在内存泄漏问题,赶紧排查问题。
问题排查
首先确定内存泄漏问题出现的时间,发现在该时间点的上线有两次代码提交,其中一个就是我的。于是立刻排查这两次代码的改动,确定了另一个同事的代码不可能会有内存问题后(因为另一个同事的上线仅仅修改了配置),我知道肯定是自己的代码出现了问题。
确定了问题所在后赶紧把自己的代码回滚掉,接下来就可以放心debug了。
Debug
什么是内存泄漏?
简单的讲,就是程序员申请的内存在使用完后没有还给操作系统,由于笔者使用的是C++语言,因此内存泄漏一般是这样的:
obj* o = new obj();
...
// 使用完obj后没有delete掉
肯定有什么地方申请了内存后没有调用delete释放内存。
在这里介绍一下笔者的代码改动,我的任务其实是重构一段代码,把这段代码并行化。也就是旧的逻辑是在一个线程中串行执行的,现在我要把这段逻辑放到两个线程中并行执行,这是最让人头疼的任务之一,并行化改造是比较容易出bug的。
接下来梳理了一遍所有内存的申请和释放,这其中包括:
使用new/delete分配释放的内存
使用内存池分配释放的内存
仔细梳理一遍后没有发现任何问题,该释放的内存都已经释放掉了,这时笔者已经开始怀疑人生了 :) ,很显然还有一段没有注意到的地方出现了问题,这是必然的,虽然知道问题必然出现在改动的这些代码里,但是我并不能确定出现的位置。
没有办法,到这里基本上已经要放弃自己人肉debug了,想利用一些内存检测工具来帮助自己确定问题。
常见的内存泄漏检测工具包括valgrind、gperftools等,valgrind的好处在于无需重新编译代码即可进行内存检测,但是缺点是会使得程序运行非常缓慢,官方文档给的说法是会比正常的程序运行慢20-30倍;gperftools则需要重新编译可执行程序。这些工具需要下载安装测试,其中还涉及到申请机器权限等问题,笔者觉得还是比较麻烦,况且这个问题也不是大海捞针一样,问题肯定出在了并行化的这段代码中。
到这里我决定再换一个思路来排查问题,既然代码重构后开始并行执行,那么出现问题大概率是因为多线程问题,遇到多线程问题首先重点排查的就是线程间的共享数据。
多线程问题的关键——共享数据
我们知道如果线程之间没有共享数据那么就不会有线程安全问题,我们使用的锁、信号量、条件变量等其实都是用来保护共享数据的,比如锁通常是用来包括临界区的,临界区中的代码操作的就是线程共享数据;信号量使用的一个经典场景就是生产者消费者问题,生产者线程以及消费者线程都会操作同一个队列,这里的队列就是共享数据。
沿着这个思路开始找在两个线程中都使用到的共享数据,果不其然,在一个角落中发现了这样一段代码:
auto* pb = global->mutable_obj();
这是分配protobuf对象的一段代码,protobuf是Google开发是一种类似于JSON、XML的技术,因此常用于网络通信和数据交换等场景,比如RPC等。
如果你不了解protobuf也没有关系,实际上上面的这段代码要做的事情是这样的:
if (global->obj == NULL) {
global->obj = new obj();
}
return global->obj;
值得注意的是,这段代码现在会在两个线程中执行,显然问题就出现在了这里。
那么问题是怎么出现的呢?
我们假设有两个线程,线程A和线程B,当这样一段代码在线程AB中同时执行时可能会有以下场景:
线程A拿到global->obj并检测到此时的global->obj为空,因此决定为其分配内存,但不巧的是此时发生线程切换,线程A在为global->obj分配内存前被暂停运行,如下所示:
if (global->obj == NULL) {
<------- 线程切换,线程A被暂停执行
global->obj = new obj();
}
return global->obj;
线程A被暂停运行后线程B开始执行,这段代码同样会在线程B中执行一遍,因此线程B会首先检查global->obj发现为空,因此为global->obj分配内存,分配完内存后发生线程切换,线程B被暂停运行,如下所示:
if (global->obj == NULL) {
global->obj = new obj();
<------- 线程切换,线程B被暂停执行
}
return global->obj;
线程B被暂停运行后调度器决定重新运行线程A,此时线程A开始从被中断的地方继续运行,还记得线程A是从哪里被中断的吗,没错,就是在为global->obj分配内存前被中断的,此时线程A继续运行,也就是说global->obj = new obj()这段代码又被执行了一次,虽然线程B已经为global->obj分配了内存。
Oops,典型的内存泄漏,线程B分配的内存再也无法被正常释放掉了。
至此,我们已经找到了问题的原因,罪魁祸首就是共享数据,关键的一点是要意识到你的线程会随时被中断执行,CPU会随时切换到其它线程。
代码修复也非常简单,再新增一个变量,两个线程不再使用共享数据,到这里问题就解决了,从发现问题到完成修复耗时大概4小时。
经验教训
代码的并行化重构是一件非常棘手的任务,很容易出现线程安全问题,解决线程安全问题首先要考虑的不是要不要加锁,而是多个线程是否真的有必要使用共享数据,没有必要的话,多个线程操作私有数据根本就不会出现线程安全问题。
当出现线程安全问题时,第一时间重点排查线程使用的共享数据。
内存泄漏检测工具
虽然这些没有使用检测工具全靠人肉debug,其实还是因为问题排查范围比较小,如果我们根本就不知道问题出现在了那次代码改动,那么检测工具就非常重要了,在这里简单介绍一下valgrind的使用,详细的介绍请参考官方文档。
假设有这样一段问题代码:
#include <stdlib.h>
void f(void)
{
int* x = malloc(10 * sizeof(int));
x[10] = 0; // 问题1: 越界
} // 问题2: 内存泄漏,x没有被释放掉
int main()
{
f();
return 0;
}
这段代码中有两个问题:一个是数据的越界访问;另一个是内存泄漏。将该程序编译为myprog。
接下来使用valgrind来检查该程序,使用以下命令:
valgrind --leak-check=yes myprog
运行完成后valgrind会给出检测报告,关于程序越界访问会给出这样的输出:
==19182== Invalid write of size 4
==19182== at 0x804838F: f (example.c:6)
==19182== by 0x80483AB: main (example.c:11)
==19182== Address 0x1BA45050 is 0 bytes after a block of size 40 alloc'd
==19182== at 0x1B8FF5CD: malloc (vg_replace_malloc.c:130)
==19182== by 0x8048385: f (example.c:5)
==19182== by 0x80483AB: main (example.c:11)
第一行告诉你代码中存在Invalid write,也就是无效的写,并给出了问题出现的位置。
关于内存泄漏问题会给出这样的输出:
==19182== 40 bytes in 1 blocks are definitely lost in loss record 1 of 1
==19182== at 0x1B8FF5CD: malloc (vg_replace_malloc.c:130)
==19182== by 0x8048385: f (example.c:5)
==19182== by 0x80483AB: main (example.c:11)
这里第一行报告了内存"definitely lost",也就是说一定会存在内存泄漏,并给出了问题出现的位置。
实际上除了"definitely lost",valgrind还会给出"probably lost"的报告,这两种报告的含义是这样的:
"definitely lost":你的程序一定存在内存泄漏问题,修复。
"probably lost":你的程序看起来像是有内存泄漏,有可能你在使用指针完成一些特定操作,因此不一定100%存在问题。
总结
编写正确的多线程代码从来不是一件容易的事情,线程安全问题的根源在于共享资源,因此在使用共享资源前务必确认我们一定要用共享资源吗?








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721