
然而,仅仅通过Kubernetes管理并运行数千个容器是不够的,你还需要监控这些容器,以确保服务处于最佳运行状态。这一过程被称为网站可靠性工程(Site Reliability Engineering),是由谷歌提出并推广的一个术语。可观测性和分析性是SRE的重要组成部分。它可细分为以下三个部分:
监踪:从应用程序和宿主机中提取数值指标,这些指标可以被可视化和分析,以显示资源的当前状态。一旦提取到了数值指标,就可以使用它们来设置告警规则、促进分析和调试,并更好的做出决策;
日志:帮助开发人员在容器发生故障时,排除出错原因。容器日志随着容器生命周期的结束也就消失了。Kubernetes和Docker确实提供了一种浏览容器日志的方式,但是它的功能非常有限。因此,在任何以容器构成的环境中,集中式的管理日志是必须的;
跟踪:帮助你调试在网络上运行的服务,并跟踪请求链路,直到找到问题的根源。在微服务体系结构中,当多个服务/容器相互发送请求以完成一个业务任务时,需要一个适当的跟踪解决方案。
本文将详细讲解六个最热门的开源工具,专门用于容器化服务的监控和分析。
当讨论开源监控解决方案时,首先想到的就是Prometheus。它在开发社区中非常流行,是CNCF的毕业项目。Prometheus最初由SoundCloud创建并开放源代码。Prometheus简化了提取数值指标的过程,直接从一个基于时间序列的监控端点中提取。适用于监视高度动态变化的容器环境。
Prometheus由三个部分组成:Prometheus server、Alertmanager和exporters。exporters以独立进程或容器的方式运行在目标机器上,生成各种指标数据,通过API的方式发送给Prometheus server。Prometheus server负责服务发现,也可以从exporters直接拉取指标数据,然后将数据存储在Prometheus的数据库中,用于可视化或告警服务。Alertmanager用于设置告警规则,分析Prometheus数据库中的数据,当触发某个规则时,向接收者发送警报。在这里可以找到大量的exporters,它们都得到了Prometheus的官方支持和社区的维护。
Prometheus已经成为监控云原生应用的行业标准。尽管它以服务发现的简单性、易用性、告警服务和与Kubernetes的集成而闻名,但指标数据只能被Prometheus server拉取的方式并不理想。这意味着exporters必须能够被Prometheus server访问。然而,在Prometheus中实现了一个pushgateway,它支持将数据直接推送给Prometheus server,而不是由Prometheus server主动拉取。Prometheus的另一个缺点是它不能很好地水平扩展。这个问题可以在Thanos adaptation of Prometheus(https://improbable.io/blog/thanos-prometheus-at-scale)找到解决方案。
相关工具和技术:Grafana、Cortex、Thanos、Prometheus Exporters、Alert Manager、Istio、Prometheus Operator。
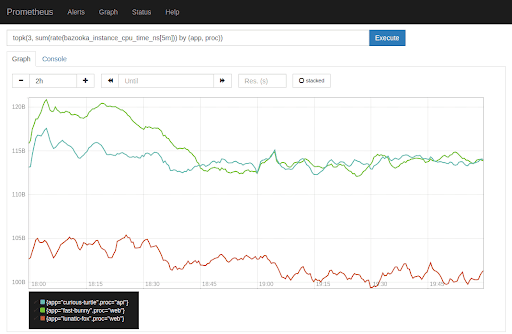
图1:Prometheus图表
Grafana是一款开源的指标分析和可视化套件。它允许你使用来自多个数据源(如Prometheus、Elasticsearch、MySQL、Postgres和Redis)的数据创建自定义仪表板。此外,Grafana有自己的告警系统和基于角色的访问控制(RBAC)系统。Grafana作为一种数据可视化工具,在Prometheus的用户中非常出名,它可以有效地可视化存储在Prometheus中的指标数据。Grafana为来自各种数据源的数据提供了大量官方和社区构建的定制化仪表板,允许用户轻松地设置仪表板并监控数据。Grafana提供另一种相关产品Loki,它将Kubernetes中的日志聚集起来,并与Grafana UI很好地集成在一起。
相关工具和技术:Loki、Prometheus。

图2:Grafana中Kubernetes资源仪表板
Elastic Stack是一组来自Elastic的开源产品,旨在帮助用户实时搜索、分析和可视化来自任何类型的数据源的任何格式的数据。该产品之前被称为ELK,每个字母代表公司的一款主要产品:Elasticsearch、Logstash和Kibana。Elastic Stack利用Elasticsearch提供监测和日志解决方案。
为了聚合日志,人们倾向于使用Elasticsearch进行存储,使用Logstash或Fluentd发送日志,使用Kibana进行可视化。Fluentd不是Elastic Stack的一部分,但它广泛地应用于Kubernetes环境中,用以代替Logstash。类似地,Metricbeat用于获取指标数据并在Kibana上进行可视化。Elastic Stack企业版附带了X-Pack,X-Pack是一组支持报表、警报和基于角色的访问控制(RBAC)等功能的附加工具。默认情况下,Elastic Stack GUI(Kibana)不支持RBAC。你必须使用Elastic Stack企业版本来启用RBAC。
相关工具和技术:X-pack、Metricbeat、Logstash、Kibana。
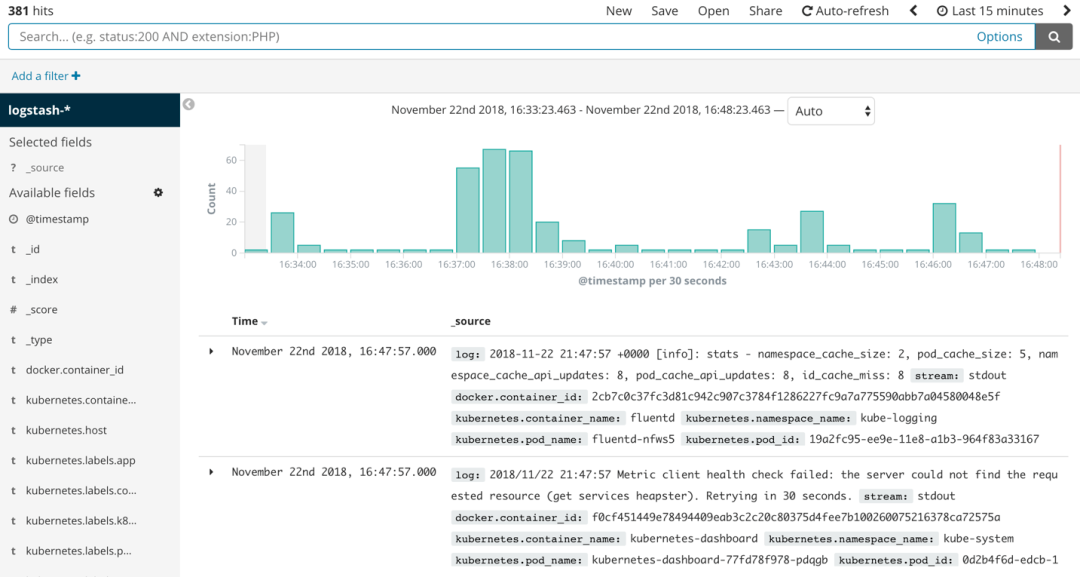
图3:Elasticsearch中的发现视图。
Sensu Go是一款用于多云监控的遥测和服务健康检测解决方案。帮助你查看服务器、容器、服务、应用程序、功能和跨任何公有或私有云的连接设备。Sensu可以和Prometheus一起运行,以获得两种解决方案的最佳效果,也可以在没有Prometheus的情况下自己运行。因为将应用程序级别的指标数据导出到Prometheus需要将Prometheus SDK加载到应用程序的代码库中,并暴露一个端口,所以Sensu与Prometheus一起工作是最好的。然后,该端口负责收集数据并存储在Prometheus server中。这听起来好像有很多工作要做——有时确实如此。Sensu通过使用sidecar的方式来避免这种复杂性。在应用程序旁部署了一个Sensu代理。Sensu代理不断地收集数据并发送给Prometheus server,这样就不需要更改应用程序代码了。
Sensu也可以脱离Prometheus工作,独自在Kubernetes中运行,在Kubernetes中,Sensu有自己的服务器来存储和可视化由Sensu代理收集的数据。
相关工具和技术:Prometheus。
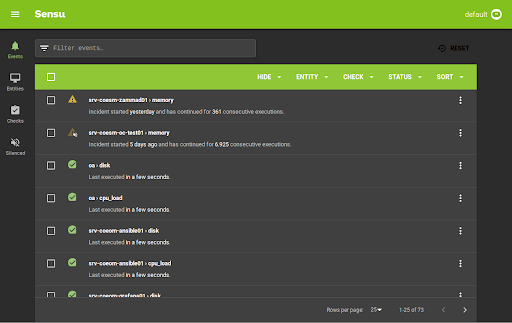
图4:Sensu中的事件
Sysdig公司有两款开源产品:Sysdig Inspect和Falco。在这里,我们将重点讨论Inspect,Sysdig Inspect用于监视和捕获系统中运行的容器进程,并允许深入这些进程以进行事后取证,帮助分析应用程序性能、排查错误并监视任何可能出现错误的处理器。此外,如果你的系统遭到了破坏,Sysdig帮助你了解破坏是如何发生的,以及在这个过程中丢失了哪些数据。Sysdig Inspect是一个非常强大的工具,它关注于系统的性能调优和安全性调查。
相关工具和技术:Grafana、Sysdig、Sysdig Falco。
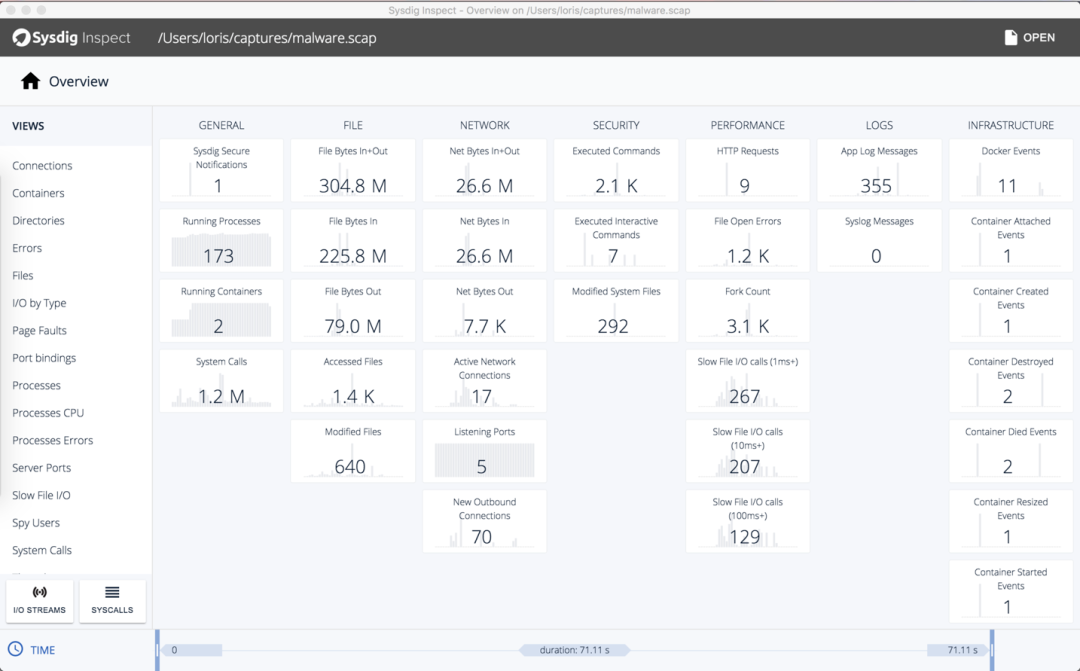
图5:Sysdig检查概述
Jaeger是一种端到端的分布式跟踪解决方案,由Uber Engineering开源。帮助你在复杂的分布式系统中监视和排查事务故障。在现代微服务体系结构中,大多数操作问题都属于网络和可观察性的范畴。当发生服务故障时,你不知道请求是如何通过网络从一个服务转到另一个服务来完成单个业务请求的。调试变得异常困难。Jaeger目前在CNCF下孵化,Jaeger使用跟踪技术来寻找出错原因、性能和延迟优化,以及分布式事务监控。Jaeger可以与Istio一起使用,Istio是由谷歌开源的一款流行的服务网格实现。
相关工具和技术:Prometheus、Jaeger、Zipkin、Istio。
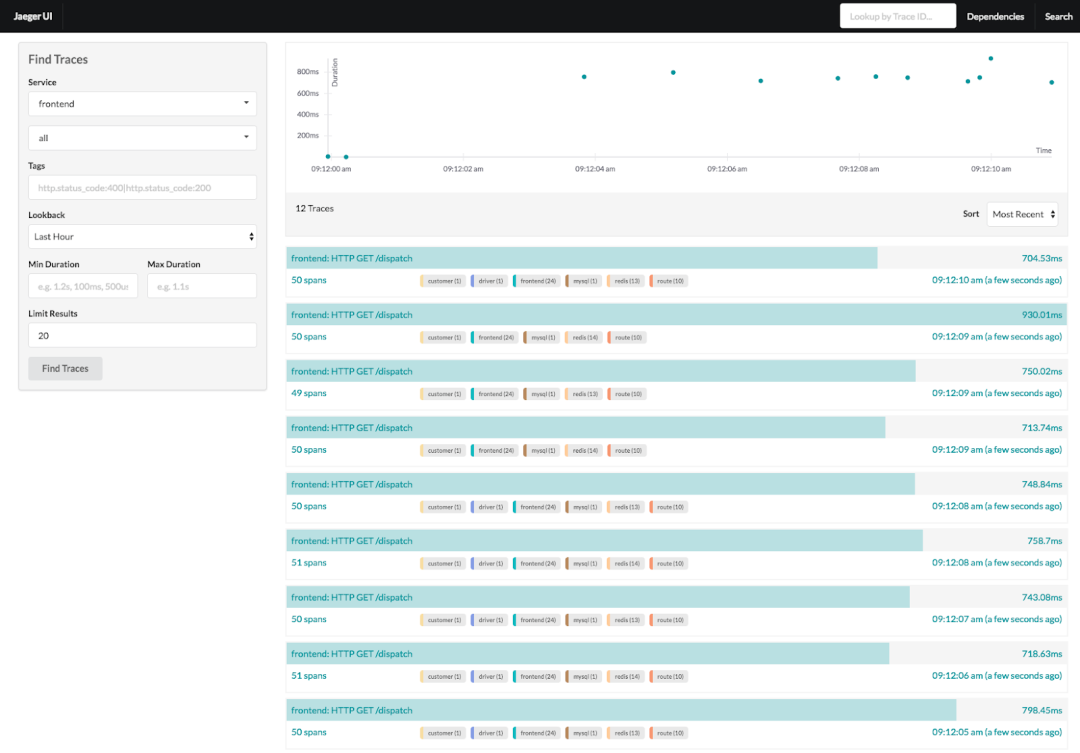
图6:Jaeger轨迹追踪图
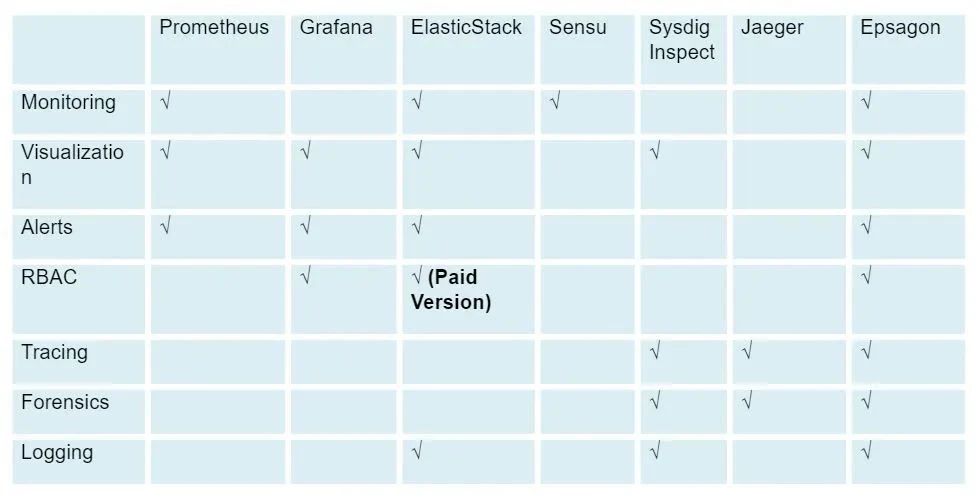
这些工具在科技行业中被广泛使用,它们都有各自的特点。然而,大多数解决方案都需要熟练的技能去部署和持续的维护,这可能会成为DevOps团队的负担,并分散他们对业务的注意力。没有一个解决方案可以满足所有需求,因为每个工具都侧重于可观察性和分析的一个或两个特定方面。通过将这些工具混合在一起,可以针对自己的业务需求获得独特的解决方案。
为了便于比较,下面的图表概述了本文讨论的每种工具提供的特性。
原文地址
https://devops.com/top-six-open-source-tools-for-monitoring-kubernetes-and-docker/








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721