
杨经营
58到家运维专家
多年互联网运维经验,2015年加入58到家,精通Linux操作系统,见证了58到家运维体系从0到1的建设,主要负责运维自动化、平台化在58到家的应用及推进工作。
现任58到家技术委员会成员,负责58到家运维体系整体发展方向与技术选取。
近几年公有云已日趋成熟、稳定,成为很多中小型互联网公司的首选,其成本、易维护、轻资产、可靠性、基础设施、技术支持这几方面公有云和传统IDC相比有着独特的优势,尤其是当公司整体资源体量较小(硬件IDC成本在100万/年以下)时,该优势会非常明显。
4年前,2016年初58到家决定All in 公有云。
一、石器时代那道坎
2015年10月份,58到家获得阿里、平安、KKR联合投资,到家各项业务取得了飞速的发展,经58到家技术中心管理层决策,58到家正式开启了由IDC机房迁移至公有云的"凌云"之路。
从计划迁移,到IDC机房-公有云专线打通、公有云全量部署线上资源(服务器、数据库),笔者有幸全程参与并作为运维组的接口人推进实施,整体的架构迁移《从IDC到云端架构迁移之路》有详细记载。
有一点要说明的是对于WEB站点的迁移,运维内部采用的基于Nginx upstream模块实现逐步切流量至云端服务,相对于万网、DNSPod商业DNS的权重调整方式来说,更加符合我们58到家当时的迁移需求,做到了真正的平滑、极速切换和回退,解决了运营商缓存的难题。

凌云项目从基础资源的准备,到线上环境迁移完成,历时114天,涉及2T+数据(不包含大数据),迁移的服务160+,涉及数据库70+,全体的技术同学投入到了该历史性的项目中,相信每一个参与其中的战友必定收获满满。
二、All in 公有云的“坑”
凌云项目结束后,58到家正式开启了基于公有云的技术升级之路,这其中也包含了运维,对于机器、资源、域名、云端各项服务,云端都能够实现快速部署、实施和交付,这个是云的明显优势。
但是随之而来的,我们也面临了很多问题:如2016年上半年迁云不久即被我们遇到的多年不遇的公有云城际网出口故障,导致业务中断2小时以上,到家核心库使用的havip产品问题导致数据库连续2小时以上的故障,BI使用的服务器的性能一直在报瓶颈,价格成本的增长与我们的预期变化较大,从初次部署时月总费用到价格翻倍只用了几个月的时间(梳理清费用都去哪儿了、谁花的钱最多需要一周甚至更长时间)。
当时运维3人,RD研发150+人,运维每天面对的都是重复性的需求申请、各种线上问题、资源查询等,基本处于被动应对、救火的阶段,很多资产、申请都不可追溯甚至无主,某个服务的交接、迁移涉及梳理、确认时,效率非常低,运维内部的资产维护还是基于excel模式,如下图所示:

三、应运而生的“58到家运维平台“
基于上述状况,运维需要打造运维平台来为我们整体的工作提效,2016年10月份,运维第一代运维平台正式启动开发,架构图如下:
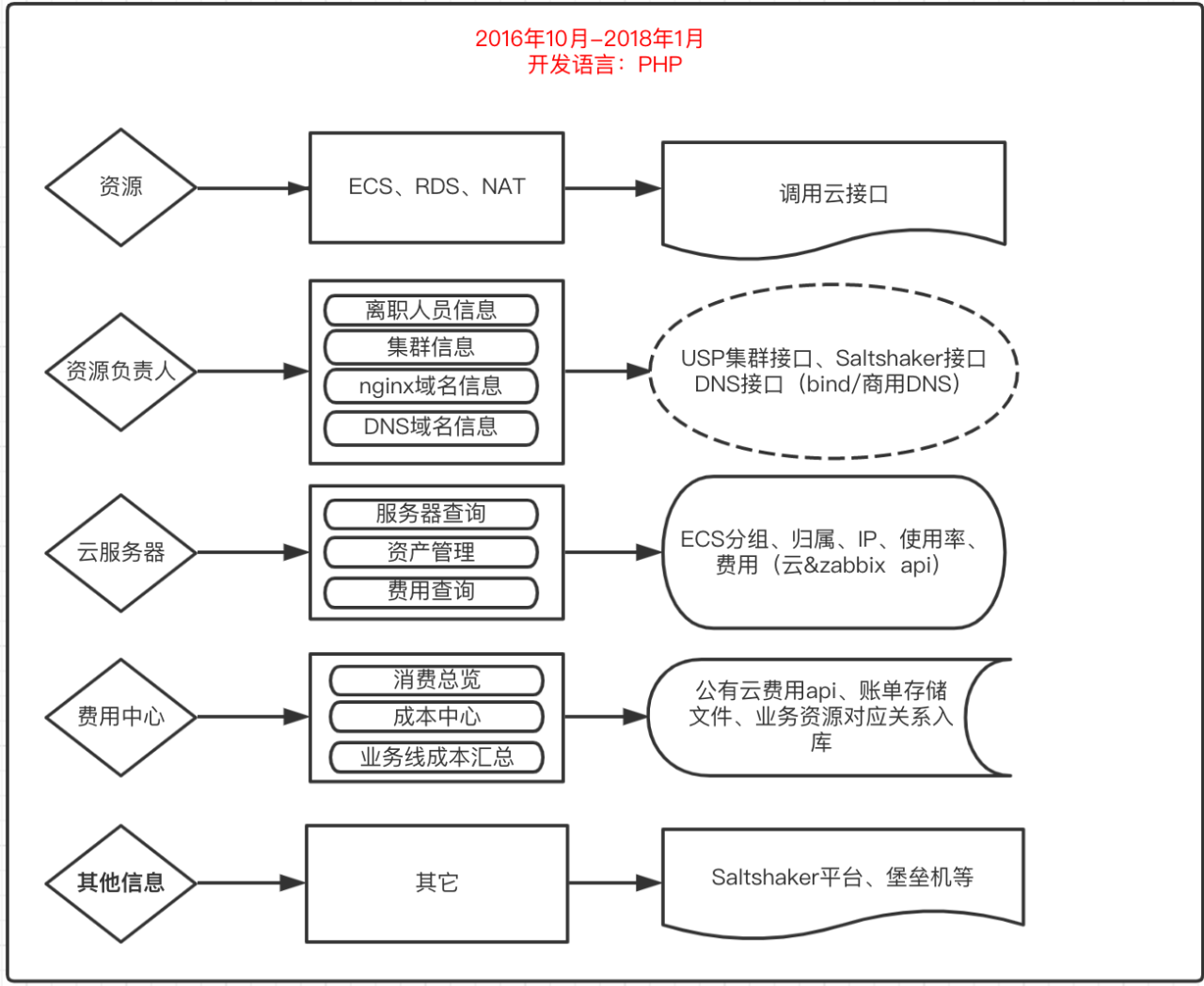
第一代运维的靓照如下图所示:

运维平台的诞生,解决了我们资源归属、资源成本计算的问题,解决了运维手动添加NAT外网权限的问题,解决了费用拆分至各业务线的问题,解决了技术人员离职归属资产变更的问题,解决了域名、资产归属查询的问题,一定程度的解放了运维的双手。
四、“苦尽甘来”持续演进:第二代运维平台
2019年4月份,随着我们的Python开发妹子加入运维团队,我们的第二代运维平台正式起航,开始了持续演进之路,附架构图:
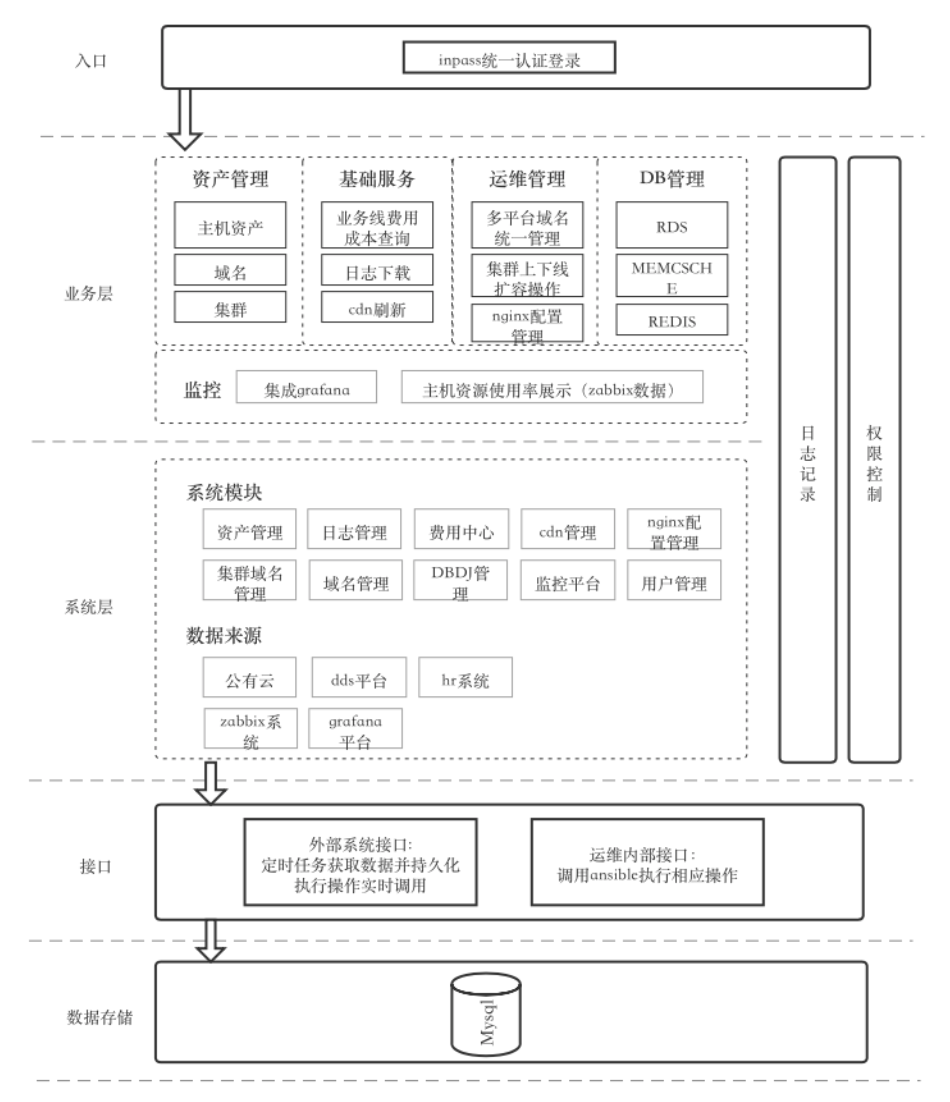
现运维平台核心功能点&解决的问题:
支持部门维度的资产、费用导出,对于各部门产生的云端资源费用,一目了然,可查询、无异议,哪个部门是消费大户查一下,就知道。
支持服务器资源归属、服务器使用率、是否可以部署新服务进行建议,以前我们遇到的发现某个IP在疯狂的调用我们,不知道是哪个部门的?现在只要查一下,就知道。
当夜深人静、华灯初上时,我们还为上完线后要立即刷新某个静态文件而走一通申请流程而苦恼吗?运维平台已经通过调用公有云cdn接口并结合权限控制,实现也FEleader层面自助刷新功能,啥时刷新,你说了算(当然,恶意刷新会上我们的黑名单哦)。
将内部DNS、公有云、商用DNS产品整合在一起。之前运维新增、变更某个域名,可能需要登录各个DNS管理平台,现有的域名管理已将几个平台整合在一起,一个界面搞定了全部。
将运维的grafana监控整合进运维平台,业务同学直接可以在此查各自服务器等监控信息。
对于业务线同学来说,可以在此根据域名关键字、端口、iP等维度查询自己想要的信息,省去了和运维沟通的成本;对于运维来说,运维通过集成、调用nginx域名添加、集群扩容、域名下线、集群下线等http接口,实现一站式业务需求管理,极大的提升了运维的工作效率。
根据平台功能模块,添加不同维度的管理权限,进而实现分权限使用。
嵌入业务同学需要用到的各种需求、申请提报站点以及只读账号介绍、家政神奇的nb命令介绍、域名规范、工单邮件规范、堡垒机站点、运维工单站点等等,站点导航中全部都有以后大家只需要记住运维平台一 个域名即可^_^。
运维平台现在长这个样子:

五、未来规划
从2015年11月至今,58到家运维平台经历了不同的发展阶段,一路风雨兼程,与我们一起见证58到家的发展,后续我们的运维平台将持续演进、优化,进一步推广自动化,为业务同学、为运维内部、为其他有需求的平台,提供助力,让我们一起携手,共同努力,走过2020这注定不平凡的一年!
“学则思,思则变,变则通,通则达,达则济天下,运维、QA、RD、FE是一家”与大家共勉!
Q&A
Q1:成本管理和相关规范是怎么规划和落地的?
A:运维平台建立之前,最初是完成由运维人工管理、确认,季度性维度对整体资源进行梳理,并产出相关资源使用情况报告。
运维平台成本中心模块建立后,结合我们zabbix资源使用率相关信息,就能够实现自动化的管理,可以根据我们自行制定的资源使用规范(例如服务器cpu内存整体使用率低于40%的情况下需要对服务器降配或者暂时不能新申请服务器等)。
借助于运维平台以及公有云的费用中心接口,将成本明确的拆分的各个使用方,后续定期给其发送资产使用报告,对于严重浪费的部门限期资源整合等,这样就能将成本管理简易化,让使用方和运维都心中有数,逐步提高全体对资源、成本的控制、节约的意识。
Q2:运维平台与云机器(不同云平台)的数据怎么打通获取?
A:不同公有云的互联互通,是使用多云的企业面临的非常现实的问题,我建议大家直接使用第三方做多云互通的公司,通过第三方公司的专线形式实现多云的内网互联。如果有自己的IDC托管机房,可以从IDC机房云厂商分别拉专线以IDC为中转点进而实现混合云环境的内网互联。
Q3:把当前公司内部系统和云厂商,进行整合到现在的一个平台上,阻力大不大?通常会有哪些阻力?
A:这个内部系统和云相关的功能整合,如果是运维内部系统的话内部可以消化,阻力可以忽略。如果涉及其他部门的系统要整合在一个平台,需要运维和系统负责人协调好,最好是由双方的leader层面达成一致后再实行,要不然跨部门、甚至跨云的整合,阻力肯定是有的并且不会小。
Q4:您这边容器及K8S监控是怎么整合的?
A:容器和K8S的话,我们计划今年下半年开始推,使用公有云的容器相关产品,监控的选型使用Prometheus。
Q5:对于ECS/RDS/OSS/CDN这些IaaS、PaaS服务,以及对于业务的不同运行环境(开发、测试、预生产、生产等)都有对应的成本优化最佳实践吗?
A:我们现在是不同的环境,分别部署了相应的整套服务,生产、开发、测试、预发布,成本优化还是基于我上文提到的利用运维平台成本中心的功能,去做整体的优化。其实个人认为要逐渐培养全体技术具备主人翁的意识、成本控制意识,资源的最大化利用自然就能做到水到渠成,而不是作为我们的一个包袱。
Q6:请问您这边的监控中心是怎么规划实现的?
A:目前58到家在做的监控中心项目,是集成了我们FE、运维、DB、架构的对应监控的负责人,在整体的集合、开发、聚合我们各个监控系统的资源,最终目标是汇聚、定制化开发为我们全体技术服务的全方位资源、服务监控体系。
Q7:对于安全,运维会额外多做很多事情,但不考虑安全又有隐患,怎么拿捏这个度?
A:很多中小型公司,前期是没有专职安全人员的(我们58到家最初也是这样,我们的安全完全依赖于同城安全团队对我们的支持),这个时候安全相关的很多工作会落到运维同学身上,因为互联网安全法对于涉及个人敏感信息等的网站的管控越来越严格,建议没有专职安全同时存在着很多安全问题无处着手的中小型公司,可以最低成本请专业的安全团队来协助解决自己面临的安全方面的问题。
这方面我想说的是术业有专攻,运维之于安全方面的专业度毕竟有限,建议大家交给专业的人来做安全方面的事情。
Q8:上文提到有zabbix和Prometheus,是不是Prometheus监控业务和服务层,zabbix监控基础设施层,混合使用?
A:Prometheus的监控我们规划是对容器方面的监控,基础设施层如K8S底层的ecs可以选择zabbix或者Open-Falcon去实现,这个建议根据自己业务的实际需求来即可。
服务层面的监控,如果大家公司的技术栈是java并且没有专职的架构团队来开发业务监控的话,可以使用美团开源的CAT监控。
Q9:监控有没有二次开发,能让业务负责人自助添加监控?
A:让业务负责人自助添加监控我们现在是在我上文提到的监控中心里面有规划,后续会统一开发、实现。
对于运维自身的监控平台来讲,如果我们有专职的运维开发来支持,可以进行二次开发。如果没有,建议以能解决自己的实际需求、痛点为出发点重新来审视这个问题。

直播回看链接:http://z-mz.cn/qJYV








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721