
本文基于目前运维领域普遍存在的业务痛点,研究智能运维在证券行业相关场景中的落地及实践,主要涉及根因分析、容量预测及智能知识库三个方面。通过自主设计智能化运维平台,实现了IT运维、大数据及AI算法的有机统一。
根因分析探索海量强关联监控预警信息,运用数据挖掘及算法分析技术,剖析问题根本原因所在;
容量预测通过研究历史数据,利用AI模型算法,实现了容量信息的提前预警;
而智能知识库结合传统知识库和AI算法的双重优势,实现了知识共享与解决方案的快速定位。
以上三个场景的落地均切实提升了运维人员的工作效率,为打造智能型自动化运维奠定了基础。
本文首次提出将改良的排序算法应用于根因分析,详细算法组成中根源影响速算得分和利用变更性质推导根源概率因子的做法,目前在国内论文上均未见提及,可供后续研究者开拓思路。
一、引言
近年来,随着信息技术的发展,金融科技的概念已越来越多被应用于金融行业,这不仅涉及传统金融业务的颠覆和转型,也深刻影响着传统运维模式的转变。
业务的发展不仅带来了新的机遇,也向提供技术支持的运维部门提出了更多的挑战。从传统的手工运维到自动化运维,再到现阶段的智能化运维,运维方式和效率的提升为各类技术系统的稳健和高效提供了强有力的支持。
而人工智能、大数据等前沿技术的发展,也促使构建智慧运维成为未来的趋势。本文结合证券行业现有运维工作中的业务痛点,对大数据、人工智能等技术在具体运维场景下的应用进行了实践性探索。
在信息化时代,企业早期构建的各类系统一般采用“烟囱式”架构,而传统的运维方式则更多依靠人工巡检,不仅效率低下,同时也不能提前预知系统可能遇到的问题。此时,各系统的管理更偏重于集中式和两地三中心等模式。
随着信息系统建设的发展,分布式、横向扩展、轻量级、去中心化成为首要考虑目标。因此,基于虚拟化和云计算技术的自动化运维工具成为首选。
虽然自动化运维在一定程度上提升了系统运维效率,却不能解决业务与IT管理系统之间存在的断层问题,这导致企业在进行数字化转型的过程中,遇到了新的阻力。
通过对大数据技术的应用,能够初步解决IT与业务之间的断层问题,实现面向业务运维的转型。而在业务运维之上加入AI技术则是实现智能运维的基础。智能运维必将成为未来运维的发展趋势。
智能运维的通俗定义可以理解为传统运维与人工智能技术的结合,即利用大数据分析、机器学习等人工智能技术来自动化管理运维事物。在国外,其定义最早由Gartner提出,据其预测,到2022年,部署智能运维的企业将从现阶段的不足5%迅速提升到40%左右。不久的将来,智能运维将会取代原有的运维工具,让更多企业通过它进行业务运营及IT运维工作。
在国内,目前以BATJ为代表的互联网企业已在智能运维领域进行了初步的探索和特定场景的实践。以百度为例,其在2014年围绕系统可用性、成本、效率等三个方面,实现了智能运维在监控、知识库、容量控制等场景的落地。提出了百度智能运维的三个核心,即百度运维知识库、智能运维开发框架及算法服务。腾讯则提出了以织云Metis智能运维体系作为落地的智能运维实践平台。
考虑到证券行业对系统的稳定、安全、实时性等要求较高,因此其运维文化相较于互联网行业更为稳健及保守。同时,由于系统异构和标准化程度不够,直接照搬互联网企业的方式往往很难落地。有鉴于此,虽然智能运维的概念已被提出,但在证券行业,仍主要处于理论研究阶段,相关实践案例也较少。
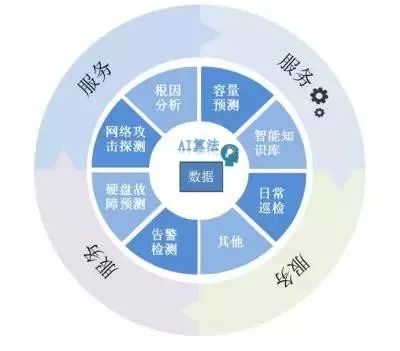
图1 证券行业智能运维模型
智能运维的初始模型由Gartner提出,根据其理念,该模型是一个融合了人工智能、大数据等技术,通过构建相关平台,最终实现集监控、自动化、服务于一体的智能运维体系。而本文提出的智能运维模型也是基于其模型的改进,结合实际,初步规划了如图1所示的证券行业智能运维的通用模型。
如图1所示,该模型是数据、算法、场景、服务的有机整合,以数据为核心,运用不同AI算法,落地具体场景并最终提供所需各类服务,结构上以由内而外的发散型结构为主,通过层层递进,最终利用服务实现价值输出。
结合模型理念,在具体实施上,采用“运维数据总线+三大子平台”的“1+3”模式来构建智能运维平台。
其中,三大子平台分别代表一体化运维平台、大数据平台及算法平台。一体化运维平台即传统的监管控一体化平台。大数据平台负责将运维数据以时间序列存储,主要提供海量运维数据的标注和快速访问能力。而算法平台主要完成算法的集成、训练及接口调用服务。设计框架上则采用了分层思想,具体可参见第二章的框架设计。
二、智能运维平台框架设计
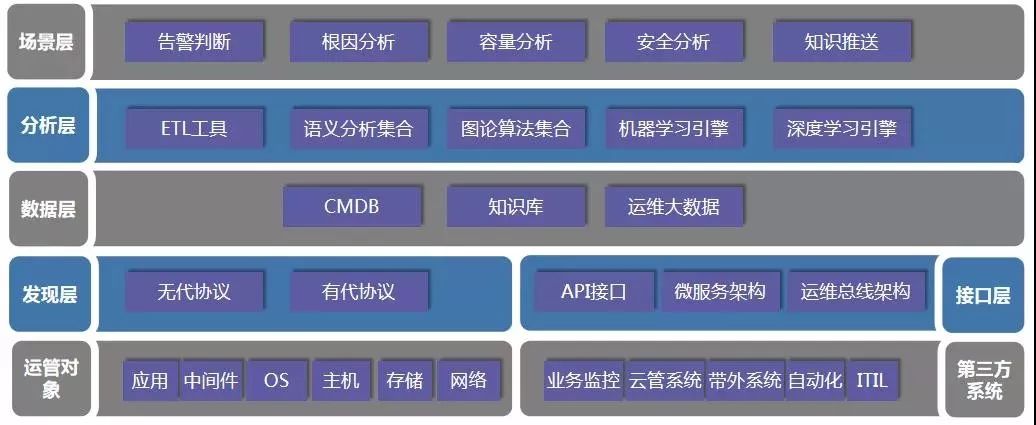
图2 智能运维平台框架设计图
智能运维平台的设计框架如图2所示。按照自底向上的结构主要可以分为五大层次,分别涵盖发现层、接口层、数据层、分析层和场景层。
发现层用于实现各类系统、设备信息的采集获取工作。通过自动发现或在各类系统设备上配置规则,实时获取数据信息,为数据层提供支持。其直接面向内部系统设备,包括应用系统、存储、网络设备及操作系统等。
接口层主要是对各类运维监控数据进行归集,并向其他系统获取运维数据提供服务。考虑到企业内部原本存在的一些其他类型监控,该层的作用主要用于整合现有各类第三方监控系统,获取额外数据信息。典型的第三方系统如带外管理、云管平台、自动化及ITIL等。实现上推荐建设kafka 消息总线来实现接口的标准化、解耦、高负载和性能的横向扩展。
数据层基于发现层和接口层提供的原始数据,完成数据的分类存储。目前主要建设CMDB、知识库及运维大数据,是各类数据汇聚的核心层。数据层广泛采用Elastic Search技术实现数据的存储及搜索。其提供的分布式多用户搜索能力能支持海量数据的实时搜索,从而保障稳定、可靠的性能体验。
分析层也称算法层,采用机器学习、深度学习等技术,融合以语义分析、图论算法及传统ETL分析工具,能实现各类监控信息数据的处理分析及挖掘工作,为后续的场景层提供支持,是智能运维平台的关键核心所在。目前采用的实现方案主要包含三点:①以Python语言作为AI算法的统一载体,实现最大限度复用互联网算法成果,缩短系统建设周期;②以Apache Spark作为通用并行框架计算引擎,确保数据的灵活访问并能满足按需扩展的要求。③以JSON作为数据格式化的规范。具体算法上做到能对外提供AI算法服务及调用。
场景层可以理解为具体应用的实现层和落地层。在运维领域,存在许多特定场景,普遍存在使用频繁、涉及海量数据、问题定位困难及发生问题破坏性大等特点。典型的如网络攻击探测、故障根源探测、容量预测等。而场景的选择可以按照使用频率、影响程度等因素采用“四象限法则”对建设优先级进行排序,如图3所示。
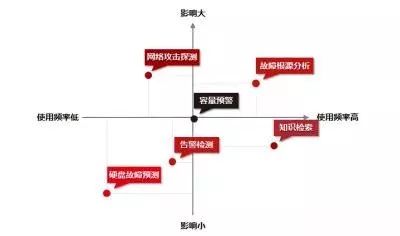
图3 场景设计“四象限法则”
三、场景选择及实践
结合智能运维平台设计框架,以评估运维效果的重要指标MTBF、MTTR为参照,本文选择了“根因分析”、“智能知识库”、“容量预测”三个场景进行落地。通过这三个场景的实践实现对系统负载情况的预测及指导、辅助运维人员快速定位生产问题及相关解决方案。
1)背景概述
随着信息系统规模的不断扩大,各类系统及应用之间的关系也错综复杂,一旦某个节点发生故障就极易扩散形成多头告警,如何提供有效的工具解决这一痛点成为当务之急。有鉴于此,根因分析成为智能运维系统的一个典型应用场景。
2)算法实现
目前广泛应用于根因分析的算法主要分为传统RCA算法和机器学习算法。但上述算法普遍存在的局限性是对应用对象有着较为严苛的要求,因此导致普适性不强,更适合于理论研究。基于此,本文提出了将排序算法应用于根因分析场景的想法。
参考百度、谷歌搜索引擎的排序算法,根因分析排序算法的数学公式可以表示为:
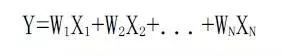
应用到本文系统,其原理是先通过白盒、黑盒和变更经验三种子算法分别计算出根因结果分值(子算法得分),如W1、W2.. WN,然后获取各分值与其对应加权因子Xi的乘积之和,最终得到总的排序值Y。
相关排序分值公式如下:
根因排序值=[白盒]加权因子*[白盒]子算法得分+[黑盒]加权因子*[黑盒]子算法得分+[变更经验]加权因子*[变更经验]子算法得分
相较于传统算法仅关注于判断指标的对错,本文使用的排序算法更关注于根因指标的可能性评估,通过降序排列确保命中最有可能的几条根因数据,从而提高算法准确度。该算法在总框架建立后还可以随时增补新的子算法;或在子算法结果WN不变的情况下,通过调整各子算法加权因子XN来改进排序效果。
[白盒]子算法实现
白盒算法的核心思路是研究告警在不同类型设备之间的传导次序:根据告警传导方向来决定对象摆放的层次(被传导者放于上层)。比如服务器出问题,会导致其上的数据库、中间件、程序发生次生错误/告警;但是不会影响下面的网络设备,如图4所示。
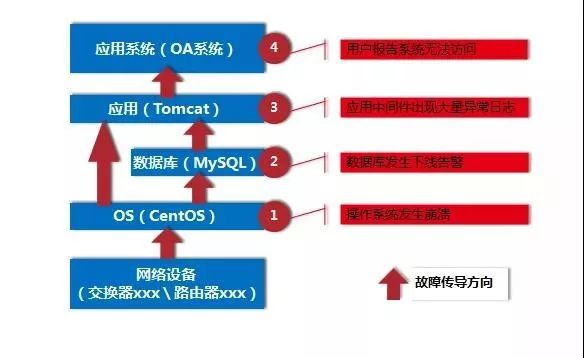
图4 故障扩散方向示意图
根据经验提炼【根源影响速算得分】用于无图速算:伴随生产系统的不断变更,实际操作中很难针对各系统专门绘制并准确维护如图4所示的故障扩散方向示意图,因此必须考虑在无图情况下进行分析的速算方法。
通过统计机房设备告警传导顺序并对结果进行排序,得出如表1所示速算得分表,其中分值越低表示越容易被影响,在并发告警后要优先处理速算得分高的设备告警。
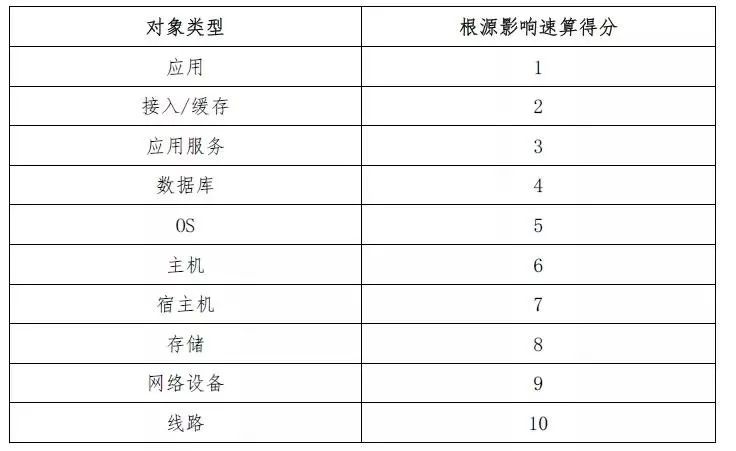
表1 设备速算得分表
根据表1可设置[白盒]子算法得分公式为:
得分=告警对应【设备类型】的【根源影响速算得分】
根据上述公式可以得出各类配置项告警后排错的先后顺序,但对同一个配置项内部并发告警的关联影响尚无法涉及。这就需要[黑盒]算法来弥补。
[黑盒]子算法实现
黑盒算法的原理是利用CNN卷积算法,从大量历史并发告警事件和根因告警事件的对应关系样本中,学习并发告警及根因告警事件之间的关联关系,从而生成相关度分析模型,最终用以预测生产告警事件中的根因告警事件。
该算法先将首次发生时间间隔不超过【2*指标最大监控采集间隔】的告警分为同一组;比如指标每10秒采集一次,则首次告警间隔不超过20秒的为一组。然后采用CNN卷积算法对相关数据进行训练,最后以事务组为样本单位展开分析,对各组内的并发告警给出具体某项告警是根源告警的分析结果。
最终算法设计如下:
得分=f(是否根源告警)*根源常量
针对:f(是否根源告警)是,返回1。不是,返回0.
根源常量=8
备注:根源常量设计选择范围为1到10,目前根据经验数据取值为8,目的是为了提升通过黑盒算法所确定的对应指标分值,令其值域范围能落到白盒算法结果的输出象限区间[1,10]之内。
目前,[黑盒算法]最大的局限性在于训练结果只能给出一个根源结果,若当前系统确实存在多个告警,且相互并不存在主次关系时,算法容易误报。但考虑到多个告警同时出现错误的概率极小,则在这种情况下即使存在100%误报,也不会大幅度降低单一错误下根源分析的准确度,因此可以忽略不计。
[变更经验]子算法实现
通常生产环境告警,运维人员的第一反应就是询问是否有过变更;根据ITIL标准维护组织(英国商务部OGC)发布的统计数据,80%的IT运维事故源自变更,而经验算法的原理就是以近期变更数据为依据来寻找告警根源设备。
①“近期发生变更的设备出错的可能性更高”是经验算法的核心思路:即从ITIL系统中查找各类设备是否最近发生过变更,若发生变更,则返回高分值,若无变更,则返回低分值。
②变更性质是评价出错可能性的细分依据:不同性质的变更通常隐藏着不同的风险。根据ITIL的分类建议,可以将变更划分为以下等级:
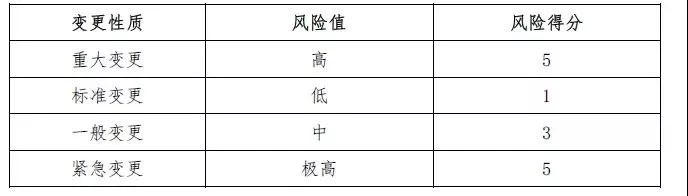
备注:考虑到需将经验算法的得分与白盒算法得分落到同一个象限区间[1,10]中,一般将经验算法的得分设置在1到5之间;另外经验算法相当于加分项,并不能准确给出根源,所以不宜超过5。
③算法公式
每个告警的[经验]子算法得分公式为:
得分=Max(对应设备七天内变更的风险得分)
经验算法的局限性在于如果近期相关设备没有发生过变更,则该算法不适用。
3)数据准备
和一般机器学习选用历史数据来作为样本不同,根源告警无法直接使用历史告警数据作为样本数据。主要是因为两点:
历史告警数据的数据量和频率太小,无法满足机器学习数以百万计的样本数据规模要求;
生产环境不能作为训练环境,而测试环境又难以和生产环境完全一致。
有鉴于此,我们采用方案为:
首先选择在测试环境模拟各种常见告警,用集中监控系统取得告警信息,形成单一场景的样本;
通过程序,随机选择一个或多个单一场景样本,形成大量(百万级)的叠加样本;
最后将上述样本灌入黑盒子算法机器学习程序进行训练。
4)算法模型及数据处理
通过上述算法设计,可以得出[白盒]、[黑盒]、[变更经验]的准确得分;为了确定各算法加权因子,我们参考了遗传算法的组合测试理论,即将各算法对应加权因子X1、X2、X3分别从0到1按0.01的精度调整并进行组合测试,通过程序比对不同组合结果下准确性的命中率来测算最佳加权因子。
根据实际测算,形成了基于现实数据的排序分值公式,具体数据如下:

5)落地效果
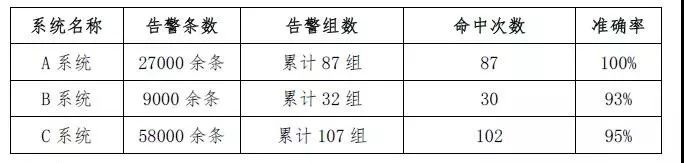
系统开发完毕后,通过将生产环境集中监控系统从2017年10月至2018年9月的94719条历史告警导入模型,逐一检查分析结果,统计信息如下:
备注:
[命中]指系统对告警分组正确且根源排序前3条数据即为真实根源告警。
这里A系统、B系统、C系统为生产系统的脱敏表述。
目前本系统及其算法对上述告警的根因准确度超过90%,可以为运维人员提供较好的决策支持。
以下将举例展示2018-12-03某真实系统告警的根源分析效果:
①图5为集中监控系统的告警图,集中展示了系统相关告警情况列表。
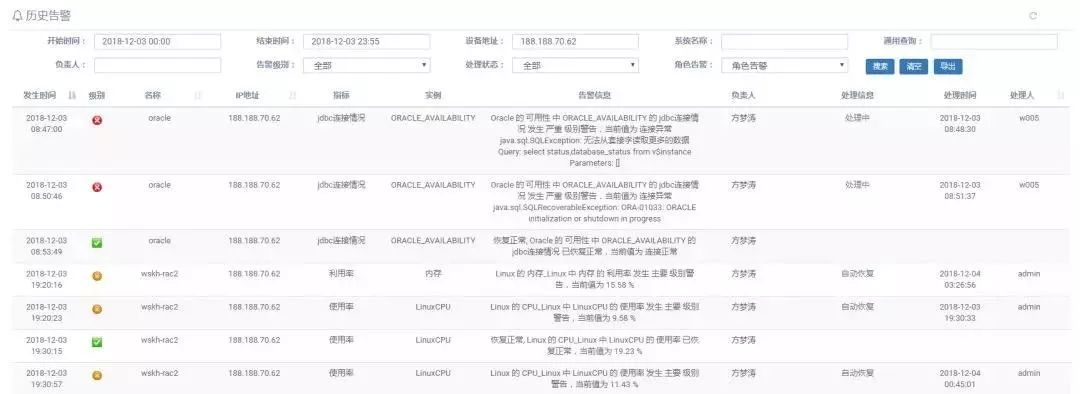
图5 集中监控系统告警图
②图6为根因分析模块汇总界面图,展示了告警错误信息及涉及配置项的统计信息。
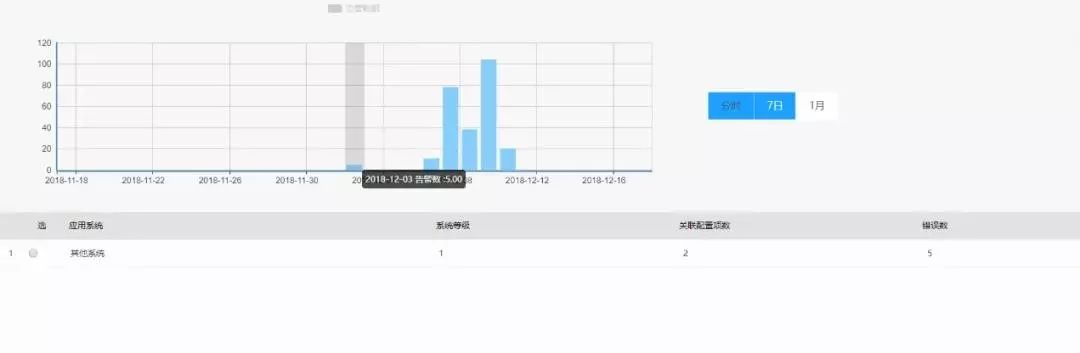
图6 根因分析数据汇总界面
③图7为根因分析界面根因分析详细结果描述图,展示了涉及的配置项、具体综合加权得分及错误原因等信息。
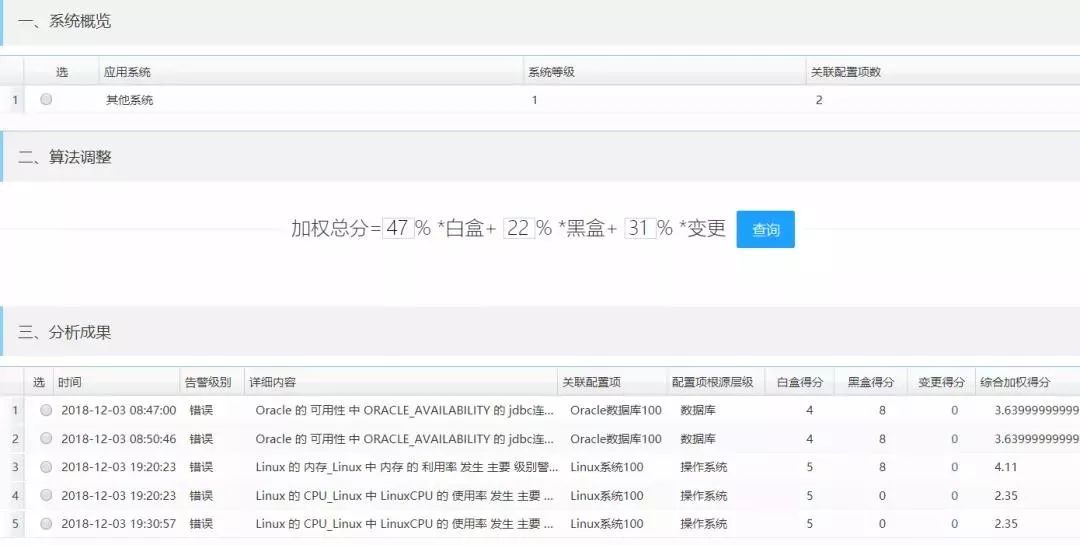
图7 根因分析界面
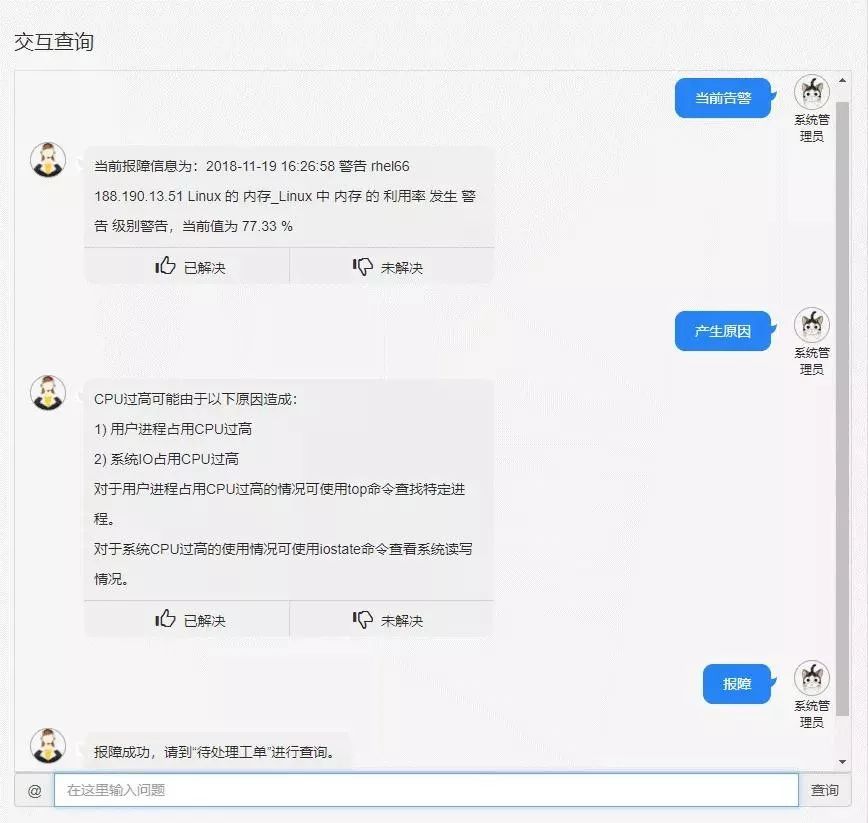
如图7所示,可以看到系统准确揭示了下列故障根源:
这里的5条告警分别处于4个不同的时间窗口。
第①②条是关于Oracle JDBC的连接状态在不同时间内发生异常的告警,根因是数据库本身。
第③条是由于Linux内存写入所引起的CPU占用过高,根因是内存写入(加权得分4.9)。第④⑤条是Linux CPU占用过高,根因是操作系统本身。
6)小结
在根因分析场景中,改良的排序算法经过实践,命中率达到90%;通过统计ITIL系统事件工单的人均处置时间,二三类故障(非重大故障)的处置速度由平均2.18小时缩短为1.45小时,整体速度提升率为33%。但不足之处在于,对系统内同一时间发生且相互间无关联的并发告警,存在误报的可能性。
1)背景概述
智能知识库的设计初衷是为了收集各类系统的基础信息及问题解决方案,通过运用机器学习算法增强系统智能性和命中率,从而提升运维人员的运维效率。本文尝试借鉴搜索引擎技术实现基础知识按词元关系存储,并通过搭建智能问答系统,优化运维知识数据的使用环节,让用户能以自然语言交互的方式获取运维知识、解决运维问题。
2)算法实现
系统采用了支持向量机(SVM)及长短期记忆网络(LSTM)等算法。本文将SVM算法应用在数据源选择、数据抓取及清洗过程中,针对运维数据进行筛选和分类。而LSTM模型则被用于构建运维知识智能问答系统的后台服务。此外,使用Elastic Search作为知识库系统的基础平台,通过集成和二次开发,实现了知识库系统所需的搜索引擎、算法平台和数据存储平台。最后,还引入了基于图结构的思考模型实现问答计算。
3)数据准备
智能知识库中的知识条目主要由两部分组成,一部分来自网络爬取的通用性知识,如硬件、操作系统等,另一部分则来自于行业知识。
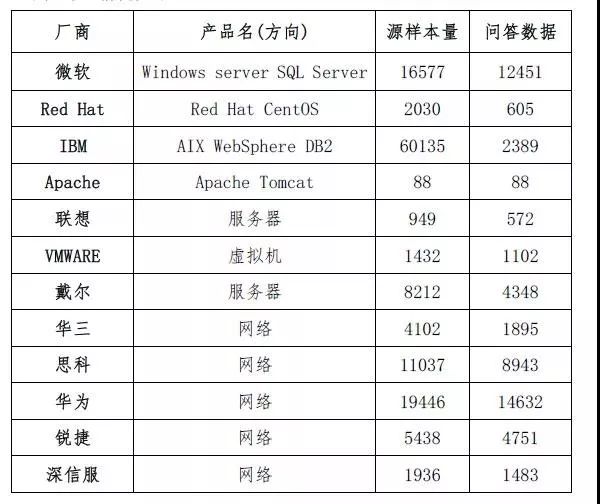
其中利用爬虫技术获取的信息来源于微软、Apache、Red Hat、IBM、联想等IT产品厂商的官方问答、知识库、社区、论坛等网站。同时,为了提高基础知识条目的数据质量,抓取过程中也使用SVM算法对爬取数据进行了分类筛选,通过建立样本库,配置相关参数形成所需的训练集和测试集。
SVM运维数据筛选分类器各项指标如下:

备注:F1值为模型筛选精准率和召回率的调和平均值,F1值越高代表模型的数据过滤能力越强。
数据抓取系统采集30多万条互联网数据,在使用SVM运维数据筛选分类器过滤后剩余有效数据131382条,数据质量方面以官网问答及官网知识库为最优。爬取的具体信息如下表所示:
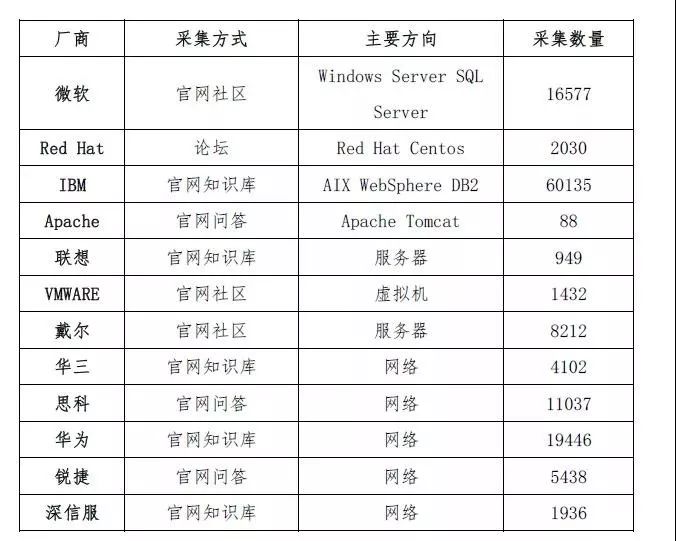
行业知识主要来自于各业务系统运维管理知识的长期积累,目前合计录入系统10000多条。
4)模型及数据处理
智能问答系统的构建过程是将优质的运维问答数据导入图结构思考模型从而提供问答服务。同时智能问答系统还能通过交互反馈信息不断优化运维问答模型。
运维问答数据分类模型的构建过程如图8所示:
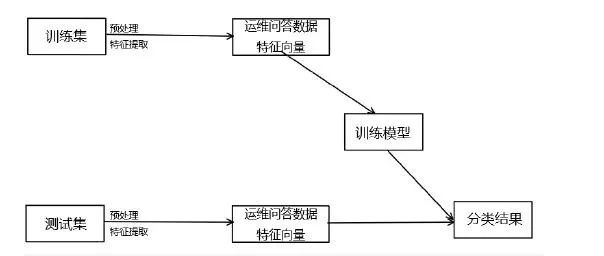
图8 问答数据分类模型图
如图8,在抓取了相关数据并形成训练集和测试集后,由于该类信息仅能提供基础运维知识,尚不满足实现智能问答所需的要求,因此还需对数据做进一步处理,包括信息过滤及特征提取。通过问答数据分类模型进行预处理的优质运维问答数据,将进一步导入图结构思考模型并最终实现智能问答。
数据预处理-特征提取
本文基于以下自然语言特征实现运维问答数据特征向量提取,主要包括:
疑问词提取
核心关键词的主要义原提取
问句主谓宾的主要义原提取
命名实体的提取
单(复)数提取
考虑到运维问答数据都是在特定运维场景下产生的,可以在其特征向量中加入自然语言依存关系,而依存关系则通过中文分词、词性标注及语法分析构建。
举例说明: LINUX系统运行的HTTP服务程序NGINX无法启动,怎么处理?
分词和词性标注结果为:Linux/ws 系统/n 运行/v 的/u http/ws 服务/v 程序/n nginx/v 无法/v 启动/v 怎么/r 处理/v ?/wp
通过依存关系分析,句中“nginx”有2个限制性定语:“Linux系统运行 的”,“ http 服务程序”。识别出这种长距离依赖关系后,可准确定位问句中心“nginx”及长距离的约束条件。
依存关系能体现限定性疑问词所限定的名词成分,这对问句分类具有重要指示作用。
命名实体识别结合依存关系分析在问题分类中能加强分类特征的辨识度。
本文基于以上特征提取方法,利用人工挑选的问答数据训练集和测试集,使用SVM算法训练问答数据分类模型。
运维问答数据分类模型各项指标如下所示:

使用运维问答数据分类模型从13万运维知识数据中提取运维问答数据53259个,详细情况如下:
5)落地效果
在知识库查询界面采用会话式问答,实现了基础运维问题的解答及基本运维工作的自动化。具体案例效果如下:
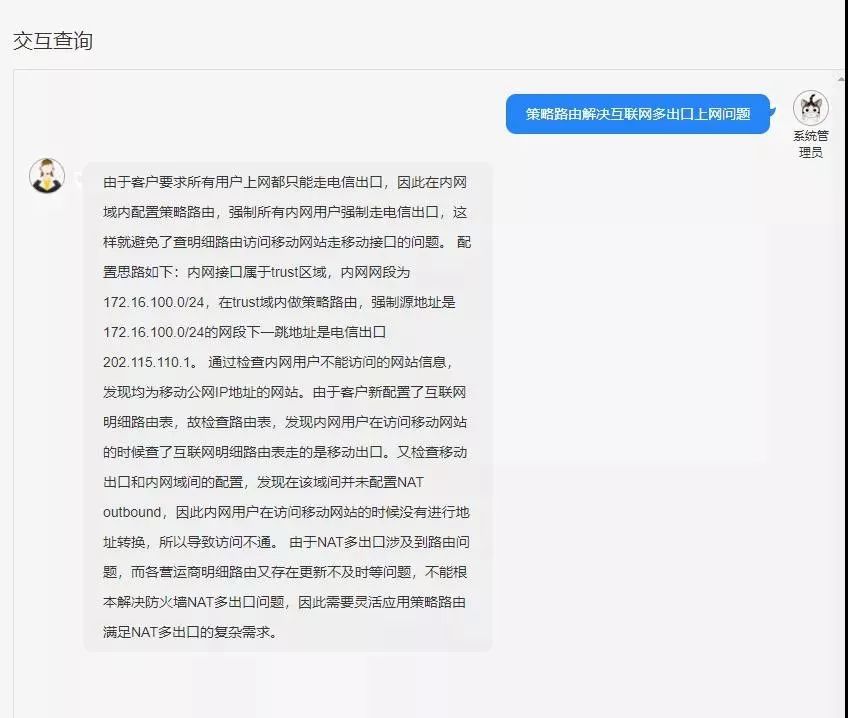
①运维知识问答
在智能问答模块的图结构思考模型中训练了5万多个运维相关问题,在交互界面中,可以回答相应的运维问题,快速提供解决方案。具体效果如下所示:
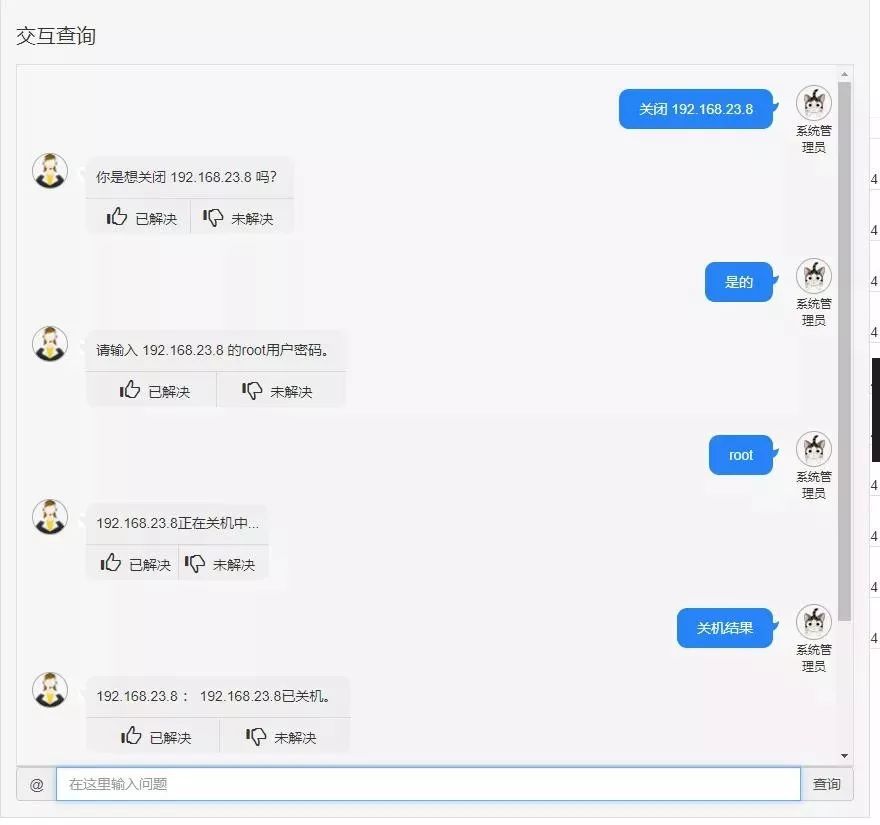
②运维操作执行
在智能问答模块中集成了运维操作接口,允许用户使用自然语言交互完成系统基础管理操作。如:输入“关闭+IP”的指令可进行远程关机操作,而通过输入“关机结果”可查询对应IP服务器的关机情况。
③告警处理
在智能问答模块中集成了事件平台接口及工作流管理系统,方便客户查询系统状态,并基于运维知识决定是否创建管理任务。
6)小结
在知识分析场景中,系统累计承载知识条目达到140000余条;通过跟踪用户搜索行为并进行统计,平均三次搜索即可命中有效知识的概率达到87%左右,而用户对知识整体质量的评价得分为4.27分左右(满分5分),基本符合预期。
1)背景概述
容量预警场景的实践,目前主要针对的是证券行业的核心应用系统“网上交易系统”,对其使用相关模型并进行了算法训练。
本文中我们使用的网上交易系统容量指标包含三个维度,分别是:QPS(每秒业务请求数)、CPU利用率、MEM内存使用量。
2)算法实现
本文所解决的“预测”,是指通过历史数据得到关于未来的一些估算值,然后用概率统计方法定量地建立一个合适的数学模型。根据这个模型对相应时间序列所反映的过程或系统做出数据预报,同时给出合适的置信区间和置信度。根据观测到的序列数据特征,可使用指数平滑法或ARIMA模型等算法。
3)数据准备
数据准备工作主要包括数据采集及清洗,一般通过系统日志、运维平台等渠道获取选定的指标数据信息。通常使用的均为历史数据,而采集频率则设置到分钟。针对有异常值、数据缺失等问题的数据也做了必要的梳理和补充。
4)模型及数据处理
在本文系统落地过程中,使用了三次指数平滑法(Holt-Winters)。置信区间置信度设置为95%。将获取的样本数据前2/3天数的数据作为训练集,采用三次指数平均法(Holt-Winters方法),进行容量预测模型训练。后1/3天数的数据作为测试集,来对预测模型进行测试评估。测试评估结果采用MAPE (Mean Absolute Percent Error)指标衡量。
5)落地效果
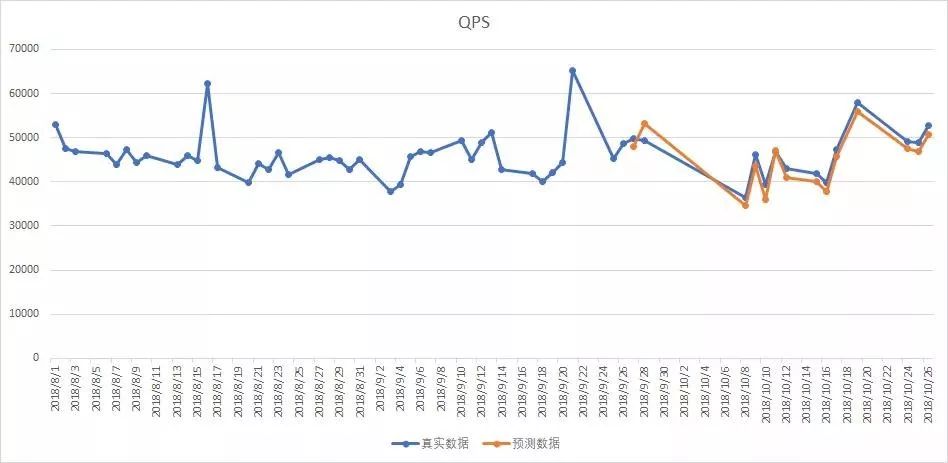
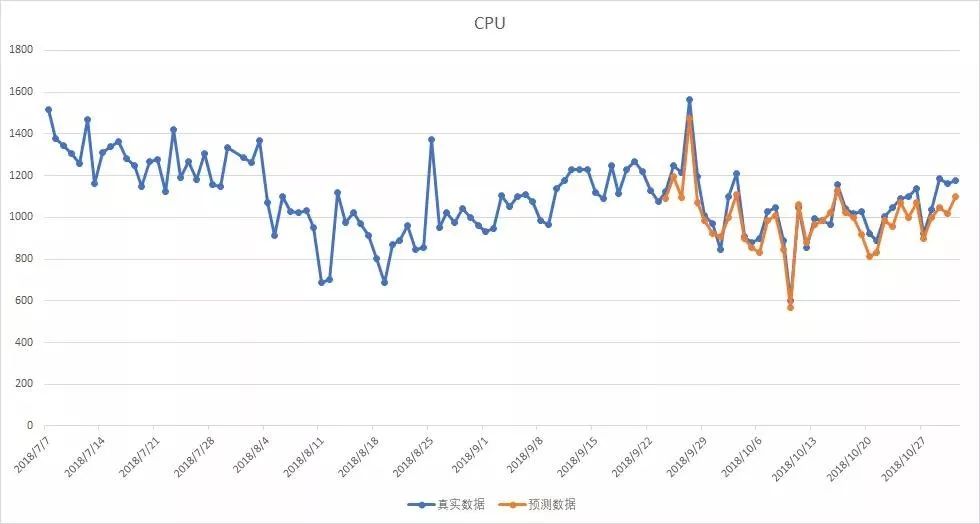
以下为网上交易系统各容量指标预测值(黄线)和真实值(蓝线)的表现数据。可以看到,无论是QPS、CPU利用率还是内存使用量,预测值与真实值之间的吻合程度均较高。
①QPS指标预测图(MAPE=2.237)
②CPU利用率指标预测图(MAPE=2.383)
③内存使用量指标预测图(MAPE=2.176)

在上述预测算法的基础上,我们可以形成多级告警算法:当出现预测的置信区上限(或下限),高于(或低于)容量预警阈值时,即可产生告警。在实践中,根据预测时间段内出现告警的频率,可设置一级预警(黄色预警)、二级预警(红色预警)并采取相应的预置扩容措施。
6)小结
在容量预测场景中,指标数据的来源主要基于网上交易和资金管理系统。经过统计,选取的三个维度指标的预测值和真实值吻合程度均较高,其平均绝对百分比误差MAPE也在预期范围内,可以为系统负载情况预先提供指导信息。
四、总结
本文基于证券行业运维领域存在的业务痛点,应用大数据、人工智能的相关理论,自主设计智能化运维平台,并以此为基础,探索智能运维在证券行业三个典型运维场景的落地与实践。
在三个场景中,对于根因分析,应用了改良的排序算法,通过实践证明有着较高的命中率。但不足之处在于,对系统内同一时间发生且相互无关的并发告警,存在误报的可能性。智能知识库在数据完备的特定场景表现满意,但考虑到数据质量不佳,数据覆盖面不够等问题,还不能全面囊括各个运维场景。而容量预测场景中采用的模型则对样本质量和数量要求较高。
本文相关架构模型、技术和算法选型可以为证券行业智能运维系统设计提供参考。文中选用的三个场景都是运维工作中目前广泛被关注的领域,可以为同业系统建设开辟思路,为进一步探索其他应用场景的落地及实践提供了宝贵的经验。
参考资料
黄荣怀、李茂国、沙景荣,2004,《知识工程学:一个新的重要研究领域》
刘俊、彭冬、朱伟等,2018,《智能运维:从0搭建大规模分布式AIOps系统》,电子工业出版社
林莉,2011,《智能化网络运维管理平台的研究与实现》
王博(百度运维部),2017,《百度大规模时序指标自动异常检测实战》,CNUTCon全球容器技术大会
王晓东、许乐、、张晨曦,2009,《一种基于ITIL的IT运维中心模型设计》
王肇刚(梓弋),2018,《AIOps智能告警管理在阿里巴巴集团的成功实践》,云栖大会
]J. D. Cryer and K. S. Chan, 2008,“Time Series Analysis with With Applications in R(Second Edition): Springer”
NASCIO: National Association of State Chief Information Officers,2005, “IT Management Frameworks: A Foundation for Success”
OGC:Office Government Commerce,2007,“IT Infrastructure Library Version3 Framework”
TcpRT,2018,“Instrument and Diagnostic Analysis System for Service Quality of Cloud Databases at Massive Scale in Real-time”
作者介绍
黄成 李华,上海证券交易所。
罗秋清 杨兵 李文珺 刘郭洋 刘博,海通证券股份有限公司。
廖万里 屈文浩 肖飞 何鎏,珠海金智维信息科技有限公司。
活动推荐
2020年4月17日,北京,Gdevops全球敏捷运维峰会将开启年度首站!重点围绕数据库、智慧运维、Fintech金融科技领域,携手阿里、腾讯、蚂蚁金服、中国银行、平安银行、中邮消费金融、建设银行、农业银行、民生银行、中国联通大数据、浙江移动、新炬网络等技术代表,展望云时代下数据库发展趋势、破解运维转型困局。








如果字段的最大可能长度超过255字节,那么长度值可能…
只能说作者太用心了,优秀
感谢详解
一般干个7-8年(即30岁左右),能做到年入40w-50w;有…
230721